Pixtral 12B - the first-ever multimodal Mistral model.
Pixtral 12B - the first-ever multimodal Mistral model.
https://mistral.ai/news/pixtral-12b/
Pixtral 12B in short:
- Natively multimodal, trained with interleaved image and text data
- Strong performance on multimodal tasks, excels in instruction following
- Maintains state-of-the-art performance on text-only benchmarks
- Architecture:
- New 400M parameter vision encoder trained from scratch
- 12B parameter multimodal decoder based on Mistral Nemo
- Supports variable image sizes and aspect ratios
- Supports multiple images in the long context window of 128k tokens
- Use:
- License: Apache 2.0
- Try it on La Plateforme or on Le Chat
Pixtral is trained to understand both natural images and documents, achieving 52.5% on the MMMU reasoning benchmark, surpassing a number of larger models. The model shows strong abilities in tasks such as chart and figure understanding, document question answering, multimodal reasoning and instruction following. Pixtral is able to ingest images at their natural resolution and aspect ratio, giving the user flexibility on the number of tokens used to process an image. Pixtral is also able to process any number of images in its long context window of 128K tokens. Unlike previous open-source models, Pixtral does not compromise on text benchmark performance to excel in multimodal tasks.
Performance
Pixtral was trained to be a drop-in replacement for Mistral Nemo 12B. Its key distinguishing factor from existing open-source models is the delivery of best-in-class multimodal reasoning without compromising on key text capabilities such as instruction following, coding, and math.
Evaluation protocol
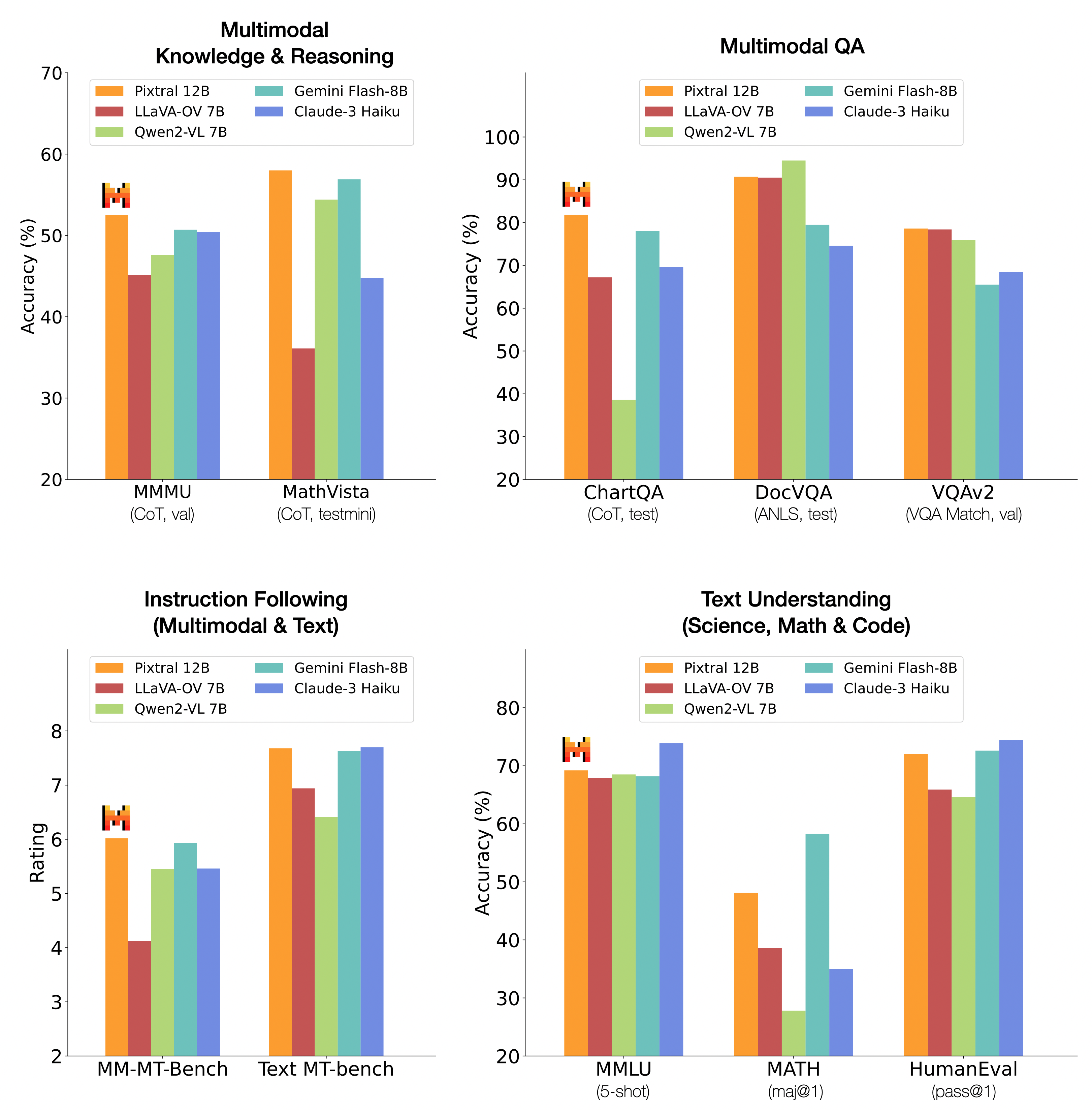
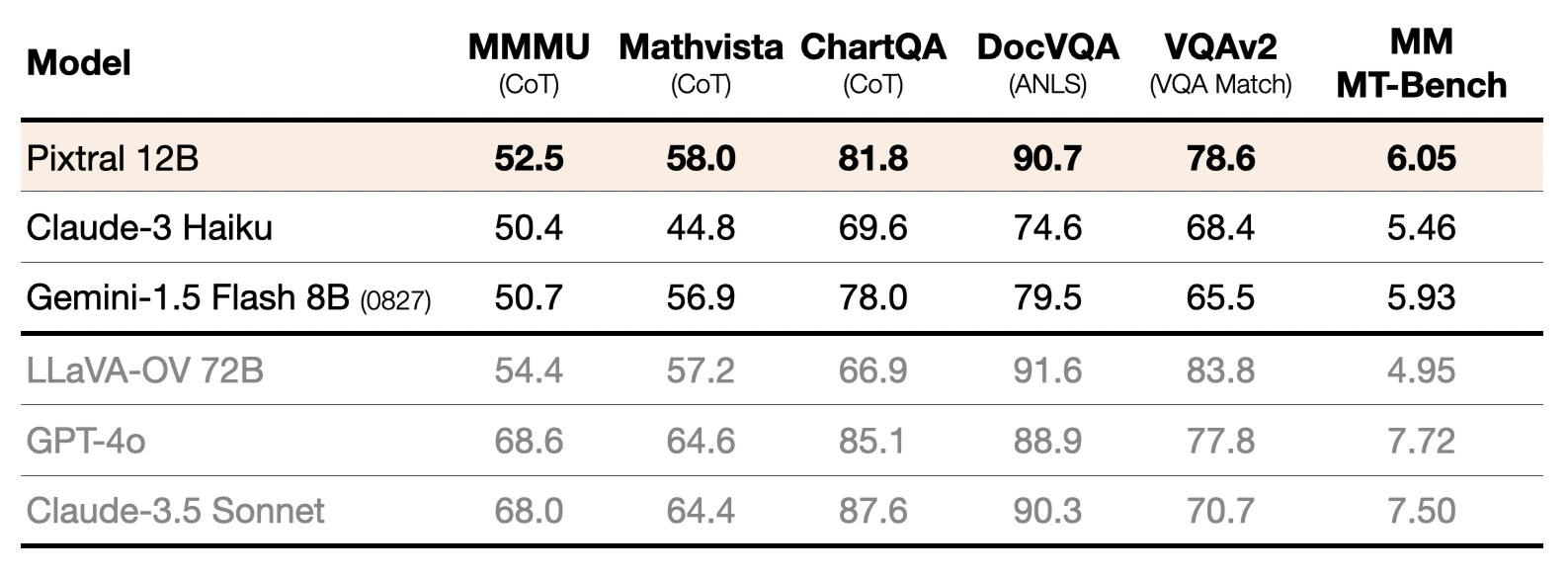
We re-evaluate a range of open and closed models through the same evaluation harness. For each dataset, the prompt was chosen such that we could reproduce the results of leading multimodal models (GPT-4o and Claude-3.5-Sonnet). All models were then evaluated with this same prompt. Overall, Pixtral substantially outperforms all open models around its scale and, in many cases, outperforms closed models such as Claude 3 Haiku. Pixtral even outperforms or matches the performance of much larger models like LLaVa OneVision 72B on multimodal benchmarks.All prompts will be open-sourced.
Performance of Pixtral compared to closed and larger multimodal models. [All models were benchmarked through the same evaluation harness and with the same prompt. We verify that prompts reproduce the performance reported for GPT-4o and Claude 3.5 Sonnet (prompts will be provided in technical report)].
Instruction following
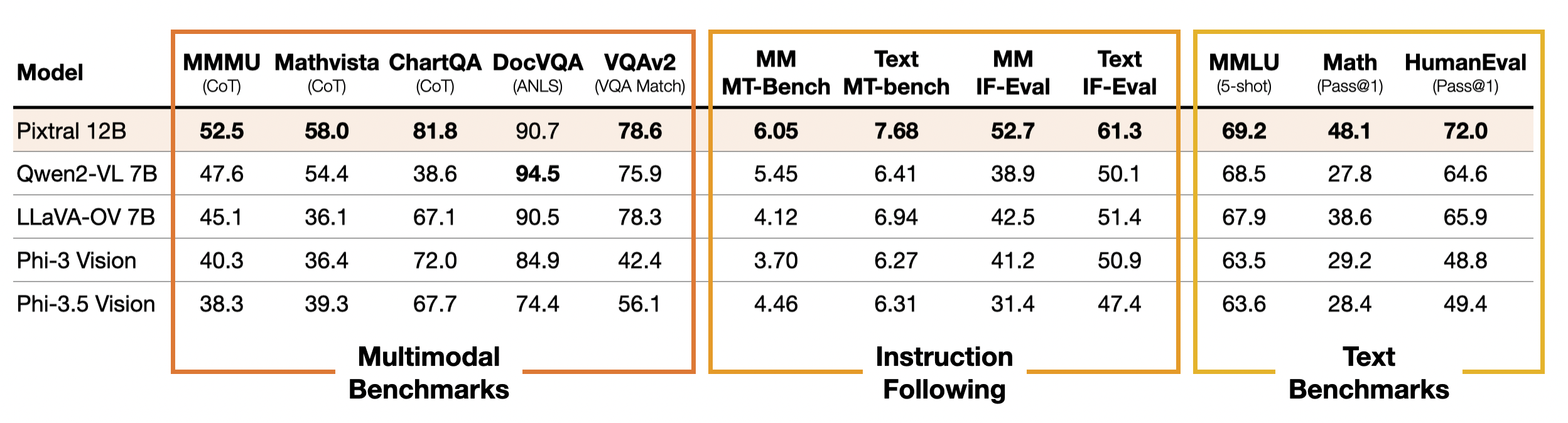
Pixtral particularly excels at both multimodal and text-only instruction following as compared to other open multimodal models. It substantially outperforms Qwen2-VL 7B, LLaVa-OneVision 7B and Phi-3.5 Vision in instruction following, with a 20% relative improvement in text IF-Eval and MT-Bench over the nearest OSS model. To further evaluate this ability for multimodal use cases, we create multimodal versions of these benchmarks: MM-IF-Eval and MM-MT-Bench. Pixtral outperforms open-source alternatives on multimodal instruction following benchmarks as well. We will open-source MM-MT-Bench to the community.
Performance of Pixtral compared to open multimodal models. All models were benchmarked through the same evaluation harness and with the same prompt.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号