多模态大模型
多模态大模型(MLLMs)是一类结合了大型语言模型(LLMs)的自然语言处理能力与对其他模态(如视觉、音频等)数据的理解与生成能力的模型。 旨在通过整合文本、图像、声音等多种类型的输入和输出,提供更加丰富和自然的交互体验。
A Survey on Multimodal Large Language Models
https://arxiv.org/pdf/2306.13549
多模态大模型,其是基于LLM,同时具有了接收、推理、输出多模态信息的能力。
In light of this complementarity, LLM and LVM run
towards each other, leading to the new field of Multimodal
Large Language Model (MLLM). Formally, it refers to the
LLM-based model with the ability to receive, reason, and
output with multimodal information
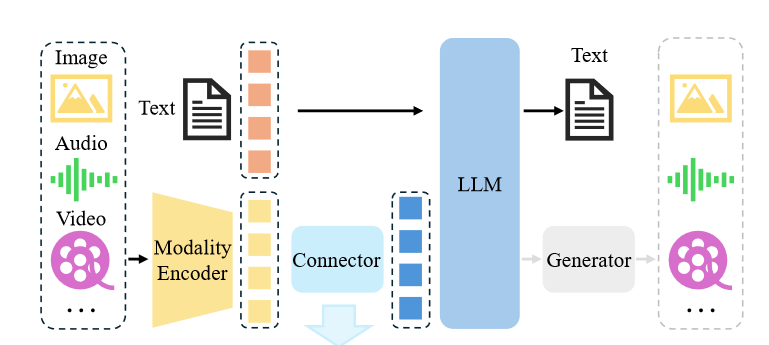
A typical MLLM can be abstracted into three modules, i.e.
a pre-trained modality encoder, a pre-trained LLM, and a
modality interface to connect them. Drawing an analogyto humans, modality encoders such as image/audio en-
coders are human eyes/ears that receive and pre-process
optical/acoustic signals, while LLMs are like human brains
that understand and reason with the processed signals. In
between, the modality interface serves to align different
modalities. Some MLLMs also include a generator to output
other modalities apart from text. A diagram of the architec-
ture is plotted in Fig. 2. In this section, we introduce each
module in sequence
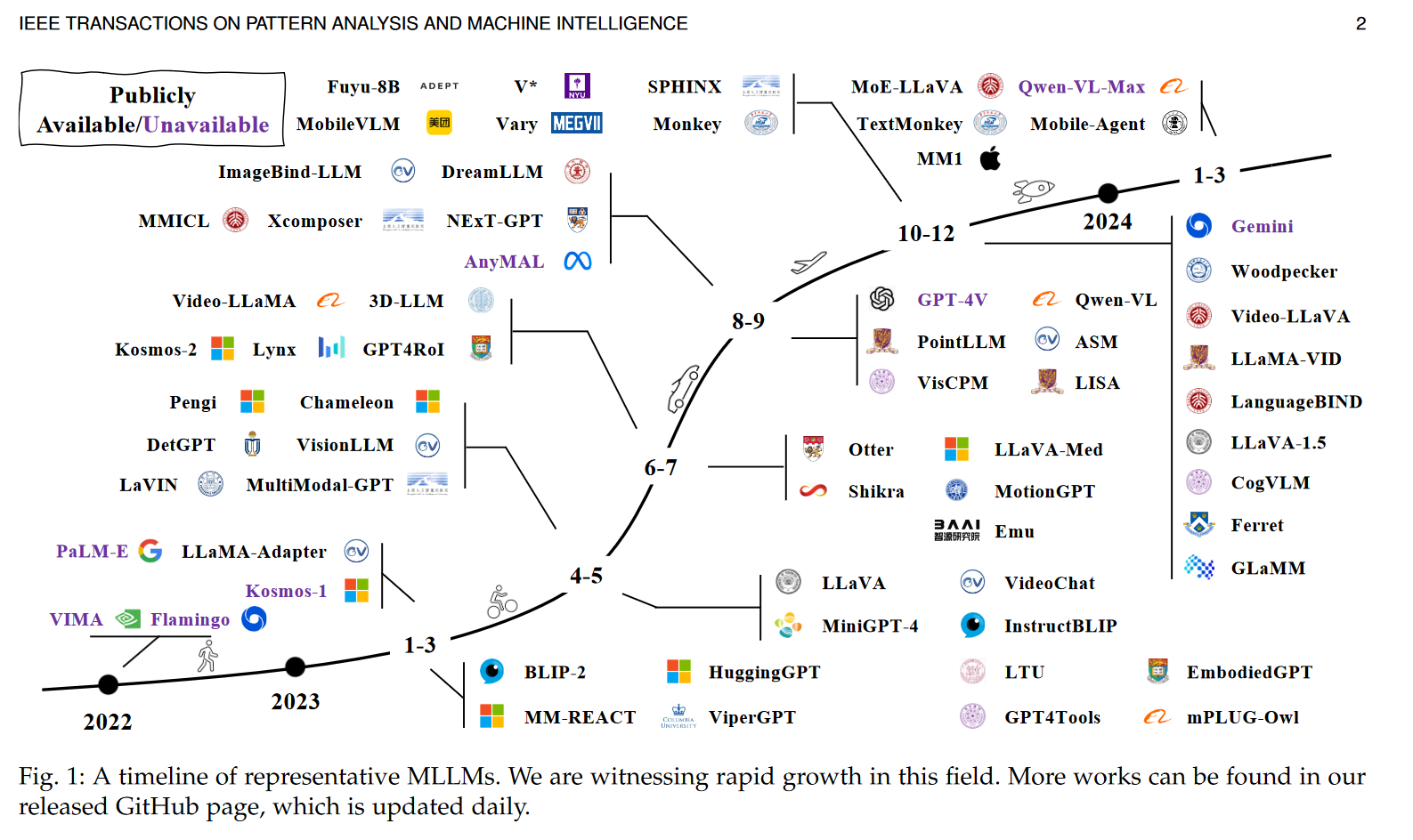
MM-LLMs: Recent Advances in MultiModal Large Language Models
https://arxiv.org/pdf/2401.13601
https://zhuanlan.zhihu.com/p/680487634
https://developer.volcengine.com/articles/7389112087835836466
随着人工智能技术的快速发展,大型语言模型(LLM)已成为自然语言处理领域的一大热点。如今,这些强大的语言模型开始支持多模态输入和输出,形成了一个全新的研究领域——多模态大型语言模型(MM-LLM)。在过去一年中,MM-LLM取得了长足的进步。
The timeline of MM-LLMs
多模态LLMs的通用架构
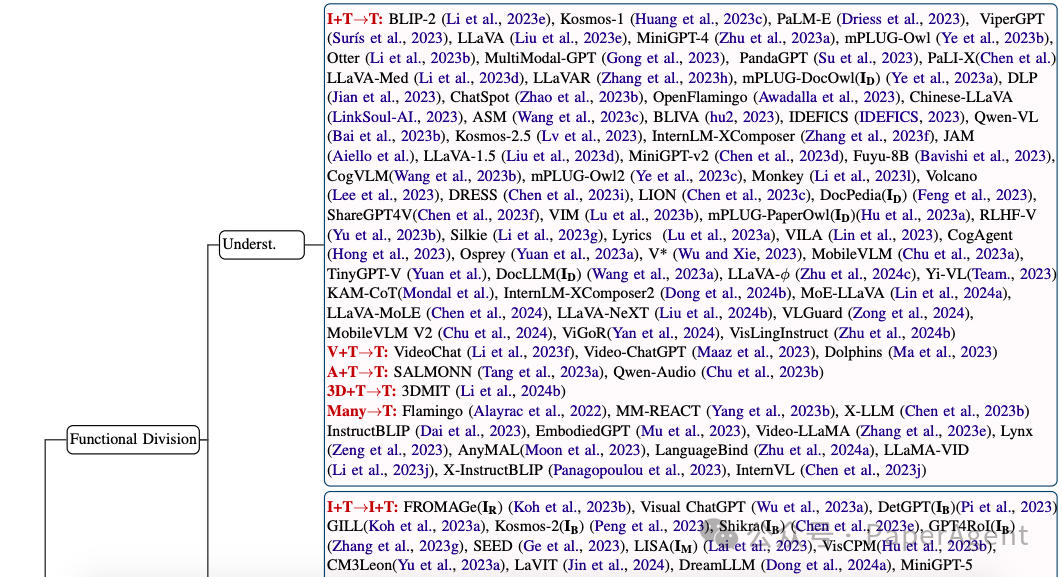
多模态大型语言模型(MLLMs)的通用架构通常包括以下几个关键组件:
- 视觉编码器(Visual Encoder):这部分负责处理和理解输入的视觉信息,如图像。它通常使用预训练的视觉模型,如Vision Transformer(ViT)或其他卷积神经网络(CNN)架构,来提取图像特征。
- 语言模型(Language Model):这是MLLM的核心部分,通常基于Transformer架构,如BERT或GPT系列模型。语言模型处理文本输入,理解和生成自然语言。
- 适配器模块(Adapter Module):这个模块是MLLM中的关键部分,它负责在视觉和语言模态之间建立联系。适配器可以是一个简单的线性层,也可以是更复杂的结构,如多层感知器(MLP)或Transformer层,它们通过自注意力机制促进视觉和文本特征之间的对齐。
多模态大型语言模型(MLLMs)的 通用架构 ,由视觉编码器、语言模型和一个适配器模块组成,该适配器模块将视觉输入连接到文本空间。
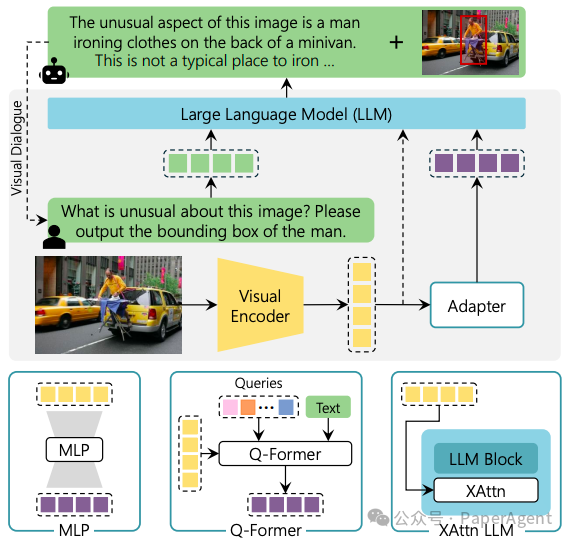
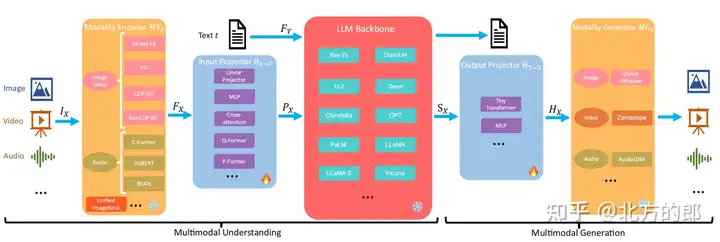
MM-LLM的模型架构
The general model architecture of MM-LLMs and the implementation choices for each component.
如图所示,MM-LLMs的模型架构包括以下5个组成部分:
模态编码器(Modality Encoder): 负责对不同的模态输入IX进行编码,得到对应的特征FX。IX可以是图像、视频、音频、3D等不同类型的输入。常用的编码器包括:
- 图像编码器:NFNet-F6、ViT、CLIP ViT、Eva-CLIP ViT
- 视频编码器
- :对视频均匀采样成5帧,进行与图像类似的预处理
- 音频编码器:C-Former、HuBERT、BEATs、Whisper
- 3D点云编码器:ULIP-2、PointBERT
- 统一编码器:ImageBind,支持图像、视频、文本、音频、热图等多种模态
输入投影器(Input Projector): 负责将编码后的其他模态特征FX投影到文本特征空间
T,得到对齐的特征PX。常用的实现方法有:
- 直接线性投影或多层感知机
- 交叉注意力:利用可训练的查询向量与编码特征FX进行压缩,得到固定长度的表示,并直接输入LLM或进行交叉注意力融合
- Q-Former:从FX中提取相关特征,作为提示PX
- P-Former:生成参考提示,对Q-Former生成的提示进行对齐约束
LLM骨干网络(LLM Backbone): 利用预训练的大型语言模型作为核心,负责对齐后的特征进行语义理解、推理和决策,并输出文本输出t和来自其他模态的信号令牌SX。常用的LLM包括:
- Flan-T5
- ChatGLM
- UL2
- Qwen
- Chinchilla
- OPT
- PaLM
- LLaMA
- LLaMA-2
- Vicuna
输出投影器(Output Projector): 将LLM骨干网络中的信号令牌SX映射到特征HX,以使其可被后续的模态生成器MGX理解。通常采用Tiny Transformer或多层感知机来实现。
模态生成器(Modality Generator): 负责生成不同模态的输出,通常采用预训练的潜在扩散模型
(LDMs),将输出投影器映射的特征HX作为条件输入,以生成多模态内容。常用的LDMs包括:
- 图像合成:Stable Diffusion
- 视频合成:Zeroscope
- 音频合成:AudioLDM-2
这5个部分共同组成了MM-LLMs的模型架构,每个部分都有其特定的功能和实现选择。


三大闭源模型推理能力
https://hiresynth.ai/blog/googleio_puzzle_multimodal_eval.html#introduction-the-models
OpenAI GPT-4V
The multimodal LLM craze started with the release of GPT-4V in September and the enticing caption:
"ChatGPT can now see, hear, and speak"Google Gemini Ultra
Next Google Gemini Ultra was released in December, along with the following press release:
"[Gemini] was built from the ground up to be multimodal, which means it can generalize and seamlessly understand, operate across and combine different types of information including text, code, audio, image and video."Anthropic Claude3 Opus
Finally, Anthropic Claude3 Opus has just been released in February, with the following caption: "The Claude 3 models have sophisticated vision capabilities on par with other leading models. They can process a wide range of visual formats, including photos, charts, graphs and technical diagrams."
Along with the release of Claude3, we were provided a handy chart comparing the multimodal capabilities of the three models:
The results of our evaluation test reveal that the current state of multimodal reasoning in LLMs is far from perfect. None of the models were able to understand the puzzle or provide a correct solution. This is a surprising outcome, given the multimodal capabilities that each model claims to possess.
The Google IO 2024 puzzle has proven to be a challenging benchmark for evaluating multimodal reasoning in LLMs, and it is clear that there is still much work to be done in this area.
With that said, GPT4-V consistently understood the puzzle and the task it was required to perform and thus we conclude that currently for multimodal reasoning tasks, we'd recommend using GPT-4V over the other models.
All the above models will be available to try out at hiresynth.ai within the next couple days, just potentially be careful when building any multimodal AI agents with them for the time being.

https://www.iamdave.ai/blog/what-is-multimodal-ai-top-5-multimodal-ai-models-for-businesses-in-2024/
The multimodal AI scene is rapidly expanding. The global market for multimodal Al market is projected to grow from USD 1.0 billion in 2023 to USD 4.5 billion by 2028, at a CAGR of 35.0% during the forecast period. This has led to tech giants investing in the innovative platform. The most popular ones by far include:
- Google Gemini
- GPT-4V
- Inworld AI
- Meta ImageBind
- Runway Gen-2
Multimodal LLM: Expert Guide On The Next Frontier Of AI
https://www.a3logics.com/blog/multimodal-llm-in-ai/#OpenAI
Coupled with the ongoing AI developments of other powerhouse technology companies — Microsoft, Meta, Google, and Amazon — these advancements are colossal. In reality we’ve seen generative AI (GenAI) become functionally multimodal AI in less than 12 months. As per Grand View Research Report, the global large language model market size was estimated at USD 4.35 billion in 2023 and is projected to grow at a compound annual growth rate (CAGR) of 35.9% from 2024 to 2030. With milestone after milestone achieved, everyone is considering what is ahead for AI in 2024. Now we’ll dive into this expert guide on the next AI frontier and everything businesses should know about multimodal LLM.
多模态大模型评测榜单
lmsys && opencompass high ranked MLLM
https://lmarena.ai/
https://rank.opencompass.org.cn/leaderboard-multimodal/?m=REALTIME
多模态大模型最新进展
https://www.shlab.org.cn/news/5443890
https://developer.volcengine.com/articles/7389112087835836466

 浙公网安备 33010602011771号
浙公网安备 33010602011771号