HMM 中文分词应用
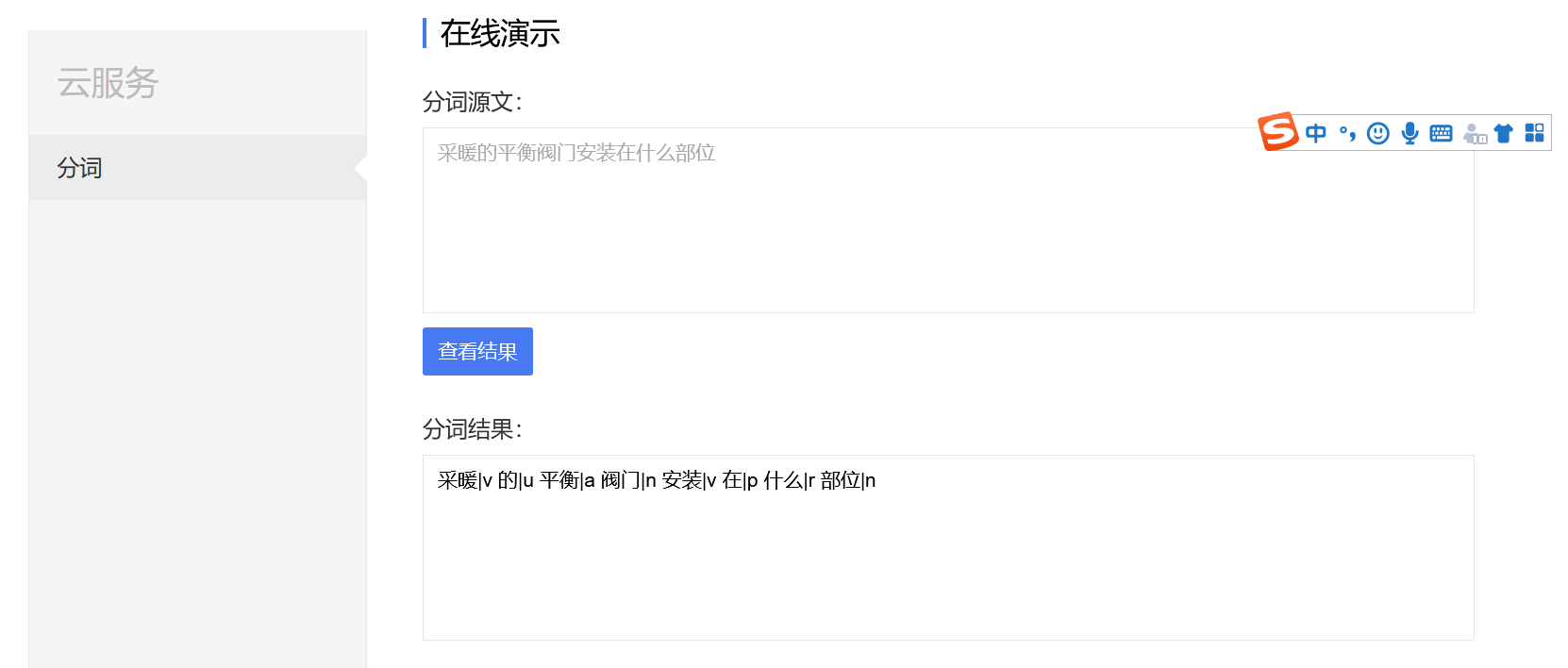
sougou中文分词服务
http://www.sogou.com/labs/webservice/
中文分词指的是将连续的汉字序列切分成一个个单独的词。
分词精度:
使用国家语委语料库所开放的2000万字汉语语料,其词性标注集符合《信息处理用现代汉语词类标记规范》(GB/T 20532—2006)。其中1800万字作为训练集,220万字作为测试集。在该集合上进行封闭测试,分词精度可达:F1 = 97.03%。
词性标注精度:
训练和测试集同上。封闭测试精度:96.08%
语料库
https://www.jianshu.com/p/206caa232ded
1. 原始语料,比如某某新闻,微博合集,一些未经处理的原始语料;
这个是xml格式,包含很多meta
2. 分词库(语料),最常见的比如搜狗分词库,结巴词库;
这种词库比较好找,也比较杂乱,这里我整理了几个不错的,在这里:all@百度盘
此处尽量按照『文本组成@词数量_出处』格式进行文件命名,如下:
分词词库列表
- 这里比较推荐
分词_频数_词性@35万_结巴.txt和分词_拼音@4万_搜狗.txt两个词库。如果你有一些比如拼音需求,也可以选择对应文本;- 需要注意的一点是,有一个
分类_分词@12大类5485文本1127万_搜狗.20151022.tar.gz文件,这个是搜狗细胞词库所有的词了,里面包含非常多的各行业词汇,如下图,在针对特定行业ML时候,这些分词应该是比较有帮助的,特别是带有【官方推荐】名字的,都非常不错。
分类_分词@12大类5485文本1127万_搜狗.20151022.tar.gz3. 词性标注库(语料),比如98年人民日报词性标注库@百度盘;
此处尽量按照『词性标注@行数量_出处』格式进行文件命名。
相较于上面两种语料,此语料人工标注成本太高,所以也比较少。目前我也只有98年人民日报词性标注库。不过网上说人民日报2014年词性标注库也已经有了,但是需要授权,我也没拿到。
98年人民日报词性标注库




人民日报标注语料库(PFR)
https://www.jianshu.com/p/30fa95e143bf
经过人工分词和标注处理过的语料库,是熟语料库。
生语料库和熟语料库
- 语料库中存放的是在语言的实际使用中真实出现过的语言材料,语料库是以电子计算机为载体承载语言知识的基础资源,真实语料需要经过加工、分析和处理之后才能成为可用的语料库
- 生语料库是指收集之后未加工的预料库 相对而言,熟语料库就是经过加工的
格式
19980101-01-001-001/m 迈向/v 充满/v 希望/n 的/u 新/a 世纪/n ——/w 一九九八年/t 新年/t 讲话/n (/w 附/v 图片/n 1/m 张/q )/w
……
19980101-01-001-006/m 在/p 1998年/t 来临/v 之际/f ,/w 我/r 十分/m 高兴/a 地/u 通过/p [中央/n 人民/n 广播/vn 电台/n]nt 、/w [中国/ns 国际/n 广播/vn 电台/n]nt 和/c [中央/n 电视台/n]nt ,/w 向/p 全国/n 各族/r 人民/n ,/w 向/p [香港/ns 特别/a 行政区/n]ns 同胞/n 、/w 澳门/ns 和/c 台湾/ns 同胞/n 、/w 海外/s 侨胞/n ,/w 向/p 世界/n 各国/r 的/u 朋友/n 们/k ,/w 致以/v 诚挚/a 的/u 问候/vn 和/c 良>好/a 的/u 祝愿/vn !/w
标注
1.标记说明
代码 名称 Ag 形语素 a 形容词 ad 副形词 an 名形词 Bg 区别语素 b 区别词 c 连词 Dg 副语素 d 副词 e 叹词 f 方位词 g 语素 h 前接成分 i 成语 j 简略语 k 后接成分 l 习用语 Mg 数语素 m 数词 Ng 名语素 n 名词 nr 人名 ns 地名 nt 机构团体 nx 外文字符 nz 其它专名 o 拟声词 p 介词 Qg 量语素 q 量词 Rg 代语素 r 代词 s 处所词 Tg 时间语素 t 时间词 Ug 助语素 u 助词 Vg 动语素 v 动词 vd 副动词 vn 名动词 w 标点符号 x 非语素字 Yg 语气语素 y 语气词 z 状态词
开放在github上
https://github.com/chenhui-bupt/PeopleDaily1998
PeopleDaily1998
人民日报标注语料库(版本1.0,下面简称PFR语料库)是在得到人民日报社新闻信息中心许可的条件下,以1998年人民日报语料为对象,由北京大学计算语言学研究所和富士通研究开发中心有限公司共同制作的标注语料库。该语料库对600多万字节的中文文章进行了分词及词性标注,其被作为原始数据应用于大量的研究和论文中。
NLTK 语料库
https://www.cnblogs.com/yucen/p/9343547.html
什么是语料库?文本语料库是一个大型结构化文本的集合。
NLTK包含了许多语料库:
(1)古滕堡语料库
(2)网络和聊天文本
(3)布朗语料库
(4)路透社语料库
(5)就职演讲语料库
(6)标注文本语料库
jieba分词工具
https://github.com/fxsjy/jieba
“结巴”中文分词:做最好的 Python 中文分词组件
"Jieba" (Chinese for "to stutter") Chinese text segmentation: built to be the best Python Chinese word segmentation module.
算法
- 基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
- 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
- 对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
使用的HMM对于未收录的新词,可以有效识别。
代码示例
# encoding=utf-8 import jieba jieba.enable_paddle()# 启动paddle模式。 0.40版之后开始支持,早期版本不支持 strs=["我来到北京清华大学","乒乓球拍卖完了","中国科学技术大学"] for str in strs: seg_list = jieba.cut(str,use_paddle=True) # 使用paddle模式 print("Paddle Mode: " + '/'.join(list(seg_list))) seg_list = jieba.cut("我来到北京清华大学", cut_all=True) print("Full Mode: " + "/ ".join(seg_list)) # 全模式 seg_list = jieba.cut("我来到北京清华大学", cut_all=False) print("Default Mode: " + "/ ".join(seg_list)) # 精确模式 seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式 print(", ".join(seg_list)) seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式 print(", ".join(seg_list))输出:
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学 【精确模式】: 我/ 来到/ 北京/ 清华大学 【新词识别】:他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了) 【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
- 添加自定义词典
HMM
https://en.wikipedia.org/wiki/Hidden_Markov_model
Hidden Markov models are known for their applications to thermodynamics, statistical mechanics, physics, chemistry, economics, finance, signal processing, information theory, pattern recognition - such as speech, handwriting, gesture recognition,[1] part-of-speech tagging, musical score following,[2] partial discharges[3] and bioinformatics.[4][5]

 – with unobservable ("hidden") states. HMM assumes that there is another process
– with unobservable ("hidden") states. HMM assumes that there is another process  whose behavior "depends" on
whose behavior "depends" on  , the conditional probability distribution of
, the conditional probability distribution of  given the history
given the history  must not depend on
must not depend on  .
. 

https://zhuanlan.zhihu.com/p/166552799
隐马尔科夫模型(Hidden Markov Model,简称HMM)是用来描述隐含未知参数的统计模型,HMM已经被成功于语音识别、文本分类、生物信息科学、故障诊断和寿命预测等领域。
HMM可以由三个要素组成:
=(A,B,II),其中A为状态转移概率矩阵,B为观测状态概率矩阵,II为隐藏状态初始概率分布。
HMM有两个基本假设,一是齐次马尔可夫性假设,隐马尔可夫链t的状态只和t-1状态有关;二是观测独立性假设,观测只和当前时刻状态有关。
HMM解决的三个问题:
- 一是概率计算问题,已知模型和观测序列,计算观测序列出现的概率,该问题求解的方法为向前向后法;
- 二是学习问题,已知观测序列,估计模型的参数,该问题求解的方法为鲍姆-韦尔奇算法
- 三是预测问题(解码问题),已知模型和观测序列,求解状态序列,该问题求解的方法为动态规划的维特比算法。【实例分析】
HMM的实现:python的hmmlearn类,按照观测状态是连续状态还是离散状态,可以分为两类。GaussianHMM和GMMHMM是连续观测状态的HMM模型;MultinomialHMM是离散观测状态的模型。
hmmlearn
https://github.com/hmmlearn/hmmlearn
Hidden Markov Models in Python, with scikit-learn like API
https://hmmlearn.readthedocs.io/en/latest/
Simple algorithms and models to learn HMMs (Hidden Markov Models) in Python,
Follows scikit-learn API as close as possible, but adapted to sequence data,
Built on scikit-learn, NumPy, SciPy, and matplotlib,
Open source, commercially usable — BSD license.
HMM 分词实现思想
https://zhuanlan.zhihu.com/p/40502333
- a. 评估问题(概率计算问题) :即给定观测序列 O=O1,O2,O3…Ot和模型参数λ=(A,B,π),怎样有效计算这一观测序列出现的概率. (Forward-backward算法)
- b. 解码问题(预测问题) :即给定观测序列 O=O1,O2,O3…Ot和模型参数λ=(A,B,π),怎样寻找满足这种观察序列意义上最优的隐含状态序列S。 (viterbi算法,近似算法)
- c. 学习问题 :即HMM的模型参数λ=(A,B,π)未知,如何求出这3个参数以使观测序列O=O1,O2,O3…Ot的概率尽可能的大. (即用极大似然估计的方法估计参数,Baum-Welch,EM算法)
模型的关键相应参数λ=(A,B,π),经过作者对大量语料的训练, 得到了finalseg目录下的三个文件(初始化状态概率(π)即词语以某种状态开头的概率,其实只有两种,要么是B,要么是S。这个就是起始向量, 就是HMM系统的最初模型状态,对应文件prob_start.py;隐含状态概率转移矩A 即字的几种位置状态(BEMS四个状态来标记, B是开始begin位置, E是end, 是结束位置, M是middle, 是中间位置, S是single, 单独成词的位置)的转换概率,对应文件prob_trans.py;观测状态发射概率矩阵B 即位置状态到单字的发射概率,比如P(“狗”|M)表示一个词的中间出现”狗”这个字的概率,对应文件prob_emit.py)。
3 使用Viterbi算法实现中文分词
3.1 模型
HMM的典型模型是一个五元组:
StatusSet: 状态值集合
ObservedSet: 观察值集合
TransProbMatrix: 转移概率矩阵
EmitProbMatrix: 发射概率矩阵
InitStatus: 初始状态分布3.2 基本假设
HMM模型的三个基本假设如下:
有限历史性假设:
P(Status[i]|Status[i-1],Status[i-2],… Status[1]) = P(Status[i]|Status[i-1])
齐次性假设(状态和当前时刻无关):
P(Status[i]|Status[i-1]) = P(Status[j]|Status[j-1])
观察值独立性假设(观察值只取决于当前状态值):
P(Observed[i]|Status[i],Status[i-1],…,Status[1]) = P(Observed[i]|Status[i])
3.3 五元组
3.3.1 状态值集合(StatusSet)
为(B, M, E, S): {B:begin, M:middle, E:end, S:single}。分别代表每个状态代表的是该字在词语中的位置,B代表该字是词语中的起始字,M代表是词语中的中间字,E代表是词语中的结束字,S则代表是单字成词。
如:
给你一个隐马尔科夫链的例子。
可以标注为:
给/S 你/S 一个/BE 隐马尔科夫链/BMMMME 的/S 例子/BE 。/S3.3.2 观察值集合(ObservedSet)
为就是所有汉字(东南西北你我他…),甚至包括标点符号所组成的集合。
状态值也就是我们要求的值,在HMM模型中文分词中,我们的输入是一个句子(也就是观察值序列),输出是这个句子中每个字的状态值。
3.3.3 初始状态概率分布(InitStatus )
如:B -0.26268660809250016 E -3.14e+100 M -3.14e+100 S -1.4652633398537678数值是对概率值取【对数】之后的结果(可以让概率【相乘】的计算变成对数【相加】)。其中-3.14e+100作为负无穷,也就是对应的概率值是0。
也就是句子的第一个字属于{B,E,M,S}这四种状态的概率。
3.3.4 转移概率矩阵(TransProbMatrix )
【有限历史性假设】
转移概率是马尔科夫链。Status(i)只和Status(i-1)相关,这个假设能大大简化问题。所以,它其实就是一个4x4(4就是状态值集合的大小)的二维矩阵。矩阵的横坐标和纵坐标顺序是BEMS x BEMS。(数值是概率求对数后的值)
3.3.5 发射概率矩阵(EmitProbMatrix )
【观察值独立性假设】
P(Observed[i], Status[j]) = P(Status[j]) * P(Observed[i]|Status[j])
其中,P(Observed[i]|Status[j])这个值就是从EmitProbMatrix中获取。3.4 使用Viterbi算法
这五元的关系是通过一个叫Viterbi的算法串接起来,ObservedSet序列值是Viterbi的输入,而StatusSet序列值是Viterbi的输出,输入和输出之间Viterbi算法还需要借助三个模型参数,分别是InitStatus, TransProbMatrix, EmitProbMatrix。
HMM 分词实现代码
https://github.com/fanqingsong/chinese_word_segment
# implement chinese words segmentation with HMM model
# model training
python HMM_train.py
* RenMinData.RenMinData_utf8 corpus from People Daily with words segmentation.
Then three probability configurations are produced.
* prob_start.py -- initial state probability vector
* prob_trans.py -- transfer probability matrix between all states
* prob_emit.py -- watched probability matrix for every state
# model testing
python HMM_app.py
#reference
* viterbi :http://zh.wikipedia.org/wiki/%E7%BB%B4%E7%89%B9%E6%AF%94%E7%AE%97%E6%B3%95
* https://github.com/fxsjy/finalseg
train
#!/usr/bin/python #-*-coding:utf-8 import sys import math import pdb class WordSegmentTrainer: def __init__(self): self._state_transfer_count = {} self._state_emit_count = {} self._state_count = {} self._state_pi_count = {} self._word_set = set() self._state_list = ['B','M','E','S'] self._line_num = -1 self._corpus_file = "./corpus/RenMinData.txt_utf8" self._prob_start = "./persistence/prob_start.py" self._prob_emit = "./persistence/prob_emit.py" self._prob_trans = "./persistence/prob_trans.py" self._init_ds() def _init_ds(self): for state in self._state_list: self._state_transfer_count[state] = {} for state1 in self._state_list: self._state_transfer_count[state][state1] = 0.0 for state in self._state_list: self._state_pi_count[state] = 0.0 self._state_emit_count[state] = {} self._state_count[state] = 0 def _get_states(self, input_str): outpout_str = [] input_len = len(input_str) if input_len == 0: pass elif input_len == 1: outpout_str.append('S') elif len(input_str) == 2: outpout_str = ['B','E'] else: M_num = len(input_str) -2 M_list = ['M'] * M_num outpout_str.append('B') outpout_str.extend(M_list) outpout_str.append('S') return outpout_str def _output_prob_start(self): start_handler = file(self._prob_start, 'w') for key in self._state_pi_count: ''' if Pi_dic[key] != 0: Pi_dic[key] = -1*math.log(Pi_dic[key] * 1.0 / line_num) else: Pi_dic[key] = 0 ''' self._state_pi_count[key] = self._state_pi_count[key] * 1.0 / self._line_num start_handler.write(self._state_pi_count.__str__()) start_handler.close() def _output_prob_trans(self): trans_handler = file(self._prob_trans,'w') for src_state in self._state_transfer_count: src_state_count = self._state_count[src_state] dst_states_count = self._state_transfer_count[src_state] for one_dst_state in dst_states_count: ''' if A_dic[key][key1] != 0: A_dic[key][key1] = -1*math.log(A_dic[key][key1] / Count_dic[key]) else: A_dic[key][key1] = 0 ''' one_dst_state_count = dst_states_count[one_dst_state] self._state_transfer_count[src_state][one_dst_state] = one_dst_state_count / src_state_count trans_handler.write(self._state_transfer_count.__str__()) trans_handler.close() def _output_prob_emit(self): emit_handler = file(self._prob_emit, 'w') for src_state in self._state_emit_count: src_state_count = self._state_count[src_state] dst_words_count = self._state_emit_count[src_state] for one_dst_word in dst_words_count: ''' if B_dic[key][word] != 0: B_dic[key][word] = -1*math.log(B_dic[key][word] / Count_dic[key]) else: B_dic[key][word] = 0 ''' one_dst_word_count = dst_words_count[one_dst_word] self._state_emit_count[src_state][one_dst_word] = one_dst_word_count / src_state_count emit_handler.write(self._state_emit_count.__str__()) emit_handler.close() def _output_prob_matrixes(self): print("len(word_set) = %s " % (len(self._word_set))) self._output_prob_start() self._output_prob_trans() self._output_prob_emit() def _get_line_words(self, line): word_list = [] for i in range(len(line)): if line[i] == " ": continue word_list.append(line[i]) self._word_set = self._word_set | set(word_list) return word_list def _get_line_states(self, line): segments = line.split(" ") state_list = [] for one_segment in segments: segment_states = self._get_states(one_segment) state_list.extend(segment_states) return state_list def _handle_one_line(self, line): line = line.strip() if not line: return line = line.decode("utf-8", "ignore") word_list = self._get_line_words(line) state_list = self._get_line_states(line) word_len = len(word_list) state_len = len(state_list) if word_len != state_len: print("exception on [line_num = %d][line = %s]" % (self._line_num, line.endoce("utf-8", 'ignore'))) return for i in range(state_len): one_state = state_list[i] one_word = word_list[i] if i == 0: self._state_pi_count[one_state] += 1 self._state_count[one_state] += 1 continue prev_state = state_list[i - 1] self._state_transfer_count[prev_state][one_state] += 1 self._state_count[one_state] += 1 state_emit_count = self._state_emit_count[one_state] if not state_emit_count.has_key(one_word): state_emit_count[one_word] = 0.0 else: state_emit_count[one_word] += 1 def train(self): corpus_handler = file(self._corpus_file) for line in corpus_handler: self._line_num += 1 if self._line_num % 10000 == 0: print(self._line_num) self._handle_one_line(line) corpus_handler.close() self._output_prob_matrixes() if __name__ == "__main__": trainer = WordSegmentTrainer() trainer.train()
test
#!/usr/bin/python #-*-coding:utf-8 import os import sys import pdb class WordSegmentApp: def __init__(self): self._prob_start = "./persistence/prob_start.py" self._prob_emit = "./persistence/prob_emit.py" self._prob_trans = "./persistence/prob_trans.py" self._state_list = ['B', 'M', 'E', 'S'] self._load_models() def _load_model(self, model_file): model_handler = file(model_file, 'rb') return eval(model_handler.read()) def _load_models(self): self._prob_start_data = self._load_model(self._prob_start) self._prob_trans_data = self._load_model(self._prob_trans) self._prob_emit_data = self._load_model(self._prob_emit) def viterbi(self, obs): V = [{}] #tabular path = {} state_list = self._state_list prob_start = self._prob_start_data prob_trans = self._prob_trans_data prob_emit = self._prob_emit_data # init first word gain for y in state_list: #init V[0][y] = prob_start[y] * prob_emit[y].get(obs[0],0) path[y] = [y] # dynamic program to calc every state gain for the rest words for t in range(1,len(obs)): V.append({}) newpath = {} for y in state_list: (prob, state) = max([(V[t-1][y0] * prob_trans[y0].get(y,) * prob_emit[y].get(obs[t],0) ,y0) for y0 in state_list if V[t-1][y0]>0]) V[t][y] = prob newpath[y] = path[state] + [y] path = newpath (prob, state) = max([(V[len(obs) - 1][y], y) for y in state_list]) return (prob, path[state]) def cut(self, sentence): #pdb.set_trace() prob, pos_list = self.viterbi(sentence) return (prob,pos_list) if __name__ == "__main__": app = WordSegmentApp() test_str = u"长春市长春节讲话。" prob,pos_list = app.cut(test_str) print(test_str) print(pos_list) test_str = u"他说的确实在理." prob,pos_list = app.cut(test_str) print(test_str) print(pos_list) test_str = u"毛主席万岁。" prob,pos_list = app.cut(test_str) print(test_str) print(pos_list) test_str = u"我有一台电脑。" prob,pos_list = app.cut(test_str) print(test_str) print(pos_list)
HMM其它应用
Contains all code related to using HMMs to predict stock market prices.
https://github.com/Jays-code-collection/HMMs_Stock_Market
A simple speech recognition using HMM (python)
https://github.com/drbinliang/Speech_Recognition
隐马尔科夫模型python实现简单拼音输入法
https://zhuanlan.zhihu.com/p/25132270
https://github.com/LiuRoy/Pinyin_Demo

 浙公网安备 33010602011771号
浙公网安备 33010602011771号