MySQL笔记(4)---表
1.前言
上一章记录了MySQL中的一些文件组成,以及相关作用和参数配置,本章开始记录深层次的存储结构,以便更好理解MySQL的设计。
2.索引组织表
InnoDB中,表都是根据主键顺序组织存放的,这种方式称为索引组织表。每个表都有一个主键,没有主键会按照一定规则选择或创建主键:
判断表中是否有非空唯一索引,有则为主键,多个按建表时定义顺序的第一个作为主键,这个意思并不是SQL语句的顺序。
没有,自动创建一个6字节的指针,_rowid,通过这个字段可以查看主键(对复合主键无能为力)
3.InnoDB逻辑存储结构
前几章说了InnoDB的一些概念,比如共享表空间ibdata1,单表表空间,页,区等,这里对其逻辑结构进行详细记录说明。
InnoDB的数据被逻辑地存放在一个空间中,称为表空间。表空间又由段(segment)、区(extent)、页(page)组成,页有时也被称为块(block)。
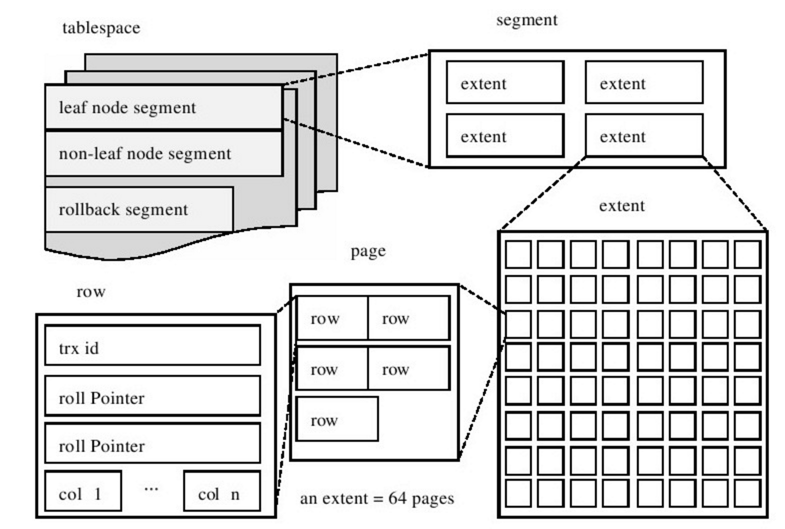
3.1 表空间
用户启动参数innodb_file_per_table,每张表数据单独放到一个表空间。只存放数据,索引和缓冲bitmap页。其他数据如回滚信息,插入缓冲索引页,系统事务信息,二次写缓冲都还是存放在共享表空间中。打开一个手动提交的事务,修改表数据,可以观察到共享表空间大小增大,这就说明undo页存放在共享表空间中,执行回滚并不会变小,只是标记这些undo页可用而已。
3.2 段
表是由段组成的,常见的段有数据段、索引段、回滚段等。InnoDB是索引组织结构,所以数据就是索引,数据段就是B+树的叶子节点,索引段就是B+树的非叶子节点。回滚段较特殊。
3.3 区
区是由连续的页组成的,大小固定1MB,为了保证页的连续性,InnoDB一次会申请4~5个区。默认情况,页大小16KB,1个区里面有64个连续的页。
1.0版本开始有压缩页,每个页大小可以通过参数KEY_BLOCK_SIZE设置为2K、4K、8K,对应区的页数为512,256,128。
1.2版本增加参数innodb_page_size,将默认的页大小设置为4K、8K,页中的数据库不是压缩。区的大小始终是1MB。
在为每张表创建表空间的时候,会发现创建的表默认大小是96KB,区不是固定1MB吗?这是因为在每个段开始的时候,会使用32个页大小的碎片页,使用完了之后才会申请64个页,减少磁盘开销。
3.4 页
InnoDB页是磁盘管理的最小单位,默认大小16kb。1.2版本开始,可以通过参数innodb_page_size将页的大小设置成4K、8K、16K。设置完成,所有页的大小都是innodb_page_size。不能对其再次修改,除非通过mysqldump导入和导出操作产生新的库。
常见的页类型有:
数据页、undo页、系统页、事务数据页、插入缓冲bitmap、插入空闲free列表页、未压缩的二进制大对象页、压缩的二进制大对象页。
3.5 行
InnoDB存储引擎是面向列的,也就是说数据是按行进行存放的。每页最多放16KB / 2~200行的数据,即7992行。
4. InnoDB行记录格式
页中保存一行行的数据,以链表的形式存储。在1.0版本之前,提供了Compact和Redundant两种格式来存放记录,后者是为了兼容之前版本保留的。通过SHOW TABLE STATUS LIKE ”table_name"查看当前表使用的格式。row_format属性表示当前使用的行记录结构。创建表的时候可以指定:create table name engine=xxx row_format=xxx
4.1 Compact格式
MySQL5.0版本引入,目标是高效地存储数据。简单来说,一个页存放的数据越多,性能越高。具体格式如下:

变长字段长度:列的长度小于255,使用1字节存放,大于255,使用2字节。因为varchar最大65535。是按列顺序的逆序存放其长度的。
NULL标志位:表明列中是否有NULL值。有为1。1个字节
记录头信息:5个字节,40位
1~2:未知
3:该行是否已被删除
4:为1,如果该记录是预先被定义为最小的记录
5~8:该记录拥有的记录数
9~21:索引堆中该条记录的排序记录
22~24:记录类型:000普通,001B+树节点指针,010 Infimum, 011 Supermum, 1xx保留
25~40:页中下一条记录的相对位置。(这个就是链表的原因)
最后就是实际列的数据了,NULL不占空间,只有NULL标志位。还有两个隐藏列:事务ID列和回滚指针列,分别是6字节和7字节。没有主键,会产生rowid,6个字节。在记录头后面,列数据前面。
char类型空间未用完,会填充0x20。
4.2 Redundant行记录格式

偏移列表,同样是按字段列的逆序放置。长度小于255,用1字节表示,大于255用2字节表示。与长度列表不同的是,这里定位的是偏移量,后者的偏移量等于前者的+前者保存的长度
头信息:6个字节,48位
1~2:未知
3:该行是否删除
4:为1,如果该记录是预先被定义为最小的记录
5~8:该记录拥有的记录数
9~21:索引堆中该条记录的索引号
22~31:记录中的列数量
32:偏移列表为1字节还是2字节
33~48:下一条记录的位置
列数量使用了10个字节记录,所以mysql支持的最大列数是2^10-1=1023列。
这种格式varchar的NULL是不占空间的,但是char需要占用空间。
4.3 行溢出数据
InnoDB可以将一条记录中的某些数据存储在数据页之外,比如BLOB、LOG这类大对象列。BLOB可以不将数据放入溢出页面,但是varchar列数据却也可能被放在溢出数据。
varchar虽然使用2个字节记录长度,理论上可以存放65535字节,但是实际创建的时候不支持这么大的,因为还有其他开销,最大长度应该是65532.(2个字节记录长度,1个字节用于NULL)
另外要注意的是65532针对的字符类型是Latin1的,如果是GBK或者UTF8又会失败。
VARCHAR(N)指的是字符的长度,而最大支持是指字节,所以GBK的话大概是32766,UTF-8是21845。超过这个值且数据库SQL_MODE没有设置成严格,会警告,并自动转为text类型。
此外,VARCHAR指的是一条记录中所有VARCHAR字段的总长度限制。比如一张表里有3个varchar字段,每个长度22000,总长度就660000了,这样创建是会失败的。
InnoDB中一页是16KB,16384字节,怎么放下varchar呢。一般情况数据是存放在页类型为B-tree node中,但是发生行溢出时,数据放在页类型为Uncompress BLOB页中。前面一部分空间存放数据,后面通过一个偏移量指向溢出页。问题来了,多长的varchar会保存在页中,从多长开始保存在BLOB页中:
首先要清楚页的存储结构是B+树,如果只能存放一条记录,那么就没有意义了,所以一条记录超过页大小的时候,就会被放入溢出页中。如果能放入两条记录的话,大小阈值是多少才会被放入BLOB中呢,大概是8098。两条这么长的varchar记录依旧会在一页之中。另外,Text和BloB的数据类型也不是总是放在Uncompressed BLOB Page中的,和之前一样,要保证一个页存放两条记录。
4.4 Compressed和Dynamic行记录格式
1.0版本开始引入新的文件格式,以前的Compact和Redundant格式称为Antelope文件格式,新的是Barracuda:Compressed和Dynamic两种格式。
新的格式对于存放BLOB中的数据采取了完全的行溢出方式,只存放20个字节的指针,数据都放在Off Page中,之前的格式会存放768个前缀字节。Compressed行记录格式的另一个功能就是,存储在其中的行数据会以zlib的算法进行压缩,因此对于BLOB、TEXT、VARCHAR这类大长度类型的数据能够进行有效的存储。
4.5 CHAR的行结构存储
从4.1开始CHR(N)中的N指的是字符的长度,不是字节的长度了。因此CHAR类型的内部存储可能不是定长的数据。所以在内部将CHAR也视为变长字符类型,这就意味着变长长度列表中会记录CHAR数据类型的长度,对于未占满长度的字符还是填充0x20.
5.InnoDB数据页结构
数据页由7个部分组成:File Header文件头、Page Header页头、Infimum和Supermum Records、User Record行记录、Free Space空闲空间、Page Directory页目录、File Trailer文件结尾信息。其中头尾大小是固定的,分别是38、56、8字节,这些空间用来记录一些该页的信息,如checksum,数据页在B+树索引的层数等。其它的是实际的行记录存储空间,是动态的。
5.1 File Header
由8个部分构成,共38个字节:
FIL_PAGE_SPACE_OR_CHECKSUM 4字节 mysql4.0.14之前,该值为0,后面代表checksum的值
FIL_PAGE_OFFSET 4字节 表空间页的偏移量。如独立表空间大小为1GB,该页16KB,一共65536个页,这个就表示该页在所有页中的位置。若表空间ID是10,那么searchKey(10,1)就是查找表中的第二个页。
FIL_PAGE_PREV 4字节 当前页的上一个页,B+树决定了叶子节点必须是双向列表
FIL_PAGE_NEXT 4字节 当前页的下一个页
FIL_PAGE_LSN 8字节 该页最后被修改的日志序列位置LSN
FIL_PAGE_TYPE 2字节 InnoDB存储引擎页类型,0x45BF代表存放的是页数据
0x0002 undo log 页
0x0003 索引节点
0x0004 insert buffer空闲列表
0x0000 新分配的页
0x0005 insert buffer bitmap
0x0006 系统页
0x0007 事务系统数据
0x0008 File Space Header
0x0009 扩展描述页
0x000A BLOB页
FIL_PAGE_FILE_FLUSH_LSN 8字节 该值仅在系统表空间的一个页中定义,代表文件至少被更新到了该LSN值。独立表都是0
FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID 4字节 从MySQL4.1开始该值表示页属于哪个表空间。
5.2 Page Header
该部分用来记录数据页的状态信息,由14个部分组成,共占用56字节。
PAGE_N_DIR_SLOTS 2 在Page Directory(页目录)中Slot(槽)数,‘4.4.5 Page Directory’小节中会介绍
PAGE_HEAP_TOP 2 堆中第一个记录的指针,记录在页中是根据堆形式存放的
PAGE_N_HEAP 2 堆中的记录数。一共占用2字节,但是第15位表示行记录格式
PAGE_FREE 2 执向可重用空间的首指针
PAGE_GARBAGE 2 已删除记录的字节数,即行记录结构中delete flag为1的记录大小的总数
PAGE_LAST_INSERT 2 最后插入记录的位置
PAGE_DIRECTION 2 最后插入的放向,可能是0x01 left、0x02 right、0x03 same rec、0x04 same page、0x05 no direction
PAGE_N_DIRECTION 2 一个方向连续插入记录的数量
PAGE_N_RECS 2 该页中记录的数量
PAGE_MAX_TRX_ID 8 修改当前页的最大事务ID,注意该值仅在Secondary Index中定义
PAGE_LEVEL 2 当前页在索引树中的位置,0x00代表叶节点,即叶节点总是在第0层
PAGE_INDEX_ID 8 索引ID,表示当前页属于哪个索引
PAGE_BTR_SEG_LEAF 10 B+树数据页非叶节点所在段的segment header。注意该值仅在B+树的ROOT页定义
PAGE_BTR_SEG_TOP 10 B+树数据页所在段的segment header.注意该值仅在B+树的Root页定义
5.3 Infimum和Supermum Record
每个数据页由两个虚拟的行记录,用来限定记录的边界。Infimum记录是比该页中任何主键都要小的值,Supermum是比任何可能大的值都大的值。在页创建的时候被建立,并且不会被删除。
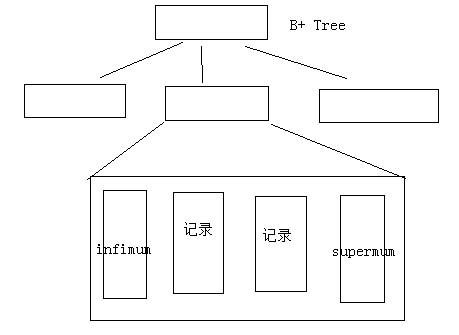
5.4 User Record和Free Space
User Record就是实际存储记录的内容。
Free Space就是空闲空间,链表结构。
5.5 Page Directory
页目录保存了记录的相对位置,这里放的是页的相对位置,不是偏移量。这些记录指针有时被称为槽或者目录槽。不是每个记录都有槽的,这是一个稀疏目录,一个槽中可能包含多个记录。在槽中按照索引键值顺序存放,这样可以使用二叉查找迅速找到记录的指针,但是由于是稀疏目录,所以只能查到一个初略的结果,还需要通过reocorder header中的next_record来继续查找。
B+树不能定位到具体记录,只能定位到记录所保存的页,然后将页加载到内存,通过Page Directory进行二叉查找定位到具体记录。
5.6 File Tailer
这个用于校验数据是否完整写入磁盘,占用8个字节,前4个表示checksum,后四个与File Header的FIL_PAGE_LSN相同。
该校验会对系统有些开销,innodb_checksums可以关闭这个校验。
MySQL5.6.6版本开始新增了参数innodb_checksum_algorithm,用来控制检测checksum的算法,默认crc32。可设置的有:innodb、crc32、none、strict_innodb、strict_crc32、strict_none。
innodb算法是用于兼容之前版本的checksum检测方式,crc32是5.6.6版本引进的新的checksum算法,性能比innodb高。用strict算法保存,低版本的MySQL库无法读取这些页。none不检测。启动strict_crc32是最快的,他不会对innodb和crc32算法进行两次检测,但是低版本无法使用。
6. Named File Formats机制
随着存储引擎的发展,新的页数据结构有时用于支持新的功能特性。比如前面提到的表压缩功能等。这些数据结构和之前的版本并不兼容,所以在1.0版本开始,InnoDB存储通过Named File Formats机制来解决不同版本下页结构兼容性问题。
1.0版本之前的称为Antelope,之后的为Barracuda,新版的文件格式总是包含旧版的内容。SHOW VARIABLES LIKE ’innodb_file_format'
7 约束
7.1 数据完整性约束
关系型数据库本身保证存储数据的完整性,提供了约束机制,通常有3种形式:
1.实体完整性:保证表中有一个主键,可以定义Primary Key,Unique Key。
2.域完整性:保证数据每列满足特定条件。以下途径可以保证:选择合适的数据类型保证数据值满足条件,外键约束,编写触发器,用DEFAULT。
3.参照完整性:保证两张表之间的关系,外键。
InnoDB提供了以下几种约束:
Primary Key
Unique Key
Foreign Key
Default
NOT NULL
7.2 约束的创建和查找
创建方式:
表建立时定义
ALTER TABLE命令创建约束
对于唯一索引约束Unique Key,用户还可以通过命令CREATE UNIQUE INDEX来创建。
对主键约束,名为PRIMARY,对于Unique Key约束,约束名和列名一样。Foreign Key约束似乎会有一个比较神秘的默认名称。
7.3 约束和索引的区别
创建约束的方法不就是创建索引吗,有什么区别?约束是一个逻辑的概念,用来保证数据的完整性。索引是一个数据结构,有逻辑的概念,也代表着物理存储方式。
7.4 对错误数据的约束
在某些默认设置下,MySQL数据库允许非法的或不正确的插入数据或更新,或者在内部转换成一个合法的值,如向NOT NULL字段插入一个NULL值,数据库会将其改为0再进行插入。这个是通过设置sql_mode完成的。SET sql_mode = "STRICT_TRANS_TABLES",这个类型对输入进行了约束。
7.5 ENUM和SET约束
MySQL不支持传统的CHECK约束,但是可以通过ENUM和SET类型解决部分需求。比如表上有一个性别类型,范围只有male或者female,这个时候可以使用ENUM约束。创建表的时候sex字段为ENUM('male','female')。只支持离散数据类型,对连续的无能为力。
7.6 触发器约束
MySQL5.1开始触发器相对稳定。CREATE TRIGGER,只有super权限的用户才能执行。最多可以为一个表创建6个触发器,即分别为INSERT、UPDATE、DELETE的before和after各定义一个。当前MySQL只支持FOR EACH ROW的触发方式,即按每行记录进行触发。
CREATE
[DEFOMER = {user | CURRENT_USER}]
TRIGGER trigger_name BEFORE | AFTER INSERT|UPDATE|DELETE
ON table_name FOR EACH ROW trigger_stmt。
通过触发器可以实现一些不支持的特性,比如CHECK约束,物化视图,高级复制,审计等特性。比如买东西,每次都是减的,但是如果用户输入了一个负数,就变成加了。这个时候就可以通过触发器来完成这个判断了。
7.7 外键约束
外键用来保证参照完整性,MySQL数据库的MyISAM引擎本身不支持外键,对外键的定义只是一个注释作用。
[CONSTRAINT [symbol]] FOREIGN KEY
[index_name] (index_col_name, ...)
REFERENCES tbl_name (index_col_name,...)
[ON DELETE reference_option]
[ON UPDATE reference_option]
reference_option: RESTRICT|CASCADE|SET NULL| NO ACTION
CASCADE表示父表发生DELETE或UPDATE操作时,对应子表数据也进行DELETE或UPDATE操作。
SET NULL 表示父表发生DELETE或UPDATE操作时,子表设置NULL
NO ACTION表示子表有相关联记录,抛出异常,不允许操作
RESTRICT表示父类发生DELETE或UPDATE操作时,抛出错误,不允许这类操作。
Oracle数据库有一种延时检查的外键约束,检查在SQL执行之后进行,但MySQL都是即时检查,所以NO ACTION和RESTRICT没区别。默认使用RESTRICT。
MySQL会自动为外键创建索引,避免死锁问题。
8 视图
MySQL中视图是一个命名的虚表,它由一个SQL查询来定义,可以当做表使用。与持久表不同,视图没有实际的物理存储。
8.1 视图的作用
视图的主要作用之一是用做一个抽象装置,程序本身不需要关心基表的结构,只需要按照视图定义来取数据或更新数据,一定程度上起到了安全层的作用。5.0版本开始支持视图:
CREATE [OR REPLACE]
[ALGORITHM = { UNDEFINED | MERGE | TEMPTABLE}]
[DEFINER = {user | CURRENT_USER }]
[SQL SECURITY { DEFINER | INVOKER }]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
虽然视图是虚拟表,但是可以对其进行更新,本质上就是更新基本表。可能更新失败,带上WITH CHECK OPTION会失败的时候抛出异常。
8.2 物化视图
Oracle支持物化视图,即该视图不是基于基表的虚表,而是根据基表实际存在的实表,存储在非易失的存储设备上。
物化视图用于预先计算并保存多表的链接或者聚集等耗时较多的SQL操作结果。这样,执行复杂查询时,就可以避免进行这些耗时的操作。Oracle中创建方法有两种:
BUILD IMMEDIATE:默认方式,在创建的时候就生成数据
BUILD DEFERRED:根据需要生成数据
查询重写就是会自动判断是否能通过查询物化视图得到最终结果,如果可以就避免了复杂的SQL操作。
物化视图的刷新是指基表发生了DML操作后,物化视图何时采用哪种方式和基表进行同步:
ON DEMAND:在用户需要的时候进行刷新
ON COMMIT:对基表的操作提交时同步进行
刷新的方式有4种:
FAST:增量刷新,只刷新自上次刷新后的修改
COMPLETE:全量刷新
FORCE:刷新的时候会去判断,能快速刷新使用FAST,不能使用COMPLETE.
NEVER:不刷新
MySQL不支持物化视图,可以自己实现,比如定时将一个表导入另一个表。这个就是ON DEMAND类型。这自然是COMPLETE刷新方式,要实现FAST就比较复杂了,统计上次刷新的位置。实现ON COMMIT就复杂了,可以通过触发器。
查询重写功能MySQL就无能为力了,需要在应用端进行控制。
9 分区表
9.1 分区概述
分区功能不是在存储引擎层完成的,所以InnoDB、MyISAM、NDB等都支持,但是也有不支持的,比如:CSV、FEDORATED、MERGE等。
MySQL5.1版本添加了对分区的支持。这个过程是一个将表或索引分解为多个更小、更可管理的部分。从逻辑上讲,只有一个表或者一个索引,但是在物理上这个表或者索引可能由数十个物理区组成,这样就可以对各个部分处理的能力了。
MySQL支持的分区类型是水平分区,不支持垂直分区。分区是局部分区索引,一个分区中既存放了数据又存放了索引,全局分区指的是数据存放在各个分区,但是索引存放在一个对象中。目前MySQL不支持全局分区。通过SHOW VARIABLES LIKE '%partition%'查看是否启用了分区。也可以使用SHOW PLUGINS查看。
分区不一定会让数据库更快,可能会提高某些SQL的性能,但是分区主要是用于数据库的高可用性管理。在OLTP应用中,对分区的使用应该非常小心。
MySQL数据库支持的分区类型有:
RANGE分区:行数据基于属于一个给定连续区间的列值被放入分区。MySQL5.5开始支持RANGE COLUMNS的分区
LIST分区:和RANGE分区类型,只是LIST分区面向的是离散的值。MySQL5.5开始支持LIST COLUMNS分区
HASH分区:根据用户自定义的表达式的返回值来进行分区,返回值不能为负数。
KEY分区:根据MySQL数据库提供的哈希函数进行分区。
不论创建什么类型的分区,如果表中存在主键或者唯一索引时,分区列必须是唯一索引的一个组成部分。比如唯一索引是a,b,创建PARTITION BY hash(c)就不行,c不是a,b的一个组成部分。如果表没有主键,唯一索引,可以指定任何一个列为分区列。
分区的目的是将数据分割,查询的范围就小了,这样速度就快了,所以要考虑表执行的SQL是否适合分区,万一分区却扫描了全表,那么就得不偿失了。
9.2 分区类型
9.2.1 RANGE分区
Partition By Range(id) (
Partition p0 values less than (10),
Partition p1 values less than (20)
);
id小于10的插入p0,大于等于10,小于等于20的插入p1。
启用分区后,物理磁盘上就不是一个ibd文件了,会有各个分区的ibd文件。
另外,由于没有定义大于等于20的情况,插入这个会抛出异常。对于这种情况可以写成
ALTER TABLE t ADD PARTITION( partition p2 values less than maxvalue);
RANGE分区主要用于日期列的分区,例如对于销售类的表,可以根据年来分区存放销售记录。Partition by range (year(date)) (partition p2008 values less than(2009));
这样的好处在于我们删除08年的数据只需要:alter table sales drop partition p2008;
另一方面,查询08年的数据也只会查这个分区。EXPLAIN PARTITIONS,但是如果查询08和09年的就会跨分区了,这个是不好的操作。
如果按月进行分区,实际上查询并不会只查那个月的,优化器不一定会根据分区选择。因为对RANGE分区的查询,优化器只对YEAR()、TO_DAYS()、TO_SECONDS()、UNIX_TIMESTAMP()这类函数进行优化选择,所以如果按月查询,要写成:
Partition By range(To_DAYS(date)) (
Partition p201001 values less than (to_days('2010-02-01'))
);
9.2.2 LIST 分区
LIST分区和RANGE很相似,但是值是离散的,而不是连续的。range中使用values less than,list中使用values in,毕竟值是离散的。如果插入的值不在定义中,也会抛出异常。
此外对于多行插入中存在未定义的值,MyISAM会将之前的数据都插入,遇到未定义的之后的不插入。InnoDB都不插入。
partition by list(b) (
partition p0 values in (1,2,3,4,5)
);
9.2.3 hash分区
hash分区的目的是将数据均匀的分布到预先定义的各个分区中,保证各分区的数据量大致都一样。hash分区中,数据库自动完成这个操作。
Partition by hash(expr) expr是一个返回整型的表达式,后面还要跟上一个partitions num,表示分多少个区。
MySQL还支持一种LENEAR HASH。优点在于增加、删除、合并、拆分分区更加快捷。缺点在于各分区的数据分布可能不大均衡。
9.2.4 KEY分区
KEY与HASH相似,不同在于HASH分区使用用户定义的函数进行分区,KEY分区使用MySQL数据库提供的函数进行分区。对于NDB Cluster引擎,使用MD5函数分区。对于其他引擎,使用内部的hash函数。
9.2.5 COLUMNS分区
前面介绍的分区条件都要是整型,不是整型要通过函数转变成整型,比如YEAR等。COLUMNS分区可以直接使用非整型的数据进行分区,分区根据类型直接比较而得。
COLUMNS分区支持以下的数据类型:
所有的整型类型:FLOAT和DECIMAL不支持
日期类型:DATE和DATETIME,其余不支持
字符串类型:如CHAR、VARCHAR、BINARY、VARBINARY。BLOB和TEXT不支持。
9.3 子分区
子分区是在分区的基础上再进行分区,也称复合分区。SUBPARTITION。
子分区要注意:
1.每个子分区的数量必须相同
2.要在一个分区表的任何分区上使用SUBPARTITION来明确定义任何子分区,就必须定义所有的子分区。
每个SUBPARTITION子句必须包括子分区的一个名字。
子分区不能重名。
9.4 分区中的NULL值
mysql允许使用NULL值做分区,把NULL看做比所有非NULL都小的值。这个操作和order by操作是一样的。所以对不同的分区类型,对NULL的操作也不同。
range分区中,会放在最左边的分区,
list分区,要显示指出放在哪个分区,PARTITION p0 VALUES in (NULL)
hash和key分区和前两个不同,任何函数都将含有NULL的记录返回为0.
9.5 分区和性能
使用分区不一定会带来查询速度的提升,要明确其使用环境。
数据库应用分为两类:OLTP(在线事务处理),比如Blog、电子商务、网络游戏。
OLAP(在线分析处理),比如数据仓库、数据集市。
对后者会有性能的提高,因为大部分查询要频繁的扫描一张很大的表。
对于OLTP的应用,分区就要非常小心了。通常只需要返回几条记录,对B+树而言,大概需要2~3次磁盘IO,所以本身可以很好完成操作,不需要分区支持,设计不好反而会带来严重的性能问题。
9.6 在表和分区间交换数据
MySQL5.6开始支持ALTER TABLE ... EXCHANGE PARTITION语法,支持分区的数据与非分区的表中数据进行交换。如果非分区表数据为空,等于将分区的数据移动到非分区。若分区表中数据为空,等于将外部表数据导入分区中。
满足以下条件才行:
表和分区表有相同的表结构,但表中不能有分区
非分区表中的数据必须在交换的分区定义内
被交换的表不能含有外键,或者其他的表含有对该表的外键引用
用户处理ALTER INSERT 和CREATE权限外,还需要DROP权限
还要注意:
使用过程中,触发器不会被触发
AUTO_INCREMENT列会被重置。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号