MySQL笔记(2)---InnoDB存储引擎
1.前言
本节记录InnoDB的相关知识点。
2.InnoDB存储引擎简介
2.1版本
MySQL5.1开始,允许用动态方式加载引擎,这样存储引擎的更新可以不受MySQL数据库版本的限制。下面是各个InnoDB版本功能对比:
老版本的InnoDB 支持ACID、行锁设计、MVCC
InnoDB 1.0.x 也称为InnoDB Plugn 增加compress和dynamic页格式
InnoDB 1.1.x 增加了Linux AIO、多回滚段
InnoDB 1.2.x 增加全文索引支持,在线索引添加
2.2 体系架构
InnoDB采取多线程模型,每个线程负责处理不同的任务。另外,其由多个内存块构成一个大的内存池,主要用于:维护内部数据结构,缓存磁盘上的数据,方便快速地读取,同时在对磁盘文件的数据修改之前在这里缓存,重做日志缓冲等等。
2.2.1 各个线程的主要作用
1.Master Thread
核心的后台线程,主要将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新,合并插入缓冲,UNDO页的回收。
2.IO Thread
使用AIO来处理IO请求,这样可以极大提高数据库的性能。IO线程主要负责处理IO请求的回调处理。
1.0版本的InnoDB之前共有4个IO Thread,分别是write、read、insert buffer和log IO thread。linux平台下不能修改,windows可以通过参数innodb_file_io_threads来增大IO Thread
1.0.x版本开始,read、write增大到4个,使用innodb_read_io_threads和innodb_write_io_threads参数来设置。
SHOW VARIABLES LIKE “innodb_%io_threads"
SHOW ENGINE INNODB STATUS 查看线程状态
3.Purge Thread
事务被提交后,其所使用的undolog可能不再需要,因此需要这个线程进行回收已使用并分配的undo页。
1.1版本前,purge操作是在master线程中进行的,之后减轻master thread工作,提供CPU的使用率,放入了独立的线程中进行。
1.2版本开始,支持多个Purge Thread,目的是加快undo页的回收,同时由于Purge Thread需要离散地读取undo页,这样也能更进一步利用磁盘的随机读取性能。设置innodb_purge_threads。SHOW VARIABLES LIKE “innodb_purge_threads”查看相关参数。
4.Page Cleaner Thread
这个是在1.2版本中引入的,作用是将之前版本中脏页的刷新操作都放入到单独的线程中完成。目的是为了减轻原Master Thread的工作及对用户查询线程的阻塞,进一步提高InnoDB存储引擎的性能。
2.2.2 InnoDB的缓冲池技术
InnoDB是采取磁盘存储的方式,众所周知磁盘和CPU之间的效率差的太多,所以会使用到内存缓存数据,这个就是缓冲池。
InnoDB将记录按照页(一个页16KB)的方式进行管理,在数据库首次读取页操作的时候,首先从磁盘读取页放入缓冲池,这个过程称为FIX,下次读取同一个页时,首先判断页是否在缓冲池中。若在缓冲池中,称为缓存命中,直接读取,否则读取磁盘上的页。修改数据,首先修改的是缓冲池中的页,后续会以一定频率刷新到磁盘上,这个不是每次都触发,使用了一种Checkpoint机制。
缓冲池大小影响数据库的整体性能,32操作系统最多设置为3G,建议使用64位系统。
设置innodb_buffer_pool_size来设置。SHOW VARIABLES LIKE “innodb_buffer_pool_size"
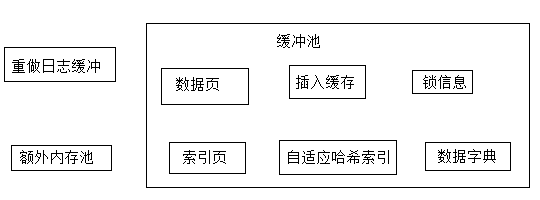
上图是一个基本的缓冲池构成,在1.0.x版本开始,支持多个缓冲池实例,每个页根据哈希值分配到不同实例中,减少数据库内部资源竞争。innodb_buffer_pool_instances,默认为1。
SHOW ENGINE INNODB STATUS可以观察缓冲池状态。
线程和缓存的详细描述:
上述内容描述了InnoDB的一个基本设计,将磁盘数据以页的形式读取到内存中,修改先修改内存,再刷新到磁盘。这个操作虽然简单,但是实现起来涉及到内存回收,并发处理等内容,下面围绕这些问题,描述一下InnoDB是如何解决的。
1.内存管理(LRU、Free、Flush)
LRU(最近最少使用算法)进行内存管理。内存不是无限大的,有新数据进来满了之后就有旧的数据需要处理。这里有篇介绍LRU的文章可以参考一下:这里。
这个算法就是用于淘汰最不常使用的页,但是不同在于其加入了midpoint位置,新读取到的页不是直接放入首部,而是放入LRU列表的midpoint位置,默认在LRU列表长度的5/8处,通过参数innodb_old_blocks_pct控制。放在中间的原因在于有些操作可能会访问很多的页,比如全表扫描,如果放在首部,很有可能将热点页刷掉。InnoDB使用另一个参数进一步管理LRU列表:innodb_old_blocks_time,用于表示页读取到mid位置后需要等待多久才会放入LRU列表的热端。
LRU列表是一个用于缓存热点数据的一个队列,里面没有任何页。页都是放在Free列表中。需要页的时候,从Free列表中获取空闲页,加入LRU列表。没有就开始进行LRU淘汰尾端的页,将该内存分配给新的页。由old到new的过程,称之为page made young,因innodb_old_blocks_time导致没有变成new的称为page not made young。
SHOW ENGINE INNODB STATUS可以观察缓存状态,buffer pool hit rate就是缓冲命中,为100%就是运行良好,小于95%的就需要观察是否有全表扫描造成的LRU列表污染。
1.0版本之后支持压缩页,16KB的页压缩到1、2、4、8,LRU列表也有对应的改变。非16KB的页,通过unzip_LRU列表进行管理。具体的管理步骤是:
假设申请一个4KB的页。检查unzip_LRU列表,是否有可用的,有就直接使用。
没有,就找有没有8KB可用的,有就分成2个4KB使用,存入unzip_LRU列表
没有,就向LRU列表申请一个16KB的页,将其分成1个8KB,2个4KB存入unzip_LRU列表。
LRU列表的页被修改后,称为脏页,通过checkpoint机制将脏页保存到磁盘。Flush列表就是脏页列表,它也被LRU列表持有,互相不影响。
2.2.3 重做日志缓冲
上面的图也看见了这个缓冲不在缓冲池里面,InnoDB会将重做日志信息先放入到这个缓冲区,再按一定频率刷新到重做日志文件。一般不需要很大,因为一般1秒刷新一次。通过innodb_log_buffer_size控制,默认8MB。
刷新条件如下:
Master Thread会每一秒刷新到重做日志文件
每个事务提交时会将重做日志缓冲刷新到重做日志文件
当重做日志缓冲池剩余空间小于1/2时,重做日志缓冲刷新到重做日志文件。
2.2.4 额外的内存池
InnoDB存储引擎中,对内存的管理是通过一种内存堆的方式进行的。对一些数据结构本身的内存进行分配时,需要从额外的内存池中进行申请,当该区域的内存不够时,会从缓冲区申请。
2.3 Checkpoint技术
有脏数据的时候不会立刻刷新到磁盘上,这样做太频繁,所以需要采取一种机制来做这件事情。又因为如果在写入磁盘的时候宕机了,那么数据库就被破坏了,无法恢复。所以事务数据库目前普遍采用Write Ahead Log策略,提交事务时,先写重做日志,再修改页,修改页之后事务才算成功,这样日志已经记录好了。宕机时通过重做日志来完成数据恢复。
如果重做日志可以无限增大,缓冲池足够大,那么就不需要刷新数据到磁盘,因为可以通过重做日志来恢复,然而实际上受到了限制。
Checkpoint主要解决以下问题:
缩短数据库的恢复时间
缓冲池不够用时,将脏页刷新到磁盘
重做日志不可用时,刷新脏页
数据库宕机时,不需要重做所有的日志,因为之前的页已经刷新到磁盘,只需对这个节点之后的重做日志进行恢复。
LRU淘汰的页是脏页的时候,需要强制执行Checkpoint,否则再次查询的时候,数据就不对了。
重做日子不可用是因为对重做日志都是循环使用的,不是无限增大,因为可以覆盖不需要的部分,即checkpoint之前的。若要让重做日志能够使用,强制执行checkpoint,使得重做日志可以覆盖。
InnoDB通过LSN(Long Sequence Number)来标记版本的。而LSN是8字节的数字,单位是字节。每页都有LSN,重做日志也有,Checkpoint也有。
Checkpoint产生的条件很复杂,在InnoDB中,有两种Checkpoint:
Sharp Checkpoint 关闭时,刷新回磁盘,innodb_fast_shutdown=1
Fuzzy Checkpoint 刷新一部分回磁盘。
1.Master Thread会以每秒或者每10秒的速度从缓冲池的Flush列表中刷新一定比例的页回磁盘,异步操作。
2.LRU列表需要100个左右的空闲页供使用,没有就会移除尾端的,如果是脏页就需要刷新回磁盘。
3.重做日志不可用时,刷新一定比例页回磁盘,从flush列表中选择。假设重做日志文件大小为1GB,超过75%的空间不可用的时候会触发AsyncFlush,腾出空间,超过90的时候会触发SyncFlush。后者显然不常见,因为前者先被触发。AsyncFlush会阻塞发现日志空间不够的用户线程,SyncFlush会阻塞所有用户线程。
4.脏页数据过多也会触发刷新操作,由innodb_max_dirty_pages_pct参数控制。
3.Master Thread工作方式
1.0.x版本之前:
线程优先级最高,内部有多个循环组成:主循环、后台循环、刷新循环、暂停循环,会根据运行状态进行挑选使用哪个循环。
主循环中包含每秒操作和每10秒的操作:
每秒操作:
1.日志缓冲刷新到磁盘,即使事务没有提交(总是)
2.合并插入缓存(可能,前一秒IO次数是否小于5,小于5压力小,可以执行合并插入缓存操作)
3.至多刷新100个脏页到磁盘(可能,判断脏页比例,超过90% innodb_max_dirty_pages_pct)
4.如果没有用户活动,切换到后台循环(可能)
每10秒:
1.刷新100个脏页到磁盘(可能,10秒内IO是否小于200)
2.合并最多5个插入缓冲(总是)
3.将日志缓冲刷到磁盘(总是)
4.删除无用的undo页(总是)
5.刷新100个或者10个脏页到磁盘(总是,超过70%的脏页,100个,其它的10个)
后台循环会执行以下操作:
1.删除无用的Undo页(总是)
2.合并20个插入缓冲(总是)
3.跳回到主循环(总是)
4.不断刷新100个页直到符合条件(可能,跳转到flushloop中完成)
1.2.x版本之前的MasterThread:
之前的IO判断是硬编码进行判断,不符合现代磁盘的发展,所以采取了innodb_io_capacity来表示磁盘的IO吞吐量,默认200。
合并插入缓冲时,数量是他的5%,刷新脏页时,数量是innodb_io_capacity。
另一个问题在于innodb_max_dirty_pages_pct是90比例太高,内存很大的时候,刷新脏页速度降低。1.0版本开始,这个值变成了75,另外新加了一个参数innodb_adaptive_flushing,自适应地刷新。full purge操作时,最多回收20个undo页。1.0开始可以通过参数innodb_purge_batch_size进行设置。
1.2.x版本的MasterThread:
这个版本又进行了优化,对脏页的刷新交给了Page Cleaner Thread。
4. InnoDB的关键特性
4.1 插入缓冲
在innodb存储引擎中,主键是行唯一的标识符,通常插入顺序是按照主键递增顺序进行的。因此插入聚集索引(Primary Key)一般是顺序的,不需要磁盘随机读取。因此此类情况下的插入操作,速度是非常快的。但是不是所有的都是聚集索引,更多情况下,一个表上有多个非聚集的辅助索引,比如一个字符串的字段作为索引。数据的存放还是按主键进行顺序存放,但是对非聚集索引叶子节点的插入不再是顺序的了。随机读取导致插入操作性能下降,B+树的特性决定了非聚集索引插入的离散性。
Innodb开创性的设计了Insert Buffer,对于非聚集索引的插入或是更新操作,不是每一次直接插入到索引页中,而是先判断插入的非聚集索引是否在缓冲池中,如果在直接插入,不再放入一个insert buffer。然后按一定频率进行insert buffer和辅助索引子节点的merge操作,这样大大提高了对于非聚集索引插入的性能。
insert buffer使用要满足两个条件:1.索引是辅助索引 2.索引不唯一。不唯一在于插入缓冲的时候不需要去查找索引页来判断插入的记录唯一性,如果去查找又是离散读取,失去了意义。
写密集的情况,可能会占用过多的缓冲池内存。
Change Buffer:
1.0版本引入了ChangeBuffer,可以对INSERT、DELETE、UPDATE都进行缓冲。对应的是Insert Buffer、Delete Buffer、 Purge Buffer。
适用对象也是非唯一的辅助索引。Update分为两个过程,将记录标记删除,真正将记录删除。
1.2版本开始使用innodb_change_buffer_max_size来控制其使用内存的大小,25意味着最多使用1/4的缓冲池内存空间,最大有效值是50。
内部实现:
insert buffer是一个B+树,存放在共享表空间中,默认也就是ibdata1中。试图通过独立表空间ibd文件恢复表中数据,往往会check table失败,因为辅助索引中的数据可能还在insert buffer中,即在共享表空间中,需要进行repair table操作重建表上所有的索引。
非叶子节点存放了search key,9个字节:前4个是space,记录插入的表空间id,marker一个字节,兼容老版本的insert buffer,offset表示页所在的偏移量。
如果一个辅助索引要插入到非聚类索引页,不在缓存中,就会构建一个search key,标识这个页的位置,接下来查询insert buffer这个B+树,将记录插入这个树节点中。叶子节点的记录不是直接将待插入的记录插入,而是构造一个13个字节的内容,前9个和search key含义相同,2个字节整数存放记录进入insert buffer的顺序。
为了保证merge成功,要记录一下索引页中可用空间,insert buffer bitmap,用来追踪16384个辅助索引页,256个区。每个insert buffer bitmap都在16384个页的第二个页中。
Merge Insert Buffer:
合并操作可能发生在:
辅助索引页读取到缓冲池时
Insert Buffer bitmap追踪到辅助索引页没有可用空间。
Master Thread操作。
SELECT操作会检查是否有记录在insert buffer中,有就会将B+树中的记录插入到辅助索引页中。因为只用了一次操作就合并了对该页的多次操作记录,所以性能会提升。
Insert Buffer Bitmap用来追踪每个辅助索引页的可用空间,并且至少有1/32页的空间。若插入记录时发现之后可用空间小于这个值,会强制进行合并操作,强制读取辅助索引页,将记录及待插入记录插入到辅助索引页中。
4.2 两次写
insert buffer提升的是性能,双写就是保证可靠性了。
数据库宕机时,如果正在将页写入某个页到表中,16kb,写了4kb,那么数据就丢失了。也许会说,可以通过重做日志进行恢复。但遗憾的是重做日志是对页的物理操作,比如偏移量多少写入什么记录,如果页本身损坏,重做没有任何意义。所以在重做之前要有一个副本,使用副本还原再重做,这就是doublewrite的来源。
doublewrite有两部分组成,一部分内存中的,大小2MB,另一部分是物理磁盘上的共享表空间连续的128个页,2个区,大小也是2MB。
在对缓冲池的脏页刷新时,并不直接写磁盘,而是通过memcpy函数将脏页复制到内存的double write buffer,分两次,一次1MB顺序写入共享表空间的物理磁盘,立刻调用fsync函数,同步磁盘。doublewrite写完后,再将数据写入各个表空间文件中。前一次操作是顺序写入开销不大,写入各个表是离散的。
4.3 自适应哈希索引
hash是一种非常快的查找方法,在一般情况下是O(1)。B+数的查找次数,取决于树的高度,一般生产环境中,3~4层,所以需要3~4次的查询。
innodb会监控对表上各个索引页的查询,如果判断建立hash可以提速,就会创建,这个就是自适应hash(Adaptive Hash Index)AHI。AHI是通过缓冲池的B+树页构造而来,因此创建很快,不需要对整个表建立哈希索引。
innodb会根据访问频率和模式来自动为热点创建hash索引。AHI的一个条件是连续访问模式必须一样,比如
where a=xxx
where a=xxx and b=xxx
访问模式一样指查询条件一样,若交替执行上述查询,不会对该页构造AHI。其它的要求比如:该模式访问了100次,页通过该模式访问了N次,N=记录/16
AHI读取写入提升2倍,辅助索引连接操作提升5倍。
hash索引只能用于等值查询,范围查询是不能使用hash索引的。
4.4 异步IO
为了提高磁盘操作性能,当前数据库系统采用异步IO方式处理磁盘操作。另一个优势在于可以进行IO merge操作。
1.1版本之前使用代码模拟实现。之后提高了内核级别的AIO支持,Native AIO。需要libaio库支持编译。Mac OSX系统没有提供异步IO的支持,所以还是使用原模拟的方法。
4.5 刷新邻接页
当刷新一个页的时候,会检查该页所在的区所有页,如果是脏页会一起刷新,好处在于可以通过AIO将多个IO合并成一个IO操作。
这里会有个问题,如果将不怎么脏的页写入了,该页很快变成了脏页会不会很麻烦,固态磁盘有较高的IOPS,还需要这个特性吗?
1.2版本提供了innodb_flush_neighbors来控制是否开启这个特性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号