机器学习实战(一)k-近邻算法
转载请注明源出处:http://www.cnblogs.com/lighten/p/7593656.html
1.原理
本章介绍机器学习实战的第一个算法——k近邻算法(k Nearest Neighbor),也称为kNN。说到机器学习,一般都认为是很复杂,很高深的内容,但实际上其学习门栏并不算高,具备基本的高等数学知识(包括线性代数,概率论)就可以了,甚至一些算法高中生就能够理解了。kNN算法就是一个原理很好理解的算法,不需要多好的数学功底,这是一个分类算法(另一个大类是回归),属于监督学习的范畴(还有非监督学习,监督学习需要注有标记的训练集)。
首先,分类顾名思义就是给同一种事物分成不同的种类,比如人分成男人、女人,书分为工具书,教科书,漫画书等。要对一个事物分类,要有分类的依据,即你为什么这样划分,有时候划分的依据十分准确比如男女按性别,但很多时候是由多个因素来决定划分到哪一个类别,而不同的分类某一单一的因素又可能存在交集,这些因素在机器学习中被称之为特征,特征的选择对算法的准确率也是有影响的。个体用一组特征数据来进行描述,这样计算机处理就成了可能,分类算法所要做的就是判断这个个体所给出的特征属于哪一个类别。方法有很多,kNN采取了一个最简单的方法来判断:判断其与已知分类的训练集数据的差异,差异最小的前k个训练集个体大部分处于哪个分类该输入个体就被认作是哪个分类。
这个原理很好理解,比如判断男女,特征只有身高,体重。通常来说男人都比女人要高和重,即便女人要高,体重也比同等级的男人大部分会轻。所以对于一个输入个体来说,在已知身高、体重的情况下,求其与训练集样本的身高、体重差异,找到训练集中差异最小的k个个体,这k个个体如果大部分是男人,则输入样本就是男人,否则则是女人。选择差异最小的k个个体也就是为了避免小部分不同寻常的样本,因为男人都比女人要高和重也只是大部分情况,这样选择k个的权重,可信度就较高了。差异计算一般采用欧式距离,即各个特征相减,求平方和,开根号:
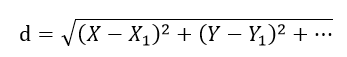
上图就是差异的定义了,这样挑选出K个最小的训练集,已知这些训练集的分类,选择K个训练集大部分所属的分类就是新输入个体的分类了。
2.问题及优缺点
kNN算法的原理简单易懂,但是在实现过程中也是有些问题需要解决的。首先我们需要关注d的计算,kNN选择的是d最小的k个训练集个体,所以d的结果合理性是很重要的。但是由该公式可以很明显的看出,d的大小很可能受到某一单一的特征影响。试想一下如果X的取值范围在1~10,Y的取值范围在1000~10000,那么d的大小严重受到Y特征的影响,那么X的作用就几乎没有了。解决该问题的方法就是将数值归一化,意思就是不管X还是Y,按照合理的放缩方法,使他们落在同一个范围区间,一般就选择0~1之间了。这个放缩方法也并不难得出,公式如下:
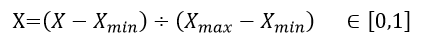
优点:精度高,对异常值不敏感,无数据输入假定
缺点:计算复杂度高、空间复杂度高
从kNN的实现上也能看出来,其计算代价较高,每个个体都需要和所有的训练集个体进行比较,而且kNN算法无法获得指定分类的一般性特征,因此其不适合大量的训练集。
3.代码
下面代码出自《机器学习实战》一书,原书中所有代码例子可以在网站:这里。进行下载。
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels

 浙公网安备 33010602011771号
浙公网安备 33010602011771号