mysql、oracle分库分表方案之sharding-jdbc使用(非demo示例)
基于3.1.0配置spring boot可参考sharding jdbc(sphere) 3.1.0 spring boot配置。
选择开源核心组件的一个非常重要的考虑通常是社区活跃性,一旦项目团队无法进行自己后续维护和扩展的情况下更是如此。
至于为什么选择sharding-jdbc而不是Mycat,可以参考知乎讨论帖子https://www.zhihu.com/question/64709787。
还可以参考https://blog.csdn.net/u013898617/article/details/79615427。
关于分库分表和读写分离、主从
一般来说,需要分库分表的系统是流量比较大的,而且比较容易出现峰值的比如说打折/活动的时候;其次,当单机扛不住业务流量的时候,分库分表一定不是第一选择,在分库分表之前,应该先保证垂直拆分完成了,子系统内都是高内聚的,其次基于Master-Slave的读写分离或者模糊查询很多的,可能NoSQL比如elastic就引流去很大一部分了。当读写分离也做完了,主库只剩下关键业务逻辑之后,流量还是很高,这个时候才开始考虑分库分表。因为相对于读写分离、垂直拆分,分库分表对开发和运维的要求多得多,如果确定业务一两年内不会剧增的,盲目引入只会导致成本高昂(尤其是各种SQL限制)。
其次,分库分表会增加N倍的数据库服务器,一般来说是4的倍数,如果某个应用说要做分库分表,又只有两台机器,那完全就是凑热闹。
读写分离和分库分表应该来说是前后的两件事比较合理,不少人将这两个事情混到一起去讲准确的说不合理的。分库分表通常更多的是用于纯粹的OLTP的事情,让系统可以水平扩展。而读写分离更多的是为了把一部分可以容忍短时延迟/不保证100%(但应该在99%以上)准确的查询路由到查询库,准确的说是对业务根据优先级做个归类,这些查询从资源消耗的角度来说相对逻辑上的PK查询要高几倍到数百倍,比如说查询某个人过去3个月的交易情况,但他从业务角度并不算是DSS概念,比如说查询已经T-N的订单/针对这些订单进行导出,并针对这个单子可能会进行一些操作,甚至人工修改状态。通过把这些功能从核心的订单/交易/资金OLTP中拆分出去,可以保证核心业务系统不会因为一个异常操作比如SQL不合理导致系统出现业务负载增加外的额外抖动因素。
从系统设计角度来说,读写分离虽然从逻辑表结构角度来说是相同的,都具有相同的字段定义,但是物理实现上是一定是不相同(要是完全相同,说明没有领会读写分离的初衷)的,尤其是在索引上,写库可能除了PK、唯一索引(任何表都应该有唯一索引,分布式锁只能作为缓冲器)外,最多还有一两个简单的字段索引以最大化性能,任何SQL符合条件的数据一般不会超过几十条(极端客户除外),但是读库根据业务不同,可能会有很多的索引以满足各种查询以及简单的统计汇总报表的需求。
那写库是不是一定就比读库重要呢?是,又不是。是是绝对的,不是是相对的。因为读库不是DSS库,是交易库中相对来说不是特别重要的业务功能。所以,写库一旦挂了,就会导致业务下不去,读库挂了,可能会导致做业务的人决策错误。比如没有没有查到做过某交易,又重新交易一次。
考虑分库分表一个很重要的决策就是是否允许跨多库操作以及有没有必要。TODO。。。。待补充。。。。。。
其次,分库和分表是两件事,是到底选择分库还是分表,如果量没有那么大的话而且是虚拟机的话,估计分库就够了。
sharding-jdbc的版本及其架构差异
目前最新版本的sharding-jdbc是v3.0.0.M1,应该来说还不稳定,包名又改成了io.shardingsphere,jar包名是sharding-jdbc。
1.5.4.1是目前最新版,也可能是终版,1.x的,坐标是com.dangdang,jar包名是sharding-jdbc。
2.0.3是目前最新版,包名和坐标统一改成了io.shardingjdbc,jar包名是sharding-jdbc-core。
说明规划不是特别好,还是有些乱。
因为2.0之后基本上纯粹分库分表的核心特性的增强就不多了,主要往治理和代理方向去了,所以如果没有特别的需求比如需要类似mycat的独立服务代理模式,使用1.x(注:1.x版本官网文档好像下线了)就可以了,不过如果是大规模的部署,同时已经使用了微服务架构中的注册中心或者基于spring boot,可以考虑使用2.0,因为2.0增加了基于注册中心的配置管理以及spring boot starter。所以2.0的架构是这样的:
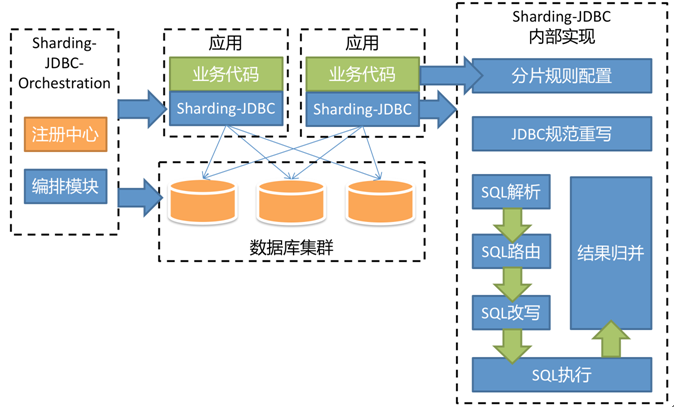
3.0之后,增加了类似mycat角色的sharding-proxy无状态服务器(代理层可以有,但是不应该作为应用直接访问的入口,如下图所示),以及类似于Service Mesh的Database Mesh。不过核心没有变化,对SQL语法增加了部分新的支持。所以3.0的架构如下:
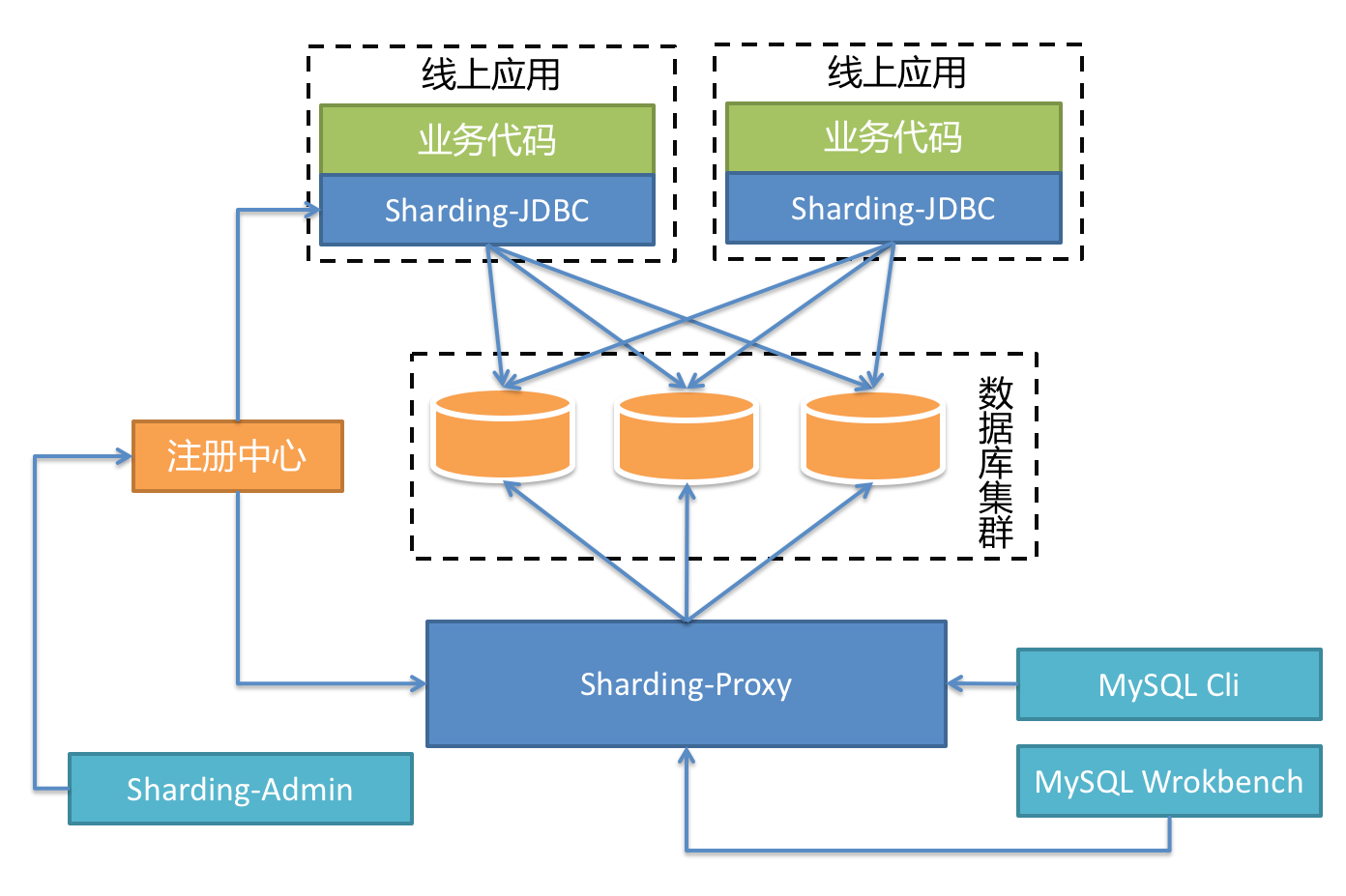
就分库分表核心来说,我们就只要关心sharding-jdbc就可以了,不需要关心sharding-sphere的其他部分。
sharding-jdbc/Sharding-Proxy/Sharding-Sidecar三者的对比如下:
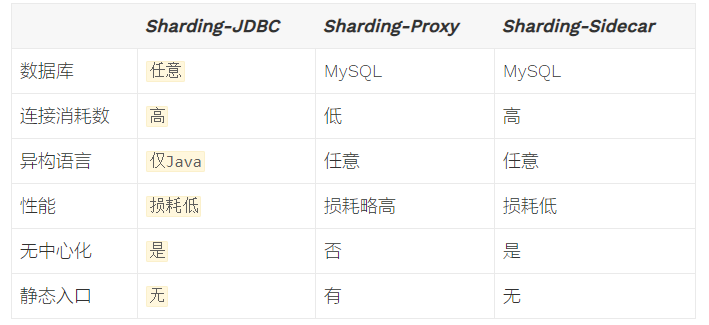
核心特性
事务
对任何重要的系统来说,事务一致性都是关键的。对分布式系统来说更是如此,最重要的就是事务一致性,从这个层面来说,分库分表本身并没有引入另外一个层次的复杂性。因为它在jdbc驱动层包了一层,所以我们有必要理解它对事务的支持性以及相关的限制。事务
sharding jdbc 2.x不支持强一致性的分布式事务,一般现在的系统设计也不追求强一致性,而是最终一致性。所以sharding jdbc 2.x支持2中事务:弱XA(同mycat)和最大努力投递事务(官方简称BED)(算是BASE的一种),具体选择哪一种需要根据业务和开发进行权衡,如果架构规范和设计做得好,是可以做到不跨库分布式事务的。
弱XA事务是默认的模式(即只要dml期间没有抛出异常,commit期间有机器断网或者宕机,是无法保证一致性的),没有特别的要求。
BED则在一定上增加了短时容忍,将执行的语句另作中心化存储,然后轮询commit期间失败的事务重试,所以BED的架构如下:
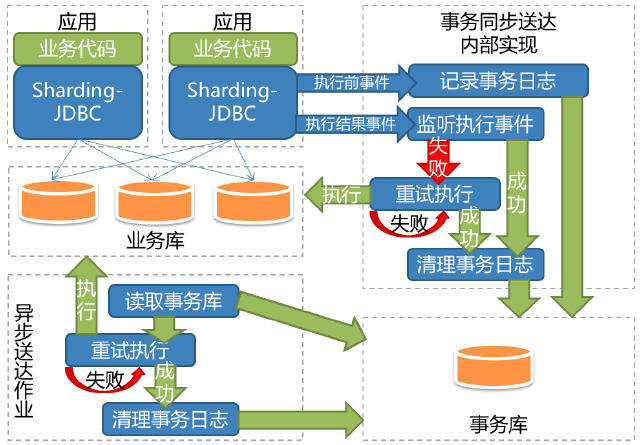
但是没有免费的午餐,BED对开发和维护有着一定的额外要求,而且这些要求都涉及面很广,绝对算得上伤筋动骨。开发层面包括:
- INSERT语句的主键不能自增
- UPDATE必须可重复执行,比如不支持UPDATE xxx SET x=x+1,对于更新余额类,这就相当于要求必须乐观锁了
运维层面包括:
- 需要存储事务日志的数据库
- 用于异步作业使用的zookeeper
- 解压sharding-jdbc-transaction-async-job-$VERSION.tar,通过start.sh脚本启动异步作业
我们选择了从设计层面避免强一致性的分布式事务。
分片灵活性
对于分库分表来说,很重要的一个特性是分片的灵活性,比如单个字段、多个字段的=、IN、>=、<=。为什么多个字段很重要的,这里涉及到一个特殊的考虑
sharding-jdbc目前提供4种分片算法。
由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
- 精确分片算法
对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
- 范围分片算法
对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND进行分片的场景。需要配合StandardShardingStrategy使用。
- 复合分片算法
对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,多分片键逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
- Hint分片算法(Hint分片指的是对于分片字段非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。例:内部系统,按照员工登录ID分库,而数据库中并无此字段。SQL Hint支持通过Java API和SQL注释(待实现)两种方式使用。)
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
因为算法的灵活性,标准的方式是通过实现具体的java接口是实现具体的分片算法比如SingleKeyDatabaseShardingAlgorithm,有不少的情况下,分片是比较简单的,比如说纯粹是客户编号,此时提供了行内表达式分片策略,使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,不过这只支持单分片键。比如,t_user_${u_id % 8} 表示t_user表按照u_id按8取模分成8个表,表名称为t_user_0到t_user_7。
分片键+分片算法=真正可用的分片策略。
算法和分片键的选择是分库分表的关键,其直接决定了各个分库的负载是否均衡,以及扩展是否容易。在设计上的考虑一节笔者会详细阐述,订单和委托业务、用户在使用分库分表时设计上的考虑以及原因。
SQL语法限制
对于分库分表来说,还需要知道有哪些SQL的限制,尤其是涉及到需要二次处理的,比如排序,去重,聚合等。
这里笔者就列下那些常用但没有被支持的。比如:
- case when
- distinct
- union
不过好在这些在java/js中处理都比较方便。
如果有很复杂的SQL,那最大的可能就是设计上有问题,应该采用读写分离解决。
sharding-jdbc对SQL的限制完整可以参考http://shardingsphere.io/document/current/cn/features/sharding/usage-standard/sql/
设计上的考虑
哪些表要分库分表
首先从设计上要区分清楚哪些是广播表/哪些是分库表/哪些是只在一个库的全局表,因为是公用数据源的,所以不管是不是分库的表,都需要配置,不配置分片规则Sharding-JDB即无法精确的断定应该路由至哪个数据源。但是一般分库分表组件包括Sharding-JDBC都会提供简化配置的方法。对于不分片的表:
方法1:sharding-jdbc可以在<sharding:sharding-rule />配置default-data-source-name,这样未配置分片规则的表将通过默认数据源定位。
方法2:将不参与分库分表的数据源独立于Sharding-JDBC之外,在应用中使用多个数据源分别处理分片和不分片的情况。
分库还是分表
一般来说应该选择分库(准确的说是分schema),不应该使用分表, 因为oracle可以包含n个schema,mysql可以包含多个database,而且就算真的需要,schema之间也是可以关联查询的,所以感觉就算是为了扩展性问题,也没有必要使用分表,分表反而在扩展的时候更加麻烦。就算数据量多了一点,感觉稍微偏慢,可以先采用分区挡一挡。
分片键的选择
其中最重要的是分片键不能是自增字段,否则insert就不知道去哪里了。所以对于ID生成,需要一个ID生成中心。
分布式主键
分布式系统的主键生成可以通过设置增量或者也通过ID生成中心来生成,不过话说回来,既然使用ID生成中心了,就不要再使用数据库机制的ID了,这不一定需要通过代码全部重写,可以在dao层通过aop判断是否insert,是Insert的动态从ID中心获取,这样就避免了分库分表和非分库分表在开发商的差别。
Sharding-JDBC使用说明
对于只有一个分片键的使用=和IN进行分片的SQL,建议使用行表达式代替Java类的配置。假设我们不使用弱性事务(如果使用柔性事务,则还需要引入sharding-jdbc-transaction以及sharding-jdbc-transaction-async-job),这样就只要引入sharding-jdbc-core这个jar包就可以了,(因为sharding-jdbc的配置支持java、yaml、spring boot以及spring命名空间(类似dubbo),所以建议使用spring 命名空间方式)如下:
<dependency> <groupId>io.shardingjdbc</groupId> <artifactId>sharding-jdbc-core</artifactId> <version>2.0.3</version> </dependency> <!-- for sharding-jdbc spring namespace --> <dependency> <groupId>io.shardingjdbc</groupId> <artifactId>sharding-jdbc-core-spring-namespace</artifactId> <version>2.0.3</version> </dependency>
因为sharding jdbc可以支持dbcp、druid,所以就不用改动其他的依赖项了。
接下去配置数据源、数据源分片策略和表分片策略。
我们假设分库结构(此处2个库仅做演示目的,实际应该至少4个分库)如下:
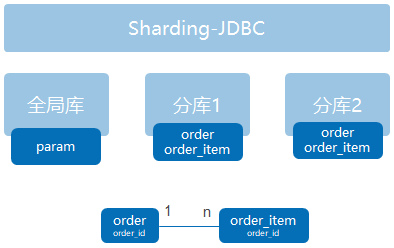
order和order_item通过order_id关联,且分片规则相同。
分库1和分库2通过user_id作为分片字段,采用取模(采用取模而不是区间的好处是负载从理论上最均衡,用区间其实是不均衡的,比如假设客户比较稳定,就1000万,0-100万第一个分片,以此类推,实际上还是可能很不均衡,因为某段时间增加的客户可能会特别活跃,尤其是在互联网应用中)
配置三个数据源:
1、globalDataSource,指向全局库,非分库分表和广播的表,比如系统参数;
2、dataSource_0、dataSource_1,指向分库1和分库2;
<bean name="dataSource_0" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> <property name="url" value="${jdbc.url_0}"/> <property name="username" value="${jdbc.username}"/> <property name="password" value="${jdbc.password}"/> <!-- 配置初始化大小、最小、最大 --> <property name="initialSize" value="${jdbc.initialSize}"/> <property name="minIdle" value="${jdbc.minIdle}"/> <property name="maxActive" value="${jdbc.maxActive}"/> <!-- 配置获取连接等待超时的时间 --> <property name="maxWait" value="${jdbc.maxWait}"/> <!-- 打开PSCache,并且指定每个连接上PSCache的大小 --> <property name="poolPreparedStatements" value="${jdbc.pps}"/> <property name="maxPoolPreparedStatementPerConnectionSize" value="${jdbc.mpps}"/> <!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 --> <property name="timeBetweenEvictionRunsMillis" value="${jdbc.timeBetweenEvictionRunsMillis}"/> <!-- 配置一个连接在池中最小生存的时间,单位是毫秒 --> <property name="minEvictableIdleTimeMillis" value="${jdbc.minEvictableIdleTimeMillis}"/> <property name="removeAbandoned" value="${jdbc.removeAbandoned}"/> <property name="removeAbandonedTimeout" value="${jdbc.removeAbandonedTimeout}"/> <property name="logAbandoned" value="${jdbc.logAbandoned}"/> <!-- 配置监控统计拦截的filters --> <property name="filters" value="${jdbc.filters}"/> </bean> <bean name="dataSource_1" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> <property name="url" value="${jdbc.url_1}"/> <property name="username" value="${jdbc.username}"/> <property name="password" value="${jdbc.password}"/> <!-- 配置初始化大小、最小、最大 --> <property name="initialSize" value="${jdbc.initialSize}"/> <property name="minIdle" value="${jdbc.minIdle}"/> <property name="maxActive" value="${jdbc.maxActive}"/> <!-- 配置获取连接等待超时的时间 --> <property name="maxWait" value="${jdbc.maxWait}"/> <!-- 打开PSCache,并且指定每个连接上PSCache的大小 --> <property name="poolPreparedStatements" value="${jdbc.pps}"/> <property name="maxPoolPreparedStatementPerConnectionSize" value="${jdbc.mpps}"/> <!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 --> <property name="timeBetweenEvictionRunsMillis" value="${jdbc.timeBetweenEvictionRunsMillis}"/> <!-- 配置一个连接在池中最小生存的时间,单位是毫秒 --> <property name="minEvictableIdleTimeMillis" value="${jdbc.minEvictableIdleTimeMillis}"/> <property name="removeAbandoned" value="${jdbc.removeAbandoned}"/> <property name="removeAbandonedTimeout" value="${jdbc.removeAbandonedTimeout}"/> <property name="logAbandoned" value="${jdbc.logAbandoned}"/> <!-- 配置监控统计拦截的filters --> <property name="filters" value="${jdbc.filters}"/> </bean> <bean name="globalDataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> <property name="url" value="${jdbc.url}"/> <property name="username" value="${jdbc.username}"/> <property name="password" value="${jdbc.password}"/> <!-- 配置初始化大小、最小、最大 --> <property name="initialSize" value="${jdbc.initialSize}"/> <property name="minIdle" value="${jdbc.minIdle}"/> <property name="maxActive" value="${jdbc.maxActive}"/> <!-- 配置获取连接等待超时的时间 --> <property name="maxWait" value="${jdbc.maxWait}"/> <!-- 打开PSCache,并且指定每个连接上PSCache的大小 --> <property name="poolPreparedStatements" value="${jdbc.pps}"/> <property name="maxPoolPreparedStatementPerConnectionSize" value="${jdbc.mpps}"/> <!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 --> <property name="timeBetweenEvictionRunsMillis" value="${jdbc.timeBetweenEvictionRunsMillis}"/> <!-- 配置一个连接在池中最小生存的时间,单位是毫秒 --> <property name="minEvictableIdleTimeMillis" value="${jdbc.minEvictableIdleTimeMillis}"/> <property name="removeAbandoned" value="${jdbc.removeAbandoned}"/> <property name="removeAbandonedTimeout" value="${jdbc.removeAbandonedTimeout}"/> <property name="logAbandoned" value="${jdbc.logAbandoned}"/> <!-- 配置监控统计拦截的filters --> <property name="filters" value="${jdbc.filters}"/> </bean>
全局表、分库不分表、分库分表、广播表、主、子表绑定的各自规则配置(下面使用行内策略,注:https://blog.csdn.net/shijiemozujiejie/article/details/80786231提到行表达式的策略不利于数据库和表的横向扩展,这是有道理的,因为java代码我们可以随时重新加载分库和分表的基数,做到不停机扩展,但是行内表达式不行)如下:
<!-- 必须加上ignore-unresolvable,否则很可能会出现java.lang.IllegalArgumentException: Could not resolve placeholder以及cannot invoke method mod() on null object-->
<context:property-placeholder location="classpath:jrescloud.properties" ignore-unresolvable="true" order="1"/>
<!-- 分库策略,尽量使用sharding:standard-strategy而不是inline-stragegy --> <sharding:inline-strategy id="databaseStrategy" sharding-column="user_id" algorithm-expression="dataSource_${user_id % 2}" /> <!-- 分表策略 --> <sharding:inline-strategy id="orderTableStrategy" sharding-column="order_id" algorithm-expression="t_order_${order_id % 2}" /> <sharding:inline-strategy id="orderItemTableStrategy" sharding-column="order_id" algorithm-expression="t_order_item_${order_id % 2}" /> <sharding:data-source id="shardingDataSource"> <!-- configDataSource为不参数分库分表的全局表的默认数据源,比如系统参数 --> <sharding:sharding-rule data-source-names="dataSource_0,dataSource_1,globalDataSource" default-data-source-name="globalDataSource"> <sharding:table-rules> <!-- 分库+分表 --> <sharding:table-rule logic-table="t_order" actual-data-nodes="dataSource_${0..1}.t_order_${0..1}" database-strategy-ref="databaseStrategy" table-strategy-ref="orderTableStrategy" /> <sharding:table-rule logic-table="t_order_item" actual-data-nodes="dataSource_${0..1}.t_order_item_${0..1}" database-strategy-ref="databaseStrategy" table-strategy-ref="orderItemTableStrategy" />
<!-- 分库不分表 --> <sharding:table-rule logic-table="t_order" database-strategy-ref="databaseStrategy"/> <!-- 广播表 --> <sharding:table-rule logic-table="t_dict"/> </sharding:table-rules> <!-- 绑定表规则列表,表示分库分表的规则相同,这样万一涉及到多个分片的查询,sharding-jdbc就可以确定分库之间不需要不必要的二次关联,所有的查询都应该如此 --> <sharding:binding-table-rules> <sharding:binding-table-rule logic-tables="t_order,t_order_item"/> </sharding:binding-table-rules> </sharding:sharding-rule> </sharding:data-source> <bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource" ref="shardingDataSource" /> </bean> <!-- 使用annotation 自动注册bean, 并保证@Required、@Autowired的属性被注入 --> <tx:annotation-driven transaction-manager="transactionManager"/> <bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"> <property name="configLocation" value="classpath:mybatis.xml"/> <property name="dataSource" ref="shardingDataSource"/> <property name="mapperLocations"> <list> <value>classpath*:sqlmap/com/yidoo/k3c/**/*.xml</value> </list> </property> </bean>
HINT分片策略的使用
Hint分片指的是对于分片字段非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。举个实例的例子,我们都知道mysql insert values相对于循环插入来说,性能差距基本上可以说是网络延时的倍数,比如说插入1000条记录,网络来回1ms,1000条就得1m,如果是跨网段的,延时就更长了。而sharding-jdbc和Mycat都不支持多values(sharding-jdbc 3.x支持,但还没有正式发布),有些SQL语句比较复杂比如说有(a = var or b = var) and member_id = N,这个时候druid sqlparser并不支持的时候,虽然可以通过多数据源解决,但是我们不希望架构搞得太复杂,这种情况下,可以通过sharding-jdbc的Hint分片策略来实现各种sharding-jdbc不支持的语法的限制。因为Hint分片策略是绕过SQL解析的,所以对于这些比较复杂的需要分片的非DSS查询,采用Hint分片策略性能可能会更好。同样,我们还是使用mybatis作为数据库访问层作为例子,对于Hint分片策略,帖子大都是基于1.x版本进行源码分析路由,顺带提及,基本上都是瞎扯,同时在用法上sharding-jdbc-example没有提及。因为我们实际要用,所以笔者基于2.0.3版本进行了完整的测试确保结果符合我们的预期。
首先定义一个hint策略,hint策略需要实现io.shardingjdbc.core.api.algorithm.sharding.hint.HintShardingAlgorithm接口。
<sharding:hint-strategy id="hintDatabaseStrategy" algorithm-class="com.yidoo.common.route.hint.HintShardingAlgorithm"/>
package com.yidoo.common.route.hint; import java.util.ArrayList; import java.util.Collection; import java.util.List; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import com.alibaba.druid.util.StringUtils; import com.yidoo.utils.JacksonHelper; import io.shardingjdbc.core.api.algorithm.sharding.ListShardingValue; import io.shardingjdbc.core.api.algorithm.sharding.ShardingValue; public class HintShardingAlgorithm implements io.shardingjdbc.core.api.algorithm.sharding.hint.HintShardingAlgorithm { private static final Logger logger = LoggerFactory.getLogger(HintShardingAlgorithm.class); @Override public Collection<String> doSharding(Collection<String> availableTargetNames, ShardingValue shardingValue) { logger.debug("shardingValue=" + JacksonHelper.toJSON(shardingValue)); logger.debug("availableTargetNames=" + JacksonHelper.toJSON(availableTargetNames)); List<String> shardingResult = new ArrayList<>(); availableTargetNames.forEach(targetName -> { String suffix = targetName.substring(targetName.lastIndexOf("_")+1); if(StringUtils.isNumber(suffix)) {
// hint分片算法的ShardingValue有两种具体类型: ListShardingValue和RangeShardingValue,取决于io.shardingjdbc.core.api.HintManager.addDatabaseShardingValue(String, String, ShardingOperator, Comparable<?>...)的时候,ShardingOperator的类型。见下文。 ListShardingValue<Integer> tmpSharding = (ListShardingValue<Integer>) shardingValue; tmpSharding.getValues().forEach(value -> { if (value % 2 == Integer.parseInt(suffix)) { shardingResult.add(targetName); } }); } }); return shardingResult; } }
@SuppressWarnings("unchecked")
private ShardingValue getShardingValue(final String logicTable, final String shardingColumn, final ShardingOperator operator, final Comparable<?>[] values) {
Preconditions.checkArgument(null != values && values.length > 0);
switch (operator) {
case EQUAL:
case IN:
return new ListShardingValue(logicTable, shardingColumn, Arrays.asList(values));
case BETWEEN:
return new RangeShardingValue(logicTable, shardingColumn, Range.range(values[0], BoundType.CLOSED, values[1], BoundType.CLOSED));
default:
throw new UnsupportedOperationException(operator.getExpression());
}
}
sharding:sharding-rule节点上定义属性default-database-strategy-ref为hintDatabaseStrategy,如下:
<sharding:sharding-rule data-source-names="dataSource_0,dataSource_1,globalDataSource" default-database-strategy-ref="hintDatabaseStrategy" default-data-source-name="globalDataSource">
不用定义<sharding:table-rules>。
接下去在执行sql语句前设置分片值即可,如下:
UnitQuery treq = new UnitQuery(); Unit record1 = new Unit(); record1.setUnitName("强制指定Hint-1"); record1.setRemark1(" "); record1.setInputMan("系统管理员"); Unit record2 = new Unit(); record2.setUnitName("强制指定Hint-3"); record2.setRemark1(" "); record2.setInputMan("系统管理员"); List<Unit> records = new ArrayList<>(); records.add(record1); records.add(record2); HintManager hintManager = HintManager.getInstance(); hintManager.setDatabaseShardingValue(1); // hintManager.addDatabaseShardingValue("t_Unit","user_id",1); unitMapper.insertValues(records); hintManager.close(); hintManager = HintManager.getInstance(); // 必须先clear,重新拿到instance hintManager.setDatabaseShardingValue(1); List<Unit> unitList = unitMapper.selectByHint(treq); logger.info("强制指定Hint-1提示" + JacksonHelper.toJSON(unitList)); hintManager.close(); Unit record3 = new Unit(); record3.setUnitName("强制指定Hint-2"); record3.setRemark1(" "); record3.setInputMan("系统管理员"); Unit record4 = new Unit(); record4.setUnitName("强制指定Hint-4"); record4.setRemark1(" "); record4.setInputMan("系统管理员"); records.clear(); records.add(record3); records.add(record4); hintManager = HintManager.getInstance(); hintManager.setDatabaseShardingValue(2); // hintManager.addDatabaseShardingValue("t_Unit","user_id",2); unitMapper.insertValues(records); hintManager.close(); hintManager = HintManager.getInstance(); unitList = unitMapper.selectByHint(treq); logger.info("强制指定Hint-2提示" + JacksonHelper.toJSON(unitList)); hintManager.close();
mapper中如下:
<insert id="insertValues"> insert into t_Unit( unit_name, remark1, input_man, input_date ) values <foreach collection="list" item="item" index="index" separator=","> ( #{item.unitName}, #{item.remark1}, #{item.inputMan}, now() ) </foreach> </insert> <select id="selectByHint" resultType="com.yidoo.k3c.global.model.pojo.Unit"> select * from t_Unit </select>
执行前:

执行后:
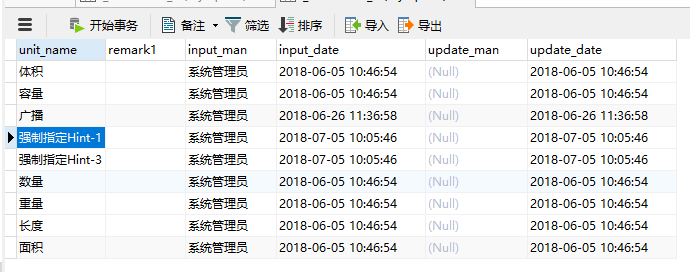
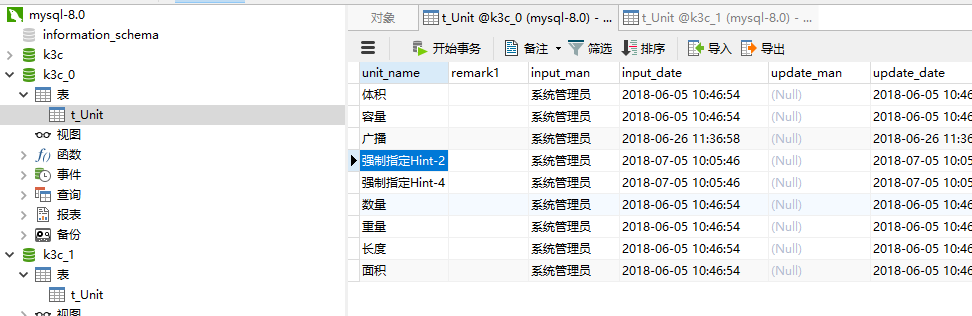
日志:
[] 2018-07-05 10:10:21 [61125] [Sharding-JDBC-SQL]-[INFO] localhost-startStop-1 io.shardingjdbc.core.util.SQLLogger.log(SQLLogger.java:59) Logic SQL: insert into t_Unit(
unit_name,
remark1,
input_man,
input_date
) values
(
?,
?,
?,
now()
)
,
(
?,
?,
?,
now()
)
[] 2018-07-05 10:10:21 [61125] [Sharding-JDBC-SQL]-[INFO] localhost-startStop-1 io.shardingjdbc.core.util.SQLLogger.log(SQLLogger.java:59) SQLStatement: DMLStatement(super=AbstractSQLStatement(type=DML, tables=Tables(tables=[]), conditions=Conditions(conditions={}), sqlTokens=[], parametersIndex=0))
[] 2018-07-05 10:10:21 [61125] [Sharding-JDBC-SQL]-[INFO] localhost-startStop-1 io.shardingjdbc.core.util.SQLLogger.log(SQLLogger.java:59) Actual SQL: dataSource_1 ::: insert into t_Unit(
unit_name,
remark1,
input_man,
input_date
) values
(
?,
?,
?,
now()
)
,
(
?,
?,
?,
now()
) ::: [强制指定Hint-1, , 系统管理员, 强制指定Hint-3, , 系统管理员]
[] 2018-07-05 10:10:21 [61514] [c.a.d.p.PreparedStatementPool]-[DEBUG] localhost-startStop-1 com.alibaba.druid.pool.PreparedStatementPool.put(PreparedStatementPool.java:129) {conn-110005, pstmt-120000} enter cache
[] 2018-07-05 10:10:21 [61515] [o.m.s.SqlSessionUtils]-[DEBUG] localhost-startStop-1 org.mybatis.spring.SqlSessionUtils.closeSqlSession(SqlSessionUtils.java:168) Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@2b3a6ec5]
[] 2018-07-05 10:10:21 [61515] [o.s.j.d.DataSourceUtils]-[DEBUG] localhost-startStop-1 org.springframework.jdbc.datasource.DataSourceUtils.doReleaseConnection(DataSourceUtils.java:329) Returning JDBC Connection to DataSource
[] 2018-07-05 10:10:21 [61519] [o.m.s.SqlSessionUtils]-[DEBUG] localhost-startStop-1 org.mybatis.spring.SqlSessionUtils.getSqlSession(SqlSessionUtils.java:104) Creating a new SqlSession
[] 2018-07-05 10:10:21 [61519] [o.m.s.SqlSessionUtils]-[DEBUG] localhost-startStop-1 org.mybatis.spring.SqlSessionUtils.getSqlSession(SqlSessionUtils.java:140) SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@41aefec2] was not registered for synchronization because synchronization is not active
[] 2018-07-05 10:10:21 [61523] [o.s.j.d.DataSourceUtils]-[DEBUG] localhost-startStop-1 org.springframework.jdbc.datasource.DataSourceUtils.doGetConnection(DataSourceUtils.java:110) Fetching JDBC Connection from DataSource
[] 2018-07-05 10:10:21 [61523] [o.m.s.t.SpringManagedTransaction]-[DEBUG] localhost-startStop-1 org.mybatis.spring.transaction.SpringManagedTransaction.openConnection(SpringManagedTransaction.java:86) JDBC Connection [io.shardingjdbc.core.jdbc.core.connection.ShardingConnection@5e996b5d] will not be managed by Spring
[] 2018-07-05 10:10:21 [61528] [i.s.c.r.t.h.DatabaseHintRoutingEngine]-[DEBUG] localhost-startStop-1 io.shardingjdbc.core.routing.type.hint.DatabaseHintRoutingEngine.route(DatabaseHintRoutingEngine.java:55) Before database sharding only db:[dataSource_0, dataSource_1, globalDataSource] sharding values: ListShardingValue(logicTableName=DB_TABLE_NAME, columnName=DB_COLUMN_NAME, values=[1])
[] 2018-07-05 10:10:21 [61529] [i.s.c.r.t.h.DatabaseHintRoutingEngine]-[DEBUG] localhost-startStop-1 io.shardingjdbc.core.routing.type.hint.DatabaseHintRoutingEngine.route(DatabaseHintRoutingEngine.java:59) After database sharding only result: [dataSource_1]
[] 2018-07-05 10:10:21 [61530] [Sharding-JDBC-SQL]-[INFO] localhost-startStop-1 io.shardingjdbc.core.util.SQLLogger.log(SQLLogger.java:59) Logic SQL: select * from t_Unit
[] 2018-07-05 10:10:21 [61530] [Sharding-JDBC-SQL]-[INFO] localhost-startStop-1 io.shardingjdbc.core.util.SQLLogger.log(SQLLogger.java:59) SQLStatement: SelectStatement(super=DQLStatement(super=AbstractSQLStatement(type=DQL, tables=Tables(tables=[]), conditions=Conditions(conditions={}), sqlTokens=[], parametersIndex=0)), containStar=false, selectListLastPosition=0, groupByLastPosition=0, items=[], groupByItems=[], orderByItems=[], limit=null, subQueryStatement=null)
[] 2018-07-05 10:10:21 [61530] [Sharding-JDBC-SQL]-[INFO] localhost-startStop-1 io.shardingjdbc.core.util.SQLLogger.log(SQLLogger.java:59) Actual SQL: dataSource_1 ::: select * from t_Unit
[] 2018-07-05 10:10:21 [61576] [c.a.d.p.PreparedStatementPool]-[DEBUG] localhost-startStop-1 com.alibaba.druid.pool.PreparedStatementPool.put(PreparedStatementPool.java:129) {conn-110005, pstmt-120001} enter cache
[] 2018-07-05 10:10:21 [61577] [o.m.s.SqlSessionUtils]-[DEBUG] localhost-startStop-1 org.mybatis.spring.SqlSessionUtils.closeSqlSession(SqlSessionUtils.java:168) Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@41aefec2]
[] 2018-07-05 10:10:21 [61578] [o.s.j.d.DataSourceUtils]-[DEBUG] localhost-startStop-1 org.springframework.jdbc.datasource.DataSourceUtils.doReleaseConnection(DataSourceUtils.java:329) Returning JDBC Connection to DataSource
[] 2018-07-05 10:10:21 [61582] [c.y.c.s.ParamexService]-[INFO] localhost-startStop-1 com.yidoo.common.service.ParamexService.afterPropertiesSet(ParamexService.java:79) 强制指定Hint-1提示[{"unitName":"体积","remark1":" ","inputMan":"系统管理员","inputDate":1528166814000,"updateMan":null,"updateDate":1528166814000},{"unitName":"容量","remark1":" ","inputMan":"系统管理员","inputDate":1528166814000,"updateMan":null,"updateDate":1528166814000},{"unitName":"广播","remark1":" ","inputMan":"系统管理员","inputDate":1529984218000,"updateMan":null,"updateDate":1529984218000},{"unitName":"强制指定Hint-1","remark1":" ","inputMan":"系统管理员","inputDate":1530756621000,"updateMan":null,"updateDate":1530756621000},{"unitName":"强制指定Hint-3","remark1":" ","inputMan":"系统管理员","inputDate":1530756621000,"updateMan":null,"updateDate":1530756621000},{"unitName":"数量","remark1":" ","inputMan":"系统管理员","inputDate":1528166814000,"updateMan":null,"updateDate":1528166814000},{"unitName":"重量","remark1":" ","inputMan":"系统管理员","inputDate":1528166814000,"updateMan":null,"updateDate":1528166814000},{"unitName":"长度","remark1":" ","inputMan":"系统管理员","inputDate":1528166814000,"updateMan":null,"updateDate":1528166814000},{"unitName":"面积","remark1":" ","inputMan":"系统管理员","inputDate":1528166814000,"updateMan":null,"updateDate":1528166814000}]
[] 2018-07-05 10:10:21 [61585] [i.s.c.r.t.h.DatabaseHintRoutingEngine]-[DEBUG] localhost-startStop-1 io.shardingjdbc.core.routing.type.hint.DatabaseHintRoutingEngine.route(DatabaseHintRoutingEngine.java:55) Before database sharding only db:[dataSource_0, dataSource_1, globalDataSource] sharding values: ListShardingValue(logicTableName=DB_TABLE_NAME, columnName=DB_COLUMN_NAME, values=[2])
[] 2018-07-05 10:10:21 [61586] [i.s.c.r.t.h.DatabaseHintRoutingEngine]-[DEBUG] localhost-startStop-1 io.shardingjdbc.core.routing.type.hint.DatabaseHintRoutingEngine.route(DatabaseHintRoutingEngine.java:59) After database sharding only result: [dataSource_0]
[] 2018-07-05 10:10:21 [61587] [Sharding-JDBC-SQL]-[INFO] localhost-startStop-1 io.shardingjdbc.core.util.SQLLogger.log(SQLLogger.java:59) Logic SQL: insert into t_Unit(
unit_name,
remark1,
input_man,
input_date
) values
(
?,
?,
?,
now()
)
,
(
?,
?,
?,
now()
)
[] 2018-07-05 10:10:21 [61587] [Sharding-JDBC-SQL]-[INFO] localhost-startStop-1 io.shardingjdbc.core.util.SQLLogger.log(SQLLogger.java:59) SQLStatement: DMLStatement(super=AbstractSQLStatement(type=DML, tables=Tables(tables=[]), conditions=Conditions(conditions={}), sqlTokens=[], parametersIndex=0))
[] 2018-07-05 10:10:21 [61587] [Sharding-JDBC-SQL]-[INFO] localhost-startStop-1 io.shardingjdbc.core.util.SQLLogger.log(SQLLogger.java:59) Actual SQL: dataSource_0 ::: insert into t_Unit(
unit_name,
remark1,
input_man,
input_date
) values
(
?,
?,
?,
now()
)
,
(
?,
?,
?,
now()
) ::: [强制指定Hint-2, , 系统管理员, 强制指定Hint-4, , 系统管理员]
[] 2018-07-05 10:10:21 [61624] [c.a.d.p.PreparedStatementPool]-[DEBUG] localhost-startStop-1 com.alibaba.druid.pool.PreparedStatementPool.put(PreparedStatementPool.java:129) {conn-10005, pstmt-20000} enter cache
[] 2018-07-05 10:10:21 [61625] [o.m.s.SqlSessionUtils]-[DEBUG] localhost-startStop-1 org.mybatis.spring.SqlSessionUtils.closeSqlSession(SqlSessionUtils.java:168) Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@767f7324]
[] 2018-07-05 10:10:21 [61625] [o.s.j.d.DataSourceUtils]-[DEBUG] localhost-startStop-1 org.springframework.jdbc.datasource.DataSourceUtils.doReleaseConnection(DataSourceUtils.java:329) Returning JDBC Connection to DataSource
[] 2018-07-05 10:10:21 [61625] [o.m.s.SqlSessionUtils]-[DEBUG] localhost-startStop-1 org.mybatis.spring.SqlSessionUtils.getSqlSession(SqlSessionUtils.java:104) Creating a new SqlSession
[] 2018-07-05 10:10:21 [61626] [o.m.s.SqlSessionUtils]-[DEBUG] localhost-startStop-1 org.mybatis.spring.SqlSessionUtils.getSqlSession(SqlSessionUtils.java:140) SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@4c582b4c] was not registered for synchronization because synchronization is not active
[] 2018-07-05 10:10:21 [61626] [o.s.j.d.DataSourceUtils]-[DEBUG] localhost-startStop-1 org.springframework.jdbc.datasource.DataSourceUtils.doGetConnection(DataSourceUtils.java:110) Fetching JDBC Connection from DataSource
[] 2018-07-05 10:10:21 [61627] [o.m.s.t.SpringManagedTransaction]-[DEBUG] localhost-startStop-1 org.mybatis.spring.transaction.SpringManagedTransaction.openConnection(SpringManagedTransaction.java:86) JDBC Connection [io.shardingjdbc.core.jdbc.core.connection.ShardingConnection@b551009] will not be managed by Spring
[] 2018-07-05 10:10:21 [61769] [Sharding-JDBC-SQL]-[INFO] localhost-startStop-1 io.shardingjdbc.core.util.SQLLogger.log(SQLLogger.java:59) Logic SQL: select * from t_Unit
[] 2018-07-05 10:10:21 [61770] [Sharding-JDBC-SQL]-[INFO] localhost-startStop-1 io.shardingjdbc.core.util.SQLLogger.log(SQLLogger.java:59) SQLStatement: SelectStatement(super=DQLStatement(super=AbstractSQLStatement(type=DQL, tables=Tables(tables=[Table(name=t_Unit, alias=Optional.absent())]), conditions=Conditions(conditions={}), sqlTokens=[TableToken(beginPosition=14, originalLiterals=t_Unit)], parametersIndex=0)), containStar=true, selectListLastPosition=9, groupByLastPosition=0, items=[StarSelectItem(owner=Optional.absent())], groupByItems=[], orderByItems=[], limit=null, subQueryStatement=null)
[] 2018-07-05 10:10:21 [61771] [Sharding-JDBC-SQL]-[INFO] localhost-startStop-1 io.shardingjdbc.core.util.SQLLogger.log(SQLLogger.java:59) Actual SQL: globalDataSource ::: select * from t_Unit
[] 2018-07-05 10:10:22 [61782] [c.a.d.p.PreparedStatementPool]-[DEBUG] localhost-startStop-1 com.alibaba.druid.pool.PreparedStatementPool.put(PreparedStatementPool.java:129) {conn-210005, pstmt-220000} enter cache
[] 2018-07-05 10:10:22 [61782] [o.m.s.SqlSessionUtils]-[DEBUG] localhost-startStop-1 org.mybatis.spring.SqlSessionUtils.closeSqlSession(SqlSessionUtils.java:168) Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@4c582b4c]
[] 2018-07-05 10:10:22 [61783] [o.s.j.d.DataSourceUtils]-[DEBUG] localhost-startStop-1 org.springframework.jdbc.datasource.DataSourceUtils.doReleaseConnection(DataSourceUtils.java:329) Returning JDBC Connection to DataSource
[] 2018-07-05 10:10:22 [61785] [c.y.c.s.ParamexService]-[INFO] localhost-startStop-1 com.yidoo.common.service.ParamexService.afterPropertiesSet(ParamexService.java:102) 强制指定Hint-2提示[{"unitName":"体积","remark1":" ","inputMan":"系统管理员","inputDate":1528166814000,"updateMan":null,"updateDate":1528166814000},{"unitName":"容量","remark1":" ","inputMan":"系统管理员","inputDate":1528166814000,"updateMan":null,"updateDate":1528166814000},{"unitName":"广播","remark1":" ","inputMan":"系统管理员","inputDate":1529984218000,"updateMan":null,"updateDate":1529984218000},{"unitName":"强制指定Hint-1","remark1":" ","inputMan":"系统管理员","inputDate":1530701874000,"updateMan":null,"updateDate":1530701874000},{"unitName":"强制指定Hint-2","remark1":" ","inputMan":"系统管理员","inputDate":1530701874000,"updateMan":null,"updateDate":1530701874000},{"unitName":"强制指定Hint-3","remark1":" ","inputMan":"系统管理员","inputDate":1530701874000,"updateMan":null,"updateDate":1530701874000},{"unitName":"强制指定Hint-4","remark1":" ","inputMan":"系统管理员","inputDate":1530701874000,"updateMan":null,"updateDate":1530701874000},{"unitName":"数量","remark1":" ","inputMan":"系统管理员","inputDate":1528166814000,"updateMan":null,"updateDate":1528166814000},{"unitName":"重量","remark1":" ","inputMan":"系统管理员","inputDate":1528166814000,"updateMan":null,"updateDate":1528166814000},{"unitName":"长度","remark1":" ","inputMan":"系统管理员","inputDate":1528166814000,"updateMan":null,"updateDate":1528166814000},{"unitName":"面积","remark1":" ","inputMan":"系统管理员","inputDate":1528166814000,"updateMan":null,"updateDate":1528166814000}]
注意点
1、使用了sharding-jdbc之后,select from TableName会被转换为select from tablename,也就是转小写,这是在代码中处理的,如果不希望转换(sql标准是大小写不敏感的,主要是mysql linux下lower-case-table-names=1这个特例会区分大小写,而且mysql 8.0不允许数据库初始化和启动的值不一致,5.7之前是可以的,https://bugs.mysql.com/bug.php?id=90695),则需要自己编译sharding-jdbc-core(我们编译了一版sharding-jdbc-core-2.0.3.zip),并更改getTableTokens中的转小写的代码(这应该算是个bug),2.0.3版本代码位置为:
// io.shardingjdbc.core.rewrite.SQLRewriteEngine.getTableTokens(TableUnit)中对sql语句中的表名做了toLowerCase()导致的,如下: private Map<String, String> getTableTokens(final TableUnit tableUnit) { String logicTableName = tableUnit.getLogicTableName().toLowerCase(); Map<String, String> tableTokens = new HashMap<>(); tableTokens.put(logicTableName, tableUnit.getActualTableName()); Optional<BindingTableRule> bindingTableRule = shardingRule.findBindingTableRule(logicTableName); if (bindingTableRule.isPresent()) { tableTokens.putAll(getBindingTableTokens(tableUnit, bindingTableRule.get())); } return tableTokens; }
2、一定要设置context:property-placeholder的ignore-unresolvable属性为true,即<context:property-placeholder location="classpath:property/*.properties" ignore-unresolvable="true" />,否则会报无法解析占位符。
3、我们在调试的时候遇到个问题,如果eclipse中同时把sharding-jdbc的源代码引入进来,war启动的时候就会报sharding.xsd找不到,然后启动出错。
参考:
各非行内ShardingStrategy的用法可以参考https://www.cnblogs.com/mr-yang-localhost/p/8313360.html
其他:
https://wenku.baidu.com/view/ddeaed18910ef12d2bf9e74a.html
https://www.oschina.net/question/2918182_2280300
https://www.oschina.net/news/88860/sharding-jdbc-1-5-4-released
http://www.infoq.com/cn/news/2017/12/Sharding-JDBC-2
http://cmsblogs.com/?p=2542
http://shardingjdbc.io/document/legacy/2.x/en/00-overview/
https://www.oschina.net/question/2356021_2264290
https://blog.csdn.net/vkingnew/article/details/80613043
https://www.jianshu.com/p/dd47dd3b1f6b
https://www.zhihu.com/question/64709787
sharding-jdbc不支持SQL
https://blog.csdn.net/Farrell_zeng/article/details/52958189
mycat不支持SQL
https://blog.csdn.net/educast/article/details/50013355
shardingjdbc作为分库分表时候性能损耗还是比较大的,大约有1/3~2/3,可参见https://blog.csdn.net/wzy0623/article/details/125118404。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号