Redis集群搭建
Redis的使用模式主要分为单机和集群,而集群又分为三种模式,分别是主从模式、Sentinel模式、Cluster模式,本文记录下三种搭建集群的方式,方便以后回顾。
由于搞不到那么多服务器,本文搭建集群使用一个主机,不同端口运行不同实例来模拟多个服务器。
一、主从模式:
主从模式是最基本的集群模式,主要构成由主数据库(master)和从属数据库(slave)构成。
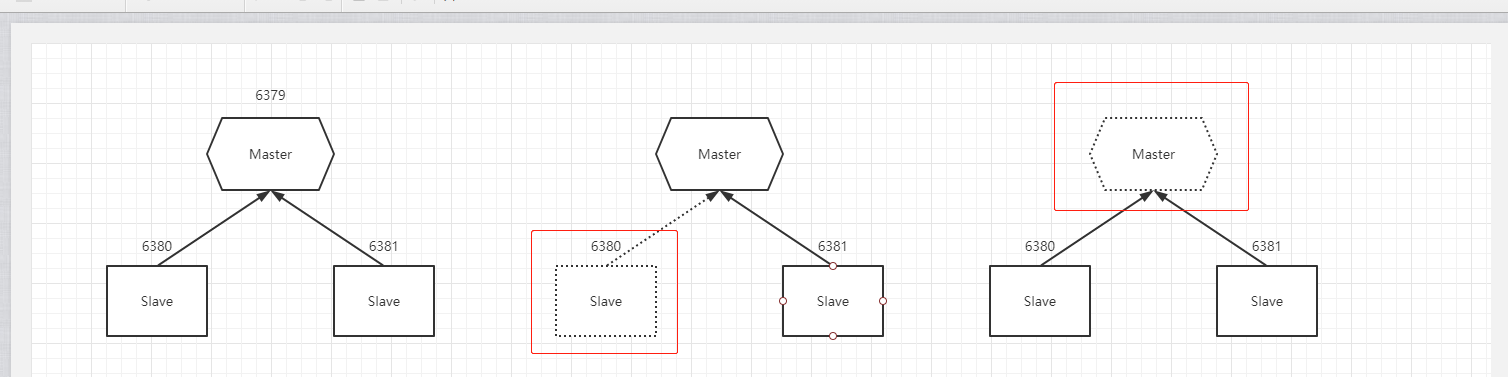
上图中的集群由一个master(6379端口)和两个slave(6380和6381端口)构成,主从模式类似于数据库的读写分离机制,主要有以下特点:
1.主数据库可以进行读和写操作,而从数据库一般只允许读操作,主数据库写入数据后会将数据同步到从数据库,所以保证了无论从哪个数据库读取数据都是一致的。
2.其中一个slave挂了(如上图6380),不影响主数据库的读写操作,如果有不止一个slave则不影响整个集群系统的运行,如果slave全部挂掉则所有读写压力均放到主数据库上。
3.主数据库挂了(如上图6379),不影响从数据的读操作,整个系统则不提供写操作,但是读数据操作不受影响。
主从模式搭建方法:
演示环境为Windows(比较好操作):
准备3个配置文件,一个master的两个slave的:

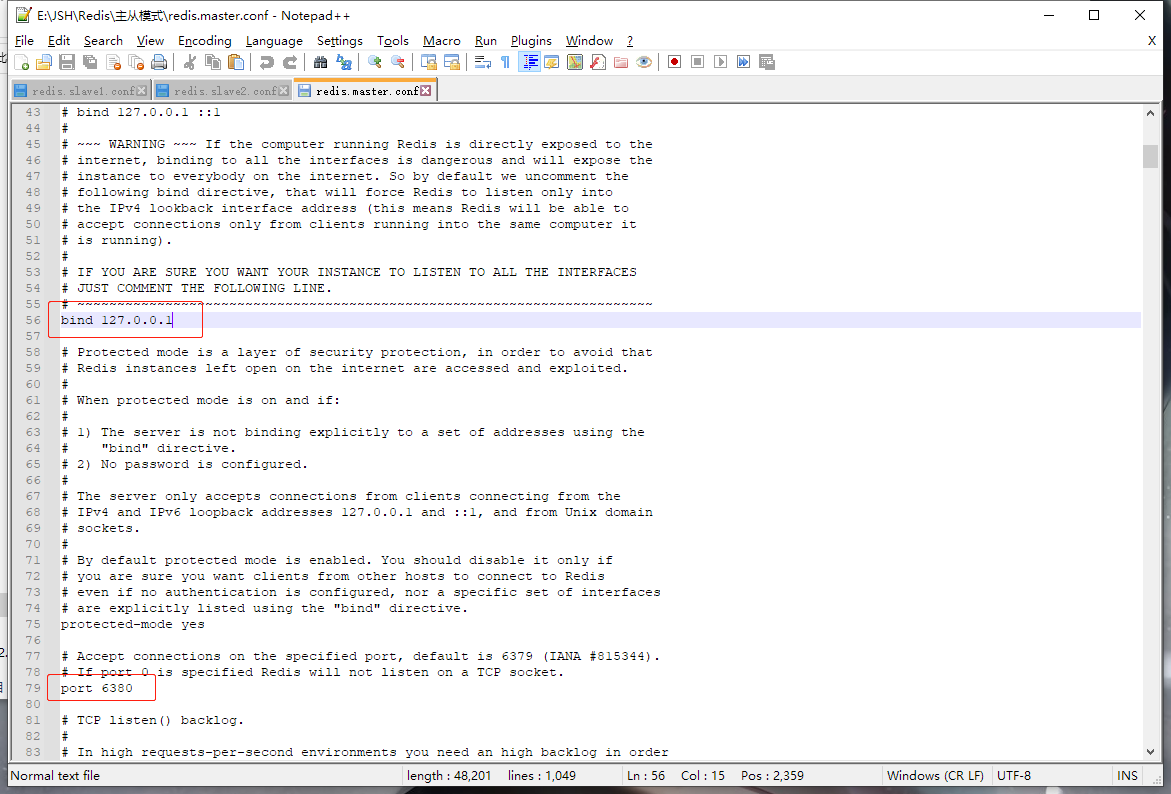
通用配置有IP、端口,这里用的是localhost:127.0.0.1,master端口是6380,slave端口是6381和6382,其他配置用的默认:
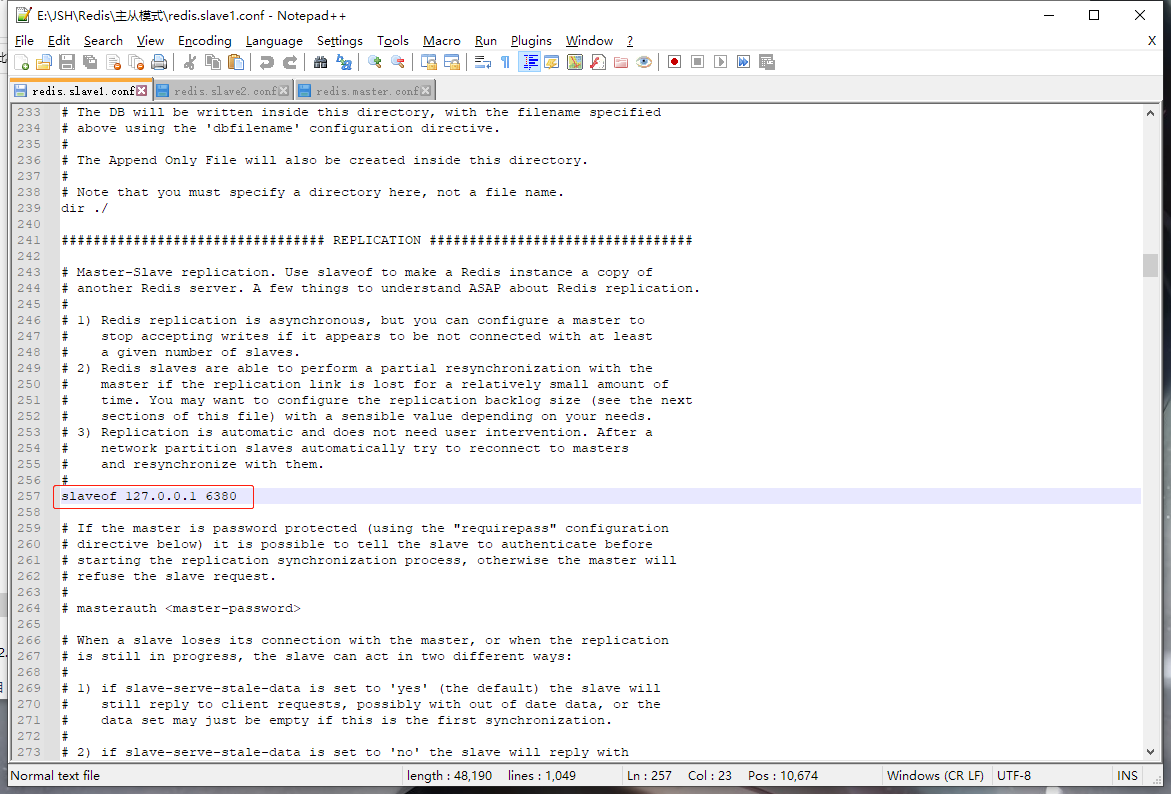
两个slave的配置中还需要开启slaveof项,表示隶属于哪个主服务器:
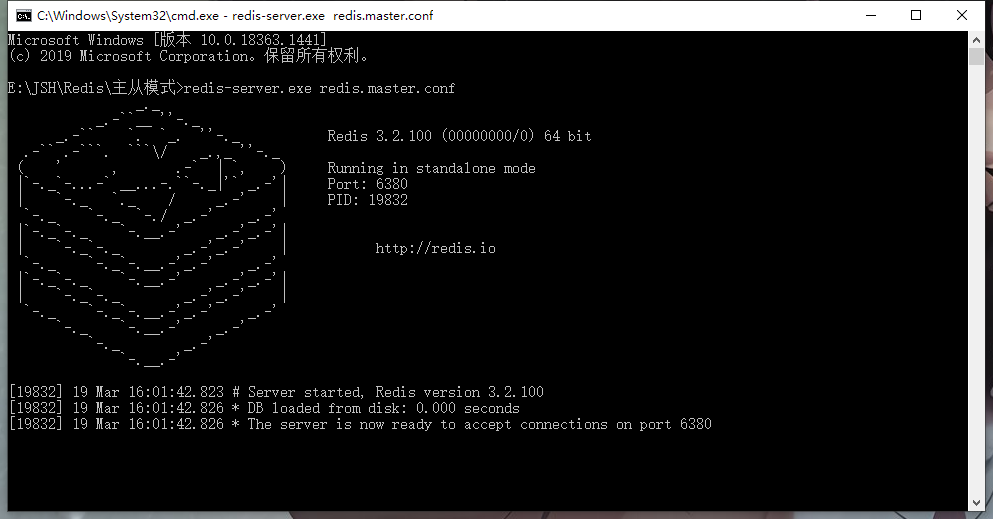
然后就可以启动服务器了,关于redis控制台命令这里不过多介绍,大家可自行百度。先启动主服务器:redis-server.exe redis.master.conf
然后启动从服务器:redis-server.exe redis.slave1.conf、redis-server.exe redis.slave2.conf
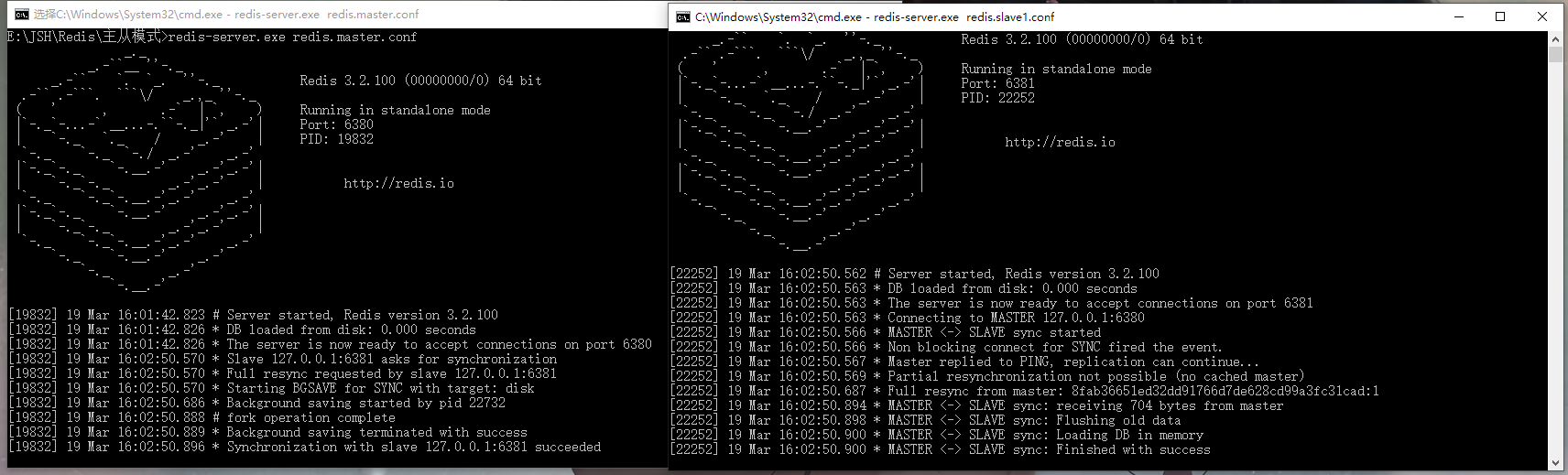
可以看到启动从服务器后会自动同步数据,现在可以启动redis客户端连接进行测试:redis-cli.exe -p 6380
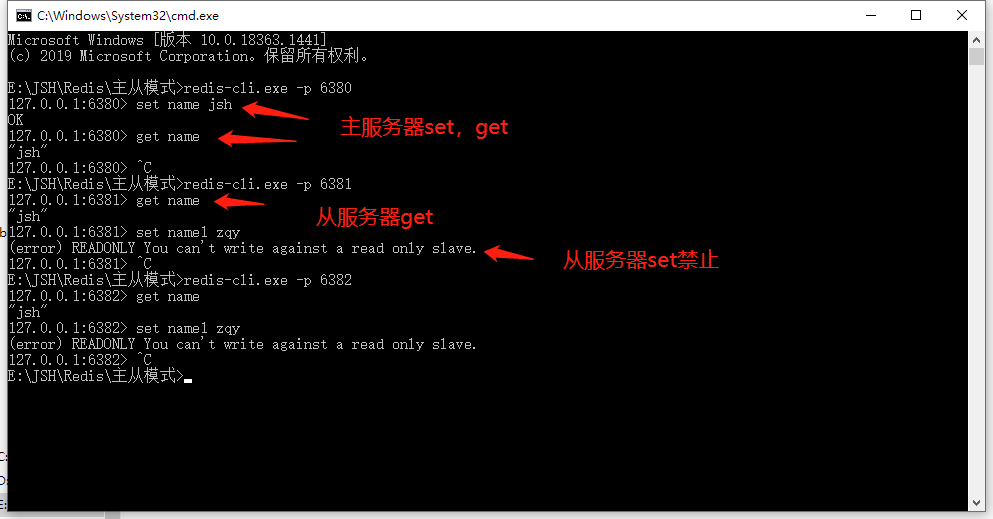
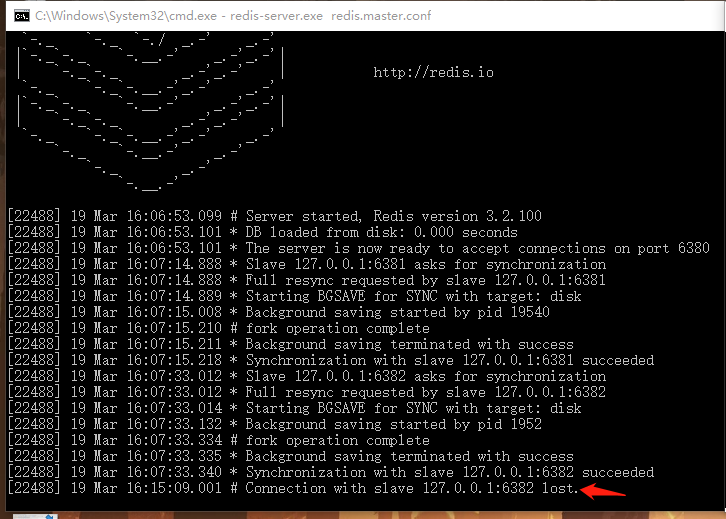
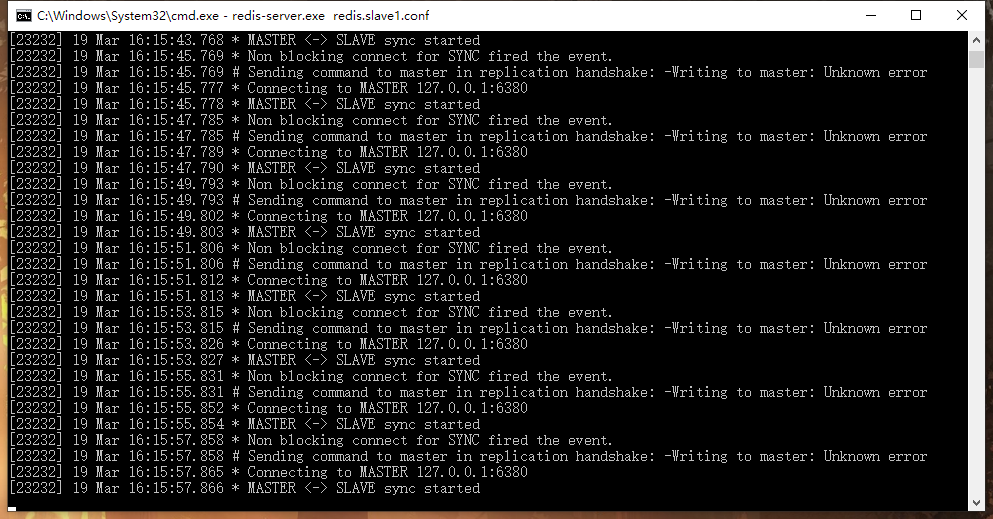
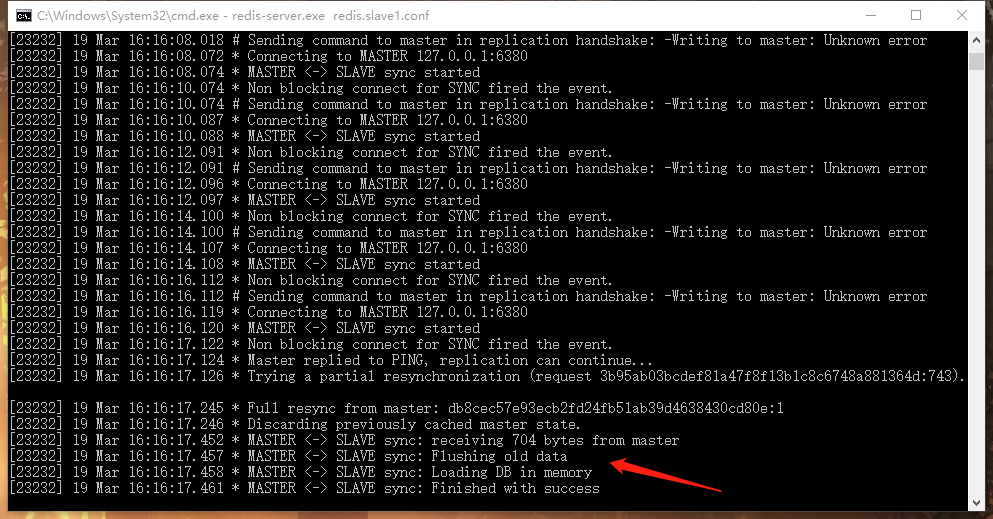
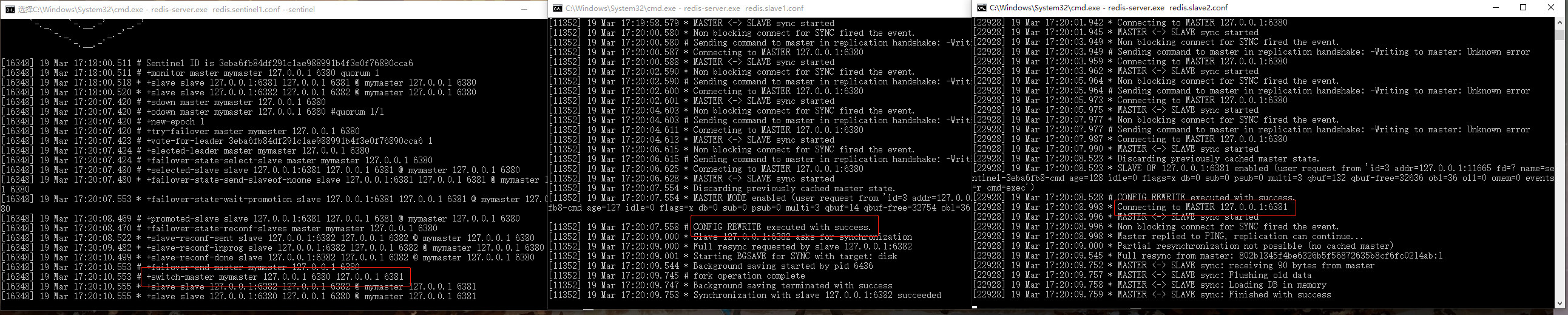
关闭一个slave在master控制台可以看到提示,关闭master在slave控制台可以看到一直尝试与主数据库同步但是一直失败,重启master后同步成功:
二、Sentinel模式:
哨兵模式建立在主从模式之上,弥补主从模式当master挂掉之后导致写操作不可用的问题,当master挂掉时会从slave中选举产生一个作为新的master,哨兵模式集群主要由主从模式加哨兵服务器构成。
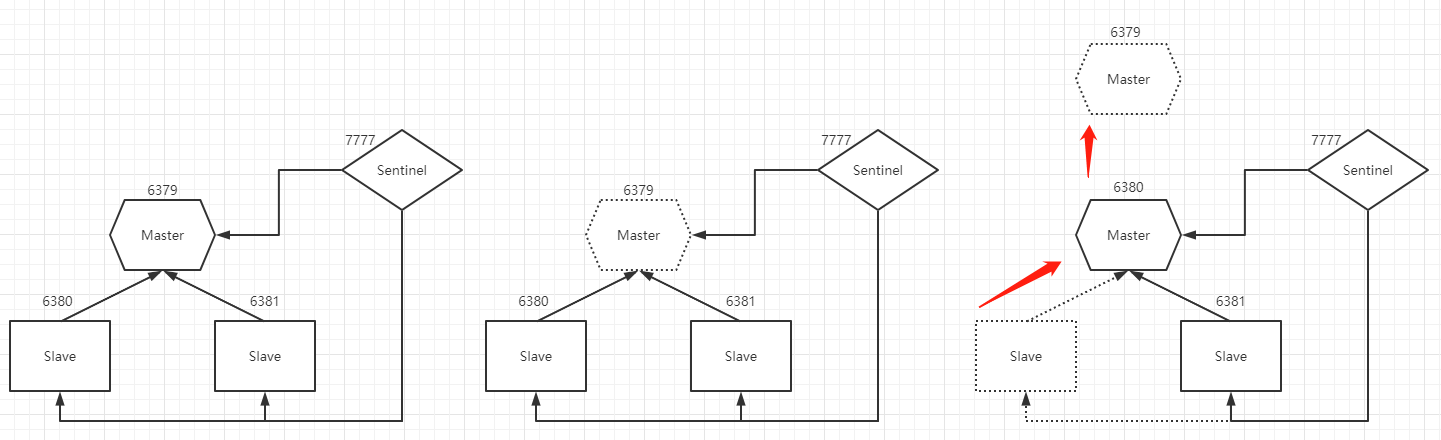
如上图,哨兵服务器监视着集群中服务器的状态,当master挂掉之后,哨兵会根据算法(投票或选举)在slave中选择一个将其晋升为master服务器。
由于算法的原因,推荐哨兵服务器是3个以上的奇数,而且slave服务器至少也要有两个,我这里演示就用的一个哨兵服务器作测试:
哨兵模式搭建方法:
准备主从模式所需文件并追加一个哨兵服务器的配置文件,再次强调本文仅用于演示只是用了一个哨兵,真实环境建议使用3个以上的奇数哨兵:
哨兵服务器的配置文件比较简单,通用的有哨服务器的ip、端口,需要新加的一项是要监视的maser信息,还有一些可选项包括宕机时间判定、故障转移超时等,大家可自行百度:

然后按照主从模式的步骤启动服务器,然后使用命令:redis-server.exe redis.sentinel1.conf --sentinel启动哨兵服务器:
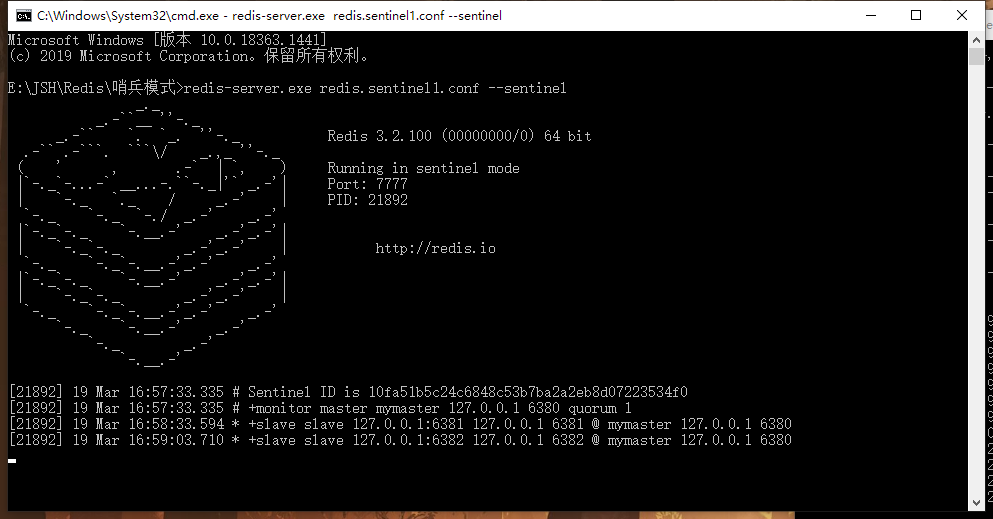
可以在哨兵服务器的控制台看到监视的集群的信息。
手动关闭master,在默认的宕机响应时间后,哨兵将6381晋升为了新的master。注意在故障转移的时候会修改配置文件,下一次启动时6381就是master服务器了,剩下两个成为slave了。
三、Cluster模式:
哨兵模式很好地实现了高可用,在master挂掉的时候可以及时将slave晋升为主节点,保证了服务的可用性。但其也只是在主从模式上新增了一个晋升机制,使其具备了高可用的特性,
master节点始终只有一个,当数据操作频繁时,写入将会成为性能瓶颈。所以在Redis3.0后加入了全新的Cluster模式,它采用了去中心方式,将数据通过一致性哈希算法进行存取。
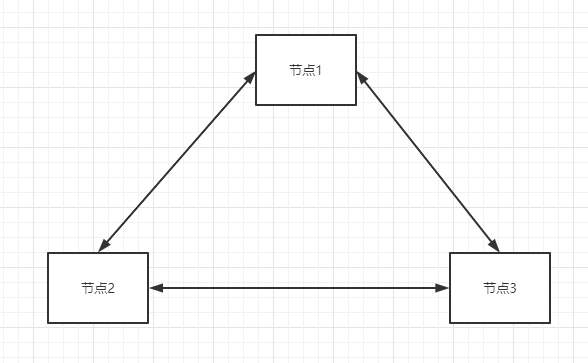
一个cluster集群由多个节点组成,每个节点都是互相连接的,会将信息及时地进行交换保证新加入或是宕机后服务的可用性,以及大数据情况下的稳定运行。ps:节点多了,自然负载就提高了。
同时为了保证高可用,,通常在使用cluster模式搭建集群时还会为每个主节点添加slave,即如下图所示:
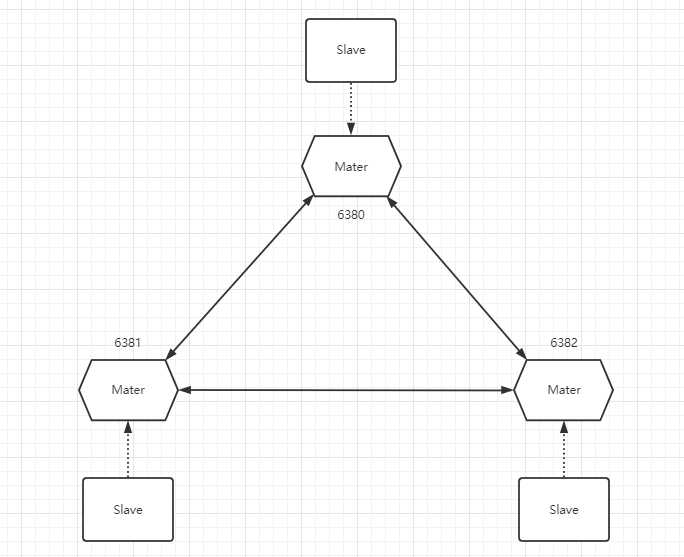
当然也可以为每个master节点设置两个或者更多的slave节点,是不是有点像在之前3个主从模式的基础上再进行了一次组合。这样cluster集群就有了3个可以写入操作的节点,所有节点均可读取数据,
当主节点挂掉之后,其下的slave会自动根据算法进行晋升(类似哨兵模式),保证主节点的数量。并且cluster还方便维护人员添加删除节点,分配槽(slot)等操作。
Redis3.0推出cluster集群模式,Redis5.0之前使用Ruby来构建cluster集群,5.0之后直接使用redis-cli --cluster来构建cluster集群。本文使用的是5.0之后的Linux版本演示(懒得安Ruby)。
Linux下的Redis安装就不做过多赘述,大家可自行百度。安装完redis后,这里准备使用上图所示的6节点模式,即3主3从。
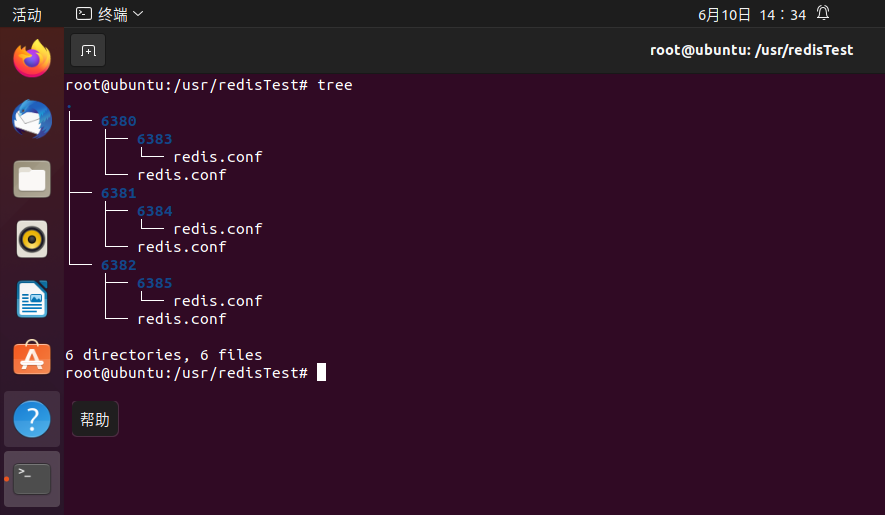
1.首先准备6个文件夹放6份配置文件,这里我刚开始想的是6380、6381、6382作为主节点,6383、6384、6385分别为对应的从节点,结果后面不小心写错了导致从属关系没对应上,无伤大雅让大家了解这个过程就行了,
ps:这才6个节点我就搞晕了,具体上线还是交给专业的运维吧!!!QAQ
2.然后是修改配置文件:端口(port:6380)、开启cluster模式(cluster-enabled yes)、节点配置文件(cluster-config-file nodes-6380.conf)、Pid文件(pidfile /var/run/redis-6380.pid),注意都要与各自的端口号对应。
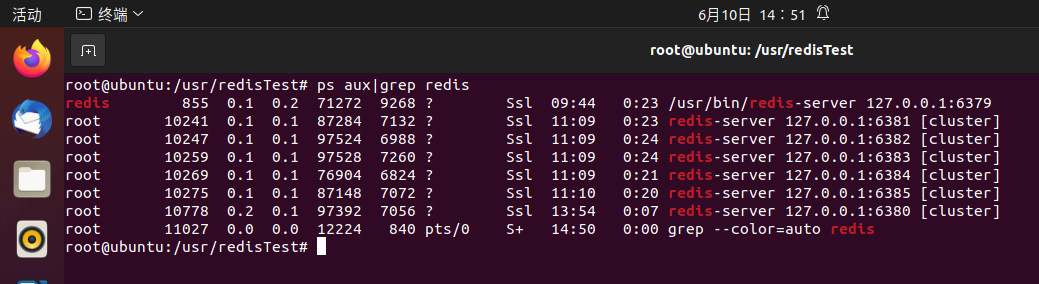
3.使用redis-server命令启动6个实例,注意使用各自的配置文件,并使用ps aux|grep redis查看服务是否开启成功。
4.接下来就是一系列的cluster操作,cluster命令是cluster集群所独有的,大家可查阅相关资料学习,这里推荐大神的文章--“Redis Cluster日常操作命令梳理”。
过程中可能遇到各种错误,本人再尝试过程中也是遇到各种各样的小问题,但是基本上百度都有,毕竟有人先试过水了。值得注意的一点就是使用redis-cli连接节点时要带上-c参数,表示使用cluster模式。
完成之后就可以通过cluster info查看集群信息,cluster nodes查看所有节点及其信息。
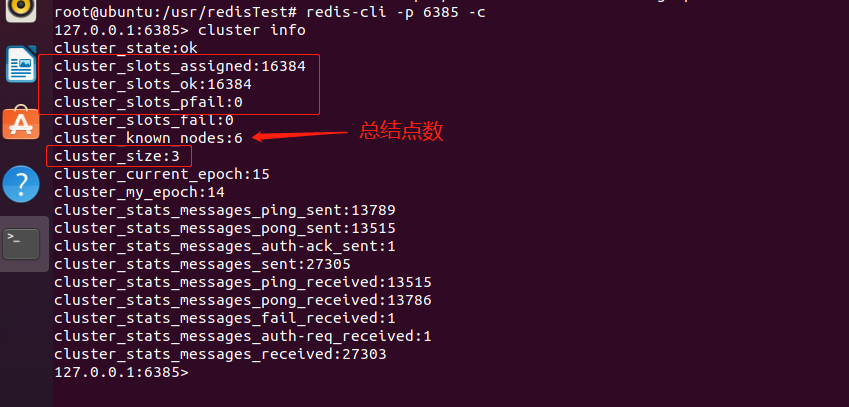
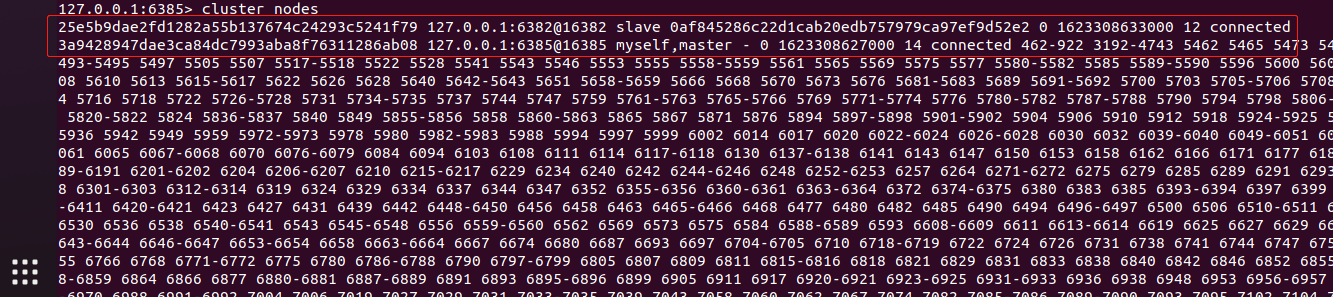
从截图可以看到相应的ID、主从关系、分配的槽点等。随便设置了几个数据测试了没有问题:

值得注意的是,由于数据是严格按照分配的槽进行存储的,所以会redirected到指定槽点的节点。ps:cluster模式虽好,配置运维也麻烦,还有各种数据同步机制,恢复机制,不得不佩服开发的大佬啊。
虽然写的不是很全面,但是大体功能是实现了,本文仅作个人练习参考,欢迎大家指正错误。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号