
redis
Nosql
Nosql(not only sql) 意为不仅仅是SQL
NoSql泛指非关系型数据库。例如谷歌和Facebook每天为他们的用户收集上万条数据,这些数据库不需要固定的格式,无多余的操作就可以横向扩展
为什么会出现nosql?
传统关系型数据库的瓶颈: 1,无法应对每秒上万次的读写请求,硬盘IO此时也将变为性能瓶颈 2,表中存储记录数量有限,横向可扩展能力有限,纵向数据可承受能力也是有限的,面对海量数据,势必涉及到分库分表,难以维护 大数据查询SQL效率极低,数据量到达一定程度时,查询时间会呈指数级别增长 3,难以横向扩展,无法简单地通过增加硬件、服务节点来提高系统性能 对于需要24小时不间断提供服务的网站来说,数据库升级、扩展将是一件十分麻烦的事,往往需要停机维护,数据迁移,为了避免服务间断,如果网站使用服务器集群,则根据集群策略,
需要相应的考虑主从一致性、集群扩展性等一系列问题
nosql的优势?
1,海量数据下,读写性能优异(一秒读11万,写8万)
2,数据模型灵活.无需事先为数据建立字段,随时可以储存自定义的数据格式,很方便的增删字段
3,数据间无关系,易于扩展(没有连表查询)
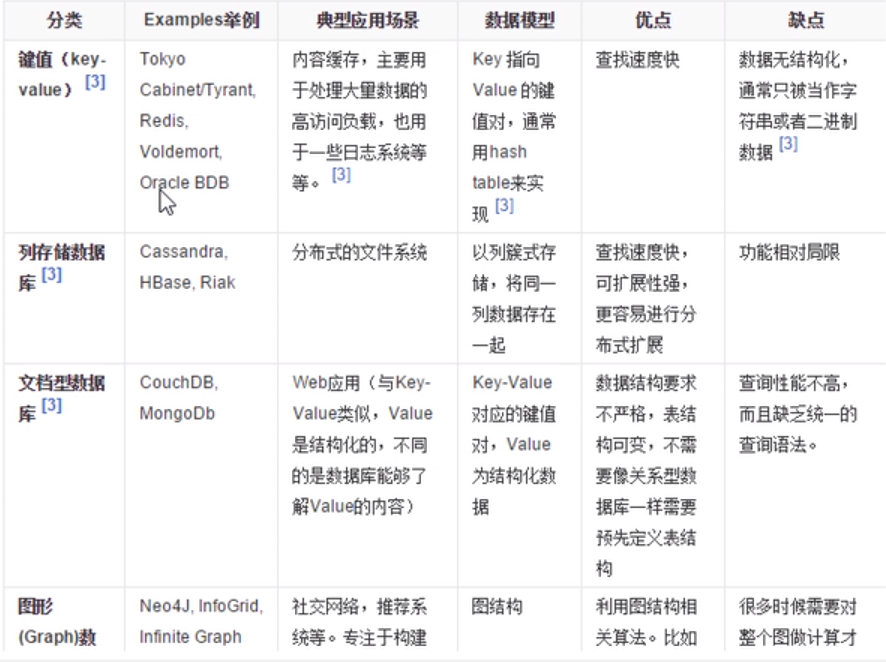
nosql数据库的四大分类
第一类:kv键值, memcache ,redis
第二类:文档型数据库, MongoDB 基于分布式文档数据库
第三类:列存储数据库
第四类:图关系数据库 存放的是朋友圈的社交关系等,不是放图形的
四大类的对比:
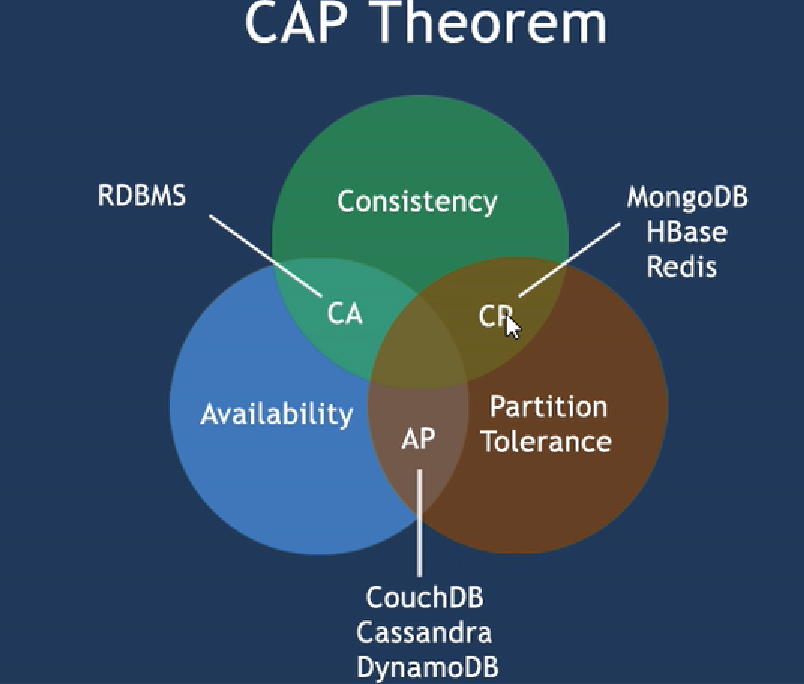
在分布式数据库中的CAP原理和BASE
CAP: 1.consistency 强一致性
2.avalibality 可靠性
3. partition tolerance 分区容错性
CAP的核心理论:一个分布式系统不可能同时满足以上的三个要求,最多只能同时较好的满足两个. 而由于当前的网络硬件,肯定会出现延迟和丢包问题,所以分区容忍性是我们必须要实现的.
所以我们只能在强一致性和高可用之间选一个
AP是大多数网站架构的选择

BASE就是为了解决关系型数据库的强一致性引起的问题而引起的可用性降低而提出的解决方案.

分布式和集群
分布式:不同的多台服务器上部署不同的服务模块,它们之间通过RPC/Rmi之间通信和调用,对外提供服务和组内协作.
集群:不同的多台服务器上部署这相同的服务模块,通过分布式的调度软件进行统一的调度,对外提供服务和访问
REDIS
redis: REmote DIctionary Server (远程字典服务器).是一个高性能(key/value)分布式内存数据库。
redis能干嘛?
1.做数据缓存,提高数据的读写速度.
2.排行榜,比如取最新的N个数据的操作.
3.利用redis发布订阅构建实时消息推送系统
4.计数器.利用Redis中原子性的自增操作,我们可以统计类似用户点赞数、用户访问数等,这类操作如果用MySQL,频繁的读写会带来相当大的压力
5.设置精准的抢购时间,利用键值的过期时间,比如淘宝要在9点钟开始对某种商品为期1小时的抢购活动,可以把这种商品的键值的过期时间,设为一小时
与Memcached的区别
- 它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型),memcached仅支持一种字符串.
- redis支持数据的持久化.可以将内存中的数据保存到硬盘中,重启加载的时候再从内存中读取出来.memcached 不支持.
- redis支持数据的备份,即主从复制
和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
linux中redis的安装
注意偶数版本是稳定版本,下载的时候要下载稳定版本
- cd 到 application 中
- 下载 wget http://download.redis.io/releases/redis-3.2.10.tar.gz.
-
tar xzf redis-3.2.10.tar.gz 解压到当前的文件夹
- cd 到 redis中
- make 编译
这时候如果出现问题,会报没有gcc
gcc是linux下的一个编译程序,用c写的
安装 gcc
yum install gcc-c++
启动redis
在redis 中 执行 redis服务端启动:要加&这样是为了能后台挂起 src/redis-server & 然后redis客户端启动 执行src/redis-cli 就会得到这样的结果: 127.0.0.1:6379>
查看redis服务端是否启动
ps -ef|grep redis
关闭redis
shutdown 关闭redis服务器
exit 退回到redis 目录中 关闭redis客户端
配置文件
redis的配置文件在安装目录下,
一般的我们自己修改的配置文件我们会放在/etc下
第一步: cd 到 /etc
第二步: 创建redis.conf 文件 vi redis.conf (不要用vim,不知道为什么,vim打开和vi打开的东西不一样)
第三步:写入配置文件
#redis.conf 是否后台运行: daemonize yes #默认端口改为6389: port 6389 AOF日志开关是否打开: appendonly no/yes #日志文件位置 logfile /var/log/redis.log #RDB持久化数据文件的名字: dbfilename dump.rdb #持久化文件的位置 dir /data/redis
第四步:进入到redis的安装目录
cd /application/redis
第五步:启动redis服务端加配置文件路径
src/redis-server /etc/redis.conf
第六步:启动客户端
src/redis-cli -p 6389
结果:
src/redis-cli -p 6389
远程登录redis

使用密码登录
src/redis-cli -h 10.0.0.200 -a 123456 -p 6389
第二种方法:
src/redis-cli -h 10.0.0.200 -p 6389 #先登录
auth 123456 #再输入密码
redis的一些杂知识
- redis是单进程下的单线程
redis 是单进程单线程模式,串行访问,并不会出现并发,因为它是缓存于内存中,处理速度飞快,一般不会出现高并发.
Redis为单进程单线程模式,采用队列模式将并发访问变成串行访问,且多客户端对Redis的连接并不存在竞争关系。其次Redis提供一些命令SETNX,GETSET,可以方便实现分布式锁机制
2.redis默认有16个库. 这个在配置文件中有介绍
可以选择数据库存储数据 127.0.0.1:6379> select 5 #选择6号数据库 OK 127.0.0.1:6379[5]> #括号中的5代表6号数据库,因为1号数据库的下标为0
3.dbsize:查看当前数据库的键的数量
4.flushdb 清除当前库,flush 清除所有库的数据
5.默认端口号:6379
redis的数据类型
redis支持的5大数据类型数据类型:
{ k1: 12, # 字符串(string) k2: [11,22], #列表 (list) k3: {11,22,33}, #集合(set) k4: {kk1:123,} , #字典(hash) k5: {('v1',1),('v2',3),('v2',9),} #有序集合(zset) }
键值
1. keys * #查看该库下所有的键,不建议用 2. exits key的名字 #判断某个key是否存在 3. move counrty 2 #把当前库的county 键移动到2号库 4.expire country 5 #为键county设置过期时间(秒) 5. ttl key #查看某个key还有多少秒过期 -1表示永不过期,-2表示已过期 6.type key #查看某个key的类型
字符串
redis中的String在在内存中按照一个name对应一个value来存储。
1.set(name, value, ex=None, px=None, nx=False, xx=False) 设置键值
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行
2.setnx(name, value) 设置值,只有name不存在时,执行设置操作(添加)
3.setex(name, value, time)
|
1
2
3
|
# 设置值# 参数: # time,过期时间(数字秒 或 timedelta对象) |
4.mset(*args, **kwargs) 批量设置键值
mset k1 11 k2 12
5.get() 获取值
6.mget(*args,**kwargs) 批量获取值
mget k1 k2
7.append(key, value)
# 在redis name对应的值后面追加内容 # 参数: key, redis的name value, 要追加的字符串
8.getrange (key,起始索引,终止索引) 根据索引切割值
127.0.0.1:6379[3]> set dd wechina 127.0.0.1:6379[3]> GETRANGE dd 0 3 #结果 "wech"
9.setrange(key,要覆盖的开始索引,替换的值)
OK 127.0.0.1:6379> get dd "weloveyou" 127.0.0.1:6379> setrange dd 6 china (integer) 11 127.0.0.1:6379> get dd "welovechina"
列表
redis中的List在在内存中按照一个name对应一个List来存储
lpush(name,values) 在name对应的list中添加元素,每个新的元素都添加到列表的最左边, 扩展:rpush(name, values) 表示从右向左操作.
lrange(name,start,end) :在name对应的列表分片获取数据.
127.0.0.1:6379> Lpush l1 1 2 3 5
(integer) 4
127.0.0.1:6379> LRANGE l1 0 -1
1) "5"
2) "3"
3) "2"
4) "1"
lpop(name) 把列表中左边第一个元素移除,并返回移除的元素
rpop(name):把列表中最右边第一个元素移除,并返回移除的元素
127.0.0.1:6379> lrange l1 0 -1 1) "8" 2) "5" 3) "3" 4) "2" 5) "1" 127.0.0.1:6379> lpop l1 "8" 127.0.0.1:6379> lrange l1 0 -1 1) "5" 2) "3" 3) "2" 4) "1"
lindex(name,index)在name对应的列表中根据索引获取列表元素
127.0.0.1:6379> lrange l1 0 -1 1) "5" 2) "3" 3) "2" 4) "1" 127.0.0.1:6379> lindex l1 1 "3"
llen(name):# name对应的list元素的个数
lrem(name,要删除的个数,要删除的值)
(integer) 6 127.0.0.1:6379> lrange k1 0 -1 1) "5" 2) "6" 3) "5" 4) "3" 5) "3" 6) "1" 127.0.0.1:6379> LREM k1 2 3 #删除 k1对应的列表中的2个3 (integer) 2 127.0.0.1:6379> lrange k1 0 -1 1) "5" 2) "6" 3) "5" 4) "1"
ltrim(name, start, end):从name对应的列表中根据索引截取指定范围的值再赋给name
127.0.0.1:6379> lrange h1 0 -1 1) "8" 2) "7" 3) "6" 4) "5" 5) "4" 6) "3" 7) "2" 8) "1" 127.0.0.1:6379> ltrim h1 1 5 OK 127.0.0.1:6379> lrange h1 0 -1 1) "7" 2) "6" 3) "5" 4) "4" 5) "3"
rpoplpush(src, dst) src对应的列表中的右边第一个值删除并添加到dst对应列表中的最右边,返回src中移除的值


127.0.0.1:6379> lrange k3 0 -1 1) "5" 2) "4" 3) "3" 4) "2" 5) "1" 127.0.0.1:6379> lrange k2 0 -1 1) "e" 2) "d" 3) "c" 4) "b" 5) "a" 127.0.0.1:6379> rpoplpush k3 k2 "1" 127.0.0.1:6379> lrange k3 0 -1 1) "5" 2) "4" 3) "3" 4) "2" 127.0.0.1:6379> lrange k2 0 -1 1) "1" 2) "e" 3) "d" 4) "c" 5) "b" 6) "a"
自定义迭代
由于redis类库中没有提供对列表元素的增量迭代,如果想要循环name对应的列表的所有元素,那么就需要:
1、获取name对应的所有列表
2、循环列表
但是,如果列表非常大,那么就有可能在第一步时就将程序的内容撑爆,所有有必要自定义一个增量迭代的功能:
import redis pool = redis.ConnectionPool(host='127.0.0.1',port=6379,db=1) r = redis.Redis(connection_pool=pool) def list_iter(name): list_count = r.llen(name) for index in range(list_count): yield r.lindex(name,index) for item in list_iter("key"): print(item)
集合
Set操作,Set集合就是不允许重复的字符串, 单key多value
sadd(name,values) # name对应的集合中添加元素
smembers(name) 获取name对应的集合的所有成员
scard(name) 获取name对应的集合中元素个数
127.0.0.1:6379> sadd set01 1 1 2 2 3 (integer) 3 127.0.0.1:6379> SMEMBERS set01 1) "1" 2) "2" 3) "3" 127.0.0.1:6379> SCARD set01 (integer) 3
srem(name, values)# 在name对应的集合中删除某些值
srandmember(name, numbers)
|
1
|
# 从name对应的集合中随机获取 numbers 个元素 |
smove(src, dst, value)
|
1
|
# 将某个成员从一个集合中移动到另外一个集合 |
sismember(name, value)
|
1
|
# 检查value是否是name对应的集合的成员 |
spop(name)
|
1
|
# 从集合的随机移除一个成员,并将其返回 |
sunion(keys, *args)
|
1
|
# 获取多一个name对应的集合的并集 |
- SSCAN 命令用于迭代集合键中的元素。
字典hash: hash 类型 key不变,value是键值的形式
hset(name, key, value) name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
hget(name,key)# 在name对应的hash中获取根据key获取value
127.0.0.1:6379> hset user id 1 (integer) 1 127.0.0.1:6379> hget user id "1"
127.0.0.1:6379[2]> hgetall id
1) "name"
2) "alex"
3) "age"
4) "11"
5) "sex"
6) "man"
hmset(name, mapping): 在name对应的hash中批量设置键值对
hmget(name, keys, *args):# 在name对应的hash中获取多个key的值
hgetall(name)获取name对应hash的所有键值
27.0.0.1:6379[2]> hmset id name alex age 11 sex man OK 127.0.0.1:6379[2]> hmget id name age sex 1) "alex" 2) "11" 3) "man"
hdel(name,*keys)# 将name对应的hash中指定key的键值对删除
hlen(name)
|
1
|
# 获取name对应的hash中键值对的个数 |
hkeys(name)
|
1
|
# 获取name对应的hash中所有的key的值 |
hvals(name)
|
1
|
# 获取name对应的hash中所有的value的值 |
hexists(name, key)
|
1
|
# 检查name对应的hash是否存在当前传入的key |
hscan(name, cursor=0, match=None, count=None)(在redis模块中存在)
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆# 参数:# name,redis的name# cursor,游标(基于游标分批取获取数据)# match,匹配指定key,默认None 表示所有的key# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数# 如:# 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)# 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)# ...# 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕hscan_iter(name, match=None, count=None)(在redis模块中存在)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据# 参数:# match,匹配指定key,默认None 表示所有的key# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数# 如:# for item in r.hscan_iter('xx'):# print item
有序集合
有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
zadd(name, *args, **kwargs)
# 在name对应的有序集合中添加元素# 如:# zadd('zz', 'n1', 1, 'n2', 2)# 或# zadd('zz', n1=11, n2=22)zcard(name)
# 获取name对应的有序集合元素的数量zcount(name, min, max)
# 获取name对应的有序集合中分数 在 [min,max] 之间的个数zincrby(name, value, amount)
# 自增name对应的有序集合的 name 对应的分数r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
# 按照索引范围获取name对应的有序集合的元素# 参数:# name,redis的name# start,有序集合索引起始位置(非分数)# end,有序集合索引结束位置(非分数)# desc,排序规则,默认按照分数从小到大排序# withscores,是否获取元素的分数,默认只获取元素的值# score_cast_func,对分数进行数据转换的函数# 更多:# 从大到小排序# zrevrange(name, start, end, withscores=False, score_cast_func=float)# 按照分数范围获取name对应的有序集合的元素# zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float)# 从大到小排序# zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)zrank(name, value)
# 获取某个值在 name对应的有序集合中的排行(从 0 开始)# 更多:# zrevrank(name, value),从大到小排序zrangebylex(name, min, max, start=None, num=None)
# 当有序集合的所有成员都具有相同的分值时,有序集合的元素会根据成员的 值 (lexicographical ordering)来进行排序,而这个命令则可以返回给定的有序集合键 key 中, 元素的值介于 min 和 max 之间的成员# 对集合中的每个成员进行逐个字节的对比(byte-by-byte compare), 并按照从低到高的顺序, 返回排序后的集合成员。 如果两个字符串有一部分内容是相同的话, 那么命令会认为较长的字符串比较短的字符串要大# 参数:# name,redis的name# min,左区间(值)。 + 表示正无限; - 表示负无限; ( 表示开区间; [ 则表示闭区间# min,右区间(值)# start,对结果进行分片处理,索引位置# num,对结果进行分片处理,索引后面的num个元素# 如:# ZADD myzset 0 aa 0 ba 0 ca 0 da 0 ea 0 fa 0 ga# r.zrangebylex('myzset', "-", "[ca") 结果为:['aa', 'ba', 'ca']# 更多:# 从大到小排序# zrevrangebylex(name, max, min, start=None, num=None)zrangebyscore(name,min,max,start=None,num=none,withscores=False, score_cast_func=float) ,根据分数范围取值,withscores=False 不包含两头的分数
print(r.zrangebyscore('name',80,100,start=0,num=2)) #从符合要求的集合中索引为0的开始取前两个 结果: ['英语', 'chinese']
zrem(name, values)
# 删除name对应的有序集合中值是values的成员# 如:zrem('zz', ['s1', 's2'])zremrangebyrank(name, min, max)
# 根据排行范围删除zremrangebyscore(name, min, max)
# 根据分数范围删除zremrangebylex(name, min, max)
# 根据值返回删除zscore(name, value)
# 获取name对应有序集合中 value 对应的分数zinterstore(dest, keys, aggregate=None)
# 获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作# aggregate的值为: SUM MIN MAXzunionstore(dest, keys, aggregate=None)
# 获取两个有序集合的并集,如果遇到相同值不同分数,则按照aggregate进行操作# aggregate的值为: SUM MIN MAXzscan(name, cursor=0, match=None, count=None, score_cast_func=float)
zscan_iter(name, match=None, count=None,score_cast_func=float)
# 同字符串相似,相较于字符串新增score_cast_func,用来对分数进行操作
redis的持久化
RDB(redis database):在指定的时间间隔内将内存中的数据写入到硬盘中,行话叫snapshot快照,恢复时将快照文件读到内存中.
redis会单独创建(fork)一个子进程来进行持久化,当到了指定时间后,会将数据写到一个临时文件中,当到了下一个指定的时间后,下一个临时文件会替换上一个文件.整个持久化过程不会有io操作,保证了持久化的准确度,
优点: 当你需要进行大规划的数据恢复时,并且对恢复数据的完整性要求不高,RDB比AOF更加高效.
缺点:1.如果redis意外挂掉,就会丢失最后一次的持久化数据,也就是不能保证数据的完整性和一致性
2.rdb会经常fork一个子进程来保存数据到硬盘上,如果数据量很大的话fork是非常耗时的和增加内存开销的.
RDB保存的是dump.rdb文件
#在配置文件中指定时间间隔来持久化
save 60 2 #意思是当我60秒内 有两个键值改动就会触发rdb的持久化
默认是指定的时间间隔
save 900 1
save 300 10
save 60 10000
如何想禁用rdb持久化 在配置文件中禁用掉save 参数
如果想立即持久化数据 save/bgsave,这两个命令的不同之处在于前者使用redis的主线程进行同步转存,而后者则在后台进行转存,因为save命令会阻塞redis服务器,所以永远不要在生产中用save命令来立即持久化.
如何恢复备份数据?
答:将备份文件移动到redis的安装目录,并启动服务即可
AOF(append only file) :是一种只记录redis写入命令的追加式日志文件. redis重启的话就是根据日志文件内容将写指令重新执行一遍以完成数据的工作
默认是关闭aof 的这个功能
AOF默认文件名是 appendonly.aof aof 的持久化策略: 1.always :同步持久化,一发生数据变动就会持久化 2.everysec 每秒钟持久化策略 默认就是这个 3.no 永不持久化策略 #如果操作系统崩溃,那么AOF文件的最后可能会损坏或截断.redis提供了一个工具,redis-check-aof,用于修复损坏的文件.如果需要修复一个aof文件,只需要运行 redis-check-aof --fix appendonly.aof
AOF重写:随着redis将写入命令追加到aof文件中,aof文件的大小会显著增加,这会拖慢redis启动时的数据重建过程,redis提供了AOF重写来压缩aof文件,只保留可以恢复的最小指令.我们可以使用bgrewriteaof
命令来启动重写过程.
redis会自动创建一个子进程来执行aof重写,这个子进程会创建一个新的aof文件来存储重写的结果,以防止重写失败时影响旧的aof文件,
自动触发aof重写的机制
auto-aof-rewrite-percentage 100 #redis会记录最后一次aof重写操作的文件大小,如果当前的aof文件大小增长超过了这个百分比,则触发一次重写,将此值设置为0将禁用aof自动重写功能.默认值是100 auto-aof-rewrite-min-size 64mb #当aof的文件大小超过了这个最小值,将会自动触发aof自动重写功能.默认是64MB,实际生产中至少3GB以上
aof的优势:1.数据的完整性和一致性要比rdb要好
2.aof文件的内容非常容易让你读懂,不让rdb是16进制文件
aof的劣势:1.相同数据集的数据,aof文件要远大于rdb文件,
2.恢复速率慢
redis中同时有rdb和aof文件该如何加载? 会先加载aof文件,因为aof文件保存的数据集比rdb要完整.
现实中我们不用aof,我们用主从复制
连接池和redis模块
redis模块
1)操作模式 python提供两个类Redis和StrictRedis, StrictRedis用于实现大部分官方的命令,Redis是StrictRedis的子类,用于向后兼用旧版本。 #!/usr/bin/env python3 #coding:utf8 import redis r = redis.Redis(host='0.0.0.0', port=6379) # r = redis.StrictRedis(host='0.0.0.0', port=6379) # 如果要指定数据库,则 r = redis.StrictRedis(host='0.0.0.0', port=6379, db=0) r.set('name', 'test') print(r.get('name')) # 输出结果 b'test' #str 还是 byte? 通过上面的简单测试,看到redis 取出的结果默认是字节,我们可以设定decode_responses=True 改成字符串。 import redis r = redis.redis(host='0.0.0.0', port=6379, decode_responses=True) r.set('c', 'python') ret = r.get('c') print(ret ,type(ret)) # 结果 python <class 'str'>
连接池
连接池的目的:减少与数据库的连接次数,提高运行性能
Redis 是基于内存的数据库,使用之前需要建立连接,建立断开连接需要消耗大量的时间。
首先Redis也是一种数据库,它基于C/S模式,因此如果需要使用必须建立连接,稍微熟悉网络的人应该都清楚地知道为什么需要建立连接,C/S模式本身就是一种远程通信的交互模式,因此Redis服务器可以单独作为一个数据库服务器来独立存在。假设Redis服务器与客户端分处在异地,虽然基于内存的Redis数据库有着超高的性能,但是底层的网络通信却占用了一次数据请求的大量时间,因为每次数据交互都需要先建立连接,假设一次数据交互总共用时30ms,超高性能的Redis数据库处理数据所花的时间可能不到1ms,也即是说前期的连接占用了29ms.
这里学到的知识点:
当你在Django中调用settings.py文件时,不要这样调用
from app01 import settings
应该这样调用
from django.conf import settings #这样导入的setting文件多,其实settins.py中只放了部分配置文件,更多的在global setting中,如果你用了上面的方法导入,将覆盖掉global setting中的配置文件
import redis pool=redis.ConnectionPool(host='127.0.0.1',port=6379) conn=redis.Redis(connection_pool=pool) conn.set('name','alex') print(conn.get('name'))
结果:
b'alex'
https://www.cnblogs.com/melonjiang/p/5342505.html
操作
mport redis conn = redis.Redis(host='127.0.0.1',port=6379) # 1.集合基本操作 # 1表示:添加成功 # 0表示:已经存在 # v = conn.sadd('xxxxxx','xl') # print(v) # values = conn.smembers('xxxxxx') # print(values) # 2. 列表基本操作 # 在列表的前面进行插入 # conn.lpush('user_list','xianglong') # conn.lpush('user_list','meikai') # conn.lpush('user_list','dawei') # 在列表的前面进行移除 # v = conn.lpop('user_list') # print(v) # 在列表的前面进行移除,如果列表中没有值:夯住 # v = conn.blpop('user_list') # print(v) # 在列表的后面进行插入 # conn.rpush('user_list','xinglong') # conn.rpush('user_list','jinjie') # 在列表的后面进行移除 # v = conn.rpop('user_list') # print(v) # 在列表的后面进行移除,如果列表中没有值:夯住 # v = conn.brpop('user_list') # print(v) # 有序集合 # conn.zadd('s8_score', 'meikai', 60, 'guotong', 30,'liushuo',90) # 根据分数从大到小排列,并获取最大的分值对应的数据 # val = conn.zrange('s8_score',0,0,desc=True) # print(val)
面试题
如果一个列表在redis中保存了10w个值,我需要将所有值全部循环并显示,请问如何实现?自定义scan_iter生成器 def list_scan_iter(name,count=3): start = 0 while True: result = conn.lrange(name, start, start+count-1) start += count if not result: break for item in result: yield item for val in list_scan_iter('num_list'): print(val)
消息队列
redis能实现两种消息队列模式:即发布订阅模式和生产者和消费者模式
订阅和发布模式
发布和订阅是进程间的一种通信方式
注意:公司不会用redis做消息中间件,一般用rabbitMQ
把发布和订阅的方法和属性定义成一个类
import redis class RedisHelper: def __init__(self): self.__conn=redis.Redis(host='127.0.0.1') self.chan_sub='fm104.5' self.chan_pub='fm104.5' def public(self,msg): """ 发布消息函数 :param msg: :return: """ self.__conn.publish(self.chan_pub,msg) #将信息发布到指定的频道 return True def subscrible(self): """ 订阅频道函数 :return: """ pub=self.__conn.pubsub()#生成一个pubsub pub.subscribe(self.chan_sub)#订阅某频道 pub.parse_response()#解析订阅发过来的内容 return pub
发布者
from s1 import RedisHelper obj=RedisHelper() obj.public("hello world")
订阅者
from s1 import RedisHelper obj=RedisHelper() redis_sub=obj.subscrible() while True: msg=redis_sub.parse_response() print(msg)
订阅和发布的应用场景
微博的大v和粉饰之间就是订阅和发布的应用场景
生产者和消费模型
使用redis中的list数据结构可以实现消息队列.
redis中的lpush和rpop能实现这个功能,但是一般用brpop,brpop是redis中的阻塞的列表弹出原语,它是rpop的阻塞版本,它可以在列表中没有数据后,阻塞连接.不会出现错误.
管道(pipeline)
出现的背景: redis默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,这样如果执行命令多的话,网络传输会花费大量的时间,为了处理这个问题,redis提供了管道这个机制.
基本思想: 客户端将多个命令打包在一起并将他们一次性发送,而不再等待每个单独命令的执行结果,同时redis服务端会将所有的命令都执行完后再返回结果.
import redis pool=redis.ConnectionPool(host='127.0.0.1') conn=redis.Redis(connection_pool=pool) pipe=conn.pipeline(transaction=True) #默认就是true #开始事物 pipe.multi() pipe.set('name','xiaoming') #提交数据 pipe.execute()
事务
事物的具体概念在计算机网路第7版中是这样介绍的
所谓事务(transaction)就是一系列的信息交换.而这一系列的信息交换是不可分割的整体,也就是说要么所有的信息交换都完成,要么一次交换都不进行.
事务可以一次执行多个命令,本质就是一组命令的集合
import redis pool=redis.ConnectionPool(host='127.0.0.1') conn=redis.Redis(connection_pool=pool) pipe=conn.pipeline(transaction=True) #开始事物 pipe.multi() pipe.set('name','xiaoming') #提交数据 pipe.execute()
与关系型数据库的区别,redis事务具有部分回滚功能.一般情况下在redis事务中可能会出现两种类型的错误,而针对这两种类型的错误会采取不同的处理方式
错误一: 命令有语法错误,这样事务中的所有命令都不会执行,即回滚到事务开始的状态
127.0.0.1:6379> MULTI OK 127.0.0.1:6379> set a1 1 QUEUED 127.0.0.1:6379> set a2 2 QUEUED 127.0.0.1:6379> set a3 3 QUEUED 127.0.0.1:6379> sett df fdf (error) ERR unknown command 'sett' 127.0.0.1:6379> set a4 4 QUEUED 127.0.0.1:6379> exec (error) EXECABORT Transaction discarded because of previous errors.
错误二: 命令语法没有问题,命令都已经成功入队,但在执行过程中发生了错误,事务将不会回滚,哪条命令错了,哪条命令不执行,没有错误的命令继续执行
127.0.0.1:6379> MULTI OK 127.0.0.1:6379> incr k1 #由于k1对应的值不是数字,没办法加一 QUEUED 127.0.0.1:6379> set k2 22 QUEUED 127.0.0.1:6379> set k3 33 QUEUED 127.0.0.1:6379> set k4 v4 QUEUED 127.0.0.1:6379> get k3 QUEUED 127.0.0.1:6379> exec 1) (error) ERR value is not an integer or out of range 2) OK 3) OK 4) OK 5) "33"
watch
悲观锁:顾名思义就是很悲观,每次去拿数据都会认为别人会修改数据,所以每次在拿数据的时候都会上锁,这样别人只能等它开锁后,才能拿数据,传统的关系型数据库大多用到了这种锁,如表锁,行锁,读锁,写锁等.
乐观锁: 总是认为不会产生并发问题,每次去取数据的时候总认为不会有其他线程对数据进行修改,因此不会上锁,但是在更新时会判断其他线程在这之前有没有对数据进行修改,一般会使用版本号机制或CAS操作实现。
version方式:一般是在数据表中加上一个数据版本号version字段,表示数据被修改的次数,当数据被修改时,version值会加一。当线程A要更新数据值时,在读取数据的同时也会读取version值,在提交更新时,
若刚才读取到的version值为当前数据库中的version值相等时才更新,否则重试更新操作,直到更新成功。
出现watch的背景
redis watch 命令用于监视一个(或多个)key,如果在事务执行之前这些key被其他命令所改动,那么事物将被打断.
watch命令类似于乐观锁,事务提交时如果key被其他客户端更改了,那么事务中的所有命令将不会执行
由于WATCH命令的作用只是当被监控的键值被修改后阻止之后一个事务的执行,而不能保证其他客户端不修改这一键值,所以在一般的情况下我们需要在EXEC执行失败后重新执行整个函数。
执行EXEC命令后会取消对所有键的监控,如果不想执行事务中的命令也可以使用UNWATCH命令来取消监控。
- 检测,watch 面试题:你如何控制剩余的数量不会被其他客户端修改? - 通过redis的watch实现 import redis import time r=redis.Redis(host='122.114.182.64',port=6379,decode_responses=True,db=7) r.set('count',1000) with r.pipeline() as pipe: while True: try: # 关注一个key pipe.watch('count') old_count = pipe.get('count') # 一定要把查询的这步放到事务开始之前 old_count = int(old_count) time.sleep(6) #为其他客户端修改count赢得时间 #事物开始 pipe.multi() if old_count >0: pipe.set('count', old_count-1) # 事务结束 pipe.execute() # 把命令推送过去 break except Exception as e: #如果客户端有变动的话,那么就会触发这个异常。 print('有错误了',e)
redis 主从复制
出现背景: 在生产环境中,单个数据库实例常常存在系统崩溃,网路连接闪断或突然断电等单点故障问题,为解决这个问题,redis提供了主从复制机制.
主从复制:主机数据更新后,根据配置和策略自动同步到备机,master以写为主,slave只能读不能写
作用: 读写分离
容错率高
主从复制基于rdb的快照技术,但是不依赖与rdb
怎么配置:
#1.原则:配从不配主 #2 命令为: slaveof 主库ip 主库端口 每次从机与主机断开后都需要重新连接,如果你认为麻烦可以把他写到配置文件中 127.0.0.1:6382> slaveof 127.0.0.1 6380
查看主从命令信息
info replication
主从复制的2种方式
- 一主多仆:
6380 是主机 #在6381redis中设置 slaveof 127.0.0.1 6380 #在6382redis中设置 slaveof 127.0.0.1 6380
2. 薪火相传
6380是主机 #在6381服务器中设置 slaveof 127.0.0.1 6380 #在6382服务器中设置 slaveof 127.0.0.1 6381
当主机宕机了,如何把某个从机手动设为主机呢?
#在某个从机中这样设置 slaveof no one 这样该从机就自动设为主机了,
主从复制原理
主从复制原理: slave启动成功连接到master后会发出一个sync(同步)命令,master接收到该命令后启动后台的存盘进程,同时搜集所有接受到的修改数据集命令,在后台进程执行完毕后,master将传送整个数据文件到slave,以完成一次完全同步
全量同步:
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下:
- 从服务器连接主服务器,发送SYNC命令;
- 主服务器接收到SYNC命名后,开始执行持久化命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
- 主服务器持久化执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
增量同步
Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
Redis主从同步策略
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
redis-Sentinel
背景:如果主机宕机了,从机不会改变还是slave
redis-Sentinel是redis官方推荐的高可用性解决方案,假如redis的master服务器宕机了,首先redis自身并没有自动切换主备的功能,但是redis-Sentinel本身是一个独立运行的进程,他能监控多个主从复制集群,发现redis的master宕机了,自动切换到从机中.
具体原理为:
当一个主服务器不能正常工作时,Sentinel会开始一次自动故障迁移操作,它会将其中的一台salve服务器升级为主服务器,并让其他的从服务器自动复制新主服务器,使得集群可以使用新主服务器代替失效服务器.
作用:
- 监控主机是否发生故障
- 当主宕机了,根据投票自动切换到某个从机
sentinel配置
#创建新文件夹存放配置文件 mkdir /data/26380 #把安装目录下的redis-sentinel复制到 新建的文件夹下 cp /application/redis/src/redis-sentinel /data/26380 cd /data/26380 #在新文件夹下创建一个文件 vim sentinel.conf ----------------文件中写入以下内容--------------- port 26380 dir "/tmp" #当6380后边是2时表示企业当中有多台sentinel,当超过2台sentinel认为主机宕机了,才可以自动切换了,就是投票机制 sentinel monitor mymaster(自己起的名字) 127.0.0.1 6380 1 #当多少毫秒后感知不到主服务器了,就会自动切换 sentinel down-after-milliseconds mymaster 5000 sentinel config-epoch mymaster 0 ------------------------------------------------ 启动 src/redis-sentinel /data/26380/sentinel.conf
python3连接sentinel
#!/usr/bin/env python # -*- coding:utf-8 -*- from redis.sentinel import Sentinel # 连接哨兵服务器(主机名也可以用域名) sentinel = Sentinel([('10.211.55.20', 26379), ('10.211.55.20', 26380), ], socket_timeout=0.5) # # 获取主服务器地址 # master = sentinel.discover_master('mymaster') # print(master) # # # # 获取从服务器地址 # slave = sentinel.discover_slaves('mymaster') # print(slave) # # # # # 获取主服务器进行写入 # master = sentinel.master_for('mymaster') # master.set('foo', 'bar') # # # # 获取从服务器进行读取(默认是round-roubin) # slave = sentinel.slave_for('mymaster', password='redis_auth_pass') # r_ret = slave.get('foo') # print(r_ret)
redis cluster(集群)
出现背景
由于redis所存储的数据增长速度很快,一个存储了大量数据(通常16GB以上)的redis实例的处理能力和内存容量会变成应用瓶颈,这时候redis Cluster 就出现了
redis Cluster是一种开箱即用的解决方案,可以将数据集通过分区的方式分布到多个redis主从实例中去.
redis cluster 是基于分布式来完成的,集群将所有能放置数据的地方创建了16384个哈希槽,为每个主redis实例分配一定范围的哈希槽,取和存值的时候根据crc16算法把字符串转换为对应的数据,然后再和16384进行取余
python3连接集群
+++++++++++++++Python 连接 redis cluster+++++++++++++++++ (1) redis-py并没有提供redis-cluster的支持,去github找了一下,有个叫redis-py-cluster的源码, 但是和redis-py不是一个作者,地址为:https://github.com/Grokzen/redis-py-cluster watch,star,fork还算可以。 (2) 安装 unzip redis-py-cluster-unstable.zip cd redis-py-cluster-unstable python3 setup.py install (3) 使用 >>>from rediscluster import StrictRedisCluster >>>startup_nodes = [{"host": "127.0.0.1", "port": "7000"}] >>># Note: decode_responses must be set to True when used with python3 >>>rc = StrictRedisCluster(startup_nodes=startup_nodes, decode_responses=True) >>>rc.set("foo", "bar") >>>print(rc.get("foo"))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号