
C json实战引擎 三 , 最后实现部分辅助函数
引言
大学读的是一个很时髦的专业, 学了四年的游戏竞技. 可惜没学好. 但认真过, 比做什么都认真. 见证了 ......
打的所有游戏人物中 分享一位最喜爱 的

“I've been alone for 10 thousand years. 我孤独了一万年。”
“What I may be,whatever I may become in this world,know that I will always look out of you,Tyrande. 无论我做了什么,无论我变成什么样子,我会永远关心你的,泰兰德。”
前言
上一次 写了两篇 关于 C json 引擎 解析和 构造内容
结合上面加上当前这篇, 一个高效能用的 cjson 引擎就诞生了.
今天 , 分享这篇, 至少可以让大家, 学到简单深拷贝. 一些构造技巧. 还有就是cjson的辅助函数使用!
同样先分享一个函数 封装 开始.
/* * 这个代码是 对 strdup 的再实现, 调用之后需要free * str : 待复制的源码内容 * : 返回 复制后的串内容 */ char* str_dup(const char* str) { int len; char* nstr; DEBUG_CODE({ if (NULL == str) { SL_WARNING("check is NULL == str!!"); return NULL; } }); len = sizeof(char) * (strlen(str) + 1); if (!(nstr = malloc(len))) { SL_FATAL("malloc is error! len = %d.", len); return NULL; } // 返回最后结果 return memcpy(nstr, str, len); }
老代码中 有过 strdup 深拷贝 字符串, 后面各个平台支持的不一样 _strdup __strdup , strdup 各种. 后面为了统一写了一个.
其中 DEBUG_CODE 是对 assert 宏的扩展
/* * 10.1 这里是一个 在 DEBUG 模式下的测试宏 * * 用法 : * DEBUG_CODE({ * puts("debug start..."); * }); */ #ifndef DEBUG_CODE # ifdef _DEBUG # define DEBUG_CODE(code) code # else # define DEBUG_CODE(code) # endif // ! _DEBUG #endif // !DEBUG_CODE
在 _DEBUG模式下开启 测试代码, 没有_DEBUG处于发布状态的时候,这段检测代码编译的时候会被去掉. 为了效率而生.
对于SL_FATAL 是 sclog.h 接口中 一个 内部错误 日志宏. sclog.h 这个日志记录类, 也很不错. 前面博文中
最后那部分 讲解了 sclog.h 代码, 当时讲的的太多了,应该分开细说的. sclog.h 思路还是很不错的, 基本上业界大体也是这个思路.
多用户, 分级等手段. 前言已经介绍完了. 后面就随意了, 都可以不看了.
正文
1. cjson 辅助操作添加的接口
新加的接口如下
// --------------------------------- 下面是 cjson 输出部分的辅助代码 ----------------------------------------- /* * 创建一个bool的对象 b==0表示false,否则都是true, 需要自己释放 cjson_delete * b : bool 值 最好是 _Bool * : 返回 创建好的json 内容 */ extern cjson_t cjson_newnull(); extern cjson_t cjson_newbool(int b); extern cjson_t cjson_newnumber(double vd); extern cjson_t cjson_newstring(const char* vs); extern cjson_t cjson_newarray(void); extern cjson_t cjson_newobject(void); /* * 按照类型,创建 对映类型的数组 cjson对象 *目前支持 _CJSON_NULL _CJSON_BOOL/FALSE or TRUE , _CJSON_NUMBER, _CJSON_STRING * NULL => array 传入NULL, FALSE 使用char[],也可以传入NULL, NUMBER 只接受double, string 只接受char** * type : 类型目前支持 上面几种类型 * array : 数组原始数据 * len : 数组中元素长度 * : 返回创建的数组对象 */ extern cjson_t cjson_newtypearray(int type, const void* array, int len); /* * 将 jstr中 不需要解析的字符串都去掉 * jstr : 待处理的json串 * : 返回压缩后的json串内容 */ extern char* cjson_mini(char* jstr); /* * 将json文件解析成json内容返回. 需要自己调用 cjson_delete * jpath : json串路径 * : 返回处理好的cjson_t 内容,失败返回NULL */ extern cjson_t cjson_dofile(char* jpath); /* * 在array中分离第idx个索引项内容. * array : 待处理的json_t 数组内容 * idx : 索引内容 * : 返回分离的json_t内容 */ extern cjson_t cjson_detacharray(cjson_t array, int idx); /* * 在object json 中分离 key 的项出去 * object : 待分离的对象主体内容 * key : 关联的键 * : 返回分离的 object中 key的项json_t */ extern cjson_t cjson_detachobject(cjson_t object, const char* key);
前面是创建, 后面是分离, 分离的意思就是离开和上一轮没关系了. 线程也有分离的概念. 分离后自己自行回收.
其中 cjson_mini 是为了去掉 cjson 字符串中 无用的字符内容.
2. 摘录其中优秀的接口,分析设计
首先看看下面一个函数
/* * 将 jstr中 不需要解析的字符串都去掉,并且纪念mini 比男的还平 * jstr : 待处理的json串 * : 返回压缩后的json串内容 */ char* cjson_mini(char* jstr) { char* in = jstr; char* to = jstr; char c; while(!!(c=*to)){ if(sh_isspace(c)) ++to; else if(c == '/' && to[1] == '/') while((c=*++to) && c!='\n'); else if(c == '/' && to[1] == '*'){ while((c=*++to) && !(c=='*' && to[1] =='/')) ; if(c) to+=2; } else if(c=='"'){ *in++ = c; while((c=*++to) && (c!='"' || to[-1]=='\\')) *in++ = c; if(c) { *in++=c; ++to; } } else *in++ = *to++; } *in = '\0'; return jstr; }
思路是 先去掉空格字符, 后面去掉 // 和 /* */ 注释内容. 再对于 "" 包裹的字符串特殊处理. 其它字符原封不动 . 其中 sh_isspace 宏设计
如下
/* * c 如果是空白字符返回 true, 否则返回false * c : 必须是 int 值,最好是 char 范围 */ #define sh_isspace(c) \ ((c==' ')||(c>='\t'&&c<='\r'))
思路也很巧妙. 都是工作总结. 不用谢.
还有一个 构建数组对象代码
/* * 按照类型,创建 对映类型的数组 cjson对象 *目前支持 _CJSON_NULL _CJSON_BOOL/FALSE or TRUE , _CJSON_NUMBER, _CJSON_STRING * NULL => array 传入NULL, FALSE 使用char[],也可以传入NULL, NUMBER 只接受double, string 只接受char** * type : 类型目前支持 上面几种类型 * array : 数组原始数据 * len : 数组中元素长度 * : 返回创建的数组对象 */ cjson_t cjson_newtypearray(int type, const void* array, int len) { int i; cjson_t n = NULL, p = NULL, a; // _DEBUG 模式下简单检测一下 DEBUG_CODE({ if(type < _CJSON_FALSE || type > _CJSON_STRING || len <=0){ SL_FATAL("check param is error! type = %d, len = %d.", type, len); return NULL; } }); // 这里是实际执行代码 a = cjson_newarray(); for(i=0; i<len; ++i){ switch(type){ case _CJSON_NULL: n = cjson_newnull(); break; case _CJSON_FALSE: n = cjson_newbool(array? ((char*)array)[i] : 0); break; case _CJSON_TRUE: n = cjson_newbool(array? ((char*)array)[i] : 1); break; case _CJSON_NUMBER: n = cjson_newnumber(((double*)array)[i]); break; case _CJSON_STRING: n = cjson_newstring(((char**)array)[i]);break; } if(i){ //有你更好 p->next = n; n->prev = p; } else a->child = n; p = n; } return a; }
其中
cjson_t n = NULL, p = NULL, a;
是为了消除编译器警告, 没有定义就使用未初始化值. 对于其中创建代码都是 普通的 分类型搞. 很大白话.
对于 对象 分离代码如下
/* * 在object json 中分离 key 的项出去 * object : 待分离的对象主体内容 * key : 关联的键 * : 返回分离的 object中 key的项json_t */ cjson_t cjson_detachobject(cjson_t object, const char* key) { cjson_t c; DEBUG_CODE({ if(!object || !object->child || !key || !*key){ SL_WARNING("check param is object:%p, key:%s.", object, key); return NULL; } }); for(c=object->child; c && str_icmp(c->key, key); c=c->next) ; if(!c) { SL_WARNING("check param key:%s => vlaue is empty.", key); return NULL; } if(c->prev) c->prev->next = c->next; if(c->next) c->next->prev = c->prev; if(c == object->child) object->child = c->next; c->prev = c->next = NULL; return c; }
主要是查找, 查找到了 从特殊链表中上传这个对象,重新构建链接关系. 其中 str_icmp 在前面分析过 , 很巧妙
/* * 这是个不区分大小写的比较函数 * ls : 左边比较字符串 * rs : 右边比较字符串 * : 返回 ls>rs => >0 ; ls = rs => 0 ; ls<rs => <0 */ int str_icmp(const char* ls, const char* rs) { int l, r; if(!ls || !rs) return (int)ls - (int)rs; do { if((l=*ls++)>='a' && l<='z') l -= 'a' - 'A'; if((r=*rs++)>='a' && r<='z') r -= 'a' - 'A'; } while(l && l==r); return l-r; }
最后分享 一个 常用函数 , 从json文件中得到cjson_t 对象. 再扯一点, 多写代码,后面熟悉后你会发现, 代码就是最好的注释.
/* * 将json文件解析成json内容返回, 需要自己调用 cjson_delete * jpath : json串路径 * : 返回处理好的cjson_t 内容,失败返回NULL */ cjson_t cjson_dofile(char* jpath) { cjson_t root; tstring tstr = file_malloc_readend(jpath); if(!tstr){ SL_WARNING("readend jpath:%s is error!", jpath); return NULL; } root = cjson_parse(tstr->str); tstring_destroy(&tstr); return root; }
上面关于 tstring 设计 具体看下面博文.
到这里 关于cjson库 补充的 辅助函数重要设计就完毕了.
3. cjson 定稿代码 总展示
cjson.h


#ifndef _H_CJSON #define _H_CJSON // json 中几种数据类型定义 , 对于C而言 最难的是看不见源码,而不是api复杂, 更不是业务复杂 #define _CJSON_FALSE (0) #define _CJSON_TRUE (1) #define _CJSON_NULL (2) #define _CJSON_NUMBER (3) #define _CJSON_STRING (4) #define _CJSON_ARRAY (5) #define _CJSON_OBJECT (6) #define _CJSON_ISREF (256) //set 时候用如果是引用就不释放了 #define _CJSON_ISCONST (512) //set时候用, 如果是const char* 就不释放了 struct cjson { struct cjson *next, *prev; struct cjson *child; // type == _CJSON_ARRAY or type == _CJSON_OBJECT 那么 child 就不为空 int type; char *key; // json内容那块的 key名称 char *vs; // type == _CJSON_STRING, 是一个字符串 double vd; // type == _CJSON_NUMBER, 是一个num值, ((int)c->vd) 转成int 或 bool }; //定义cjson_t json类型 typedef struct cjson* cjson_t; /* * 这个宏,协助我们得到 int 值 或 bool 值 * * item : 待处理的目标cjson_t结点 */ #define cjson_getint(item) \ ((int)((item)->vd)) /* * 删除json串内容 * c : 待释放json_t串内容 */ extern void cjson_delete(cjson_t* pc); /* * 对json字符串解析返回解析后的结果 * jstr : 待解析的字符串 */ extern cjson_t cjson_parse(const char* jstr); /* * 根据 item当前结点的 next 一直寻找到 NULL, 返回个数 *推荐是数组使用 * array : 待处理的cjson_t数组对象 * : 返回这个数组中长度 */ extern int cjson_getlen(cjson_t array); /* * 根据索引得到这个数组中对象 * array : 数组对象 * idx : 查找的索引 必须 [0,cjson_getlen(array)) 范围内 * : 返回查找到的当前对象 */ extern cjson_t cjson_getarray(cjson_t array, int idx); /* * 根据key得到这个对象 相应位置的值 * object : 待处理对象中值 * key : 寻找的key * : 返回 查找 cjson_t 对象 */ extern cjson_t cjson_getobject(cjson_t object, const char* key); // --------------------------------- 下面是 cjson 输出部分的处理代码 ----------------------------------------- /* * 这里是将 cjson_t item 转换成字符串内容,需要自己free * item : cjson的具体结点 * : 返回生成的item的json串内容 */ extern char* cjson_print(cjson_t item); // --------------------------------- 下面是 cjson 输出部分的辅助代码 ----------------------------------------- /* * 创建一个bool的对象 b==0表示false,否则都是true, 需要自己释放 cjson_delete * b : bool 值 最好是 _Bool * : 返回 创建好的json 内容 */ extern cjson_t cjson_newnull(); extern cjson_t cjson_newbool(int b); extern cjson_t cjson_newnumber(double vd); extern cjson_t cjson_newstring(const char* vs); extern cjson_t cjson_newarray(void); extern cjson_t cjson_newobject(void); /* * 按照类型,创建 对映类型的数组 cjson对象 *目前支持 _CJSON_NULL _CJSON_BOOL/FALSE or TRUE , _CJSON_NUMBER, _CJSON_STRING * NULL => array 传入NULL, FALSE 使用char[],也可以传入NULL, NUMBER 只接受double, string 只接受char** * type : 类型目前支持 上面几种类型 * array : 数组原始数据 * len : 数组中元素长度 * : 返回创建的数组对象 */ extern cjson_t cjson_newtypearray(int type, const void* array, int len); /* * 将 jstr中 不需要解析的字符串都去掉 * jstr : 待处理的json串 * : 返回压缩后的json串内容 */ extern char* cjson_mini(char* jstr); /* * 将json文件解析成json内容返回. 需要自己调用 cjson_delete * jpath : json串路径 * : 返回处理好的cjson_t 内容,失败返回NULL */ extern cjson_t cjson_dofile(char* jpath); /* * 在array中分离第idx个索引项内容. * array : 待处理的json_t 数组内容 * idx : 索引内容 * : 返回分离的json_t内容 */ extern cjson_t cjson_detacharray(cjson_t array, int idx); /* * 在object json 中分离 key 的项出去 * object : 待分离的对象主体内容 * key : 关联的键 * : 返回分离的 object中 key的项json_t */ extern cjson_t cjson_detachobject(cjson_t object, const char* key); #endif // !_H_CJSON
cjson.c
#include <cjson.h> #include <schead.h> #include <sclog.h> #include <tstring.h> #include <float.h> #include <math.h> // 删除cjson static void __cjson_delete(cjson_t c) { cjson_t next; while (c) { next = c->next; //递归删除儿子 if (!(c->type & _CJSON_ISREF)) { if (c->child) //如果不是尾递归,那就先递归 __cjson_delete(c->child); if (c->vs) free(c->vs); } else if (!(c->type & _CJSON_ISCONST) && c->key) free(c->key); free(c); c = next; } } /* * 删除json串内容,最近老是受清华的老学生打击, 会起来的...... * c : 待释放json_t串内容 */ void cjson_delete(cjson_t* pc) { if (!pc || !*pc) return; __cjson_delete(*pc); *pc = NULL; } //构造一个空 cjson 对象 static inline cjson_t __cjson_new(void) { cjson_t c = calloc(1, sizeof(struct cjson)); if (!c) { SL_FATAL("calloc sizeof struct cjson error!"); exit(_RT_EM); } return c; } // 简化的代码段,用宏来简化代码书写 , 16进制处理 #define __parse_hex4_code(c, h) \ if (c >= '0' && c <= '9') \ h += c - '0'; \ else if (c >= 'A' && c <= 'F') \ h += 10 + c - 'A'; \ else if (c >= 'a' && c <= 'z') \ h += 10 + c - 'F'; \ else \ return 0 // 等到unicode char代码 static unsigned __parse_hex4(const char* str) { unsigned h = 0; char c = *str; //第一轮 __parse_hex4_code(c, h); h <<= 4; c = *++str; //第二轮 __parse_hex4_code(c, h); h <<= 4; c = *++str; //第三轮 __parse_hex4_code(c, h); h <<= 4; c = *++str; //第四轮 __parse_hex4_code(c, h); return h; } // 分析字符串的子函数, static const char* __parse_string(cjson_t item, const char* str) { static unsigned char __marks[] = { 0x00, 0x00, 0xC0, 0xE0, 0xF0, 0xF8, 0xFC }; const char *ptr; char *nptr, *out; int len; char c; unsigned uc, nuc; if (*str != '\"') { // 检查是否是字符串内容 SL_WARNING("need \\\" str => %s error!", str); return NULL; } for (ptr = str + 1, len = 0; (c = *ptr++) != '\"' && c; ++len) if (c == '\\') //跳过转义字符 ++ptr; if (!(out = malloc(len + 1))) { SL_FATAL("malloc %d size error!", len + 1); return NULL; } // 这里复制拷贝内容 for (ptr = str + 1, nptr = out; (c = *ptr) != '\"' && c; ++ptr) { if (c != '\\') { *nptr++ = c; continue; } // 处理转义字符 switch ((c = *++ptr)) { case 'b': *nptr++ = '\b'; break; case 'f': *nptr++ = '\f'; break; case 'n': *nptr++ = '\n'; break; case 'r': *nptr++ = '\r'; break; case 't': *nptr++ = '\t'; break; case 'u': // 将utf16 => utf8, 专门的utf处理代码 uc = __parse_hex4(ptr + 1); ptr += 4;//跳过后面四个字符, unicode if ((uc >= 0xDC00 && uc <= 0xDFFF) || uc == 0) break; /* check for invalid. */ if (uc >= 0xD800 && uc <= 0xDBFF) /* UTF16 surrogate pairs. */ { if (ptr[1] != '\\' || ptr[2] != 'u') break; /* missing second-half of surrogate. */ nuc = __parse_hex4(ptr + 3); ptr += 6; if (nuc < 0xDC00 || nuc>0xDFFF) break; /* invalid second-half of surrogate. */ uc = 0x10000 + (((uc & 0x3FF) << 10) | (nuc & 0x3FF)); } len = 4; if (uc < 0x80) len = 1; else if (uc < 0x800) len = 2; else if (uc < 0x10000) len = 3; nptr += len; switch (len) { case 4: *--nptr = ((uc | 0x80) & 0xBF); uc >>= 6; case 3: *--nptr = ((uc | 0x80) & 0xBF); uc >>= 6; case 2: *--nptr = ((uc | 0x80) & 0xBF); uc >>= 6; case 1: *--nptr = (uc | __marks[len]); } nptr += len; break; default: *nptr++ = c; } } *nptr = '\0'; if (c == '\"') ++ptr; item->vs = out; item->type = _CJSON_STRING; return ptr; } // 分析数值的子函数,写的可以 static const char* __parse_number(cjson_t item, const char* str) { double n = 0.0, ns = 1.0, nd = 0.0; //n把偶才能值, ns表示开始正负, 负为-1, nd 表示小数后面位数 int e = 0, es = 1; //e表示后面指数, es表示 指数的正负,负为-1 char c; if ((c = *str) == '-' || c == '+') { ns = c == '-' ? -1.0 : 1.0; //正负号检测, 1表示负数 ++str; } //处理整数部分 for (c = *str; c >= '0' && c <= '9'; c = *++str) n = n * 10 + c - '0'; if (c == '.') for (; (c = *++str) >= '0' && c <= '9'; --nd) n = n * 10 + c - '0'; // 处理科学计数法 if (c == 'e' || c == 'E') { if ((c = *++str) == '+') //处理指数部分 ++str; else if (c == '-') es = -1, ++str; for (; (c = *str) >= '0' && c <= '9'; ++str) e = e * 10 + c - '0'; } //返回最终结果 number = +/- number.fraction * 10^+/- exponent n = ns * n * pow(10.0, nd + es * e); item->vd = n; item->type = _CJSON_NUMBER; return str; } // 跳过不需要处理的字符 static const char* __skip(const char* in) { if (in && *in && *in <= 32) { unsigned char c; while ((c = *++in) && c <= 32) ; } return in; } // 递归下降分析 需要声明这些函数 static const char* __parse_array(cjson_t item, const char* str); static const char* __parse_object(cjson_t item, const char* str); static const char* __parse_value(cjson_t item, const char* value); // 分析数组的子函数, 采用递归下降分析 static const char* __parse_array(cjson_t item, const char* str) { cjson_t child; if (*str != '[') { SL_WARNING("array str error start: %s.", str); return NULL; } item->type = _CJSON_ARRAY; str = __skip(str + 1); if (*str == ']') // 低估提前结束 return str + 1; item->child = child = __cjson_new(); str = __skip(__parse_value(child, str)); if (!str) {//解析失败 直接返回 SL_WARNING("array str error e n d one: %s.", str); return NULL; } while (*str == ',') { cjson_t nitem = __cjson_new(); child->next = nitem; nitem->prev = child; child = nitem; str = __skip(__parse_value(child, __skip(str + 1))); if (!str) {// 写代码是一件很爽的事 SL_WARNING("array str error e n d two: %s.", str); return NULL; } } if (*str != ']') { SL_WARNING("array str error e n d: %s.", str); return NULL; } return str + 1; // 跳过']' } // 分析对象的子函数 static const char* __parse_object(cjson_t item, const char* str) { cjson_t child; if (*str != '{') { SL_WARNING("object str error start: %s.", str); return NULL; } item->type = _CJSON_OBJECT; str = __skip(str + 1); if (*str == '}') return str + 1; //处理结点, 开始读取一个 key item->child = child = __cjson_new(); str = __skip(__parse_string(child, str)); if (!str || *str != ':') { SL_WARNING("__skip __parse_string is error : %s!", str); return NULL; } child->key = child->vs; child->vs = NULL; str = __skip(__parse_value(child, __skip(str + 1))); if (!str) { SL_WARNING("__skip __parse_string is error 2!"); return NULL; } // 递归解析 while (*str == ',') { cjson_t nitem = __cjson_new(); child->next = nitem; nitem->prev = child; child = nitem; str = __skip(__parse_string(child, __skip(str + 1))); if (!str || *str != ':'){ SL_WARNING("__parse_string need name or no equal ':' %s.", str); return NULL; } child->key = child->vs; child->vs = NULL; str = __skip(__parse_value(child, __skip(str+1))); if (!str) { SL_WARNING("__parse_string need item two ':' %s.", str); return NULL; } } if (*str != '}') { SL_WARNING("object str error e n d: %s.", str); return NULL; } return str + 1; } // 将value 转换塞入 item json值中一部分 static const char* __parse_value(cjson_t item, const char* value) { char c; if ((value) && (c = *value)) { switch (c) { // n = null, f = false, t = true case 'n' : return item->type = _CJSON_NULL, value + 4; case 'f' : return item->type = _CJSON_FALSE, value + 5; case 't' : return item->type = _CJSON_TRUE, item->vd = 1.0, value + 4; case '\"': return __parse_string(item, value); case '0' : case '1': case '2': case '3': case '4': case '5': case '6': case '7': case '8': case '9': case '+' : case '-': return __parse_number(item, value); case '[' : return __parse_array(item, value); case '{' : return __parse_object(item, value); } } // 循环到这里是意外 数据 SL_WARNING("params value = %s!", value); return NULL; } /* * 对json字符串解析返回解析后的结果 * jstr : 待解析的字符串 * : 返回解析好的字符串内容 */ cjson_t cjson_parse(const char* jstr) { cjson_t c = __cjson_new(); const char* end; if (!(end = __parse_value(c, __skip(jstr)))) { SL_WARNING("__parse_value params end = %s!", end); cjson_delete(&c); return NULL; } //这里是否检测 返回测试数据 return c; } /* * 根据 item当前结点的 next 一直寻找到 NULL, 返回个数 *推荐是数组使用 * array : 待处理的cjson_t数组对象 * : 返回这个数组中长度 */ int cjson_getlen(cjson_t array) { int len = 0; if (array) for (array = array->child; array; array = array->next) ++len; return len; } /* * 根据索引得到这个数组中对象 * array : 数组对象 * idx : 查找的索引 必须 [0,cjson_getlen(array)) 范围内 * : 返回查找到的当前对象 */ cjson_t cjson_getarray(cjson_t array, int idx) { cjson_t c; DEBUG_CODE({ if (!array || idx < 0) { SL_FATAL("array:%p, idx=%d params is error!", array, idx); return NULL; } }); for (c = array->child; c&&idx > 0; c = c->next) --idx; return c; } /* * 根据key得到这个对象 相应位置的值 * object : 待处理对象中值 * key : 寻找的key * : 返回 查找 cjson_t 对象 */ cjson_t cjson_getobject(cjson_t object, const char* key) { cjson_t c; DEBUG_CODE({ if (!object || !key || !*key) { SL_FATAL("object:%p, key=%s params is error!", object, key); return NULL; } }); for (c = object->child; c && str_icmp(key, c->key); c = c->next) ; return c; } // --------------------------------- 下面是 cjson 输出部分的处理代码 ----------------------------------------- // 2^n>=x , n是最小的整数 static int __pow2gt(int x) { --x; x |= x >> 1; x |= x >> 2; x |= x >> 4; x |= x >> 8; x |= x >> 16; return x + 1; } /* * 这里使用 tstring 结构 size 这里表示 字符串总大小,没有变化 * len 表示当前字符串的字符串起始偏移量 即 tstring->str + tstring->len 起始的 */ static char* __ensure(tstring p, int need) { char* nbuf; int nsize; if (!p || !p->str) { SL_FATAL("p:%p need:%p is error!", p, need); return NULL; } need += p->len; if (need <= p->size) //内存够用直接返回结果 return p->str + p->len; nsize = __pow2gt(need); if ((nbuf = malloc(nsize*sizeof(char))) == NULL) { free(p->str); p->size = p->len = 0; p->str = NULL; SL_FATAL("malloc nsize = %d error!", nsize); return NULL; } //这里复制内容 memcpy(nbuf, p->str, p->size); free(p->str); p->size = nsize; p->str = nbuf; return nbuf + p->len; } // 这里更新一下 当前字符串, 返回当前字符串的长度 inline static int __update(tstring p) { return (!p || !p->str) ? 0 : p->len + strlen(p->str+p->len); } // 将item 中值转换成字符串 保存到p中 static char* __print_number(cjson_t item, tstring p) { char* str = NULL; double d = item->vd; int i = (int)d; if (d == 0) { //普通0 str = __ensure(p, 2); if (str) str[0] = '0', str[1] = '\0'; } else if ((fabs(d - i)) <= DBL_EPSILON && d <= INT_MAX && d >= INT_MIN) { str = __ensure(p, 21); //int 值 if (str) sprintf(str, "%d", i); } else { str = __ensure(p, 64); //double值 if (str) { double nd = fabs(d); //得到正值开始比较 if(fabs(floor(d) - d) <= DBL_EPSILON && nd < 1.0e60) sprintf(str, "%.0f", d); else if(nd < 1.0e-6 || nd > 1.0e9) //科学计数法 sprintf(str, "%e", d); else sprintf(str, "%f", d); } } return str; } // 输出字符串内容 static char* __print_string(char* str, tstring p) { const char* ptr; char *nptr, *out; int len = 0, flag = 0; unsigned char c; if (!str || !*str) { //最特殊情况,什么都没有 返回NULL out = __ensure(p, 3); if (!out) return NULL; out[0] = '\"', out[1] = '\"', out[2] = '\0'; return out; } for (ptr = str; (c=*ptr); ++ptr) flag |= ((c > 0 && c < 32) || c == '\"' || c == '\\'); if (!flag) { //没有特殊字符直接处理结果 len = ptr - str; out = __ensure(p,len + 3); if (!out) return NULL; nptr = out; *nptr++ = '\"'; strcpy(nptr, str); nptr[len] = '\"'; nptr[len + 1] = '\0'; return out; } //处理 存在 "和转义字符内容 for (ptr = str; (c = *ptr) && ++len; ++ptr) { if (strchr("\"\\\b\f\n\r\t", c)) ++len; else if (c < 32) //隐藏字符的处理, 这里可以改 len += 5; } if ((out = __ensure(p, len + 3)) == NULL) return NULL; //先添加 \" nptr = out; *nptr++ = '\"'; for (ptr = str; (c = *ptr); ++ptr) { if (c > 31 && c != '\"' && c != '\\') { *nptr++ = c; continue; } *nptr++ = '\\'; switch (c){ case '\\': *nptr++ = '\\'; break; case '\"': *nptr++ = '\"'; break; case '\b': *nptr++ = 'b'; break; case '\f': *nptr++ = 'f'; break; case '\n': *nptr++ = 'n'; break; case '\r': *nptr++ = 'r'; break; case '\t': *nptr++ = 't'; break; default: sprintf(nptr, "u%04x", c);nptr += 5; /* 不可见字符 采用 4字节字符编码 */ } } *nptr++ = '\"'; *nptr = '\0'; return out; } //这里是 递归下降 的函数声明处, 分别是处理值, 数组, object static char* __print_value(cjson_t item, tstring p); static char* __print_array(cjson_t item, tstring p); static char* __print_object(cjson_t item, tstring p); // 定义实现部分, 内部私有函数 认为 item 和 p都是存在的 static char* __print_value(cjson_t item, tstring p) { char* out = NULL; switch ((item->type) & UCHAR_MAX) { // 0xff case _CJSON_FALSE: if ((out = __ensure(p, 6))) strcpy(out, "false"); break; case _CJSON_TRUE: if ((out = __ensure(p, 5))) strcpy(out, "true"); break; case _CJSON_NULL: if ((out = __ensure(p, 5))) strcpy(out, "null"); break; case _CJSON_NUMBER: out = __print_number(item, p); break; case _CJSON_STRING: out = __print_string(item->vs, p); break; case _CJSON_ARRAY: out = __print_array(item, p); break; case _CJSON_OBJECT: out = __print_object(item, p); break; } return out; } // 同样 假定 item 和 p都是存在且不为NULL static char* __print_array(cjson_t item, tstring p) { char* ptr; cjson_t child = item->child; int ncut, i; // 得到孩子结点的深度 for (ncut = 0; (child); child = child->child) ++ncut; if (!ncut) { //没有孩子结点 直接空数组返回结果 char* out = NULL; if (!(out = __ensure(p, 3))) strcpy(out, "[]"); return out; } i = p->len; if (!(ptr = __ensure(p, 1))) return NULL; *ptr = '['; ++p->len; for (child = item->child; (child); child = child->next) { __print_value(child, p); p->len = __update(p); if (child->next) { if (!(ptr = __ensure(p, 2))) return NULL; *ptr++ = ','; *ptr = '\0'; p->len += 1; } } if (!(ptr = __ensure(p, 2))) return NULL; *ptr++ = ']'; *ptr = '\0'; return p->str + i; } // 同样 假定 item 和 p都是存在且不为NULL, 相信这些代码是安全的 static char* __print_object(cjson_t item, tstring p) { char* ptr; int i, ncut, len; cjson_t child = item->child; // 得到孩子结点的深度 for (ncut = 0; child; child = child->child) ++ncut; if (!ncut) { char* out = NULL; if (!(out = __ensure(p, 3))) strcpy(out, "{}"); return out; } i = p->len; if (!(ptr = __ensure(p, 2))) return NULL; *ptr++ = '{'; *ptr -= '\0'; p->len += 1; // 根据子结点 处理 for (child = item->child; (child); child = child->next) { __print_string(child->key, p); p->len = __update(p); //加入一个冒号 if (!(ptr = __ensure(p, 1))) return NULL; *ptr++ = ':'; p->len += 1; //继续打印一个值 __print_value(child, p); p->len = __update(p); //结算最后内容 len = child->next ? 1 : 0; if ((ptr = __ensure(p, len + 1)) == NULL) return NULL; if (child->next) *ptr++ = ','; *ptr = '\0'; p->len += len; } if (!(ptr = __ensure(p, 2))) return NULL; *ptr++ = '}'; *ptr = '\0'; return p->str + i; } #define _INT_CJONSTR (256) /* * 这里是将 cjson_t item 转换成字符串内容,需要自己free * item : cjson的具体结点 * : 返回生成的item的json串内容 */ char* cjson_print(cjson_t item) { struct tstring p; char* out; if ((!item) || !(p.str = malloc(sizeof(char)*_INT_CJONSTR))) { SL_FATAL("item:%p, p.str = malloc is error!", item); return NULL; } p.size = _INT_CJONSTR; p.len = 0; out = __print_value(item, &p); //从值处理开始, 返回最终结果 if (out == NULL) { free(p.str); SL_FATAL("__print_value item:%p, p:%p is error!", item, &p); return NULL; } return realloc(out,strlen(out) + 1); // 体积变小 realloc返回一定成功 } // --------------------------------- 下面是 cjson 输出部分的辅助代码 ----------------------------------------- /* * 创建一个bool的对象 b==0表示false,否则都是true, 需要自己释放 cjson_delete * b : bool 值 最好是 _Bool * : 返回 创建好的json 内容 */ cjson_t cjson_newnull() { cjson_t item = __cjson_new(); item->type = _CJSON_NULL; return item; } cjson_t cjson_newbool(int b) { cjson_t item = __cjson_new(); item->vd = item->type = b ? _CJSON_TRUE : _CJSON_FALSE; return item; } cjson_t cjson_newnumber(double vd) { cjson_t item = __cjson_new(); item->type = _CJSON_NUMBER; item->vd = vd; return item; } cjson_t cjson_newstring(const char* vs) { cjson_t item = __cjson_new(); item->type = _CJSON_STRING; item->vs = str_dup(vs); return item; } cjson_t cjson_newarray(void) { cjson_t item = __cjson_new(); item->type = _CJSON_ARRAY; return item; } cjson_t cjson_newobject(void) { cjson_t item = __cjson_new(); item->type = _CJSON_OBJECT; return item; } /* * 按照类型,创建 对映类型的数组 cjson对象 *目前支持 _CJSON_NULL _CJSON_BOOL/FALSE or TRUE , _CJSON_NUMBER, _CJSON_STRING * NULL => array 传入NULL, FALSE 使用char[],也可以传入NULL, NUMBER 只接受double, string 只接受char** * type : 类型目前支持 上面几种类型 * array : 数组原始数据 * len : 数组中元素长度 * : 返回创建的数组对象 */ cjson_t cjson_newtypearray(int type, const void* array, int len) { int i; cjson_t n = NULL, p = NULL, a; // _DEBUG 模式下简单检测一下 DEBUG_CODE({ if(type < _CJSON_FALSE || type > _CJSON_STRING || len <=0){ SL_FATAL("check param is error! type = %d, len = %d.", type, len); return NULL; } }); // 这里是实际执行代码 a = cjson_newarray(); for(i=0; i<len; ++i){ switch(type){ case _CJSON_NULL: n = cjson_newnull(); break; case _CJSON_FALSE: n = cjson_newbool(array? ((char*)array)[i] : 0); break; case _CJSON_TRUE: n = cjson_newbool(array? ((char*)array)[i] : 1); break; case _CJSON_NUMBER: n = cjson_newnumber(((double*)array)[i]); break; case _CJSON_STRING: n = cjson_newstring(((char**)array)[i]);break; } if(i){ //有你更好 p->next = n; n->prev = p; } else a->child = n; p = n; } return a; } /* * 将 jstr中 不需要解析的字符串都去掉,并且纪念mini 比男的还平 * jstr : 待处理的json串 * : 返回压缩后的json串内容 */ char* cjson_mini(char* jstr) { char* in = jstr; char* to = jstr; char c; while(!!(c=*to)){ if(sh_isspace(c)) ++to; else if(c == '/' && to[1] == '/') while((c=*++to) && c!='\n'); else if(c == '/' && to[1] == '*'){ while((c=*++to) && !(c=='*' && to[1] =='/')) ; if(c) to+=2; } else if(c=='"'){ *in++ = c; while((c=*++to) && (c!='"' || to[-1]=='\\')) *in++ = c; if(c) { *in++=c; ++to; } } else *in++ = *to++; } *in = '\0'; return jstr; } /* * 将json文件解析成json内容返回, 需要自己调用 cjson_delete * jpath : json串路径 * : 返回处理好的cjson_t 内容,失败返回NULL */ cjson_t cjson_dofile(char* jpath) { cjson_t root; tstring tstr = file_malloc_readend(jpath); if(!tstr){ SL_WARNING("readend jpath:%s is error!", jpath); return NULL; } root = cjson_parse(tstr->str); tstring_destroy(&tstr); return root; } /* * 在array中分离第idx个索引项内容. * array : 待处理的json_t 数组内容 * idx : 索引内容 * : 返回分离的json_t内容 */ cjson_t cjson_detacharray(cjson_t array, int idx) { cjson_t c; DEBUG_CODE({ if(!array || idx<0){ SL_WARNING("check param is array:%p, idx:%d.", array, idx); return NULL; } }); for(c=array->child; idx>0 && c; c = c->next) --idx; if(c>0){ SL_WARNING("check param is too dig idx:sub %d.", idx); return NULL; } //这里开始拼接了 if(c->prev) c->prev->next = c->next; if(c->next) c->next->prev = c->prev; if(c == array->child) array->child = c->next; c->prev = c->next = NULL; return c; } /* * 在object json 中分离 key 的项出去 * object : 待分离的对象主体内容 * key : 关联的键 * : 返回分离的 object中 key的项json_t */ cjson_t cjson_detachobject(cjson_t object, const char* key) { cjson_t c; DEBUG_CODE({ if(!object || !object->child || !key || !*key){ SL_WARNING("check param is object:%p, key:%s.", object, key); return NULL; } }); for(c=object->child; c && str_icmp(c->key, key); c=c->next) ; if(!c) { SL_WARNING("check param key:%s => vlaue is empty.", key); return NULL; } if(c->prev) c->prev->next = c->next; if(c->next) c->next->prev = c->prev; if(c == object->child) object->child = c->next; c->prev = c->next = NULL; return c; }
总的而言 上面代码 加上注释两个文件一共 1100行左右,去掉注释应该在800行左右. 对于cjson库应该算很小的了. 很适合
学习,扩展或再优化.
4. 测试代码展示
对于上面代码又写了一个测试 , 首先 测试的 json文件内容
firefighting_rule.json 内容如下
{ "firefighting_rule": { "key1": { "id":1, "dungeon_id":40008, "level_contain":[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15], "active_time":[[1,"110000"],[4,"110000"],[5,"210000"]], "boss_ui_head":"UI_icon/IMG_ShiJieBoss_TouXiang.png", "activity_tag_icon":"IMG_GaiBan_HuoDong_ShiJieBoss_TuBiao.png", "activity_tag_word":"IMG_GaiBan_ZhuCheng_ShiJieBoss_TuBiao_MingZi.png", "activity_pic_json":"UI_HuoDong_ShiJieBoss.json", "jinbi_buff_icon":"UI_icon/IMG_WorldBoss_JinbiBuff_Atk.png", "jinbi_buff_damage":[[8,1000],[9,1000],[11,1000],[12,1000]], "jinbi_buff_price":10, "jinbi_buff_limit":999, "free_change":1, "refresh_price":20, "change_price":20, "show_hero_num":20 } } }
处理的解析文件代码如下
#include <schead.h> #include <sclog.h> #include <cjson.h> #define _STR_FILE "firefighting_rule.json" /** * 这里 是解析 上面的json文件内容 */ int main(int argc, char* argv[]) { INIT_PAUSE(); // 开启日志记录功能 sl_start(); cjson_t rule = cjson_dofile(_STR_FILE); if (NULL == rule) CERR_EXIT("cjson_dofile " _STR_FILE " is error!"); // 数据合法 这里开始得到一部分 cjson_t firefighting_rule = cjson_detachobject(rule, "firefighting_rule"); // 得到真正的内容 cjson_t key1 = cjson_detachobject(firefighting_rule, "key1"); //这里得到 key1 输出内容 char* nkey = cjson_print(key1); if (NULL == nkey) CERR_EXIT("cjson_print key1 is error!"); // 这里打印数据测试 puts(nkey); free(nkey); // 再简单测试一下 cjson_t id = cjson_getobject(key1, "id"); printf("\nid = %d\n", cjson_getint(id)); //得到数组对象 测试 cjson_t level_contain = cjson_getobject(key1, "level_contain"); printf("\ncount(level_contain) = %d\n", cjson_getlen(level_contain)); cjson_delete(&key1); cjson_delete(&firefighting_rule); // rule 释放 cjson_delete(&rule); return 0; }
其中文件结构是 测试文件在 根目录下 或者和 exe或 out同一级目录下. 最后测试结果如下
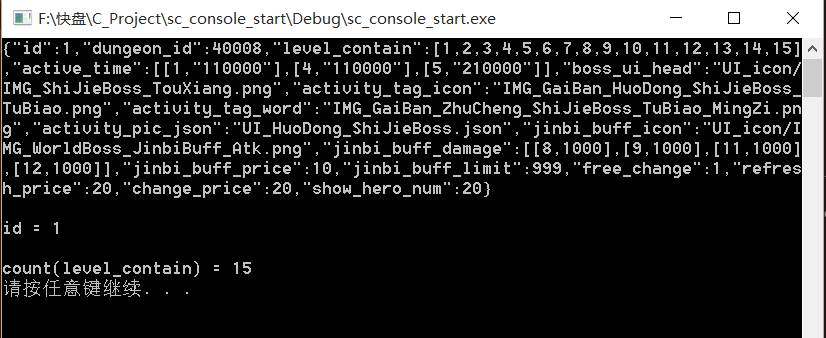
一切正常, 欢迎将这个cjson 库用在自己 纯C的小项目中. 自己想怎么改就怎么改. 楼主不介意, 还可以帮你订制改.
5. 下一个展望
C基础框架 开发的差不多了,下次再分享一个 csv文件解析内容库. 再整合一下框架 基本上用C开发小型 单机项目就没什么问题了.
现在差 网络库积累 和 图形库积累,图形库 很久一个版本 内置了 glut 和 glew 后面放弃了. 太庞大不好, 用起来不爽. 目前定位就是
后端开发框架. 最后总结 对于自己这种农民工 开发库的经验就是,
有什么想法你就去做, 有什么错就马上改. 有比自己更好,马上学习 创新.
再扯一点, 学编程真的没有高中的做的难,更没有大学学的内容深, 真的一个很傻的职业, 工资可以, 操作机械化. 值得深搞.
后记
错误是难免, 有人提出来或自己发现了,一定修改! 有始有终 ...

“ Monster? Is that what you think of me? I was... always care for you! Tyrand! I thought only to prove this word in this... my power! ”
(“怪物?你就是这么看我的?泰兰德?我一直在乎你!我只想通过自己的力量来能证明这点。“)
Intro: The Dawn http://music.163.com/#/song?id=4017240
另一个王 对 伊利丹说
“ Leave this world, and never return... If you do, I'll be waiting... ”
(离开这个世界,永远不要再回来。如果你胆敢这么做,我会等着你……)

