
对 cloudwu 简单的 cstring 进行简单解析
题外话
以前也用C写过字符串,主要应用的领域是,大字符串,文件读取方面.写的很粗暴,用的凑合着.那时候看见云风前辈的一个开源的 cstring 串.
当时简单观摩了一下,觉得挺好的.也没细看.过了较长一段时间,想整合一下,将大字符串和云风的cstring 短简单的串合在一起变成一种.但是自己
认真复制了一遍后发现.
1.整合不了 云风(后面都省略前辈二字,觉得云风两个字,就已经帅的不行了)简单cstring.因为处理的领域不一样.
云风的 cstring => String , 而自己写的操作文件的c简单串 => StringBuilder.
2.技巧太多了,不明觉厉,但是云风用的技巧,都会解释,毕竟都是C开发中常用的技巧.
3.自己很菜,只能是瞎子摸象,看见只是部分,更多的需要大家自己参悟.
参考资料
1.云风博客简单字符串简介 http://blog.codingnow.com/2013/09/cstring.html
2.云风githup cstring https://github.com/cloudwu/cstring
3.gcc inline解释 在线文档 https://gcc.gnu.org/onlinedocs/gcc-5.3.0/gcc/Inline.html#Inline
4.字符串hash 函数简介 http://www.cnblogs.com/uvsjoh/archive/2012/03/27/2420120.html#3240817
5. 简单实现原子操作 http://www.cnblogs.com/life2refuel/p/5024289.html#3326123
6. assert 使用 http://www.cnblogs.com/ggzss/archive/2011/08/18/2145017.html
7. 位运算 http://blog.sina.com.cn/s/blog_7b7cad23010163vy.html
8.stdarg.h c可变参数详解 http://www.cnblogs.com/life2refuel/p/4984275.html
前言
这次直接切入正题,也许你会不屑一顾,还是想 分享一个故事
面朝大海,春暖花开 海子 于 1989 从明天起,做一个幸福的人 喂马、劈柴,周游世界 从明天起,关心粮食和蔬菜 我有一所房子,面朝大海,春暖花开 从明天起,和每一个亲人通信 告诉他们我的幸福 那幸福的闪电告诉我的 我将告诉每一个人 给每一条河每一座山取一个温暖的名字 陌生人,我也为你祝福 愿你有一个灿烂的前程 愿你有情人终成眷属 愿你在尘世获得幸福 我只愿面朝大海,春暖花开
同名歌曲
面朝大海 http://music.163.com/#/song?id=27946316
正题
首先下载云风的cstring 源码 结构如下:
首先 看 cstring.h 文件
#ifndef cstring_h #define cstring_h #include <stdint.h> #include <stddef.h> #define CSTRING_PERMANENT 1 #define CSTRING_INTERNING 2 #define CSTRING_ONSTACK 4 #define CSTRING_INTERNING_SIZE 32 #define CSTRING_STACK_SIZE 128 struct cstring_data { char * cstr; uint32_t hash_size; uint16_t type; uint16_t ref; }; typedef struct _cstring_buffer { struct cstring_data * str; } cstring_buffer[1]; typedef struct cstring_data * cstring; #define CSTRING_BUFFER(var) \ char var##_cstring [CSTRING_STACK_SIZE] = { '\0' }; \ struct cstring_data var##_cstring_data = { var##_cstring , 0, CSTRING_ONSTACK, 0 }; \ cstring_buffer var; \ var->str = &var##_cstring_data; #define CSTRING_LITERAL(var, cstr) \ static cstring var = NULL; \ if (var) {} else { \ cstring tmp = cstring_persist(""cstr, (sizeof(cstr)/sizeof(char))-1); \ if (!__sync_bool_compare_and_swap(&var, NULL, tmp)) { \ cstring_free_persist(tmp); \ } \ } #define CSTRING(s) ((s)->str) #define CSTRING_CLOSE(var) \ if ((var)->str->type != 0) {} else \ cstring_release((var)->str); /* low level api, don't use directly */ cstring cstring_persist(const char * cstr, size_t sz); void cstring_free_persist(cstring s); /* public api */ cstring cstring_grab(cstring s); void cstring_release(cstring s); cstring cstring_cat(cstring_buffer sb, const char * str); cstring cstring_printf(cstring_buffer sb, const char * format, ...) #ifdef __GNUC__ __attribute__((format(printf, 2, 3))) #endif ; int cstring_equal(cstring a, cstring b); uint32_t cstring_hash(cstring s); #endif
第一部分 对头文件 cstring.h 简单解析如下(对于源码全部解释,自己说的不爽,别人看也会不爽,毕竟不是原创)
1.1 字符串类型
#define CSTRING_PERMANENT 1
上面声明表示一个 永久的串 类型,实现采用static 变量类型声明
#define CSTRINT_INTERNING 2
上面表示一个 符号表字符串 类型,实现方式 直接 "root" 这么搞
#define CSTRING_ONSTACK 4
这大家都知道 临时字符串 类型,实现方式 利用宏嵌到 函数代码体中
1.2 字符串大小宏
#define CSTRING_INTERNING_SIZE 32
上面是符号表串,小于32字节的 都可以声明为 CSTRINT_INTERNING
#define CSTRING_STACK_SIZE 128
上面是表明小于128字节的都可以放到栈上 类型 CSTRING_ONSTACK
2.1 特殊的结构体
typedef struct cstring_buffer { struct cstring_data * str; } cstring_buffer[1];
上面 定义的 cstring_buffer 类型,是C中一个声明技巧
例如 cstring_buffer cb; 其中 cb 内存分配在 栈上 但是可以当指针使用,传入到 struct cstring_buffer* 地方.
更简单一点如下,其它就自己悟吧
cstring_buffer cb; => struct cstring_buffer cb[1];
3.1 函数宏分析
#define CSTRING_BUFFER(var) \ char var##_cstring[CSTRING_STACK_SIZE] = { '\0' }; \ struct cstring_data var##_cstring_data = { var##_cstring, 0, CSTRING_ONSTACK, 0 }; \ cstring_buffer var; \ var->str = &var##cstring_data;
这个宏 也很巧妙, ## 表示链接宏 假如 var 是 abc,var只能同变量,不能有双引号
那么就声明了一个
char abc_cstring[128] = { '\0' };
这个变量内存在栈上,通常不需要回收.
这个宏作用是 声明了一个名为 var 的 cstring_buffer 对象 但是在函数结束时,应该使用 CSTRING_CLOSE(var) 关闭它。
3.2 另一个出彩的函数宏
#define CSTRING_LITERAL(var, cstr) \ static cstring var = NULL; \ if (var) {} else { \ cstring tmp = cstring_persist(""cstr, (sizeof(cstr)/sizeof(char)-1)); \ if(!__sync_bool_compare_and_swap(&var, NULL, tmp)){ \ cstring_free_persist(tmp); \ } \ }
这个函数宏声明变量都是 全局存储区的变量,这里认为是常量cstring.
但是cstr必须是 引起""引起宏.
这里这个
cstring_persist(""cstr, (sizeof(cstr)/sizeof(char)-1));
""特别亮,在函数编译的时候就能找出错误!第二参数 常量字符串最后一个字符的索引
后面 __sync_bool_compare_and_swap 是gcc 内置的原子函数,推荐用最新的gcc版本测试
详细一点介绍是
bool __sync_bool_compare_and_swap (type *ptr, type oldval, type newval, ...);
__sync_bool_compare_and_swap 内置函数比较 oldval 和 *ptr。 如果它们匹配,就把 newval 复制到 *ptr。 此时返回返回值是 true,否则是 false.
这个函数 在并发编程中甩掉互斥锁N条街.
4.1 函数解析,首先是cstring 如果需要把字符串做参数传递,就应该使用 cstring 类型,而不是 cstring_buffer 类型。
CSTRING(var) 可以把 var 这个 cstring_buffer 对象,转换为 cstring 类型。
但是,在对 cstring_buffer 对象做新的操作后,这个 cstring 可能无效。
所以每次传递 cstring_buffer 内的值,最好都重新用 CSTRING 宏取一次。
函数调用的参数以及返回值,都应该使用 cstring 类型。
如果 cstring 是由外部传入的,无法确定它的数据在栈上还是堆上,所以不能长期持有。
如果需要把 cstring 保存在数据结构中,可以使用这对 API :
cstring cstring_grab(cstring s); void cstring_release(cstring s);
把 cstring 转化为标准的 const char * ,只需要用 s->cstr 即可。
cstring 的比较操作以及 hash 操作都比 const char * 廉价,所以,请使用以下 API :
int cstring_equal(cstring a, cstring b); uint32_t cstring_hash(cstring s);
这里还有一个函数声明
cstring cstring_printf(cstring_buffer sb, const char * format, ...) #ifdef __GNUC__ __attribute__((format(printf, 2, 3))) #endif
重点 是 后面的 __attribute__() 这也是个gcc 内置语法,是对编译器编译行为进行一些约定 , 这里 format (printf, 2, 3)告诉编译器,
cstring_printf的format相当于printf的format, 而可变参数是从cstring_printf的第3个参数开始。
这样编译器就会在编译时用和printf一样的check法则来确认可变参数是否正确了.
关于 gcc编译器的控制行为,还是比较多的.自己可以搜索一下 gcc __attribute__,这些都很死,不是大神推荐不要用太多编译器指令,不通用技巧性太强,容易东施效颦!
到这里第一部分 基本就解释 完毕了.
这里再扩展一点 对于结构
struct cstring_data { char * cstr; uint32_t hash_size; uint16_t type; uint16_t ref; };
后面使用的时候 常出现这样的代码
struct cstring_data *p = malloc(sizeof(struct cstring_data) + sz + 1); // todo: memory alloc error assert(p); void * ptr = (void *)(p + 1); p->cstr = ptr; p->type = 0; p->ref = 1; memcpy(ptr, cstr, sz); ((char*)ptr)[sz] = '\0'; p->hash_size = 0;
这里的一个技巧是 直接一次 malloc 将两个 内存都分配好了 .
第一个 sizeof (struct cstring_data) 是给 p用的,
第二个 sizeof (struct cstring_data) + sz + 1 给 p->cstr 用的,.
对于这个技巧还用更 巧的是
struct cstring_data { uint32_t hash_size; uint16_t type; uint16_t ref; char [] cstr; };
这种结构 声明方式和方式一样
struct cstring_data *p = malloc(sizeof(struct cstring_data) + sz + 1);
下面这种方式和上面比有点 内存更小了, 小了 sizeof (cstr).
不要在C中问出,少了4字节有什么意义,那只能推荐你去学java吧.
但是 为什么 云风没有这么干呢. 是这样的 后面 那种声明方式为不完全类型, 有点 像
void* arg;
内存只能通过堆分配,不在在栈上分配,而 cstring 需要运用栈内存,具体看下面宏.
#define CSTRING_BUFFER(var) \ char var##_cstring[CSTRING_STACK_SIZE] = { '\0' }; \ struct cstring_data var##_cstring_data = { var##_cstring, 0, CSTRING_ONSTACK, 0 }; \ cstring_buffer var; \ var->str = &var##_cstring_data;
这里 再扩展一下,吐槽一下 云风前辈
struct cstring_data *p = malloc(sizeof(struct cstring_data) + sz + 1); // todo: memory alloc error assert(p);
第一次见这样代码,看一遍觉得好,屌.
看第二遍 有点不对吧.
看第三遍 确定 这样是 用错了assert, assert 在 开启 NDEBUG 会失效.
假如 程序正式跑了,设置了
gcc -Wall -INDEBUG -o $^ $@
上面代码 assert 就等同于
#ifdef NDEBUG #define assert(expression) ((void)0) #endif
那么程序 假如 另一个 BUG,将 内存吃完了,这里 就是 未定义 修改 未知内存,基本是返回NULL,操作NULL,程序崩了.
服务器当了,查原因 还没日志...... 这是 不好的, 反正是 他用错了
还是用下面这样质朴的代码吧
struct cstring_data *p = malloc(sizeof(struct cstring_data) + sz + 1); // todo: memory alloc error if(NULL == p) { fprintf(stderr, "[%s][%d][%s][error:malloc struct cstring_data return NULL!]",__FILE__, __LINE__, __func__) ; return NULL; }
上面写的比较简单,还需要错误输出需要考虑时间.
第二部分 写一个简单例子 直接用云风 的 test.c
#include "cstring.h" #include <stdio.h> static cstring foo(cstring t) { CSTRING_LITERAL(hello, "hello"); CSTRING_BUFFER(ret); if (cstring_equal(hello,t)) { cstring_cat(ret, "equal"); } else { cstring_cat(ret, "not equal"); } return cstring_grab(CSTRING(ret)); } static void test() { CSTRING_BUFFER(a); cstring_printf(a, "%s", "hello"); cstring b = foo(CSTRING(a)); printf("%s\n", b->cstr); cstring_printf(a, "very long string %01024d",0); printf("%s\n", CSTRING(a)->cstr); CSTRING_CLOSE(a); cstring_release(b); } int main() { test(); return 0; }
我们采用 Ubuntu 测试一下
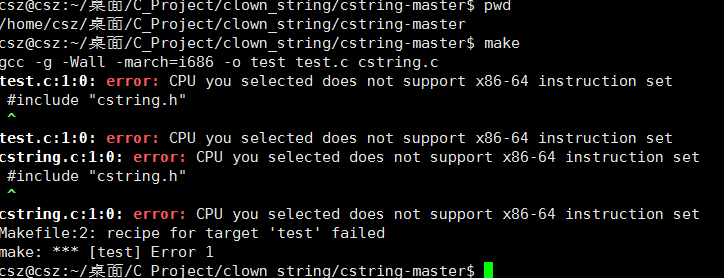
编译失败,按照下面改
vim Makefile gcc -g -Wall -march=native -o test test.c cstring.c Esc wq!
最后结果如下
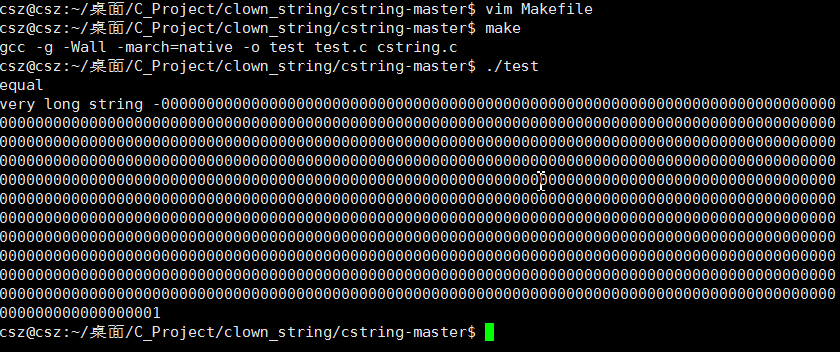
到这里 我们 代码 已经跑起来了. 对于 test.c中
我们简单 解释一下 其中 test.c使用到的 api
CSTRING_BUFFER(a); cstring_printf(a, "%s", "hello");
一开a字符串在栈上,后面输出的串比较小,仍然在栈上.后面有个
CSTRING_CLOSE(a);
关闭这个内存,本质是
#define CSTRING_CLOSE(var) \ if ((var)->str->type != 0) {} else \ cstring_release((var)->str);
因为 a->str->type == CSTRING_ONSTACK != 0 所以 cstring_release执行后没有反应,可有可无.
但是 推荐 CSTRING_BUFFER 和 CSTRING_CLOSE 成对出现.
还有就是 foo 函数里面
CSTRING_LITERAL(hello, "hello"); CSTRING_BUFFER(ret);
hello 相当于 符号表中字符串,生存周期是 和程序同生共死的.ret 目前在栈上.
后面
if (cstring_equal(hello,t)) { cstring_cat(ret, "equal"); } else { cstring_cat(ret, "not equal"); }
这个二者 执行 的 cstring_cat(ret, "equal"); 结果是 塞得字符串小 ret仍然是栈上的.
后面返回
return cstring_grab(CSTRING(ret));
变成运行时串 既
cs->type = CSTRING_INTERNING;
cs->ref = 0;
所以最后 就不需要 CSTRING_CLOSE (ret);
到了
cstring_printf(a, "very long string %01024d",0);
变成待释放的临时串 r->type = 0; r->ref = 1;
技巧很多,主要还是需要看 源码, 将在第三部剖析一下 实现 string.c中的一些技巧!
第三部分 string.c 源码 观察
#include "cstring.h" #include <stdio.h> #include <stdlib.h> #include <assert.h> #include <string.h> #include <stdarg.h> #define FORMAT_TEMP_SIZE 1024 #define INTERNING_POOL_SIZE 1024 // HASH_START_SIZE must be 2 pow #define HASH_START_SIZE 16 struct string_node { struct cstring_data str; char buffer[CSTRING_INTERNING_SIZE]; struct string_node * next; }; struct string_pool { struct string_node node[INTERNING_POOL_SIZE]; }; struct string_interning { int lock; int size; struct string_node ** hash; struct string_pool * pool; int index; int total; }; static struct string_interning S; static inline void LOCK() { while (__sync_lock_test_and_set(&(S.lock),1)) {} } static inline void UNLOCK() { __sync_lock_release(&(S.lock)); } static void insert_node(struct string_node ** hash, int sz, struct string_node *n) { uint32_t h = n->str.hash_size; int index = h & (sz-1); n->next = hash[index]; hash[index] = n; } static void expand(struct string_interning * si) { int new_size = si->size * 2; if (new_size < HASH_START_SIZE) { new_size = HASH_START_SIZE; } assert(new_size > si->total); struct string_node ** new_hash = malloc(sizeof(struct string_node *) * new_size); memset(new_hash, 0, sizeof(struct string_node *) * new_size); int i; for (i=0;i<si->size;i++) { struct string_node *node = si->hash[i]; while (node) { struct string_node * tmp = node->next; insert_node(new_hash, new_size, node); node = tmp; } } free(si->hash); si->hash = new_hash; si->size = new_size; } static cstring interning(struct string_interning * si, const char * cstr, size_t sz, uint32_t hash) { if (si->hash == NULL) { return NULL; } int index = (int)(hash & (si->size-1)); struct string_node * n = si->hash[index]; while(n) { if (n->str.hash_size == hash) { if (strcmp(n->str.cstr, cstr) == 0) { return &n->str; } } n = n->next; } // 80% (4/5) threshold if (si->total * 5 >= si->size * 4) { return NULL; } if (si->pool == NULL) { // need not free pool // todo: check memory alloc error si->pool = malloc(sizeof(struct string_pool)); assert(si->pool); si->index = 0; } n = &si->pool->node[si->index++]; memcpy(n->buffer, cstr, sz); n->buffer[sz] = '\0'; cstring cs = &n->str; cs->cstr = n->buffer; cs->hash_size = hash; cs->type = CSTRING_INTERNING; cs->ref = 0; n->next = si->hash[index]; si->hash[index] = n; return cs; } static cstring cstring_interning(const char * cstr, size_t sz, uint32_t hash) { cstring ret; LOCK(); ret = interning(&S, cstr, sz, hash); if (ret == NULL) { expand(&S); ret = interning(&S, cstr, sz, hash); } ++S.total; UNLOCK(); assert(ret); return ret; } static uint32_t hash_blob(const char * buffer, size_t len) { const uint8_t * ptr = (const uint8_t *) buffer; size_t h = len; size_t step = (len>>5)+1; size_t i; for (i=len; i>=step; i-=step) h = h ^ ((h<<5)+(h>>2)+ptr[i-1]); if (h == 0) return 1; else return h; } void cstring_free_persist(cstring s) { if (s->type == CSTRING_PERMANENT) { free(s); } } static cstring cstring_clone(const char * cstr, size_t sz) { if (sz < CSTRING_INTERNING_SIZE) { return cstring_interning(cstr, sz, hash_blob(cstr,sz)); } struct cstring_data * p = malloc(sizeof(struct cstring_data) + sz + 1); // todo: memory alloc error assert(p); void * ptr = (void *)(p + 1); p->cstr = ptr; p->type = 0; p->ref = 1; memcpy(ptr, cstr, sz); ((char *)ptr)[sz] = '\0'; p->hash_size = 0; return p; } cstring cstring_persist(const char * cstr, size_t sz) { cstring s = cstring_clone(cstr, sz); if (s->type == 0) { s->type = CSTRING_PERMANENT; s->ref = 0; } return s; } cstring cstring_grab(cstring s) { if (s->type & (CSTRING_PERMANENT | CSTRING_INTERNING)) { return s; } if (s->type == CSTRING_ONSTACK) { cstring tmp = cstring_clone(s->cstr, s->hash_size); return tmp; } else { if (s->ref == 0) { s->type = CSTRING_PERMANENT; } else { __sync_add_and_fetch(&s->ref,1); } return s; } } void cstring_release(cstring s) { if (s->type != 0) { return; } if (s->ref == 0) { return; } if (__sync_sub_and_fetch(&s->ref,1) == 0) { free(s); } } uint32_t cstring_hash(cstring s) { if (s->type == CSTRING_ONSTACK) return hash_blob(s->cstr, s->hash_size); if (s->hash_size == 0) { s->hash_size = hash_blob(s->cstr, strlen(s->cstr)); } return s->hash_size; } int cstring_equal(cstring a, cstring b) { if (a == b) return 1; if ((a->type == CSTRING_INTERNING) && (b->type == CSTRING_INTERNING)) { return 0; } if ((a->type == CSTRING_ONSTACK) && (b->type == CSTRING_ONSTACK)) { if (a->hash_size != b->hash_size) { return 0; } return memcmp(a->cstr, b->cstr, a->hash_size) == 0; } uint32_t hasha = cstring_hash(a); uint32_t hashb = cstring_hash(b); if (hasha != hashb) { return 0; } return strcmp(a->cstr, b->cstr) == 0; } static cstring cstring_cat2(const char * a, const char * b) { size_t sa = strlen(a); size_t sb = strlen(b); if (sa + sb < CSTRING_INTERNING_SIZE) { char tmp[CSTRING_INTERNING_SIZE]; memcpy(tmp, a, sa); memcpy(tmp+sa, b, sb); tmp[sa+sb] = '\0'; return cstring_interning(tmp, sa+sb, hash_blob(tmp,sa+sb)); } struct cstring_data * p = malloc(sizeof(struct cstring_data) + sa + sb + 1); // todo: memory alloc error assert(p); char * ptr = (char *)(p + 1); p->cstr = ptr; p->type = 0; p->ref = 1; memcpy(ptr, a, sa); memcpy(ptr+sa, b, sb); ptr[sa+sb] = '\0'; p->hash_size = 0; return p; } cstring cstring_cat(cstring_buffer sb, const char * str) { cstring s = sb->str; if (s->type == CSTRING_ONSTACK) { int i = (int)s->hash_size; while (i < CSTRING_STACK_SIZE-1) { s->cstr[i] = *str; if (*str == '\0') { return s; } ++s->hash_size; ++str; ++i; } s->cstr[i] = '\0'; } cstring tmp = s; sb->str = cstring_cat2(tmp->cstr, str); cstring_release(tmp); return sb->str; } static cstring cstring_format(const char * format, va_list ap) { static char * cache = NULL; char * result; char * temp = cache; // read cache buffer atomic if (temp) { temp = __sync_val_compare_and_swap(&cache, temp, NULL); } if (temp == NULL) { temp = (char *)malloc(FORMAT_TEMP_SIZE); // todo : check malloc assert(temp); } int n = vsnprintf(temp, FORMAT_TEMP_SIZE, format, ap); if (n >= FORMAT_TEMP_SIZE) { int sz = FORMAT_TEMP_SIZE * 2; for (;;) { result = malloc(sz); // todo : check malloc assert(result); n = vsnprintf(result, sz, format, ap); if (n >= sz) { free(result); sz *= 2; } else { break; } } } else { result = temp; } cstring r = (cstring)malloc(sizeof(struct cstring_data) + n + 1); // todo : check malloc assert(r); r->cstr = (char *)(r+1); r->type = 0; r->ref = 1; r->hash_size = 0; memcpy(r->cstr, result, n+1); if (temp != result) { free(result); } // save temp atomic if (!__sync_bool_compare_and_swap(&cache, NULL, temp)) { free(temp); } else { } return r; } cstring cstring_printf(cstring_buffer sb, const char * format, ...) { cstring s = sb->str; va_list ap; va_start(ap, format); if (s->type == CSTRING_ONSTACK) { int n = vsnprintf(s->cstr, CSTRING_STACK_SIZE, format, ap); if (n >= CSTRING_STACK_SIZE) { s = cstring_format(format, ap); sb->str = s; } else { s->hash_size = n; } } else { cstring_release(sb->str); s = cstring_format(format, ap); sb->str = s; } va_end(ap); return s; }
上面就是 cstring.c的源码 . 总的而言还是比较短的容易理解 ,我们依次分析. 扯一点,
他这些技巧我都会,还敲了两三遍. 因为他用的比我熟练.假如你看到这, 你需要 敲更多,才能掌握,C的技巧也挺难的.真的
搞起来就和算术公式一样.
首先分析数据结构,基本就是流水账了
/** * todo insert explain * * FORMAT_TEMP_SIZE 是后面函数 cstring_format 分配内存初始化大小 1k * * INTERNING_POOL_SIZE 表示 符号表池的大小 1k * * HASH_START_SIZE hash操作在expand中使用,插入hash使用,是 a mod b 中b的初始化值 */ #define FORMAT_TEMP_SIZE 1024 #define INTERNING_POOL_SIZE 1024 // HASH_START_SIZE must be 2 pow #define HASH_START_SIZE 16 /** * todo insert explain * * 这是一个字符串链表, hash采用桶和链表实现,这就是链表. * char buffer[CSTRING_INTERNING_SIZE];内存在栈上 ,直接 给 string_node.str.cstr * struct string_node保存运行中字符串,直接和 程序同生存周期 */ struct string_node { struct cstring_data str; char buffer[CSTRING_INTERNING_SIZE]; struct string_node * next; }; /* * todo insert explain * * string_node 的 池,这个吃的大小是固定的,1k,过了程序会异常 */ struct string_pool { struct string_node node[INTERNING_POOL_SIZE]; }; /** * 这是 字符串 池 * * lock 加锁用的 * size hash的大小,围绕他取余做hash * hash 保存字符串的对象 * pool 符号表存储的地方 * index 内部指示 pool使用到哪了 * total 指示当前 string_interning 中保存了多少 字符串运行时常量 */ struct string_interning { int lock; int size; struct string_node ** hash; struct string_pool * pool; int index; int total; }; // 全局临时用的 字符串池对象 static struct string_interning S; // 加锁 static inline void LOCK() { while (__sync_lock_test_and_set(&(S.lock), 1)) {} } //解锁 具体参照 原子参照 static inline void UNLOCK() { __sync_lock_release(&(S.lock)); }
这里扩展一下 就相当于吐槽,首先 关于
S.index 用法 局限性很大
if (si->pool == NULL) { // need not free pool //todo : check memory alloc error si->pool = malloc(sizeof(struct string_pool)); assert(si->pool); si->index = 0; } n = &si->pool->node[si->index++];
全局只用++,相当于只生产字符串,只增不减. 超过了 1024 程序就崩了. 内存访问越界. 这里 我们在下一篇博文中
重构这个字符串.思路有两个
1. 打错误日志, 加大错误 警报作用
2. 改变 string_interning 结构, 让其也支持自动扩容处理.
吐槽一下, 他这里 写的不好, 这样的代码 , 根本不敢挂上服务器跑. 到时候再优化,保证让其从玩具变成高级玩具.
这里 再吐槽一下 关于 gcc inline 用法. 具体看 推荐的 参照资料. inline 只能用于简单的 顺序结构函数.
否则 这样声明编译器也还是让其 变为 普通函数.
测试如下,采用window 汇编,linux 也一样 通过 gcc -S 看 汇编.
测试 main.c 如下:
#include <stdio.h> #include <stdlib.h> int g_cut = 0; __inline void cnotcplusplus(void) { for (int i = 0; i < 10; ++i) ++g_cut; //测试三 VS能够使用内联 //++ g_cut; } int main(int argc, char* argv[]) { printf("g_cut = %d\n", g_cut); /* *测试一 */ for (int i = 0; i < 10; ++i) ++g_cut; /* * 测试二 内联函数 汇编代码对比 */ cnotcplusplus(); printf("g_cut = %d\n", g_cut); system("pause"); return 0; }
编译环境是
这里运行打断点 查看 汇编 如下
--- h:\vs_project\clouwu_string\test_inline\main.c ----------------------------- printf("g_cut = %d\n", g_cut); 012A1040 push dword ptr [g_cut (012A3374h)] 012A1046 push offset string "g_cut = %d\n" (012A2108h) 012A104B call printf (012A1010h) /* *测试一 */ for (int i = 0; i < 10; ++i) ++g_cut; 012A1050 mov eax,dword ptr [g_cut (012A3374h)] /* * 测试二 内联函数 汇编代码对比 */ cnotcplusplus(); 012A1055 add eax,14h printf("g_cut = %d\n", g_cut); 012A1058 push eax 012A1059 push offset string "g_cut = %d\n" (012A2108h) /* * 测试二 内联函数 汇编代码对比 */ cnotcplusplus(); 012A105E mov dword ptr [g_cut (012A3374h)],eax printf("g_cut = %d\n", g_cut); 012A1063 call printf (012A1010h) system("pause"); 012A1068 push offset string "pause" (012A2114h) system("pause"); 012A106D call dword ptr [__imp__system (012A2064h)] 012A1073 add esp,14h return 0; 012A1076 xor eax,eax }
大家可以自己测试测试,这里测试结果 关于 inline 函数中出现 while 编译器 会将这个 inline函数当做 普通函数处理.
这是一个失误,如果 一定要这么干, 可以用 宏代替,下一个版本再搞. 这个字符串博文拖得太长了,准备就当下 草草干掉了. 争取下一个版本
带来一个高级的玩具.
/* * 将字符串结点n 插入 到 字符串hash表中 * * h & (sz -1) => h mod sz, 当然 sz 必须 是 2 正整数次幂 */ static inline void insert_node(struct string_node ** hash, int sz, string_node *n) ; /* * 对 S 中初始化或 扩容的函数 * 会重新hash操作,调整结构 */ static void expand(struct string_interning * si); /* * 插入 一个字符串到 字符串池中,线程安全,运行时不安全 */ static cstring cstring_interning(const char * cstr, size_t sz, uint32_t hash); /* * js hash 命中率 为 80%左右 * 这里 对于 h == 0,即hash_size == 0做特殊处理,待定,没有比较久不需要生成 */ static uint32_t hash_blob(const char * buffer, size_t len);
这里简单说一下对于 expand 中
int new_size = si->size * 2; if (new_size < HASH_START_SIZE) { new_size = HASH_START_SIZE; }
第二个判断可以省略,放在 S 的声明的初始化中. 其它的改进不提了,自己看,多看看都能有见解. 这里扩展一下, 刚对 他的写的代码.
还是 能感觉一股铺面而来的代码 美感, 能感觉都很多都是手工敲的. 他的美感 多于他的失误. 但是 这样的代码是不能用在实战中,为什么呢,
你用这个代码,你看几遍这个源码.用起来内存泄露的都无法控制了. 这也是很多开源的代码,不是领头羊,很少敢直接用于 核心模块中,除非 别无选择.
因为 维护的人没时间, 而自己不是作者,改起来成本比开发一个更高.总而言之,开源和封闭 是 两种模式 最鲜明对比就是 安卓 与 ios.
继续,
/* * 释放永久串, 相当于 释放 'static' string */ void cstring_free_persist(cstring s) ; /* * 这里 复制一份字符串, * type =0 , 表示 未初始化, 这样串可以可以被 cstring_release释放 */ static cstring cstring_clone(const char * cstr, size_t sz) ; /* * 申请这样的永久的串 */ cstring cstring_persist(const char * cstr, size_t sz) ; /* * 将栈上串 搞一份出来到 普通串中需要调用 释放函数 CSTRING_CLOSE * 如果 是 永久串 直接 变成 引用加1 */ cstring cstring_grab(cstring s) ; /* * 释放函数.只有 type == 0 && s->ref == 1才去释放 */ void cstring_release(cstring s);
这里再扩展一下 看 cstring.h 中宏
#define CSTRING_LITERAL(var, cstr) \ static cstring var = NULL; \ if (var) {} else { \ cstring tmp = cstring_persist(""cstr, (sizeof(cstr)/sizeof(char)-1)); \ if(!__sync_bool_compare_and_swap(&var, NULL, tmp)){ \ cstring_free_persist(tmp); \ } \ }
这也是个技巧,如何创建 静态 堆上 常用变量. 相当于 通过 CSTRING_LITERAL 创建 静态的字符串 var 变量
并声明了内存. 云风就是在秀技巧的. 反正也是学到了,下次自己也用用.
后面还有字符串拼接,这就是 相当于 字符串重构,性能差. 也是为什么要有 StringBuilder 的原因
/** * * 就是一个简单的字符串拼接函数,比较低效 * * 这里有个优化 是 如果串比较直接放在栈上 */ static cstring cstring_cat2(const char *a, const char * b) ; /* * 先自己拼接一下 啥也没解决 最后给 cstring_cat2 */ cstring cstring_cat(cstring_buffer sb, const char *str) ;
更多的细节 需要看 源码. 最后 分析 string_printf 函数
/* * 找到固定大小 塞数据进来 */ static cstring cstring_format(const char * format, va_list ap) ; /* * 按照标准输出到 sb中,sb内存不够会给它分配 通过 cstring_format */ cstring cstring_printf(cstring_buffer sb, const char *format, ...) ;
到这里 源码 是看完了.
多写几遍都明白了. 不好意思 太晚了不扩展了,(后面有点忽悠了, 明天还要上班.)
后记
到这里 错误是难免的,欢迎指正立马改. 下一篇中 会对cstring 进行重构. 解决 云风的坑.
最后想说一句, char * 够用了, 真的,C开发没有那么多复杂的.
我很水,但我 会改正的, 欢迎批评.

