Nonebot2插件:抽卡=欧皇?非酋:铁非酋
面向CV编程!
感觉bot没啥人用的话挺多功能都停留在脑部构思阶段了
广告位
没想好,唔-1.update(22/5/29)
突然发现prts有个干员上线时间一览可以看具体上线时间,稀有度也给了......获取途径也有
这样就不用爬bwiki了,模拟卡池也好做了,嗯!
总之这篇当做不完善的好了,搞懂了重新写一篇
prts,我的超人!
再update
麻了怎么卡池信息是js动态加载
滚去学js和selenium之类的了
0.非酋
一个游戏群自然需要模拟抽卡的功能了,嗯
大不了自己模拟下欧非情况啥啥的
总而言之,这篇实现简单的本地模拟抽卡
有可以直接调用的模拟抽卡api吗,我想做apicaller
本文实现的是明日方舟的本地模拟抽卡,知道你违反了相关的法律法规就行
同样,抽卡插件在商店有,可以一键部署的bot或多或少也有内置,总之是自留档我菜呜呜
1.前置
requests库:下载干员头像,基本信息等等
lxml库:用于爬取整个网站的信息并构造etree来获取想要的特定信息
xpath语法:上面那个要用到的
PIL库:合成获取的图片
random库:模拟抽卡
water:本文绝大部分构成
2.开搓
1.收集相关资料
对于mrfz(明日方舟,以下均使用mrfz代替)来说,实现模拟抽卡需要收集的功能有
- 干员头像,代号
- 干员可获取途径(限定卡池专属/公招限定)
- 卡池类别(限定卡池/单up卡池/常驻双up/定向寻访) ->不过本文尚未实现
同时,还需要知道mrfz的抽卡逻辑(点开游戏看看就知道了)
一开始的设想是prts直接爬,但是干员一览用了js动态加载(不会爬了),同时也没有直接给出星级及卡池类别
然后的思路是爬一遍全部名字再到各个干员的个人界面里爬,比较麻烦
最后找的解决方法是zhenxunbot
里抽卡资源下载使用的bwiki 具体代码里说
顺带copy了实现思路,面向cv编程
总之,我们定义了一个只响应超级用户的函数,用于更新当前的方舟卡池(即从网站上爬取最新的卡池列表和干员信息)
代码点我看,有点杂
import nonebot
from nonebot.rule import *
from nonebot.permission import SUPERUSER # 调用才能响应
from nonebot import *
from nonebot.adapters.onebot.v11 import Bot, Event
from nonebot.adapters.onebot.v11.message import Message
import json
import re
import urllib.parse
from lxml import etree
import requests
async def handle_rule(bot: Bot, event: Event) -> bool: # 模板直接复制懒得改了,响应最好在自己测试群?
with open("src/plugins/群名单.txt", encoding='utf-8') as file: # 提取白名单群文件中的群号
white_block = []
for line in file:
line = line.strip()
line = re.split("[ |#]", line) # 可能会有'#'注释或者空格分割
white_block.append(line[0]) # 新建一个表给它扔进去
try:
whatever, group_id, user_id = event.get_session_id().split('_') # 获取当前群聊id,发起人id,返回的格式为group_groupid_userid
except: # 如果上面报错了,意味着发起的是私聊,返回格式为userid
group_id = None
user_id = event.get_session_id()
if group_id in white_block or group_id == None:
return True
else:
return False
update_ark = on_command('更新方舟卡池', permission=SUPERUSER, rule=handle_rule,
priority=50) # permission实现了只对特定用户进行响应,SUPERUSER只对config里的超级用户响应
'''
看的zhenxunbot的源码
爬取Bwiki的方舟档案,获取干员头像及基本信息(稀有度/名字) ->原思路尝试爬prtswiki的干员名字,用selenium爬取干员信息
不过BilibiWIki直接有卡池类别,不考虑更新不同步的情况下先爬Bwiki的具体信息然后下载prts的头像(prts的头像大小更加统一且默认无背景好看点)
同时爬取当前最新卡池,或模拟卡池(切换历史常驻卡池/定向寻访/单up卡池/限定卡池) -> 还没写
慢慢写了
面向cv编程!
'''
character_list = {}
@update_ark.handle()
async def update_ark_handle(bot: Bot, event: Event):
try:
whatever, group_id, user_id = event.get_session_id().split('_') # 获取当前群聊id,发起人id,返回的格式为group_groupid_userid
data = await bot.call_api('get_group_member_list', **{
'group_id': int(group_id)
})
except: # 如果上面报错了,意味着发起的是私聊,返回格式为userid
group_id = None
user_id = event.get_session_id()
url1 = "https://wiki.biligame.com/arknights/%E5%B9%B2%E5%91%98%E6%95%B0%E6%8D%AE%E8%A1%A8"
url2 = "https://prts.wiki/w/PRTS:%E6%96%87%E4%BB%B6%E4%B8%80%E8%A7%88/%E5%B9%B2%E5%91%98%E7%B2%BE%E8%8B%B10%E5%A4%B4%E5%83%8F"
"""
url1是bwiki的链接,没有使用js动态加载可以直接爬全了,可以获取干员代号,稀有度,卡池来源,一键到位
url2是prts的链接,对应的是干员精英0头像目录,还挺方便
爬干员头像的时候还是用的zhenxunbot爬bwiki一样的思路,感觉全部下载有更加方便的方法
"""
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.66"
}
request = requests.get(url2, headers=headers).text # 上个请求头防反爬
dom = etree.HTML(request, etree.HTMLParser()) # 换成DOM树形式,然后就可以用xpath瞎搞了
char_list2 = dom.xpath("//div[@class='mw-parser-output']/p/a")
prts_dict = {}
for char in char_list2:
try:
img = char.xpath("./img/@data-srcset")[0] # 获取高清图像,prts上的分别是75px和100px,透明背景
name = char.xpath("./img/@alt")[0] # 获取干员代号,但prts命名规则是 "头像 xxxx.png"下面处理了
img_url = "https://prts.wiki/" + urllib.parse.unquote(str(img).split(' ')[-2])
character_dict = {
'name': str(name).replace("头像 ", '').replace(".png", ''),
'img_url': img_url
}
prts_dict[character_dict['name']] = character_dict # 为了避免重复直接扔到一个
except:
continue
'''
"/"从根节点选取。
"//"从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
"@"选取属性。
上面的意思就是匹配文档中table类,并且id为"mw-parser-output"的表,然后匹配其目录下的"/p/a",最后获取到的是一个"a"类的列表
循环里的部分放bwiki那边了
看不懂直接对着教程看下就好了,都是基础语法
'''
'''
无聊试试写进xml里看看爬下来没
with open("test.xml","w",encoding='utf-8') as w:
for char in char_list:
w.write(etree.tounicode(char))
w.close()
'''
ww = {}
request = requests.get(url1, headers=headers).text
dom = etree.HTML(request, etree.HTMLParser())
char_list = dom.xpath("//table[@id='CardSelectTr']/tbody/tr")
for char in char_list:
try:
# continue
avatar = char.xpath("./td[1]/div/div/div/a/img/@srcset")[0]
'''
"."选取当前节点。
"td[x]"返回第x个td类型
然后接着往下接着往下(格式自己参考网页)
"@srcset"获取图像高清的地址
"@src"获取的是适配后的地址
返回的是list所以[0]
'''
name = char.xpath("./td[2]/a/text()")[0] # 名字
name = str(name).split()[0].replace("(", "(").replace(")",
")") # 小心()括号危机,prts的近卫阿米娅用的是英文括号,但bwiki是中文,查了半天,虽然抽不到但还是不爽
star = char.xpath("./td[5]/text()")[0] # 星级
"""zhenxunbot的话:这里sources修好了干员获取标签有问题的bug,如三星只能抽到卡缇就是这个原因"""
sources = [_.strip('\n') for _ in char.xpath("./td[8]/text()")] # 卡池类别
character_dict = {
"pic_url": urllib.parse.unquote(str(avatar).split(' ')[-2]), # 获取120px的头像,如果想要获取90px的后面改成[0]就行
"prts_url": prts_dict[name]['img_url'], # 加进来了prst的头像,100px的,另一个格式是75px的
"name": name, # 干员代号
"star": int(star), # 稀有度(这个本体居然带了个回车,保存的时候不知道哪里错了)
"from_where": sources # 卡池类别,具体看下bwiki
}
ww[character_dict['name']] = character_dict # bwiki会重复,所以用字典一对一
# 不过prts的近卫阿米娅Bwiki好像没收录(本来就抽不出来所以不管啦) -> 破案了,一个中文括号一个英文括号
pic = requests.get(character_dict['prts_url'])
open(f"src/plugins/gacha/icon/arknights/{int(star)}/{name}.jpg", "wb").write(
pic.content) # 保存到本地,按星级建立文件夹,以干员代号命名
# 由于bwiki并没有收录预备干员/肉鸽四天王/肉鸽版本暮落,某种意义上方便了抽卡的时候过滤
except:
# bwiki会爬到一些奇怪的地方
continue
with open('src/plugins/gacha/game_opreator_data/arknights.txt', 'w', encoding='utf-8') as f:
for j in ww.values():
f.write(json.dumps(j, ensure_ascii=False))
f.write("\n")
# 保存下干员信息,等下需要用到的,json格式参考character_dict的格式,就不写了
await update_ark.finish(Message(f"干员信息已经更新!"))
示例:木得,反正会保存到本地
可能会出现的问题就是bwiki和prts更新不统一导致没有下下来干员吧,因为干员信息是基于bwiki的
2.模拟函数
没啥好说的,概率直接看游戏里的说明,但是实现会看起来很奇怪
用到了random.choices,可以根据不同权重抽取
唔....这个真的模拟出来了可以直接欧皇附体吧
这个没写在主体里面,三个函数用了文件包的形式,方便后续追加更多游戏import json
import re
import math
import time
from PIL import Image, ImageDraw
import random
operators = []
with open('src/plugins/gacha/game_opreator_data/arknights.txt', 'r', encoding='utf-8') as r:
for lines in r.readlines():
js = json.loads(lines.strip())
operators.append(js)
def ark_gacha(a: int) -> str: # 设置抽奖数,返回生成的图片的本地地址
original_P = [0.40, 0.50, 0.08, 0.02] # 方舟的卡池概率
star = [3, 4, 5, 6] # 对于的星级
last_six = 0 # 上一个六星花了多少抽,方舟的抽卡机制为连续50抽后未出六星则概率+2%,直到抽出重置
list_six = [] # 放下抽到的六星
gacha_type = ["常驻", "限定", "定向寻访"] # 卡池类别,还没实现
up_operator = ["史尔特尔", "异客"] # 目前还没想好该怎么实现更新卡池,接着照抄zhenxunbot的写法大概就是
full_operator = [x['name']
for x in operators
if x['star'] == 6 and x['name'] not in up_operator and "干员寻访" in x['from_where']]
"""
获取全部的六星干员,且为常驻(排除赠送和限定)
目前实现的是直接奔着300抽(一井)设计的
如果设置10连抽可能要考虑每个人单独设置水位(指last_six),或者建个数据库储存下干员列表啥的
然后J就犯懒癌了
"""
for i in range(a): # 简单粗暴地模拟每抽
gt_star = random.choices(star, weights=original_P, k=1) # 小抽一发,返回的是list
for get_star in gt_star:
if get_star == 6: # 如果是6星,那么直接水位清零
last_six = 0
six_operator = random.choices([0, 1], k=1)[0] # 抽一下是不是up干员(常驻是50%,限定是70%)
if six_operator:
list_six.append(up_operator[random.choices([0, 1], k=1)[0]]) # 再在up干员里随机一个
else:
list_six.append(random.choice(full_operator)) # 不然就全局随机一个(已经排除了up干员)
original_P = [0.40, 0.50, 0.08, 0.02] # 概率回归初始
else:
last_six += 1 # 不是6水位加一
if last_six >= 50:
original_P[3] += 0.02 # 这个实现有点奇怪,按抽卡统计大数据来看舟的六星总体会趋近于2.7%,以及还有连续没有5星的概率up,啥啥啥的
# 这里就简单地提升六星权重,不影响其他的(感觉需要)
gacha_img = Image.new(mode="RGBA", size=(
100 * 5, (100) * math.ceil(len(list_six) / 5))) # 新建一块透明画布,当通道类型为"RGBA"且没有赋值color时就会是透明的了
high = 0
for j in range(len(list_six)):
character_img = Image.open(f"/src/plugins/gacha/icon/arknights/6/{list_six[j]}.jpg") # 获取干员头像
character_img = character_img.resize((100, 100)) # 万一不是100px的
if j and j % 5 == 0: # 设置为1行显示5个,需要其他的把上面画布和这里的5都改下就好了
high += 100
gacha_img.paste(character_img, ((100 * (j % 5)), high))
gacha_img.save(f"图像保存地址.png")
img_url = "地址.png"
return img_url
# 返回生成图像地址等下直接发送
示例:这个最后函数再示例吧
常驻卡池部分的代码还没想好咋做,zhenxunbot所使用的是爬取官网的信息获取当天卡池(也就是在定时函数里要更新一下卡池列表)
实现切换卡池的也没做,大致思路是爬一下prst或其他wiki站上的历史卡池信息,然后以不同卡池为类别在值中存下当期up和当时卡池内有的六星,可能限定卡池后来还有追加权重提升,需要区分小改下
3.抽卡!
就很简单了
设置下抽卡响应参数就行
我是用包的形式编写这个插件的,所以上面和这个响应函数不是写在一起的
这个挺短
# from .arknights import *
import nonebot
import random
from PIL import Image, ImageFont, ImageDraw
from nonebot.rule import *
from nonebot import *
from nonebot.typing import T_State
from nonebot.plugin import on_keyword
from nonebot.adapters.onebot.v11 import Bot, Event, GroupMessageEvent
from nonebot.adapters.onebot.v11.message import Message
from .arknights import ark_gacha
async def handle_rule(bot: Bot, event: Event) -> bool:
with open("src/plugins/群名单.txt", encoding='utf-8') as file: # 提取白名单群文件中的群号
white_block = []
for line in file:
line = line.strip()
line = re.split("[ |#]", line) # 可能会有'#'注释或者空格分割
white_block.append(line[0]) # 新建一个表给它扔进去
try:
whatever, group_id, user_id = event.get_session_id().split('_') # 获取当前群聊id,发起人id,返回的格式为group_groupid_userid
except: # 如果上面报错了,意味着发起的是私聊,返回格式为userid
group_id = None
user_id = event.get_session_id()
if group_id in white_block or group_id == None:
return True
else:
return False
# gacha_ten = on_command("十连", rule=handle_rule, priority=40)
gacha_jing = on_command("天井", rule=handle_rule, priority=50)
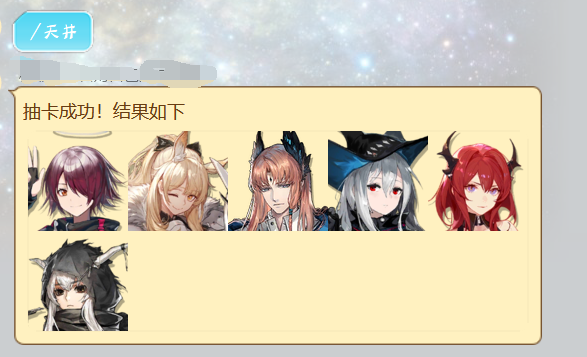
@gacha_jing.handle()
async def gacha_jing_handle(bot: Bot, event: Event):
url1 = ark_gacha(300)
# print(url1)
await gacha_jing.finish(Message(f"抽卡成功!结果如下[CQ:image,file=file:///{url1},id=40000]"))
看得到我十连没适配,其他游戏也没适配
可能考虑的方法是用on_endswith,然后对前面的类别判断下
或者是规定改咋说
command类的使用方式我还是压根没看懂啊.....
4.嘛
其实挺不完善的
但群友也不是很注重在调戏bot上,所以实现部分功能就好了
搞其他游戏模拟抽卡就想办法获取对应的游戏资源,github上挺多抽卡bot可以参考他们的爬取方式和抽卡逻辑
看到有大佬整了个一键查询材料啥的,好心动

 浙公网安备 33010602011771号
浙公网安备 33010602011771号