
Java常见编程错误:并发工具类库
为了⽅便开发者进⾏多线程编程,现代编程语⾔会提供各种并发⼯具类。但如果我们没有充分了解它们的使⽤场景、解决的问题,以及最佳实践的话,盲⽬使⽤就可能会导致⼀些坑,⼩则损失性能,⼤则⽆法确保多线程情况下业务逻辑的正确性。
⼀般⽽⾔并发⼯具包括同步器和容器两⼤类,业务代码中使⽤并发容器的情况会多⼀些。
线程重⽤导致BUG
场景:在⽣产上遇到⼀个诡异的问题,有时获取到的⽤⼾信息是别⼈的,使⽤ThreadLocal来缓存获取到的⽤⼾信息。
ThreadLocal适⽤于变量在线程间隔离,⽽在⽅法或类间共享的场景。如果⽤⼾信息的获取⽐较昂贵(⽐如从数据库查询⽤⼾信息),那么在ThreadLocal中缓存数据是⽐较合适的做法。
案例:使⽤Spring Boot创建⼀个Web应⽤程序,使⽤ThreadLocal存放⼀个Integer的值,来暂且代表需要在线程中保存的⽤⼾信息,这个值初始是null。在业务逻辑中,先从ThreadLocal获取⼀次值,然后把外部传⼊的参数设置到ThreadLocal中,来模拟从当前上下⽂获取到⽤⼾信息的逻辑,随后再获取⼀次值,最后输出两次获得的值和线程名称。
private ThreadLocal<Integer> currentUser = ThreadLocal.withInitial(() -> null);
@GetMapping("wrong")
public Map wrong(@RequestParam("userId") Integer userId) {
//设置⽤⼾信息之前先查询⼀次ThreadLocal中的⽤⼾信息
String before = Thread.currentThread().getName() + ":" + currentUser.get();
//设置⽤⼾信息到ThreadLocal
currentUser.set(userId);
//设置⽤⼾信息之后再查询⼀次ThreadLocal中的⽤⼾信息
String after = Thread.currentThread().getName() + ":" + currentUser.get();
//汇总输出两次查询结果
Map result = new HashMap();
result.put("before", before);
result.put("after", after);
return result;
}
按理说,在设置⽤⼾信息之前第⼀次获取的值始终应该是null,但我们要意识到,程序运⾏在Tomcat中, 执⾏程序的线程是Tomcat的⼯作线程,⽽Tomcat的⼯作线程是基于线程池的。
线程池会重⽤固定的⼏个线程,⼀旦线程重⽤,那么很可能⾸次从ThreadLocal获取的值是之前其他⽤⼾的请求遗留的值。这时,ThreadLocal中的⽤⼾信息就是其他⽤⼾的信息。
为了更快地重现这个问题,在配置⽂件中设置⼀下Tomcat的参数,把⼯作线程池最⼤线程数设置为1,这 样始终是同⼀个线程在处理请求:
server.tomcat.max-threads=1
运⾏程序后先让⽤⼾1来请求接⼝,可以看到第⼀和第⼆次获取到⽤⼾ID分别是null和1,符合预期:
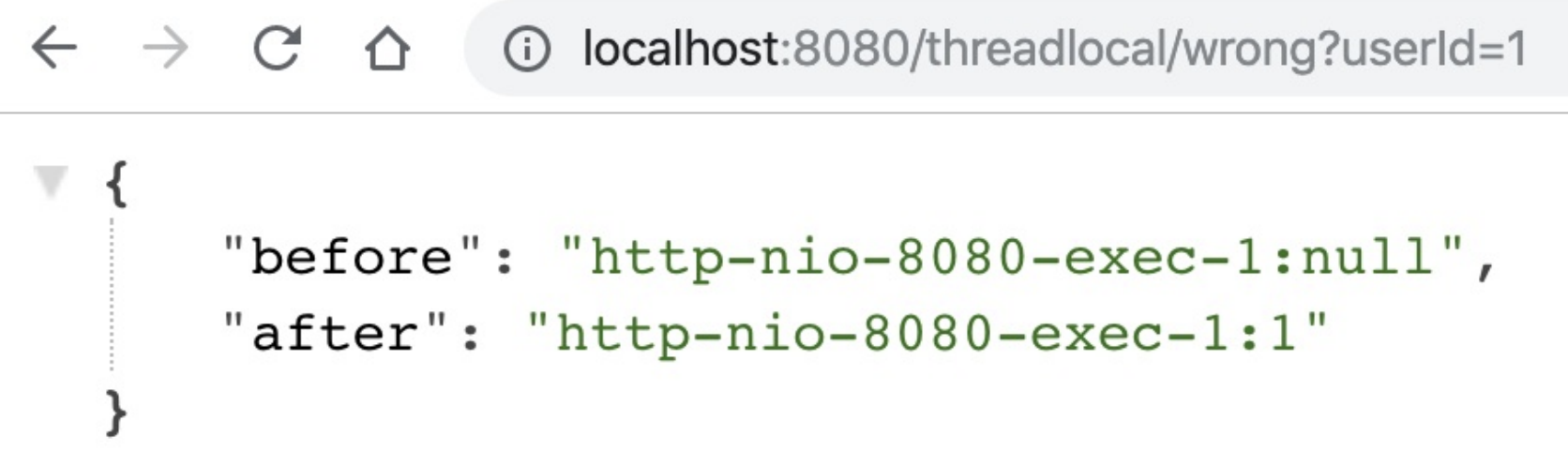
随后⽤⼾2来请求接⼝,这次就出现了Bug,第⼀和第⼆次获取到⽤⼾ID分别是1和2,显然第⼀次获取到了⽤⼾1的信息,原因就是Tomcat的线程池重⽤了线程。从图中可以看到,两次请求的线程都是同⼀个线程: http-nio-8080-exec-1。
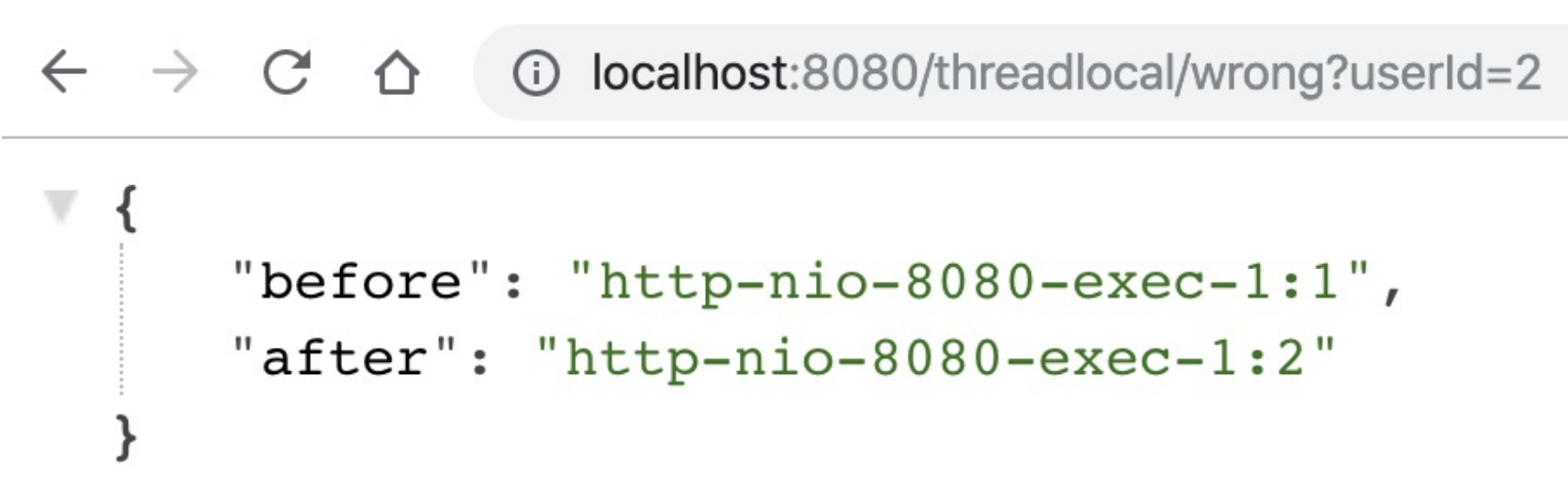
在写业务代码时,⾸先要理解代码会跑在什么线程上:
- 在Tomcat这种Web服务器下跑的业务代码,本来就运⾏在⼀个多线程环境(否则接⼝也不可能⽀持这么⾼ 的并发),并不能认为没有显式开启多线程就不会有线程安全问题。
- 因为线程的创建⽐较昂贵,所以Web服务器往往会使⽤线程池来处理请求,这就意味着线程会被重⽤。使⽤类似ThreadLocal⼯具来存放⼀些数据时,需要特别注意在代码运⾏完后,显式地去清空设置的数据。如果在代码中使⽤了⾃定义的线程池,也同样会遇到这个问题。
修正这段代码的⽅案是,在代码的finally代码块中,显式清除ThreadLocal中的数据。
@GetMapping("right")
public Map right(@RequestParam("userId") Integer userId) {
String before = Thread.currentThread().getName() + ":" + currentUser.get();
currentUser.set(userId);
try {
String after = Thread.currentThread().getName() + ":" + currentUser.get();
Map result = new HashMap();
result.put("before", before);
result.put("after", after);
return result;
} finally {
//在finally代码块中删除ThreadLocal中的数据,确保数据不串
currentUser.remove();
}
}
重新运⾏程序可以验证,再也不会出现第⼀次查询⽤⼾信息查询到之前⽤⼾请求的Bug:
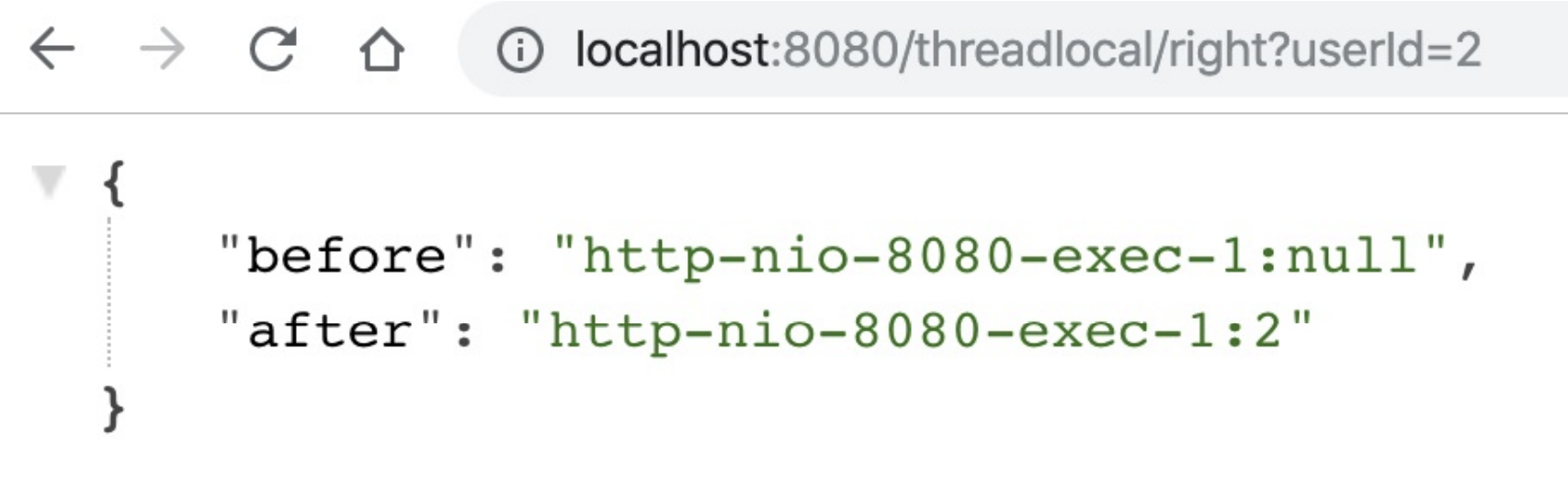
ThreadLocal是利⽤独占资源的⽅式,来解决线程安全问题,如果确实需要有资源在线程之前共享,可能就需要⽤到线程安全的容器了。
使⽤了线程安全的并发⼯具,并不代表解决了所有线程安全问题
JDK 1.5后推出的ConcurrentHashMap,是⼀个⾼性能的线程安全的哈希表容器。“线程安全”这四个字特 别容易让⼈误解,因为ConcurrentHashMap只能保证提供的原⼦性读写操作是线程安全的。
场景:
有⼀个含900个元素的Map,现在再补充 100个元素进去,这个补充操作由10个线程并发进⾏。开发⼈员误以为使⽤了ConcurrentHashMap就不会有线程安全问题,在每⼀个线程的代码逻辑中先通过size⽅法拿到当前元素数量,计算ConcurrentHashMap⽬前还需要补充多少元素,并在⽇志中输出了这个值,然后通过 putAll⽅法把缺少的元素添加进去。
为⽅便观察问题,输出了这个Map⼀开始和最后的元素个数。
//线程个数
private static int THREAD_COUNT = 10;
//总元素数量
private static int ITEM_COUNT = 1000;
//帮助⽅法,⽤来获得⼀个指定元素数量模拟数据的ConcurrentHashMap
private static ConcurrentHashMap<String, Long> getData(int count) {
return LongStream.rangeClosed(1, count)
.boxed()
.collect(Collectors.toConcurrentMap(i -> UUID.randomUUID().toString(), Function.identity(),
(o1, o2) -> o1, ConcurrentHashMap::new));
}
public static void main(String[] args) throws InterruptedException {
ConcurrentHashMap<String, Long> concurrentHashMap = getData(ITEM_COUNT - 100);
//初始900个元素
System.out.println(("init size: " + concurrentHashMap.size()));
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
//使⽤线程池并发处理逻辑
forkJoinPool.execute(() -> IntStream.rangeClosed(1, 10).parallel().forEach(i -> {
//查询还需要补充多少个元素
int gap = ITEM_COUNT - concurrentHashMap.size();
System.out.println("gap size: " + gap);
//补充元素
concurrentHashMap.putAll(getData(gap));
}));
//等待所有任务完成
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
//最后元素个数会是1000吗?
System.out.println("finish size: " + concurrentHashMap.size());
System.out.println("OK");
}
举⼀个形象的例⼦。ConcurrentHashMap就像是⼀个⼤篮⼦,现在这个篮⼦⾥有 900个桔⼦,我们期望把这个篮⼦装满1000个桔⼦,也就是再装100个桔⼦。有10个⼯⼈来⼲这件事⼉,⼤ 家先后到岗后会计算还需要补多少个桔⼦进去,最后把桔⼦装⼊篮⼦。 ConcurrentHashMap这个篮⼦本⾝,可以确保多个⼯⼈在装东西进去时,不会相互影响⼲扰,但⽆法确保 ⼯⼈A看到还需要装100个桔⼦但是还未装的时候,⼯⼈B就看不到篮⼦中的桔⼦数量。更值得注意的是,往这个篮⼦装100个桔⼦的操作不是原⼦性的,在别⼈看来可能会有⼀个瞬间篮⼦⾥有964个桔⼦,还需要 补36个桔⼦。
ConcurrentHashMap对外提供的⽅法或能⼒的限制:
- 使⽤了ConcurrentHashMap,不代表对它的多个操作之间的状态是⼀致的,是没有其他线程在操作它 的,如果需要确保需要⼿动加锁。
- 诸如size、isEmpty和containsValue等聚合⽅法,在并发情况下可能会反映ConcurrentHashMap的中间 状态。因此在并发情况下,这些⽅法的返回值只能⽤作参考,⽽不能⽤于流程控制。显然,利⽤size⽅法 计算差异值,是⼀个流程控制。
- 诸如putAll这样的聚合⽅法也不能确保原⼦性,在putAll的过程中去获取数据可能会获取到部分数据。
修改⽅案:整段逻辑加锁即可
ConcurrentHashMap<String, Long> concurrentHashMap = getData(ITEM_COUNT - 100);
System.out.println(("init size: " + concurrentHashMap.size()));
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
forkJoinPool.execute(() -> IntStream.rangeClosed(1, 10).parallel().forEach(i -> {
//下⾯的这段复合逻辑需要锁⼀下这个ConcurrentHashMap
synchronized (concurrentHashMap) {
int gap = ITEM_COUNT - concurrentHashMap.size();
System.out.println("gap size: " + gap);
concurrentHashMap.putAll(getData(gap));
}
}));
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
System.out.println("finish size: " + concurrentHashMap.size());
System.out.println("OK");
重新调⽤接⼝,程序的⽇志输出结果符合预期:
没有充分了解并发⼯具的特性,从⽽⽆法发挥其威⼒
场景:
使⽤Map来统计Key出现次数
- 使⽤ConcurrentHashMap来统计,Key的范围是10。
- 使⽤最多10个并发,循环操作1000万次,每次操作累加随机的Key。
- 如果Key不存在的话,⾸次设置值为1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号