# 导入必要的库
import numpy as np
import os
import struct
import matplotlib.pyplot as plt
# 定义导入函数
def load_images(path):
with open(path, "rb") as f:
data = f.read()
magic_number, num_items, rows, cols = struct.unpack(">iiii", data[:16])
return np.asanyarray(bytearray(data[16:]), dtype=np.uint8).reshape(
num_items, 28, 28
)
def load_labels(file):
with open(file, "rb") as f:
data = f.read()
return np.asanyarray(bytearray(data[8:]), dtype=np.int32)
# 定义sigmoid函数
def sigmoid(x):
result = np.zeros_like(x)
positive_mask = x >= 0
result[positive_mask] = 1 / (1 + np.exp(-x[positive_mask]))
negative_mask = x < 0
exp_x = np.exp(x[negative_mask])
result[negative_mask] = exp_x / (1 + exp_x)
return result
# 定义softmax函数
def softmax(x):
max_x = np.max(x, axis=-1, keepdims=True)
x = x - max_x
ex = np.exp(x)
sum_ex = np.sum(ex, axis=1, keepdims=True)
result = ex / sum_ex
result = np.clip(result, 1e-10, 1e10)
return result
# 定义独热编码函数
def make_onehot(labels, class_num):
result = np.zeros((labels.shape[0], class_num))
for idx, cls in enumerate(labels):
result[idx, cls] = 1
return result
# 定义dataset类
class Dataset:
def __init__(self, all_images, all_labels):
self.all_images = all_images
self.all_labels = all_labels
def __getitem__(self, index):
image = self.all_images[index]
label = self.all_labels[index]
return image, label
def __len__(self):
return len(self.all_images)
# 定义dataloader类
class DataLoader:
def __init__(self, dataset, batch_size, shuffle=True):
self.dataset = dataset
self.batch_size = batch_size
self.shuffle = shuffle
self.idx = np.arange(len(self.dataset))
def __iter__(self):
# 如果需要打乱,则在每个 epoch 开始时重新排列索引
if self.shuffle:
np.random.shuffle(self.idx)
self.cursor = 0
return self
def __next__(self):
if self.cursor >= len(self.dataset):
raise StopIteration
# 使用索引来获取数据
batch_idx = self.idx[
self.cursor : min(self.cursor + self.batch_size, len(self.dataset))
]
batch_images = self.dataset.all_images[batch_idx]
batch_labels = self.dataset.all_labels[batch_idx]
self.cursor += self.batch_size
return batch_images, batch_labels
# 主函数
if __name__ == "__main__":
# 加载训练集图片、标签
train_images = (
load_images(
os.path.join(
"Python", "NLP basic", "data", "minist", "train-images.idx3-ubyte"
)
)
/ 255
)
train_labels = make_onehot(
load_labels(
os.path.join(
"Python", "NLP basic", "data", "minist", "train-labels.idx1-ubyte"
)
),
10,
)
# 加载测试集图片、标签
dev_images = (
load_images(
os.path.join(
"Python", "NLP basic", "data", "minist", "t10k-images.idx3-ubyte"
)
)
/ 255
)
dev_labels = load_labels(
os.path.join("Python", "NLP basic", "data", "minist", "t10k-labels.idx1-ubyte")
)
# 设置超参数
epochs = 10
lr = 0.08
batch_size = 200
shuffle = True
# 展开图片数据
train_images = train_images.reshape(60000, 784)
dev_images = dev_images.reshape(-1, 784)
# 调用dataset类和dataloader类
train_dataset = Dataset(train_images, train_labels)
train_dataloader = DataLoader(train_dataset, batch_size, shuffle)
dev_dataset = Dataset(dev_images, dev_labels)
dev_dataloader = DataLoader(dev_dataset, batch_size, shuffle)
# 权重和偏置
w1 = np.random.normal(0, 1, size=(784, 512)) # 第一层权重
w3 = np.random.normal(0, 1, size=(512, 256)) # 第三层权重
w4 = np.random.normal(0, 1, size=(256, 10)) # 第四层权重
b1 = np.random.normal(0, 1, size=(1, 512)) # 第一层偏置
b3 = np.random.normal(0, 1, size=(1, 256)) # 第三层偏置
b4 = np.random.normal(0, 1, size=(1, 10)) # 第四层偏置
# 训练集训练过程
for e in range(epochs):
for batch_images, batch_labels in train_dataloader:
# 前向传播
H1 = np.dot(batch_images, w1) + b1 # 第一层输出
H2 = sigmoid(H1) # 第二层输出,使用sigmoid激活函数
H3 = np.dot(H2, w3) + b3 # 第三层输出
H4 = np.dot(H3, w4) + b4 # 第四层输出
p = softmax(H4) # 输出层输出,使用softmax激活函数
# 计算损失
loss = -np.mean(np.sum(batch_labels * np.log(p), axis=1))
# 反向传播
# 第四层
G4 = (p - batch_labels) / batch_images.shape[0] # 第四层误差
dw4 = np.dot(H3.T, G4) # 第四层权重梯度
db4 = np.mean(G4, axis=0, keepdims=True) # 第四层偏置梯度
# 第三层
G3 = np.dot(G4, w4.T) # 第三层误差
dw3 = np.dot(H2.T, G3) # 第三层权重梯度
db3 = np.mean(G3, axis=0, keepdims=True) # 第三层偏置梯度
# 第二层
G2 = np.dot(G3, w3.T) # 第二层误差
# 第一层
G1 = G2 * (H2 * (1 - H2)) # 第一层误差
dw1 = np.dot(batch_images.T, G1) # 第一层权重梯度
db1 = np.mean(G1, axis=0, keepdims=True) # 第一层偏置梯度
# 更新权重和偏置
w1 -= lr * dw1
b1 -= lr * db1
w3 -= lr * dw3
b3 -= lr * db3
w4 -= lr * dw4
b4 -= lr * db4
# 验证集验证并输出预测准确率
right_num = 0
for bictc_images, bictc_labels in dev_dataloader:
H1 = np.dot(bictc_images, w1) + b1 # 第一层输出
H2 = sigmoid(H1) # 第二层输出,使用sigmoid激活函数
H3 = np.dot(H2, w3) + b3 # 第三层输出
H4 = np.dot(H3, w4) + b4 # 第四层输出
p = softmax(H4) # 输出层输出,使用softmax激活函数
pre_idx = np.argmax(p, axis=-1) # 预测类别
right_num += np.sum(pre_idx == bictc_labels) # 统计正确个数
acc = right_num / len(dev_images) # 计算准确率
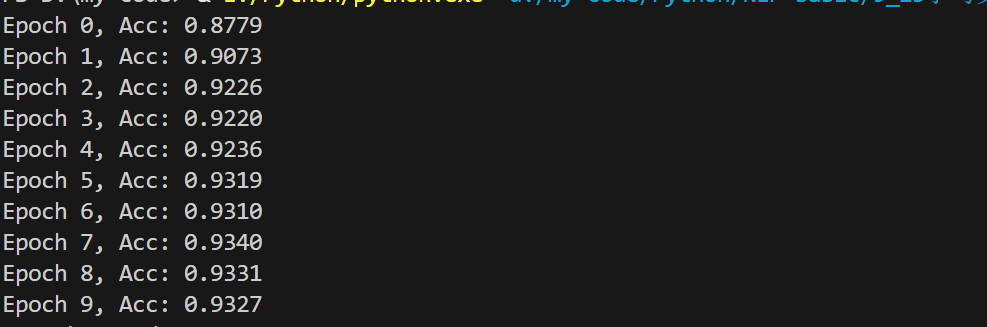
print(f"Epoch {e + 1}, Acc: {acc:.4f}")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号