第三章 训练初步深入
train2
我国科学家在脑图谱研究领域取得新突破 民生
活力中国调研行|好用好玩!科技I点亮百姓生活 财经
为何动物伪装不完美也能吓退天敌? 科技
重庆黔江被确认为白垩纪恐龙化石集群埋藏地 科技
研究发现运动抗衰老的关键因子 科技
智能设备织密暑期“安全网” 科技
我国首个海水漂浮式光伏项目建成投用 科技
“肉食塑造人类”假说有了新证据 财经
欧航局:太阳系或迎来第三位“星际访客” 民生
智能设备织密暑期“安全网cccccccccccccccc” 财经
世界首台5财经财经兆瓦冲击式机组转轮研制成功 水电机有了“大心脏” 娱乐
雷神科技举办信创旗舰新品发布会,共擎信创国产化未来 娱乐
代码
import os
import math
import random
def read_file(filepath):
with open(filepath, 'r', encoding='utf-8') as f:
all_lines= f.read().split("\n")
# print(all_lines)
all_text=[]
all_label=[]
for line in all_lines:
# print(line)
data_s=line.split()
if len(data_s ) !=2:
continue
else:
text, label = data_s
all_label.append(label)
all_text.append(text)
assert len(all_text)==len(all_label), "text and label length not equal"
return all_text,all_label
# Dataset 是所有数据集的集合,DataLoader 是每次返回一个batch的迭代器
class Dataset:
def __init__(self, all_text, all_label,batch_size):
self.all_text = all_text
self.all_label = all_label
self.batch_size=batch_size
def __iter__(self):
dataloader=DataLoader(self)
return dataloader
class DataLoader:
def __init__(self,dataset):
self.dataset=dataset
self.cursor=0
def __next__(self):
if self.cursor>=len(self.dataset.all_text):
raise StopIteration
text=self.dataset.all_text[self.cursor:self.cursor+self.dataset.batch_size]
label=self.dataset.all_label[self.cursor:self.cursor+self.dataset.batch_size]
self.cursor+= self.dataset.batch_size
return text,label
def build_word_dict(all_text):
word_dict={}
for text in all_text:
for word in text:
if word not in word_dict:
word_dict[word]=len(word_dict)
return word_dict
if __name__ == '__main__':
filepath = os.path.join("D:/", "my code", "Python", "NLP basic", "data", "train2.txt")
all_text, all_label = read_file(filepath)
# print(all_text)
# print(all_label)
epoch=3
bitch_size=6
word_dict = build_word_dict(all_text)
print(word_dict)
train_dataset = Dataset(all_text, all_label, bitch_size)
for e in range(epoch):
print("Epoch:",e,"/",epoch)
for data in train_dataset:
print(data)
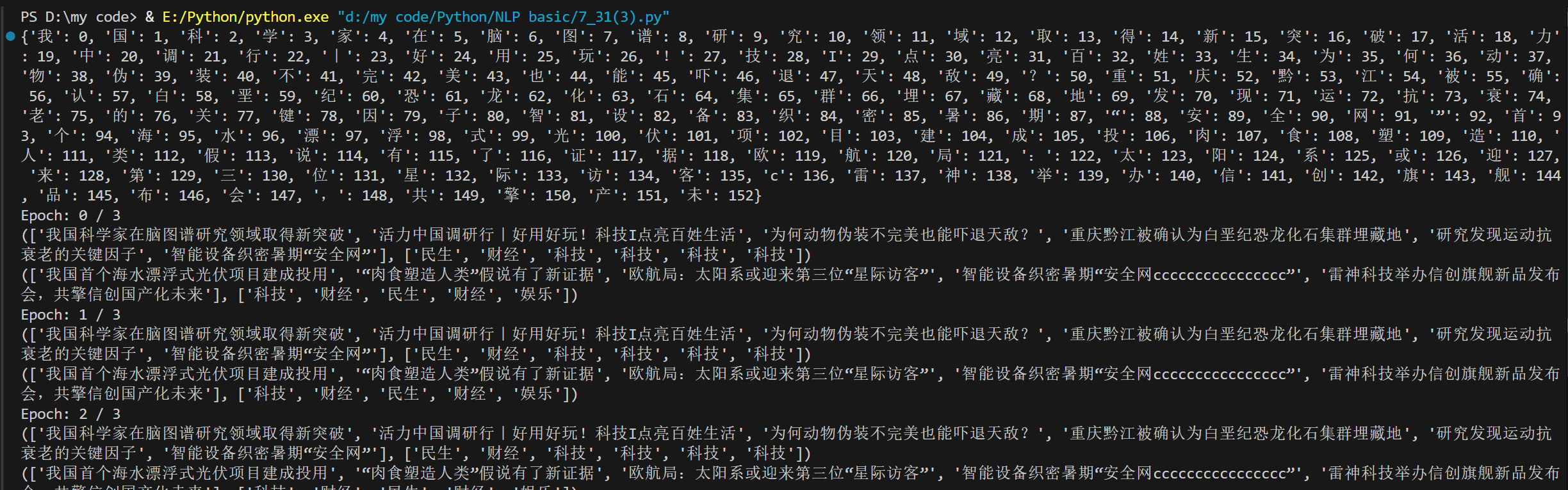
运行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号