
13-分布式事务应用
一、分布式事务的实现策略和模式
(一)分布式事务理论模型
1、分布式事务理论模型
(1)强XA和弱XA
强XA就是要求任何一次读都能读到某个数据的最近一次写的数据。系统中的所有进程,看到的操作顺序,都和全局时钟下的顺序一致。简言之,在任意时刻,所有节点中的数据是一样的。
弱XA是数据更新后,如果能容忍后续的访问只能访问到部分或者全部访问不到,则是弱一致性。
(2)CAP
CA:放弃分区容错性,加强一致性和可用性,其实就是传统的单机数据库的选择
AP:放弃一致性(这里说的一致性是强一致性),追求分区容错性和可用性,这是很多分布式系统设计时的选择,例如很多NoSQL系统就是如此
CP:放弃可用性,追求一致性和分区容错性,基本不会选择,网络问题会直接让整个系统不可用
在分布式环境下,项目只能保证CP或AP,AP虽然保证了可用性,但是却损失了一致性,CP虽然保证了一致性,却损失了可用性,但是往往我们既要可用又要一致性,那么只能在保证可用性的同时,保证其软一致性,即最终一致性。
(3)柔性事务
不同于 ACID 的刚性事务,在分布式场景下基于 BASE 理论,就出现了柔性事务的概念。要想通过柔性事务来达到最终的一致性,就需要依赖于一些特性,这些特性在具体的方案中不一定都要满足,因为不同的方案要求不一样;但是都不满足的话,是不可能做柔性事务的。
BASE是三个单词的缩写,分别是基本可用:Basically Available;软状态:Soft State;最终一致性:Eventual Consistency
BASE理论是对CAP理论的延伸,核心思想是即使无法做到强一致性,应用可以采用适合的方式达到最终一致性
(4)幂等操作
在编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。幂等函数,或幂等方法,是指可以使用相同参数重复执行,并能获得相同结果的函数。这些函数不会影响系统状态,也不用担心重复执行会对系统造成改变。例如,支付流程中第三方支付系统告知系统中某个订单支付成功,接收该支付回调接口在网络正常的情况下无论操作多少次都应该返回成功。
2、XA事务模式
(1)X/Open分布式事务模型
XA事务模式有两阶段提交和三阶段提交两种方式。
X/Open分布式事务模型:X/Open DTP是X/Open这个组织定义的一套分布式事务的标准,这个标准提出了使用两阶段提交来保证分布式事务的完整性。
X/Open DTP中包含三种角色:
AP:Application,表示应用程序
RM:Resource Manager,表示资源管理器,例如数据库
TM:Transaction Manager,表示事务管理器,一般指事务协调者,负责协调和管理事务,提供AP编程接口或管理RM,可以理解为Spring 中的Transaction Manager。
其大致实现步骤如下:
配置RM,把多个RM注册到TM
AP从TM管理的RM中获取连接,如果RM是数据库,则获取的是JDBC连接
AP向TM发起一个全局事务,生成一个全局的事务ID(XID),XID会通知所有的RM
AP通过从TM中获取的RM连接操作RM完成数据操作。这时,AP在每次操作RM时都会将XID传递给RM
AP结束全局事务,TM通知各个RM结束全局事务。
根据RM执行的结果,执行提交或者回滚操作
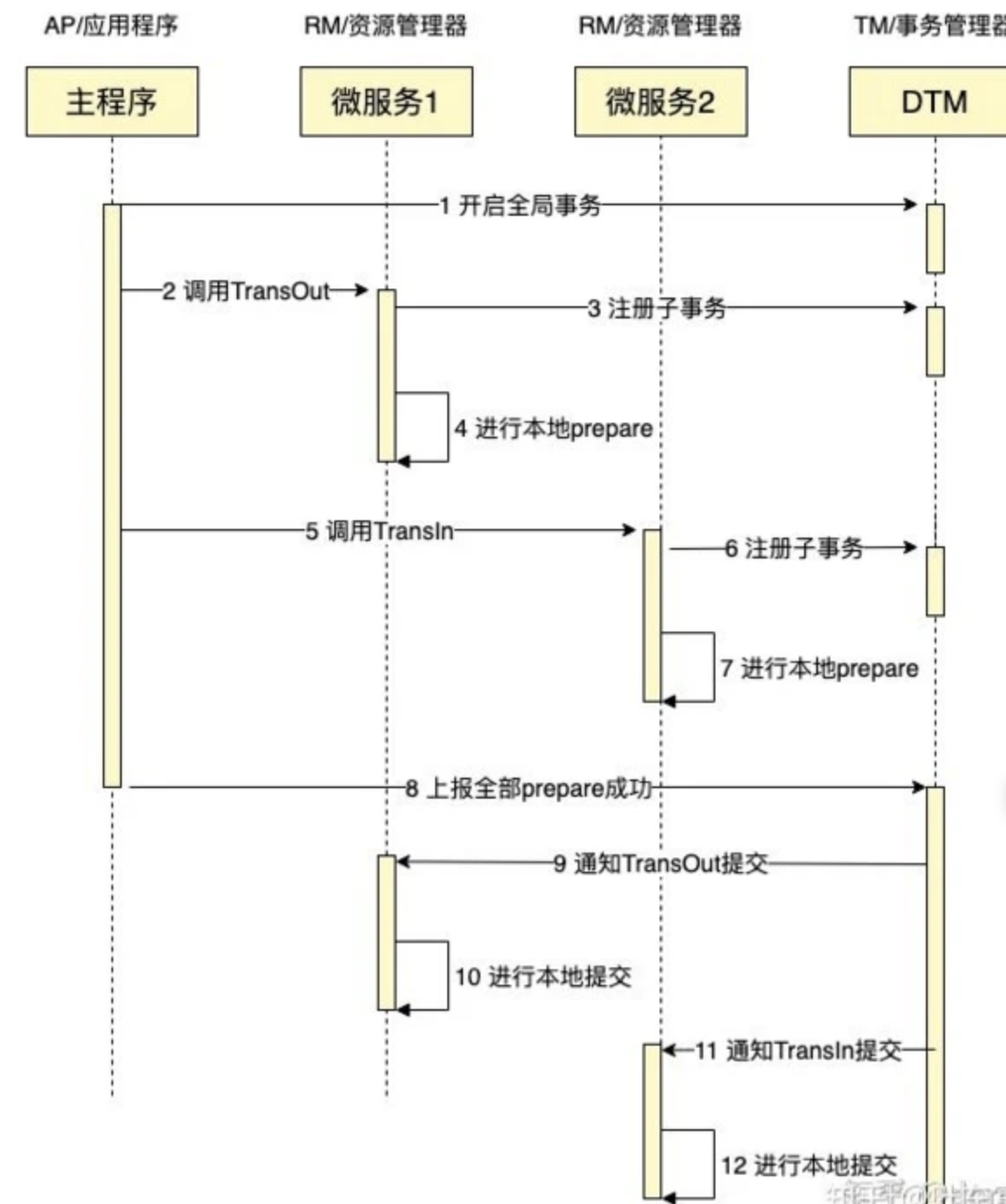
(2)两阶段提交
可以看到,上述模式就是两阶段提交,分为事务的准备和事务的提交/回滚这两个阶段,这两个阶段都是由TM发起的,两个阶段的流程大致如下:
事务准备阶段:事务管理器通知资源管理器准备分支事务,记录事务日志,并告知事务管理器准备结果。
事务提交/回滚阶段:如果所有的资源管理器都在事务准备阶段返回成功,则事务管理器向所有的资源管理器发送事务处理指令;反之,如果有资源管理器在事务准备阶段返回失败,则事务管理器向所有的资源管理器发送事务回滚指令。
两阶段提交的优缺点:
两阶段提交将一个事务的处理分为投票和处理两个阶段,他的优点在于充分的考虑了分布式系统的不可靠因素,并使用了非常简单的方式(两阶段提交)就把由于系统不稳定而导致事务提交失败的概率降到了最小。
当然其缺点也非常的明显,其存在同步阻塞、过于保守、事务协调者的单点故障、脑裂导致的数据不一致等缺点。
同步阻塞:所有的RM执行事务都是阻塞的,对于任何一次指令都必须要有明确的响应才能进行下一步操作,否则将处于阻塞状态,其占用的资源也一直被锁定。
过于保守:任何一个节点失败都会导致整个分布式事务回滚。
事务协调者的单点故障:如果协调者在第二阶段出现了问题,那么所有的参与者都将一直处于锁定状态。
脑裂导致数据不一致问题:由于网络问题,在第二阶段有部分参与者收到了commit指令并提交了事务,但是有一部分参与者没有收到commit指令而导致事务无法提交,最终造成了数据不一致。
(3)三阶段提交
三阶段提交是在两阶段提交的基础上做出的改进,其利用了超时机制解决了同步阻塞的问题:
三阶段提交的描述如下:
CanCommit:询问阶段,事务协调者向参与者发送执行请求,询问是否可以完成指令,参与者只需要回答是不是即可,不需要真正的处理事务,这个阶段会有超时终止机制。
PreCommit:准备阶段,事务协调者会根据参与者的反馈结果决定是否要继续进行,如果在询问阶段所有的参与者都返回了可以进行事务操作,那么事务协调者会向所有的参与者发送PreCommit请求,参与者收到请求后写 redo log 和 undo log ,执行事务操作但不提交事务,然后返回ACK响应,等待事务协调者的下一步指令;如果在询问阶段存在参与者返回不能参与事务,那么事务协调者会通知所有的参与者中断事务。
DoCommit:提交或回滚阶段,这个阶段也会存在两种情况,如果在PreCommit阶段所有的参与者都返回成功,那么事务协调者会向所有的参与者发送事务提交请求;反之,如果在PreCommit阶段存在参与者返回失败,事务协调者则通知所有的参与者回滚事务。
(4)三阶段提交与两阶段提交对比
可以看到,三阶段提交与两阶段提交相比,主要就是增加了一个询问阶段,用于询问所有的参与者是否可以参与事务处理,其好处是可以尽早的发现参与者不能参与事务而中止事务处理。
还有一个大的区别就是三阶段提交引入了超时机制,在询问阶段引入了超时,如果超时则中止后续的操作,在准备阶段后引入超时机制,如果超时,事务协调者和事务参与者会提交事务,并认为处理成功,因为在这种情况下,认为事务成功的概率性比较大。
实际上,一旦超时,在三阶段提交下,仍然会出现数据不一致的情况,虽然其概率比较小,但是三阶段提交主要是解决了资源被永久性锁定的问题。
不管是两阶段提交还是三阶段提交,都是数据一致性的解决方案,我们可以在实际应用中灵活调整,比如Zookeeper集群中的数据一致性,其就用到了优化版的两阶段提交,优化的点在于其不需要所有参与者在第一阶段返回成功才能提交事务,而是利用少数服从多数的投票机制来完成数据的提交或回滚。
(二)分布式事务补偿类实现模式
1、补偿模式
补偿模式的基本思路在于使用一个额外的补偿服务来协调各个需要保证一致性的服务,补偿服务按顺序依次调用各个服务,如果某个服务调用失败就撤销之前所有已经完成的服务。在这个过程中,补偿服务对需要保证一致性的微服务提供补偿操作。
补偿范围:对于补偿服务而言,记录所有微服务的操作记录和日志是一个关键点,这些记录和日志有助于确定失败的步骤和状态,从而明确需要补偿的范围。
补偿数据:在明确补偿的范围之后,我们就需要获取所需补偿的业务数据。例如就库存服务而言,补偿操作要求的业务数据包括业务流水号、订单信息和库存数据等。理论上说可根据唯一的业务流水号即可完成补偿操作,但是提供更多的数据有益于微服务的健壮性。服务在收到补偿操作的时候可以做业务的检查,比如检查账户是否相等,库存是否一致等因素。
2、补偿模式类型
补偿模式类型有 AT、TCC、Saga。
为了降低开发的复杂性和提高效率,补偿服务通常实现为一个通用的补偿框架。补偿框架提供服务编排和自动完成补偿的能力。
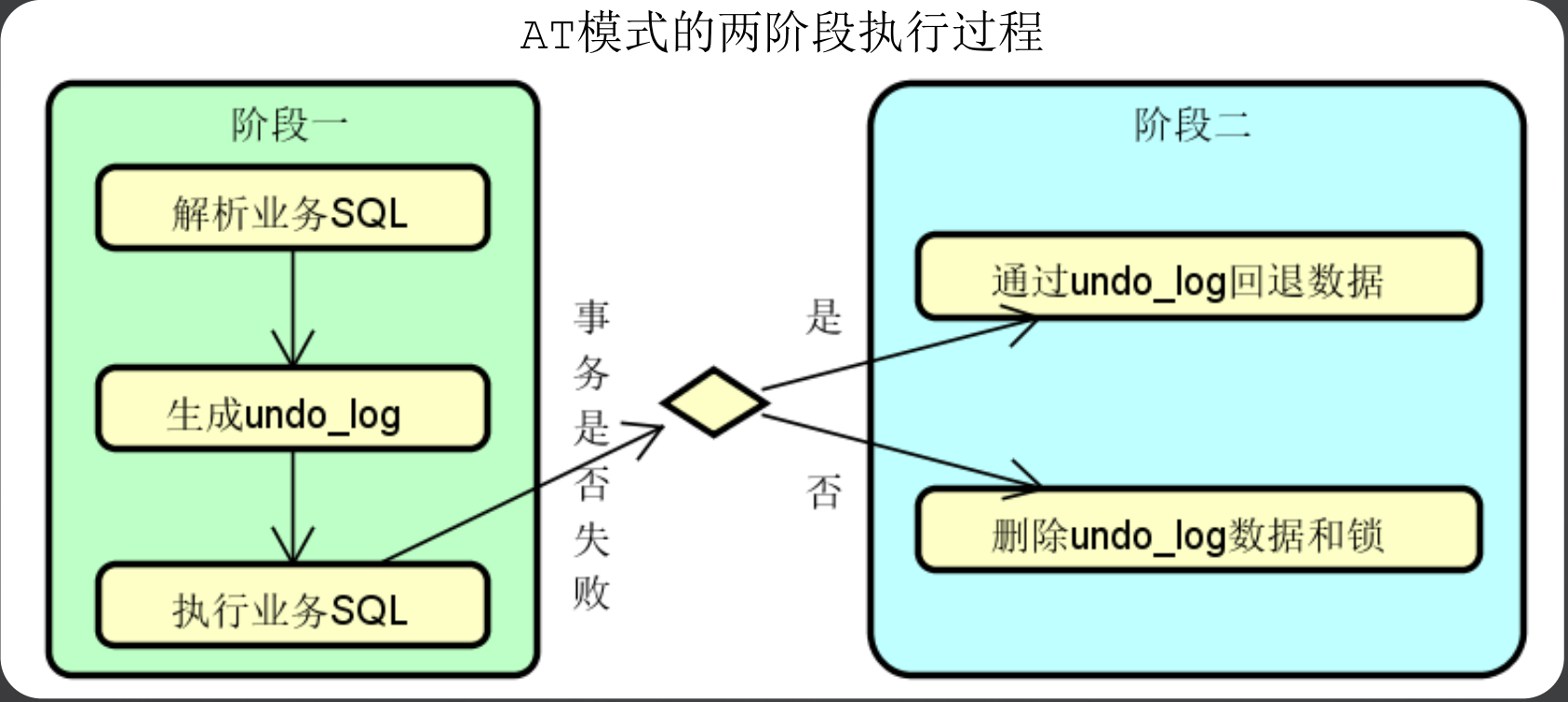
(1)AT模式
AT模式也是基于两阶段提交实现的补偿模式,在AT模式中,主要流程是补偿需要解析业务sql,然后生成需要回滚的 undo_log,织染后行业务sql,如果事务执行成功,则删除undo_log即可,如果执行失败,则通过undo_log回退数据。
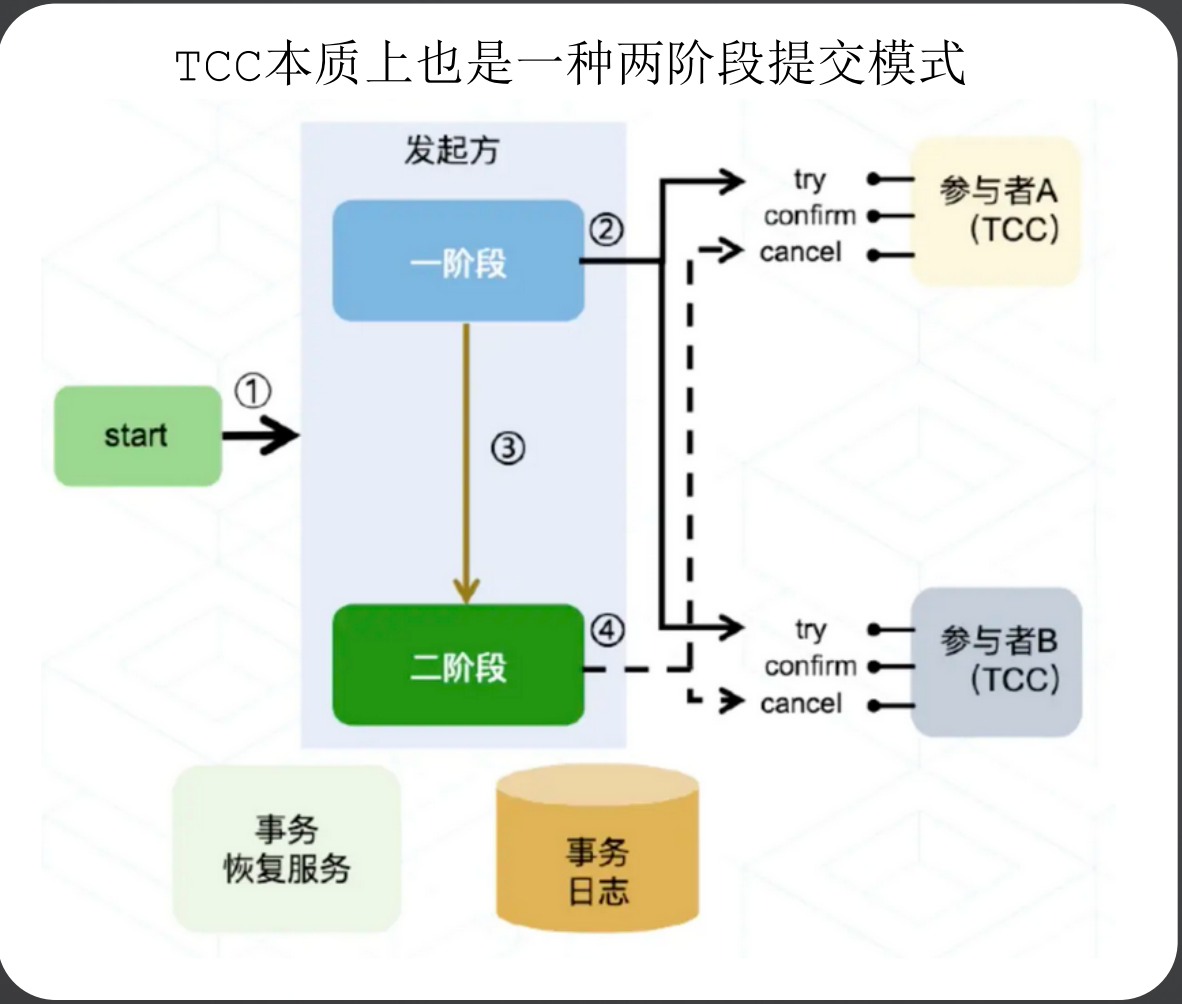
(2)TCC模式
TCC解决方案是一种两阶段提交的思想,第一阶段通过Try进行准备工作,第二阶段Confirm/Cancel表示Try阶段的确认或回滚。在分布式场景中,每个服务实现TCC之后,就作为其中的一个资源参与到整个分布式事务中,然后主业务服务在第一阶段中分别调用所有TCC服务的Try方法,然后根据第一阶段Try的执行结果进行Confirm或者Cancel。
TCC分为3个阶段
Try 阶段:尝试执行,完成所有业务检查(一致性), 预留必须业务资源(准隔离性)
Confirm 阶段:确认执行真正执行业务,不作任何业务检查,只使用 Try 阶段预留的业务资源,Confirm 操作要求具备幂等设计,Confirm 失败后需要进行重试。
Cancel 阶段:取消执行,释放 Try 阶段预留的业务资源。Cancel 阶段的异常和 Confirm 阶段异常处理方案基本上一致,要求满足幂等设计。
(3)Saga模式
Saga是将长事务拆分成短事务的操作,所有的短事务都对应的有补偿事务,除了最后一个事务之外,所有的事务都对应的有下一个事务,事务和下一个事务或者与补偿事务之间的处理,可以使用事件和命令进行处理。

(三)分布式事务其他类型实现模式
除了上述的补偿类实现模式外,还有一些其他的实现模式,例如基于消息通信可靠性的可靠事件模式, 通知类实现模式的最大努力通知模式,以及兜底方案的人工干预模式等。
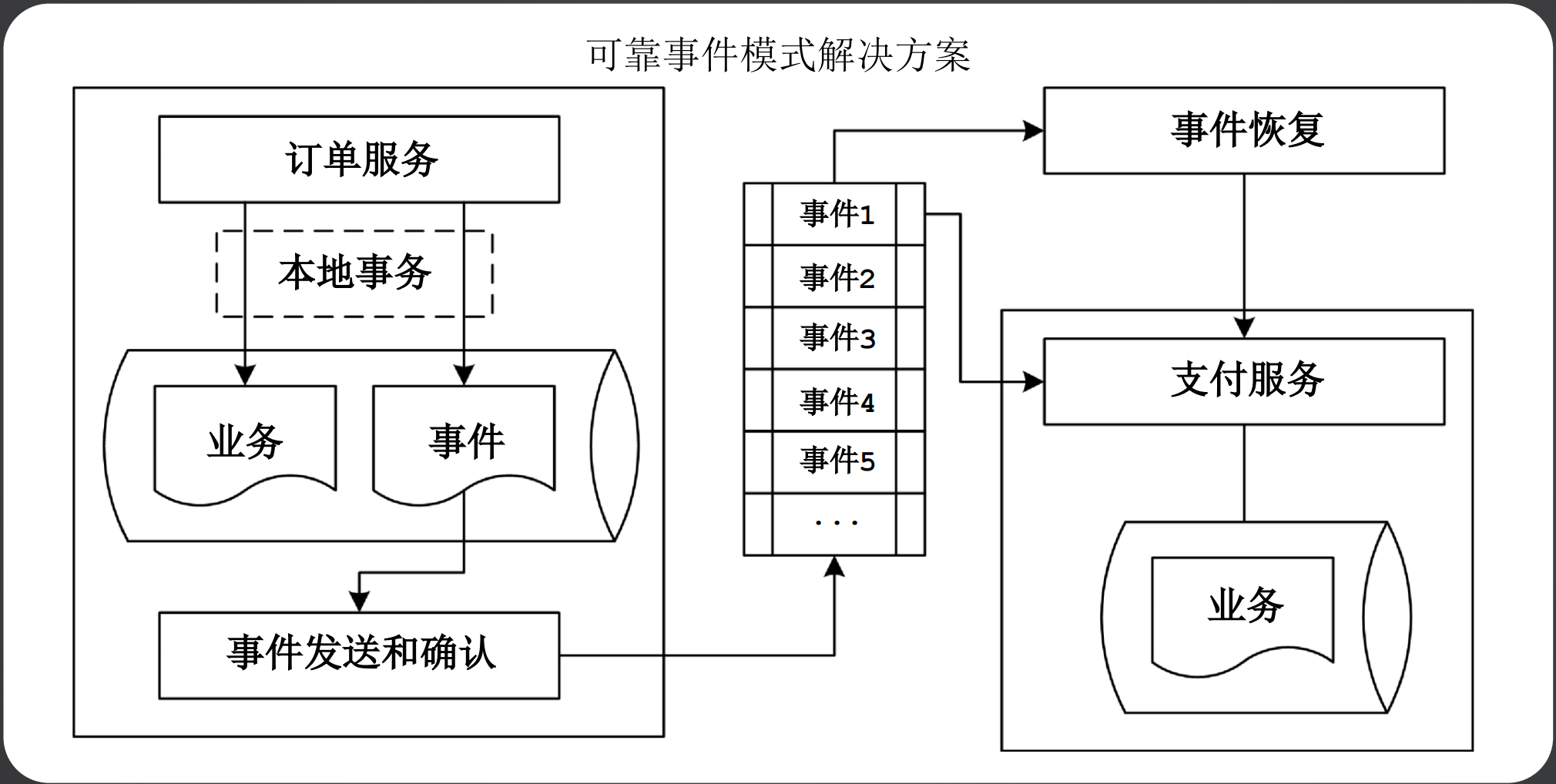
1、可靠事件模式
可靠时间模式是使用了可靠的消息通信,例如RocketMQ的事务消息,在发起方,其保证了消息发送和本地事务的同时成功和同时失败。
2、最大努力通知模式
最大努力通知型其实和基于可靠性消息的最终一致性方案非常的相似,其是一种比较简单的柔性事务解决方案,其比较适合对数据一致性要求不高的场景,最典型的就是支付宝的支付结果通知,其流程如下所示:
商户先创建一个支付订单,然后调用支付宝发起支付请求
支付宝唤起支付页面完成支付操作,支付宝同样会为商户创建一个支付交易,并且根据用户的支付结果记录支付状态
支付完成后回调通知给商户,商户收到该通知后,根据结果修改本地支付订单的状态,并且返回一个处理状态给支付宝
针对这个订单,在理想状态下,支付宝的订单状态和商户的订单状态会达到最终一致,但是由于网络等问题,支付结果通知可能会失败或者丢失,导致商户的订单状态是未知的,此时最大努力通知机制就体现出来价值了,其通过衰减重试的方式进行回调,如果到达重试最大次数后还没有收到商户订单返回成功,就不再重试
与此同时,支付宝订单还提供了一个交易结果回查接口,可以根据订单号到支付宝查询支付状态,然后商户订单方可以使用定时查询或者人工手动查询的方式处理,然后更新状态。
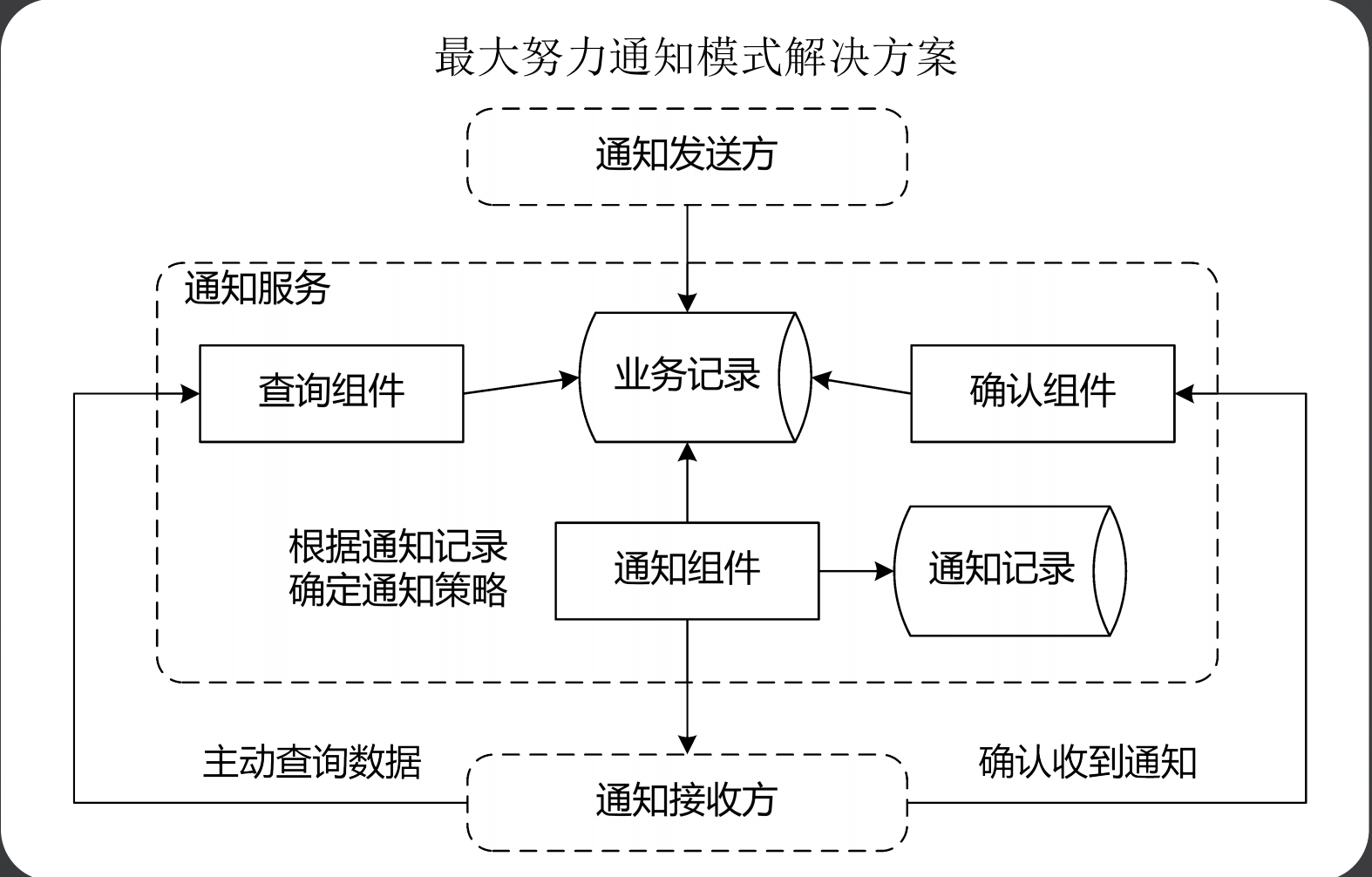
3、本地消息表
本地消息表这个方案最初是 ebay 架构师 Dan Pritchett 在 2008 年发表给 ACM 的文章。该方案中会有消息生产者与消费者两个角色,假设系统 A 是消息生产者,系统 B 是消息消费者,其大致流程如下:
当系统 A 被其他系统调用发生数据库表更操作,首先会更新数据库的业务表,其次会往相同数据库的消息表中插入一条数据,两个操作发生在同一个事务中。
系统 A 的脚本定期轮询本地消息往 mq 中写入一条消息,如果消息发送失败会进行重试
系统 B 消费 mq 中的消息,并处理业务逻辑。如果本地事务处理失败,会在继续消费 mq 中的消息进行重试,如果业务上的失败,可以通知系统 A 进行回滚操作。
本地消息表实现的条件:
消费者与生成者的接口都要支持幂等
生产者需要额外的创建消息表
需要提供补偿逻辑,如果消费者业务失败,需要生产者支持回滚操作
容错机制:
步骤 1 失败时,事务直接回滚
步骤 2、3 写 mq 与消费 mq 失败会进行重试
步骤 3 业务失败系统 B 向系统 A 发起事务回滚操作
此方案的核心是将需要分布式处理的任务通过消息日志的方式来异步执行。消息日志可以存储到本地文本、数据库或消息队列,再通过业务规则自动或人工发起重试。人工重试更多的是应用于支付场景,通过对账系统对事后问题的处理。
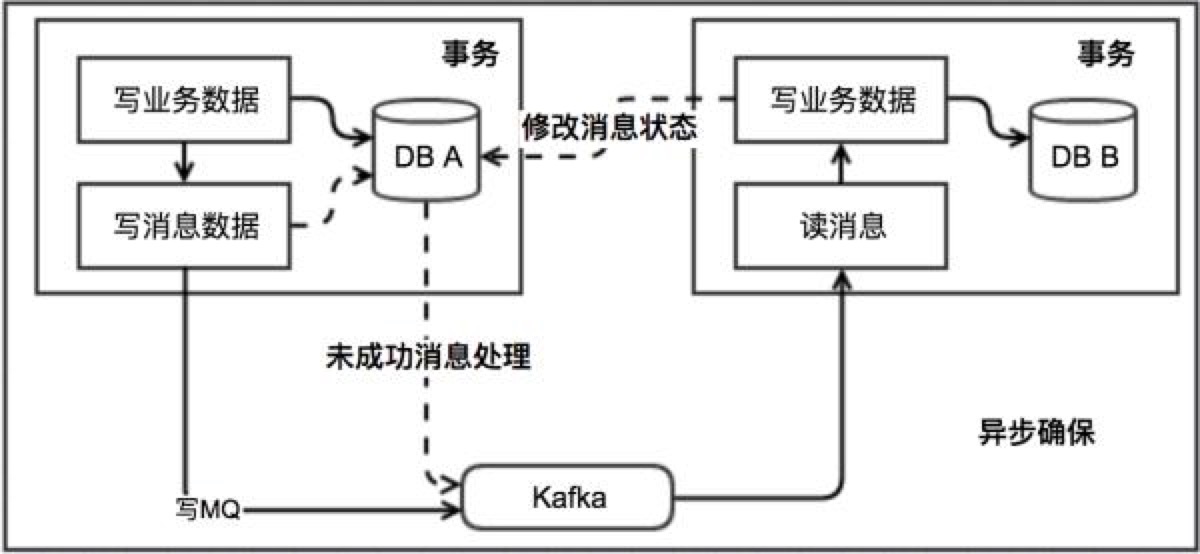
4、人工干预模式
人工干预模式比较简单,通过一个后台管理系统,可以通过人工审核的方式,重新点击发起处理。

二、Seata分布式事务框架Seata
(一)Seata框架简介
Seata是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata为用户提供了AT、TCC、SAGA和XA事务模式,为用户打造一站式的分布式解决方案。
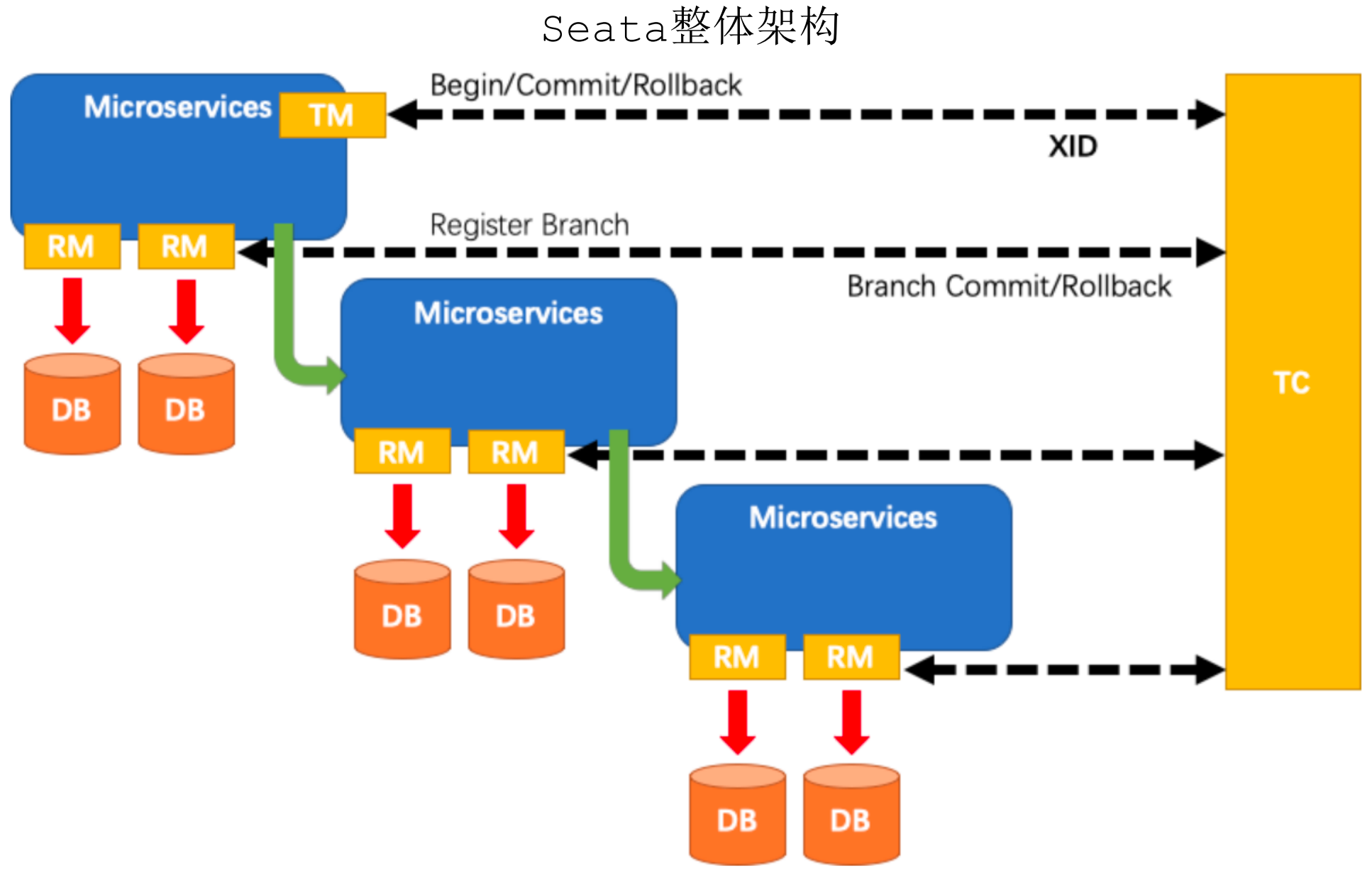
1、Seata框架总体架构
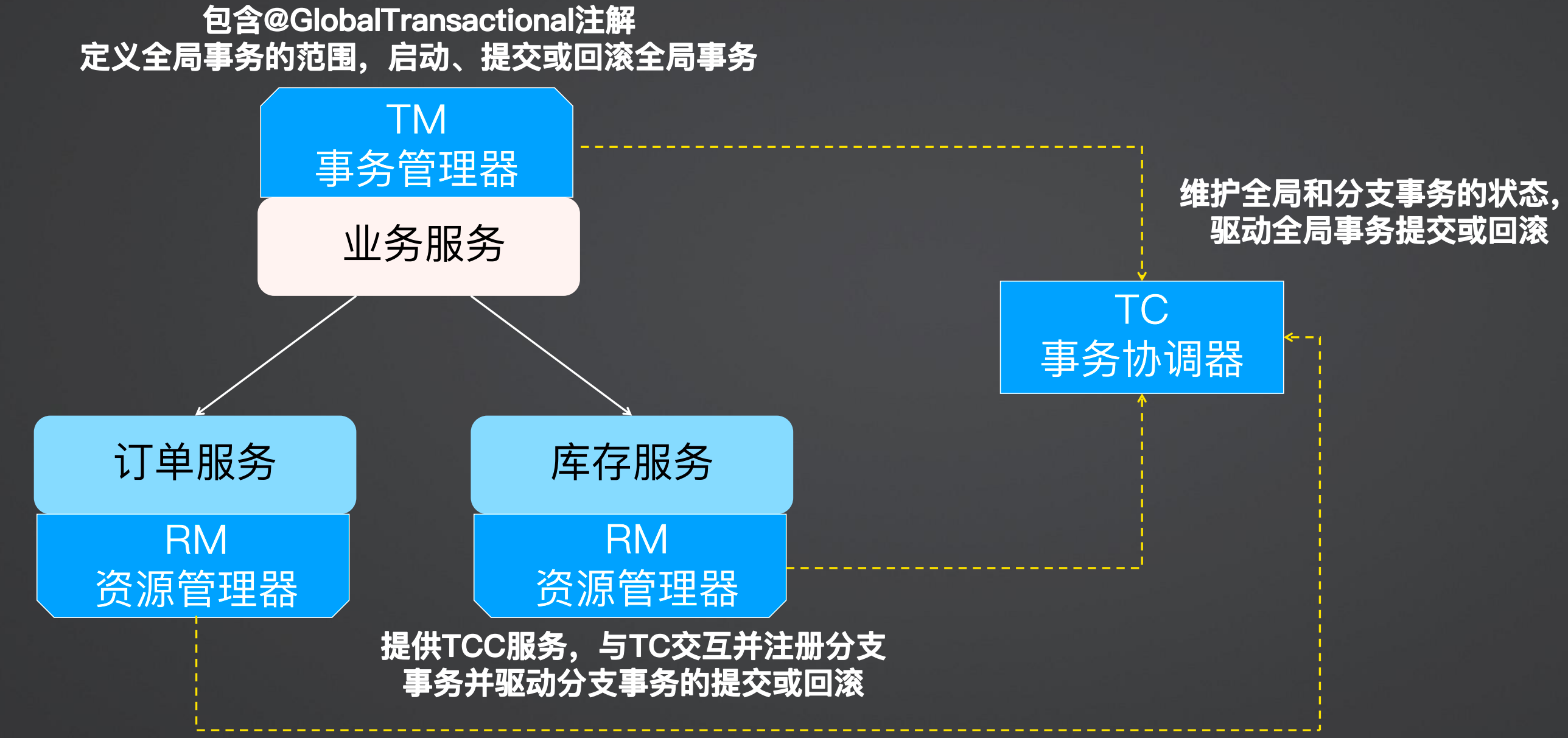
Seata角色分为TC(事务协调器)、TM(事务管理器)、RM(资源管理器)
TM(事务管理器):Transaction Manager,全局事务的管理者,或者说是全局事务的发起方
RM(资源管理器):Resources Manager,负责分支(本地)事务注册、提交和回滚
TC(事务协调器):Transaction Coordinate,全局事务的协调者,也就是Seata中间件,TM/RM启动的时候要向TC注册
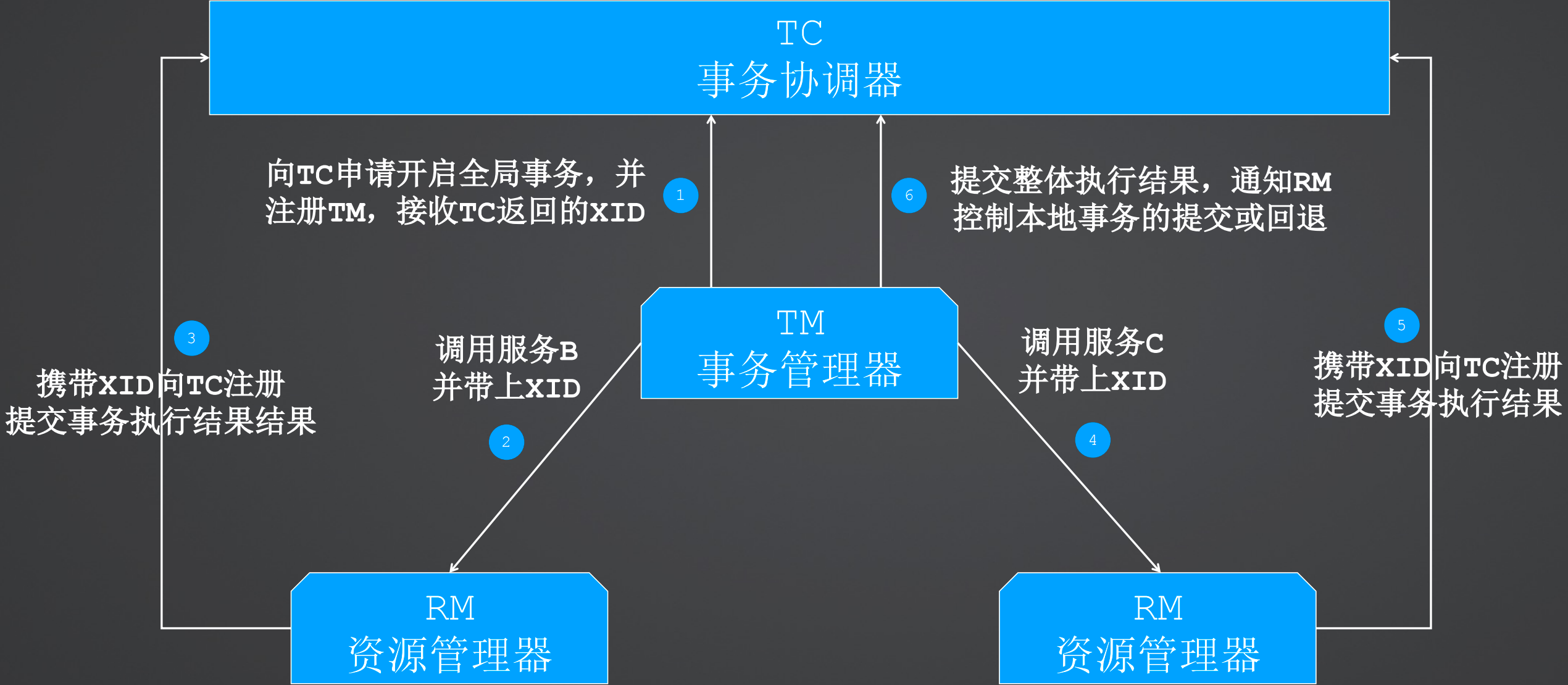
2、Seata逻辑角色交互
首先事务管理器TM向事务协调器TC申请开启全局事务,并注册TM,接收TC返回的全局事务ID(XID)
事务管理器TM调用资源管理器RM,即调用其他微服务
资源管理器携带全局事务ID(XID)向事务协调器(TC)注册提交事务执行结果
最终事务管理器TM向事务协调器TC提交整体执行结果,并通知资源管理器RM控制本地事务的提交或回退。
3、Seata部署架构
Seata本身也是一个微服务,因此有多种部署方式,例如下图是使用注册中心和配置中心的部署方式,同时Seata还有数据要存储,可以根据自身情况选择存储方式。
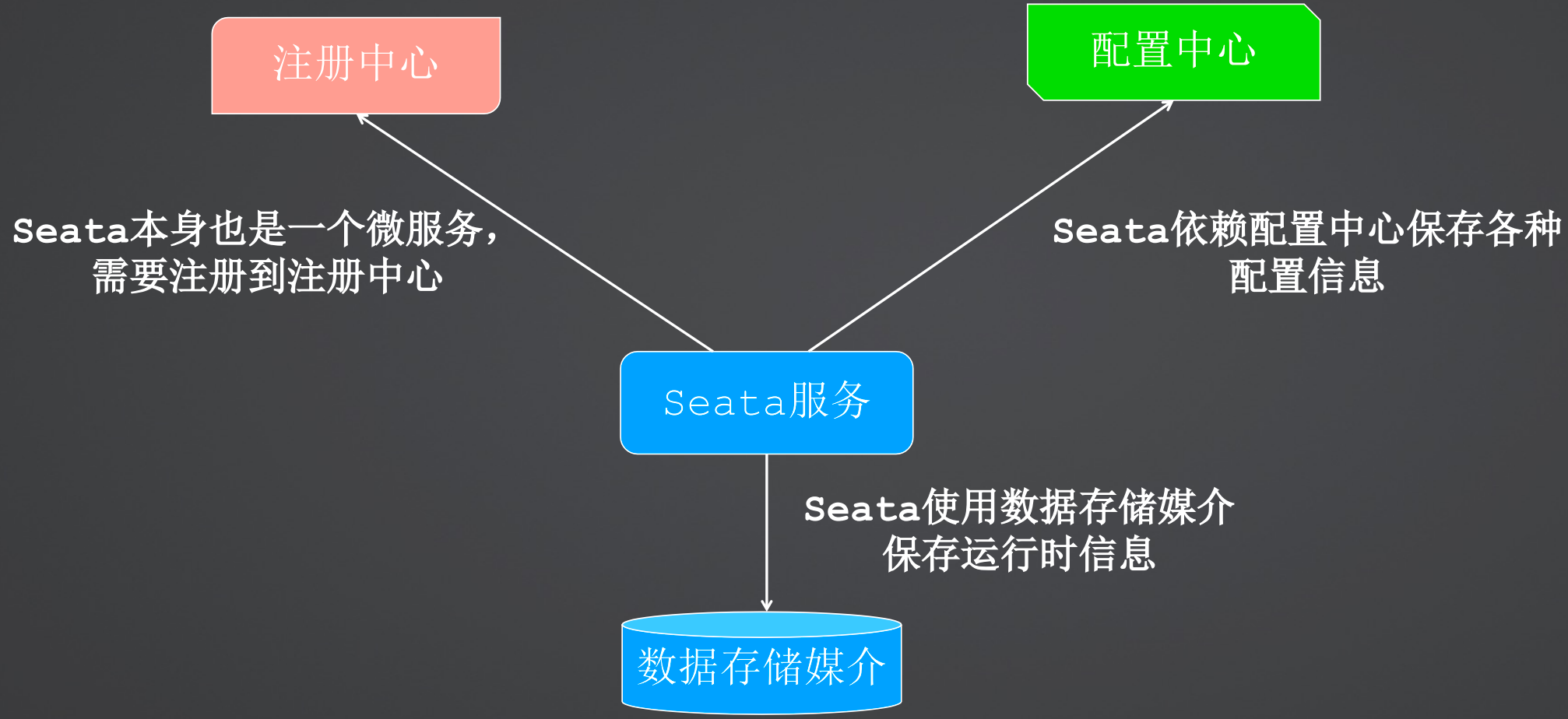
Seata本身也是一个微服务,因此也是使用yaml文件进行的配置,配置中包括端口号、服务名称、支持的配置中心、注册中心、存储类型。
server:
port: 7091 # Seata服务端口
spring:
application:
name: seata-server # Seata服务名称
seata:
config:
# Seata支持的配置中心: nacos, consul, apollo, zk, etcd3
type: nacos
registry:
# Seata支持的注册中心: nacos, eureka, redis, zk, consul, etcd3, sofa
type: nacos
store:
# Seata支持的数据存储媒介: file, db, redis
mode: file
4、Seata客户端集成
客户端集成就是一系列使用seata开头的配置,例如服务id、自定义事务分组、seata服务集群名称、注册中心、配置中心等
seata:
application-id: ${spring.application.name}
# 自定义事务分组
tx-service-group: business-service-group
service:
vgroupMapping:
# Seata服务集群名
business-service-group: default
# Seata服务注册中心
registry:
type: nacos
nacos.:
server-addr: localhost:8848
application: seata-server
group: SEATA_GROUP
# Seata服务配置中心
config:
type: nacos
nacos.:
server-addr: localhost:8848
group: SEATA_GROUP
(二)Seata安装
1、直接启动
(1)下载
下载压缩包https://github.com/seata/seata/releases,解压。
这里以 1.5.2 版本为例。
(2)建表
script/server/db目录下有建表sql
(3) 改配置
修改config/application.yml
这里主要配置seata的服务信息以及配置中心和注册中心,其中配置中心支持nacos, consul, apollo, zk, etcd3,注册中心主持nacos, eureka, redis, zk, consul, etcd3, sofa。
以nacos作为配置中心和注册中心为例,主要也是配置server-addr、namespace、group、cluster等信息
server:
port: 7091
spring:
application:
name: seata-server
logging:
config: classpath:logback-spring.xml
file:
path: ${user.home}/logs/seata
extend:
logstash-appender:
destination: 127.0.0.1:4560
kafka-appender:
bootstrap-servers: 127.0.0.1:9092
topic: logback_to_logstash
# seata 控制台账号密码
console:
user:
username: seata
password: seata
seata:
config:
# support: nacos, consul, apollo, zk, etcd3
type: nacos
nacos:
server-addr: 192.168.249.130:8848
namespace: dae2f8c4-a44a-4143-afc5-1f8aaa84c72c
group: SEATA_GROUP
cluster: beijing
username:
password:
##if use MSE Nacos with auth, mutex with username/password attribute
#access-key: ""
#secret-key: ""
data-id: seata-server.yml
registry:
# support: nacos, eureka, redis, zk, consul, etcd3, sofa
type: nacos
nacos:
application: seata-server
server-addr: 192.168.249.130:8848
group: SEATA_GROUP
namespace: dae2f8c4-a44a-4143-afc5-1f8aaa84c72c
cluster: beijing
username:
password:
##if use MSE Nacos with auth, mutex with username/password attribute
#access-key: ""
#secret-key: ""
store:
# support: file 、 db 、 redis
mode: db
# server:
# service-port: 8091 #If not configured, the default is '${server.port} + 1000'
security:
secretKey: SeataSecretKey0c382ef121d778043159209298fd40bf3850a017
tokenValidityInMilliseconds: 1800000
ignore:
urls: /,/**/*.css,/**/*.js,/**/*.html,/**/*.map,/**/*.svg,/**/*.png,/**/*.ico,/console-fe/public/**,/api/v1/auth/login
(4)添加nacos配置
在nacos配置中心添加配置文件,对应的相关信息就是上面配置的data-id、server-addr、namespace、group、cluster等信息,在该配置文件中,主要配置服务器信息、存储信息、监控信息以及和事务相关的信息。
seata:
server:
service-port: 8091 #If not configured, the default is '${server.port} + 1000'
max-commit-retry-timeout: -1
max-rollback-retry-timeout: -1
rollback-retry-timeout-unlock-enable: false
enable-check-auth: true
enable-parallel-request-handle: true
retry-dead-threshold: 130000
xaer-nota-retry-timeout: 60000
recovery:
handle-all-session-period: 1000
undo:
log-save-days: 7
log-delete-period: 86400000
session:
branch-async-queue-size: 5000 #branch async remove queue size
enable-branch-async-remove: false #enable to asynchronous remove branchSession
store:
# support: file 、 db 、 redis
mode: db
session:
mode: db
lock:
mode: db
db:
datasource: druid
db-type: mysql
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/seata?rewriteBatchedStatements=true
user: mysql
password: mysql
min-conn: 5
max-conn: 100
global-table: global_table
branch-table: branch_table
lock-table: lock_table
distributed-lock-table: distributed_lock
query-limit: 100
max-wait: 5000
redis:
mode: single
database: 0
min-conn: 1
max-conn: 10
password:
max-total: 100
query-limit: 100
single:
host: 127.0.0.1
port: 6379
sentinel:
master-name:
sentinel-hosts:
metrics:
enabled: false
registry-type: compact
exporter-list: prometheus
exporter-prometheus-port: 9898
transport:
rpc-tc-request-timeout: 30000
enable-tc-server-batch-send-response: false
shutdown:
wait: 3
thread-factory:
boss-thread-prefix: NettyBoss
worker-thread-prefix: NettyServerNIOWorker
boss-thread-size: 1
(5)启动
sh bin/seata-server.sh
(6)登录控制台
http://localhost:7091/#/login
(三)客户端集成
无论使用哪种模式,主要的配置项都是一样的,只是部分有差异。
1、引入依赖
首先要引入seata依赖,同时由于案例使用了注册中心和配置中心,因此也要引入注册中心和配置中心的依赖
<!-- seata-->
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>1.5.2</version>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<exclusions>
<exclusion>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
2、配置文件
对于每一个微服务而言,引入了seata之后,都要向seata注册,即作为TM也作为RM进行注册,跟注册相关的配置就是以seata开头的配置,其他的都是微服务正常的配置。
对于seata相关的配置,主要配置seata中的服务名称、事务组名、事务集群映射,以及seata服务端的注册中心和配置中心,可以让客户端直接与seata交互。
server:
port: 9000
spring:
application:
name: business-service
cloud:
nacos:
discovery:
server-addr: 192.168.249.130:8848
namespace: dae2f8c4-a44a-4143-afc5-1f8aaa84c72c
group: LCL_GALAXY_GROUP
config:
server-addr: 192.168.249.130:8848
seata:
application-id: ${spring.application.name}
tx-service-group: business-service-group
service:
vgroup-mapping:
business-service-group: beijing
registry:
type: nacos
nacos:
server-addr: 192.168.249.130:8848
application: seata-server
group: SEATA_GROUP
namespace: dae2f8c4-a44a-4143-afc5-1f8aaa84c72c
config:
type: nacos
nacos:
server-addr: 192.168.249.130:8848
group: SEATA_GROUP
namespace: dae2f8c4-a44a-4143-afc5-1f8aaa84c72c
3、创建事务集群
在配置中心创建一个service.vgroupMapping.${seata.tx-service-group}的文件,并设置值为 ${seata.service.vgroup-mapping.business-service-group}的值。
4、每个微服务的不同点
对于上述配置来说,都是每个微服务在集成seata时必须的配置型,其中 seata.tx-service-group 是需要单独配置的,要配置一个不会重复的名称,最好与业务或者服务名称贴近的。
对于在配置中心创建的事务集群配置service.vgroupMapping.${seata.tx-service-group},从写法上就可以看出,配置文件名称是根据seata.tx-service-group来设置的。
三、基于Seata实现AT业务无侵入式事务
(一)AT模式实现方式
AT(Auto Transaction)是一种自动型的分布式事务解决方案。这种自动型体现在它无需代码入侵,也就是说我们不需要再编写多余的代码来实现这个模式,只需要在方法中添加上指定的注解即可。
AT模式是Seata最常见的使用方式是在全局的事务处加上@GlobalTransactional注解即可。
@Service
public class BusinessService {
@GlobalTransactional
public void submitOrder(...) {
//下订单
orderService.createOrder(...);
//扣库存
inventoryService.reduceInventory(...);
}
}
1、AT模式的两阶段流程
undo_log、一阶段、二阶段的提交都是由Seata自动完成的,并不需要开发人员写代码来实现,体现了它的无代码入侵性。
在AT模式下,TM和RM都会向TC进行注册。
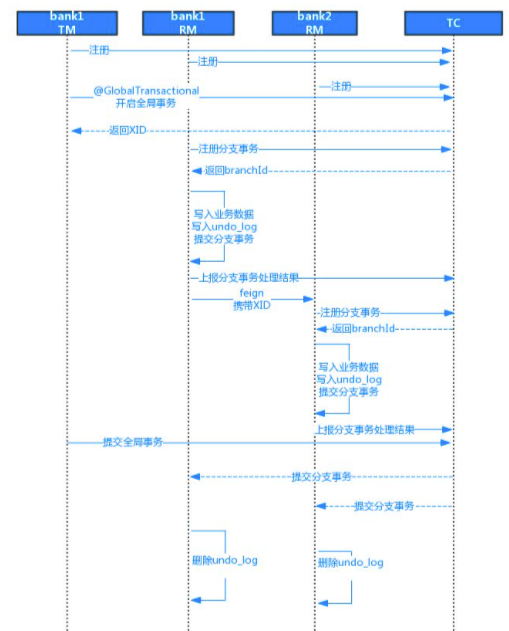
AT 模式的两阶段流程如下:
第一阶段(准备阶段):
(1)TM使用全局事务注解开启一个全局事务,然后向TC获取一个全局事务ID(XID)
(2)分支事务处理时,RM携带XID向TC注册分支事务,然后TC返回一个分支事务ID(branchID)
(3)分支事务解析业务处理的sql,将回滚数据写入undo_log,然后向TC上报分支事务处理结果
第二阶段(提交/回滚阶段):
(1)全局事务提交:如果所有参与者都成功地完成了业务逻辑的执行,并且没有出现异常,分布式事务的发起方会向 Seata 事务协调器发送提交请求。
(2)分支事务提交:Seata 事务协调器会通知各个参与者提交分支事务,每个参与者根据之前记录的操作日志,执行相应的数据库提交操作。
(3)全局事务回滚:如果在业务逻辑执行期间发生异常,分布式事务的发起方会向 Seata 事务协调器发送回滚请求。
(4)分支事务回滚:Seata 事务协调器会通知各个参与者回滚分支事务,每个参与者根据之前记录的操作日志,执行相应的数据库回滚操作。
AT模式的undo_log表:
CREATE TABLE `undo_log` (
`branch_id` bigint(20) NOT NULL COMMENT '分支事务ID',
`xid` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '全局事务ID',
`context` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '上下文',
`rollback_info` longblob NOT NULL COMMENT '回滚信息', --保存上回滚所需的数据
`log_status` int(11) NOT NULL COMMENT '状态,0正常,1全局已完成',
`log_created` datetime(6) NOT NULL COMMENT '创建时间',
`log_modified` datetime(6) NOT NULL COMMENT '修改时间',
UNIQUE INDEX `ux_undo_log`(`xid`, `branch_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8;
2、AT模式锁机制 - 普通行锁
普通行锁会导致没有找到原始的行数据

业务1执行
update table1 value1=30 where value1=20 and name=1;
业务2执行
update table1 value1=25 where name=1;
业务1回滚
找不到value1=20 and name=1的数据
3、AT模式锁机制 - 全局行锁
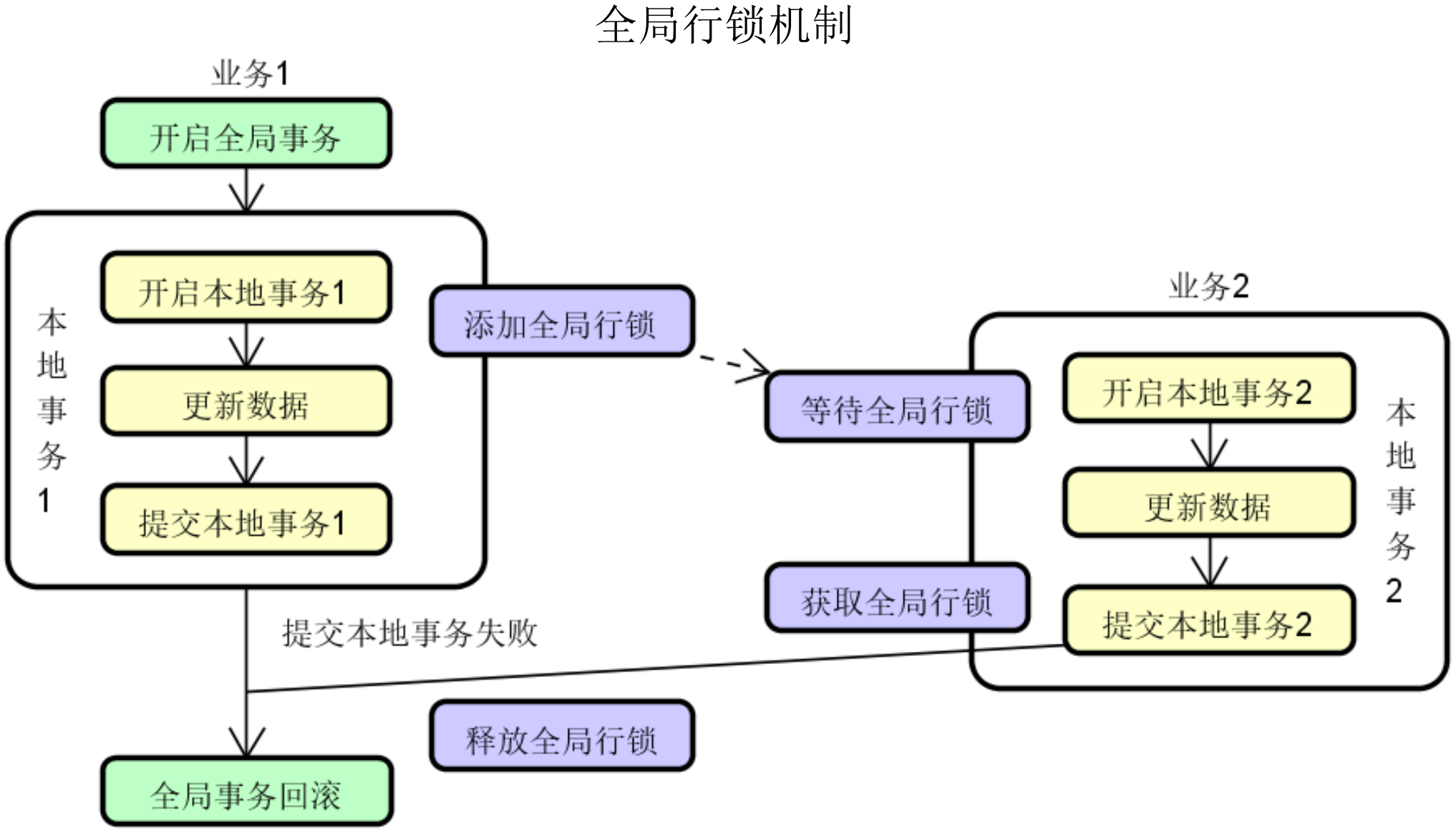
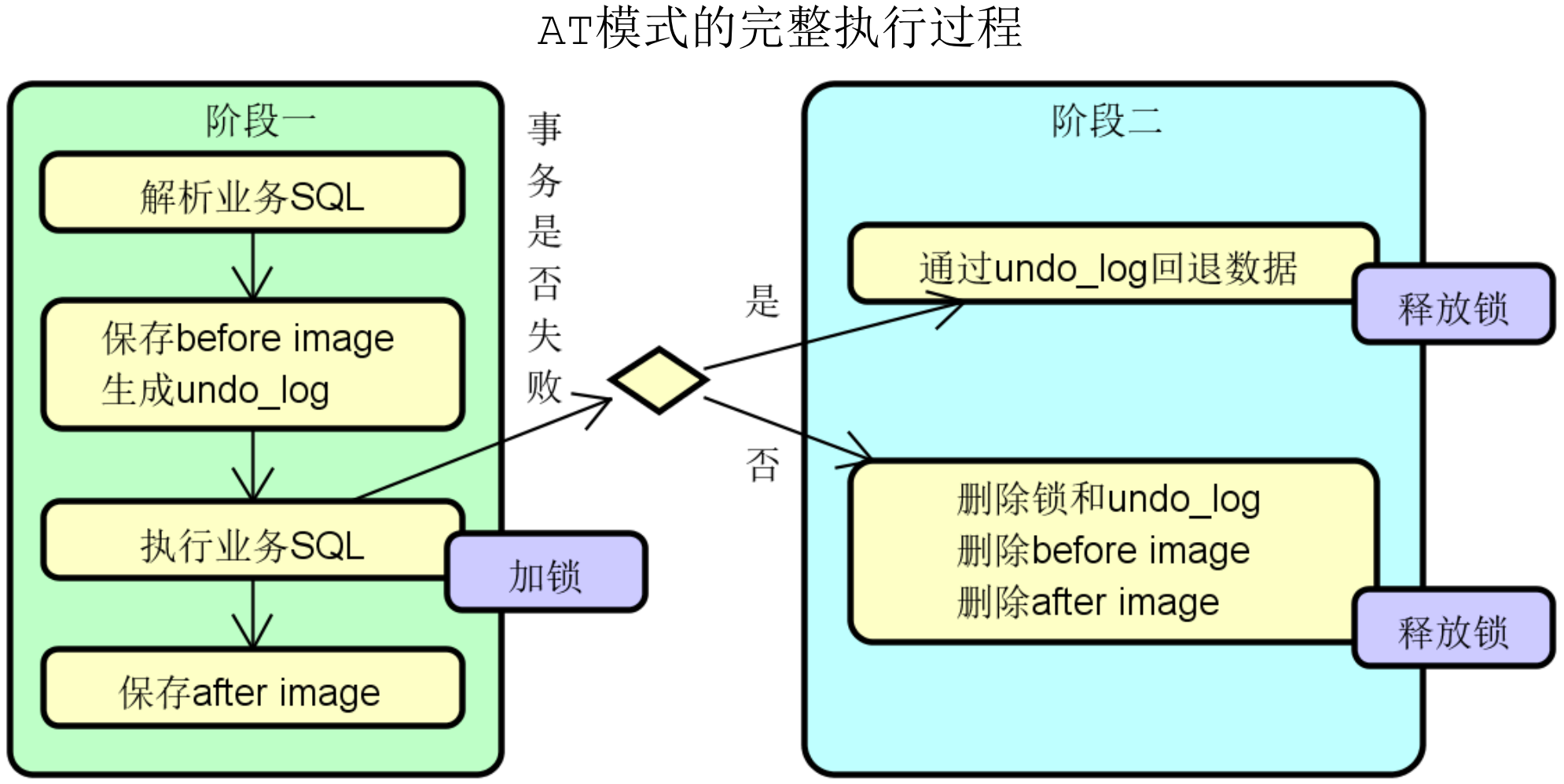
4、AT模式完整流程
before image指的是本地事务未开始之前查询出来的原数据的快照,通过before image可以反向生成回滚sql并保存到undo_log中。
after image指本地事务执行完后生成的事务后数据快照。
5、AT模式应用方式
@GlobalTransactional注解
只要在全局事务“开始”的地方把这个注解添加上去就好了,并不需要在每个分支事务中都声明它。
碰到任何 Exception 异常,都会触发全局事务回滚操作,这个行为通过rollbackFor 方法进展指定。
@GlobalTransactional(name = "XXX", rollbackFor = Exception.class)
(二)客服系统案例演进
在客服系统中,如果创建工单就需要创建聊天服务,因此针对于业务流程闭环管理的考虑,工单服务和聊天服务必须同时成功或同时失败,因此需要做分布式事务。
如果使用seata 的 AT 模式,一般会有一个独立的入口服务来做TM,而工单服务和聊天服务作为RM。那么现在就有三个微服务:业务服务(business-service)、工单服务(ticket-service)、聊天服务(chat-service),整个流程的请求入口是业务服务,然后业务服务分别调用工单服务和聊天服务插入数据。
1、创建 seata 相关的表(undo_log)
业务系统作为 TM,是不需要创建 undo_log 表的,只需要在 RM 中创建,因为 RM 才涉及数据的回滚等操作。
CREATE TABLE `undo_log`
(
`branch_id` bigint(20) NOT NULL COMMENT 'branch transaction id',
`xid` varchar(128) NOT NULL COMMENT 'global transaction id',
`context` varchar(128) NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` longblob NOT NULL COMMENT 'rollback info',
`log_status` int(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` datetime(6) NOT NULL COMMENT 'create datetime',
`log_modified` datetime(6) NOT NULL COMMENT 'modify datetime',
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='AT transaction mode undo table';
2、pom依赖与配置文件
pom依赖前面已经提到,所有的都一样,直接按照上面配置就行。
对于配置文件,和上面基本上一样,但是这里要强调一点,seata.enable-auto-data-source-proxy这个配置是是否要用数据源代理,对于 AT 模式而言,seata.enable-auto-data-source-proxy必须为true,默认也是true,但是别的模式可能会需要改为fasle,因此在AT模式中,要么不设置,设置的话必须为true。
seata:
enable-auto-data-source-proxy: true # 必须设置为 true,默认为true
application-id: ${spring.application.name}
tx-service-group: chat-service-group
......
客服系统数据一致性实现 - AT
3、使用全局事务注解
在全局事务处使用@GlobalTransactional。
@GlobalTransactional
public void initializeCustomerAndTicket(Long userId, Long staffId, String inquire) {
String ticetNo = DistributedId.getInstance().getFastSimpleUUID();
AddTicketReqVO addTicketReqVO = new AddTicketReqVO();
addTicketReqVO.setUserId(userId);
addTicketReqVO.setStaffId(staffId);
addTicketReqVO.setInquire(inquire);
addTicketReqVO.setTicketNo(ticetNo);
ticketClient.insertTicket(addTicketReqVO);
AddChatReqVO addChatReqVO = AddChatReqVO.builder().userId(userId)
.staffId(staffId).inquire(inquire).ticketNo(ticetNo).build();
chatClient.insertChat(addChatReqVO);
}
4、在启动类中添加去除数据源自动配置类DataSourceAutoConfiguration。
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})
@EnableFeignClients
public class FrontendBusinessApplication {
public static void main(String[] args) {
SpringApplication.run(FrontendBusinessApplication.class, args);
}
}
四、基于Seata实现TCC分布式事务
(一)TCC模式组成结构
TCC(Try/Confirm/Cancel)模式是一种典型的补偿模式。在TCC模式中,一个完整的业务操作由一个主服务和若干个从服务组成,主服务发起并完成整个业务流程,而TCC模式要求从服务提供三个接口:try、confirm、cancel,命名可以自定义,但是必须是这样的语义。
try:预留业务资源,完成业务规则检查
confirm:真正执行业务
cancel:释放try阶段预留的业务资源
1、TCC模式场景分析
上面提到,在TCC模式中,一个完整的业务操作由一个主服务和若干个从服务组成,主服务发起并完成整个业务流程,而TCC模式要求从服务提供三个接口:try、confirm、cancel。因此 TCC 与 AT首先一个不同就是需要有一个主服务。
如下代码所示,在使用 TCC 模式时,在业务服务中要使用 @GlobalTransactional 注解,同时调用子服务的 try 接口实现,后续还有 confirm 和 cancel 接口。
@Service
public class BusinessService {
@GlobalTransactional
public void submitOrder(...) {
//下订单
orderService.tryCreateOrder(...);
//扣库存
inventoryService.tryReduceInventory(...);
}
}
2、TCC模式场景分析
try阶段主要做了三件事情,分别是资源、业务检查、预留资源。
资源:资源就是本次操作的内容,例如订单和库存,发生了变化的主体订单会新增,库存会扣减
业务检查:订单新增:不需要检查;库存扣减:判断是否足够
预留资源:订单:新增但不生效,如设置状态;库存:对要扣减的库存进行冻结;资源预留往往是最复杂的。针对于TCC模式来说,要充分使用状态来控制资源的提交和回滚。
confirm阶段需要把try阶段预留的资源做处理
try:订单:新增但不生效,如设置状态;库存:对要扣减的库存进行冻结
confirm:订单:更新为已生效的状态,暴露给前端;库存:冻结的库存取消冻结,正式扣减
cancel阶段需要把try阶段预留的资源做撤销处理
try:订单:新增但不生效,如设置状态;库存:对要扣减的库存进行冻结
cancel:订单:更新为已失效的状态;库存:取消冻结的库存
针对于 TCC 模式来说,cancel 在逻辑上是回撤,但是在物理上并不是回撤,每一个阶段都应该对应的都自己的状态值,例如初始状态值是0,try 操作后状态值是1,confirm之后状态值是2,cancel后状态值是3,那么cancel后是将1变成3,而不是cancel后将1变成0。
3、TCC模式组成结构
TCC的组成主要有发起方和业务方,发起方第一阶段调用各个业务方执行try逻辑,第二阶段发起方根据第一阶段执行情况调用各业务方的confirm或cancel逻辑。

(二)TCC模式实现方式
1、TCC 组成方式
Seata 实现的分布式事务架构中,存在TC、TM、RM三个角色,Seata TCC模式中肯定也是这样。
在 Seata TCC 模式中,TM需要定义全局事务的范围,并启动、提交或回滚全局事务;RM 提供 TCC 服务,与TC交互并注册分支事务,并驱动分支事务的提交或回滚;而TC 用来维护全局和分支事务的状态,驱动全局事务提交或回滚。
在TCC模式中,有以下核心注解
@LocalTCC注解,用来修饰实现了二阶段提交的本地TCC接口,接口一般命名为xxxTccAction,内部包含了 TCC 的各个阶段,如下代码所示,分别定义了prepare、commit、rollback来表示。
@TwoPhaseBusinessAction注解, 该注解使用在 try 阶段,标识当前方法使用TCC模式管理事务提交,在注解中需要设置两阶段提交的名称、事务提交的方法和事务回滚的方法。
@BusinessActionContextParameter注解,该注解用在 try 阶段方法的参数上,用来在上下文中传递参数
BusinessActionContext actionContext:上下文对象,在 confirm 和 cancel 方法中均需要传递该上下文。
@LocalTCC
public interface CreateChatTccAction {
@TwoPhaseBusinessAction(name = "TccAction" , commitMethod = "commit", rollbackMethod = "rollback")
boolean prepare(BusinessActionContext actionContext,@BusinessActionContextParameter(paramName = "param") String param) throws BizException;
boolean commit(BusinessActionContext actionContext);
boolean rollback(BusinessActionContext actionContext);
}
2、TCC执行过程中的异常处理和应对策略
针对网络不可用或时延等不可控的异常情况,TCC 模式可能存在空回滚、幂等操作、TCC倒悬等问题。
(1)TCC幂等性的概念
幂等性:幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。
在 commit/cancel阶段,因为TC没有收到分支事务的响应会发起重试,这就需要RM支持幂等。如果二阶段接口不能保证幂等性,则会造成资源的重复使用或者重复释放。
如下代码所示,在 try 阶段保存了try操作成功的标识,以供第二阶段进行判断,那么在 confirm 阶段,就可以使用标识来判断 try 是否已经处理成功,如果没有处理成功,则直接返回,不做任何处理,如果处理成功,则进行commit操作并删除try标识。
public void try(...) {
//保存事务成功标识,供第二阶段进行判断
IdempotenceUtils.setResult(getClass(), actionContext.getXid(), "success");
}
public void confirm(...) {
// 幂等控制,如果commit阶段重复执行则直接返回
if (IdempotenceUtils.getResult(getClass(), actionContext.getXid()) == null) {
return true;
}
...
// commit成功删除标识
IdempotenceUtils.removeResult(getClass(), actionContext.getXid());
}
(2)TCC空回滚的概念和产生原因
TCC 空回滚是指在没有执行 try 方法的情况下,TC 下发了回滚指令并执行了cancel 逻辑。造成这一问题的原有有多种,例如 try 方法因为网络问题导致锁定资源超时,TM会判定全局事务回滚,然后TC端向各个分支事务发送cancel 指令。
TCC空回滚的应对策略:
简单应对策略: 判断资源是否被锁定;如果资源未被锁定或者压根不存在,可以认为try阶段没有执行成功
正规应对策略:引入独立的事务控制表,在try阶段中将XID和分支事务ID落表保存;如果查不到事务控制记录,那么就说明try阶段未被执行
事务控制表如下所示,其中 xid 和 branch_id 全局唯一
CREATE TABLE `transaction` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`xid` varchar(64) DEFAULT NULL COMMENT 'xid',
`branch_id` bigint(20) NOT NULL COMMENT 'branchId',
`data` text NOT NULL COMMENT '事务数据',
`state` int(4) NOT NULL COMMENT '1,初始化;2,已提交;3,已回滚',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COMMENT='事务记录表'
(3)TCC倒悬的概念和产生原因
倒悬又被叫做“悬挂”,它是指TCC三个阶段没有按照先后顺序执行;其实空回滚也是一种倒悬。
对于倒悬的解决方案和解决空回归一样,也是使用事务控制表;使用事务控制表的前提是对于 TCC 的各个阶段都都单独的状态,整个事务状态不可逆,也就是前面说的,try 阶段从无到1,cancel是从1到3,但是不能从1到0或无。
CREATE TABLE `transaction` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`xid` varchar(64) DEFAULT NULL COMMENT 'xid',
`branch_id` bigint(20) NOT NULL COMMENT 'branchId',
`data` text NOT NULL COMMENT '事务数据',
`state` int(4) NOT NULL COMMENT '1,初始化;2,已提交;3,已回滚',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COMMENT='事务记录表'
(三)客服系统案例演进
还是基于工单服务和聊天服务的事务一致性来演示,同时需要一个单独的业务服务来做调用。
1、新建或修改表
上面提到 TCC 模式会出现悬挂和空回滚的问题,因此需要在各个业务系统增加一张事务控制表;同时对于业务数据而言,也要有try、confirm、cancel各个阶段的值,因此对于业务表也要增加一个字段来记录这个状态。
-- 事务控制表,每个业务系统都要有
CREATE TABLE `transaction` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`xid` varchar(64) NOT NULL COMMENT '全局事务id',
`branch_id` bigint(11) NOT NULL COMMENT '分支事务id',
`data` text NOT NULL COMMENT '数据',
`state` tinyint(4) NOT NULL COMMENT '状态',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=22 DEFAULT CHARSET=utf8 COMMENT='客服工单表';
-- 工单系统业务表,使用tcc_status表示TCC执行的状态
CREATE TABLE `customer_ticket` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`ticket_no` varchar(64) NOT NULL COMMENT '工单编号',
`inquire` varchar(255) NOT NULL COMMENT '工单咨询内容',
`user_id` bigint(20) NOT NULL COMMENT '用户Id',
`staff_id` bigint(20) NOT NULL COMMENT '客服人员Id',
`status` int(4) NOT NULL DEFAULT '1' COMMENT '工单状态,1:初始化,2:进行中,3:结束',
`score` int(11) DEFAULT NULL COMMENT '工单评分',
`tcc_status` int(4) NOT NULL COMMENT 'TCC 执行状态,0:初始化;1:已确认;2:已回滚',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=21 DEFAULT CHARSET=utf8 COMMENT='客服工单表';
-- 聊天系统业务表,,使用tcc_status表示TCC执行的状态
CREATE TABLE `chat_record` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`ticket_no` varchar(64) NOT NULL COMMENT '工单编号',
`user_id` bigint(20) NOT NULL COMMENT '用户Id',
`staff_id` bigint(20) NOT NULL COMMENT '客服人员Id',
`last_message` varchar(255) DEFAULT NULL COMMENT '最新一条消息',
`tcc_status` int(4) NOT NULL COMMENT 'TCC 执行状态,0:初始化;1:已确认;2:已回滚',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COMMENT='聊天记录主表';
2、配置文件修改
在 AT 模式中,需要将数据库代理设置为true,但是在 TCC 模式中,就不需要了,直接使用 Spring 内置数据源即可。
seata:
enable-auto-data-source-proxy: false
3、业务系统提供 TCC 各个阶段的接口
以工单系统为例,需要提供 TCC 三个场景的方法入口,由于所有使用 TCC 模式的场景基本上都需要使用全局事务ID 和 分支事务ID,因此封装一个TccRequest,而不需要每个对象都需要单独处理。
@RestController
@RequestMapping("/customerTickets")
public class CustomerTicketController {
@Autowired
private ICustomerTicketService customerTicketService;
@PostMapping(value = "/try")
Result<Boolean> tickeTry(@RequestBody TccRequest<AddTicketReqVO> addTicketReqVO) {
customerTicketService.tickeTry(addTicketReqVO);
return Result.success(true);
}
@PostMapping(value = "/confirm")
Result<Boolean> ticketConfirm(@RequestBody TccRequest<String> ticketNo) {
customerTicketService.ticketConfirm(ticketNo);
return Result.success(true);
}
@PostMapping(value = "/cancel")
Result<Boolean> ticketCencel(@RequestBody TccRequest<String> ticketNo) {
customerTicketService.ticketCencel(ticketNo);
return Result.success(true);
}
}
@Data
@ToString
@Accessors(chain = true)
public class TccRequest<T> implements Serializable {
private String xid;
private Long branchId;
private T data;
}
4、业务系统针对于TCC各个阶段的实现
(1)try 阶段
try阶段主要是操作业务表,同时将业务表的TccStatus字段设置为0,即 try 阶段执行成功。
但是由于提到的在 TCC 中可能存在的异常情况,在 try 阶段要考虑悬挂的问题,那么就需要判断事务表中是否存在相同的全局事务id+分支事务id的数据,如果存在,则说明已经执行过TCC中的一个或多个阶段,因此直接抛出异常或返回即可,不需要再操作业务流程。
同时为了后续判断事务执行步骤,因此需要在try阶段就插入事务表。
(2)confirm 阶段
提交需要考虑幂等问题,这里放在前置系统统一处理,因此在 confirm 中只需要更新业务数据的TccStatus即可。
(3)cancel 阶段
在cancel 阶段需要考虑空回滚的问题,首先要根据自己的业务评估是否需要空回滚,我这里演示的是允许空回滚,即如果查到事务表中没有数据,直接向事务表中插入一条数据,状态为已回滚,然后直接返回,不操作业务数据,因为没有try阶段,业务数据就没有备操作。
如果查到有数据,则更新业务表的TccStatus状态,以及更新事务表的状态。
@Service
public class CustomerTicketServiceImpl extends ServiceImpl<CustomerTicketMapper, CustomerTicket> implements ICustomerTicketService {
@Autowired
CustomerTicketMapper customerTicketMapper;
@Autowired
private TransactionMapper transactionMapper;
@Override
public void tickeTry(TccRequest<AddTicketReqVO> addTicketReqVOReq) {
// 防止悬挂
Transaction transaction = transactionMapper.load(addTicketReqVOReq.getXid(), addTicketReqVOReq.getBranchId());
if(transaction != null){
throw new BizException(MessageCode.CHECK_ERROR, "事务已提交");
}
// 插入事务记录
transaction = new Transaction();
transaction.setXid(addTicketReqVOReq.getXid());
transaction.setBranchId(addTicketReqVOReq.getBranchId());
transaction.setData(JSON.toJSONString(addTicketReqVOReq.getData()));
transaction.setState(1);
transactionMapper.insert(transaction);
// 业务表
CustomerTicket customerTicket = CustomerTicketConverter.INSTANCE.convertVO(addTicketReqVOReq.getData());
customerTicket.setTicketNo(addTicketReqVOReq.getData().getTicketNo());
customerTicket.setTccStatus(0);
customerTicketMapper.insert(customerTicket);
}
@Override
public void ticketConfirm(TccRequest<String> ticketNoReq) {
transactionMapper.updateBranchTransactionToCommitted(ticketNoReq.getXid(), ticketNoReq.getBranchId());
customerTicketMapper.updateStatus(ticketNoReq.getData(), 1);
}
@Override
public void ticketCencel(TccRequest<String> ticketNoReq) {
// 空回滚:允许空回滚
Transaction transaction = transactionMapper.load(ticketNoReq.getXid(), ticketNoReq.getBranchId());
if(transaction == null ){
transaction = new Transaction();
transaction.setXid(ticketNoReq.getXid());
transaction.setBranchId(ticketNoReq.getBranchId());
transaction.setData(JSON.toJSONString(ticketNoReq));
transaction.setState(3);
transactionMapper.insert(transaction);
return;
}
transactionMapper.updateBranchTransactionToRollbacked(ticketNoReq.getXid(), ticketNoReq.getBranchId());
customerTicketMapper.updateStatus(ticketNoReq.getData(), 2);
}
}
5、前置服务实现
(1)创建调用各个业务服务的客户端
@Component
@FeignClient(value = "chat-service")
public interface ChatClient {
@PostMapping(value = "/chatRecords/try")
Result<Boolean> chatTry(@RequestBody TccRequest<AddChatReqVO> addChatReqVO);
@PostMapping(value = "/chatRecords/confirm")
Result<Boolean> chatConfirm(@RequestBody TccRequest<String> ticketNo);
@PostMapping(value = "/chatRecords/cancel")
Result<Boolean> chatCancel(@RequestBody TccRequest<String> ticketNo);
}
(2)针对各个业务服务创建TCC入口及实现
首先针对业务服务创建一个 TCC 接口,在接口上使用@LocalTCC注解表明这是一个 TCC 的接口,在接口中提供 TCC 个阶段的方法,其中在 try 阶段的方法上添加@TwoPhaseBusinessAction注解表明其是 try 阶段要执行的方法,同时设置其名称、confirm方法和rollback方法。
在 try 阶段方法实现中,主要是拼装请求对象并远程调用业务系统提供的 try 阶段方法;同时为了解决幂等操作,调用IdempotenceUtils插入数据;这里不需要关注IdempotenceUtils的实现,就是使用一个map,可以插入、移除、获取这个请求是否已经请求过等,其他的实现也可以是数据库、缓存等等,这里只是为了演示方便。
在 confirm 阶段,调用IdempotenceUtils查看请求是否已经操作,如果已经操作(map中不存在数据),则无需再次操作,直接返回;如果没有操作(map中有数据)则组装对象远程调用业务系统的 try 入口,调用成功后将map中数据移除,表明 confirm 已经被操作。
在 cannel 阶段,与 confirm 操作流程一样。
@LocalTCC
public interface CreateChatTccAction {
@TwoPhaseBusinessAction(name = "CreateChatTccAction", commitMethod = "commit", rollbackMethod = "rollback")
boolean prepare(BusinessActionContext actionContext, @BusinessActionContextParameter(paramName = "addChatReqVO") String addChatReqVO) throws BizException;
boolean commit(BusinessActionContext actionContext);
boolean rollback(BusinessActionContext actionContext);
}
@Component
public class CreateChatTccActionImpl implements CreateChatTccAction {
@Autowired
private ChatClient chatClient;
@Override
public boolean prepare(BusinessActionContext actionContext, String addChatReqVO) throws BizException {
AddChatReqVO chatReqVO = JSON.parseObject(addChatReqVO, AddChatReqVO.class);
if(chatReqVO == null || chatReqVO.getTicketNo() == null || chatReqVO.getStaffId() == null){
throw new BizException(MessageCode.CHECK_ERROR);
}
TccRequest<AddChatReqVO> tccRequest = new TccRequest<>();
tccRequest.setXid(actionContext.getXid());
tccRequest.setBranchId(actionContext.getBranchId());
tccRequest.setData(chatReqVO);
chatClient.chatTry(tccRequest);
// 事务成功,保存标识
IdempotenceUtils.setResult(getClass(), actionContext.getXid(), "success");
return true;
}
@Override
public boolean commit(BusinessActionContext actionContext) {
// 幂等操作
if(IdempotenceUtils.getResult(getClass(), actionContext.getXid()) == null) {
return true;
}
AddChatReqVO addChatReqVO = JSON.parseObject(actionContext.getActionContext("addChatReqVO").toString(), AddChatReqVO.class);
TccRequest<String> tccRequest = new TccRequest<>();
tccRequest.setXid(actionContext.getXid());
tccRequest.setBranchId(actionContext.getBranchId());
tccRequest.setData(addChatReqVO.getTicketNo());
chatClient.chatConfirm(tccRequest);
// 移除
IdempotenceUtils.removeResult(getClass(), actionContext.getXid());
return true;
}
@Override
public boolean rollback(BusinessActionContext actionContext) {
// 幂等操作
if(IdempotenceUtils.getResult(getClass(), actionContext.getXid()) == null) {
return true;
}
AddChatReqVO addChatReqVO = JSON.parseObject(actionContext.getActionContext("addChatReqVO").toString(), AddChatReqVO.class);
TccRequest<String> tccRequest = new TccRequest<>();
tccRequest.setXid(actionContext.getXid());
tccRequest.setBranchId(actionContext.getBranchId());
tccRequest.setData(addChatReqVO.getTicketNo());
chatClient.chatCancel(tccRequest);
// 移除
IdempotenceUtils.removeResult(getClass(), actionContext.getXid());
return true;
}
}
public class IdempotenceUtils {
private static Map<Class<?>, Map<String, String>> map = new ConcurrentHashMap<>();
public static void setResult(Class<?> actionClass, String xid, String v) {
Map<String, String> results = map.get(actionClass);
if (results == null) {
synchronized (map) {
if (results == null) {
results = new ConcurrentHashMap<>();
map.put(actionClass, results);
}
}
}
results.put(xid, v);
}
public static String getResult(Class<?> actionClass, String xid) {
Map<String, String> results = map.get(actionClass);
if (results != null) {
return results.get(xid);
}
return null;
}
public static void removeResult(Class<?> actionClass, String xid) {
Map<String, String> results = map.get(actionClass);
if (results != null) {
results.remove(xid);
}
}
}
(3)全局事务入口
在前置系统业务处理中,只需要分别调用各个业务的TCC接口的 try 阶段方法即可。
@Service
public class BusinessService {
@Autowired
private CreateChatTccAction chatTccAction;
@Autowired
private CreateTicketTccAction ticketTccAction;
@GlobalTransactional
public void initializeCustomerAndTicket(Long userId, Long staffId, String inquire) {
String ticetNo = DistributedId.getInstance().getFastSimpleUUID();
AddTicketReqVO addTicketReqVO = new AddTicketReqVO();
addTicketReqVO.setUserId(userId);
addTicketReqVO.setStaffId(staffId);
addTicketReqVO.setInquire(inquire);
addTicketReqVO.setTicketNo(ticetNo);
ticketTccAction.prepare(null, JSON.toJSONString(addTicketReqVO));
AddChatReqVO addChatReqVO = AddChatReqVO.builder().userId(userId)
.staffId(staffId).inquire(inquire).ticketNo(ticetNo).build();
chatTccAction.prepare(null, JSON.toJSONString(addChatReqVO));
}
}
五、Seata分布式事务模式选型
(一)Saga模式组成结构和实现方式
1、Saga模式基本概念
长事务:所谓长事务,就是需要长时间执行的事务,这类事务往往需要访问大量的数据对象,其执行周期甚至能达到几周或几月。但传统的事务执行时需要锁定占用资源,如果在这样的一个场景下,资源被长期锁定,带来的性能消耗可想而知。因此我们引入了Saga模式来解决长事务。
Saga模式:Saga模式由一串本地事务组成,每个本地事务都有自己回滚数据的补偿事务。事务之间串型执行,当正向执行的某一个事务出现报错,那么将执行这个事务的补偿事务,并且逆行执行之前事务的补偿。
2、Saga模式的优势
事务提交:一阶段直接提交事务
加锁机制:没有锁等待,性能较高
事务异步:结合事件驱动架构实现短事务异步执行
补偿机制:补偿过程实现简单,实现正向事务的逆向补偿即可
应用场景:更适用于遗留服务、第三方服务或无法改造的服务
3、Saga模式的问题
Saga由于不需要加锁,没有锁等待,性能较高。但同时由于不提供加锁机制,也就不具备原子性,因此数据隔离性的影响比大。例如,用户购买一个商品后系统赠送了一个优惠劵,然后用户使用了该优惠劵,那么当事务进行回滚时就会出现优惠劵无法回收的问题。
4、Saga模式的实现类型
事件/编排式:
前一个服务执行完成后发送消息,后一个服务通过订阅消息的模式来实现服务的协调。引入消息中间件来解决耦合性问题。
优势:引入了消息订阅降低了耦合性;简单场景实现相对来说逻辑清晰
劣势:服务之间通过订阅消息来触发调用,处理不当容易造成循环消息;复杂场景不好处理
命令/协同式:
需要定义一个集中式的Saga协调器,负责告诉每一个服务应该做什么。Saga协调器以命令/回复的方式与各个服务进行通信。
优势:理解简单,业务逻辑实现流程更加清晰;调用是单向的,不会产生依赖循环问题
劣势:存在一定的设计以及相关API的学习成本
(二)XA模式组成结构和实现方式
XA规范是X/Open组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准XA规范描述了全局的事务管理器与局部的资源管理器之间的接口,目的是允许的多个资源(如数据库,应用服务器,消息队列等)在同一事务中访问,这样可以使 ACID 属性跨越应用程序而保持有效。
XA规范使用两阶段提交来保证所有资源同时提交或回滚任何特定的事务。
本质特性:补偿型事务处理机制中的事务资源本身对分布式事务是无感知的,而XA协议要求事务资源本身提供对规范和协议的支持,所以事务资源(如数据库)可以保障从任意视角对数据的访问有效隔离,满足全局数据一致性。
事务感知性案例:例如,假设一条库存记录处在补偿型事务处理过程中,由100扣减为50。此时,系统管理人员访问数据库查询统计库存,就看到当前的 50。之后事务因为异常触发回滚,库存会被补偿回滚为 100。
补偿模式:系统管理人员查询统计到的50就是脏数据,所以补偿型事务存在中间状态
XA规范:数据中间状态50由数据库本身保证,系统管理人员无法查看。
Seata XA 模式:
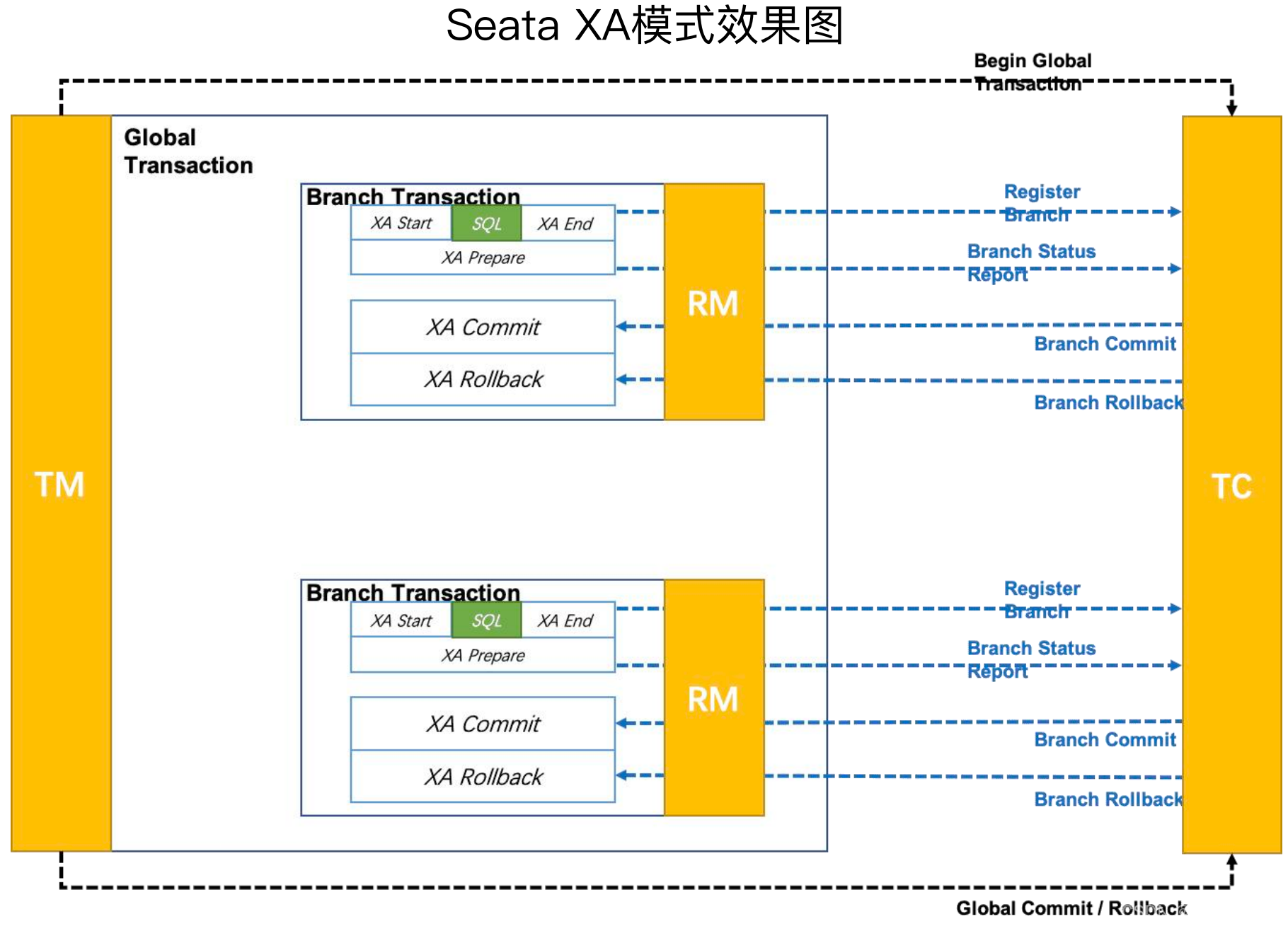
执行阶段:
可回滚:业务SQL操作放在XA分支中进行,基于资源对XA协议的支持来保证可回滚
持久化:执行XA分支的prepare方法,同样基于资源对XA协议的支持来保证持久化
完成阶段:
分支提交:执行XA分支的commit方法
分支回滚:执行XA分支的rollback方法
(三)Seata分布式事务模式选型
1、Seata分布式事务模式特性及应用场景分析
(1)AT模式
特性:业务无侵入、性能满足普通业务
应用场景:不希望对代码进行改造、数据库支持事务操作、对性能没有特别高的要求
(2)TCC模式
特性:业务强侵入、没有用到全局锁
应用场景:对性能有较高要求、无需依赖于数据库事务性、各种定制化场景
(3)Saga模式
特性:开发过程比较复杂、事务隔离性较差
应用场景:适用于长事务业务场景、适用于遗留系统改造、操作多个分散服务的数据
(4)XA模式
特性:业务无侵入、并发下性能低
应用场景:强一致,对性能要求低;使用较少
2、分布式事务模式选型的维度:
四大选型维度:业务侵入性、开发友好性、数据一致性、执行性能
业务侵入性:AT、XA < Saga < TCC,业务侵入性上来说,AT 和 XA 差不多,基本上没什么侵入。
开发友好性:Saga < TCC(try/confirm/cancel三个方法) < AT和XA(@GlobalTransactional)
数据一致性:Saga(长事务,容易引起脏读) < TCC(没有全局锁) < AT(全局锁和本地锁组合) < XA(所有事物执行完才释放本地锁)
执行性能:XA(所有事物执行完才释放本地锁) < AT(全局锁和本地锁组合) < Saga(没有锁、长事务、可并行) < TCC(没有锁、短事务)
六、基于RocketMQ实现可靠事件模式
(一)可靠事件模式
1、可靠事件模式的基本场景
在可靠事件模式中,当我们尝试将订单和支付两个微服务的数据进行分别管理的时候,需要找到一种媒介用于在这两个服务之间进行数据传递,这种数据传递方式就是事件。
消息中间件适合扮演事件处理的角色。
2、可靠事件模式的基本流程
用户下单:一方面订单服务需要对所产生的订单数据进行持久化操作;另一方面也需要同时发送一条创建订单的消息到消息中间件。
交易支付:一方面支付服务对消息进行业务处理并持久化;另一方面也需要向消息中间件发送一条支付成功消息。
订单更新:订单服务根据支付的结果处理后续业务流程
3、可靠事件模式的基本流程 - 存在问题
可靠性问题:某个服务在更新了业务实体后发布消息失败;虽然服务发布事件成功,但是消息中间件未能正确推送事件到订阅的服务。
幂等性问题:接受事件的服务重复消费事件
4、可靠事件模式的关键点
要做到可靠消息传递,需要消息中间件确保至少投递一次消息。目前主流的消息中间件都支持消息持久化和至少一次投递的功能。
那么如何实现业务操作和发布消息的原子性就变成了我们需要考虑的关键点。
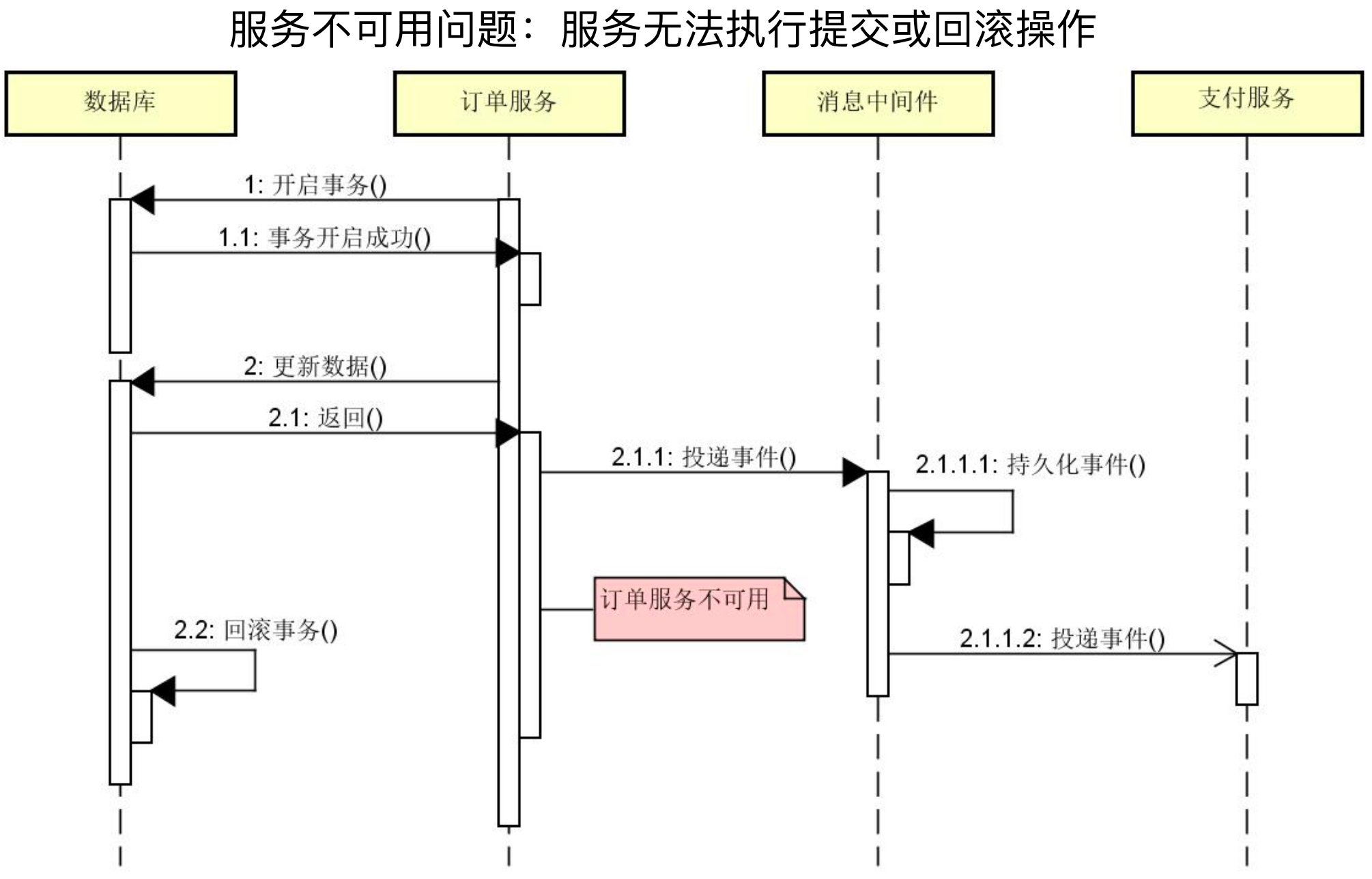
例如下面两张图分别演示了消息持久化成功但是返回失败和持久化成功后消息生产者不可用导致的消息和数据库数据不一致的问题。
业务操作和发布消息流程 - 异常1:
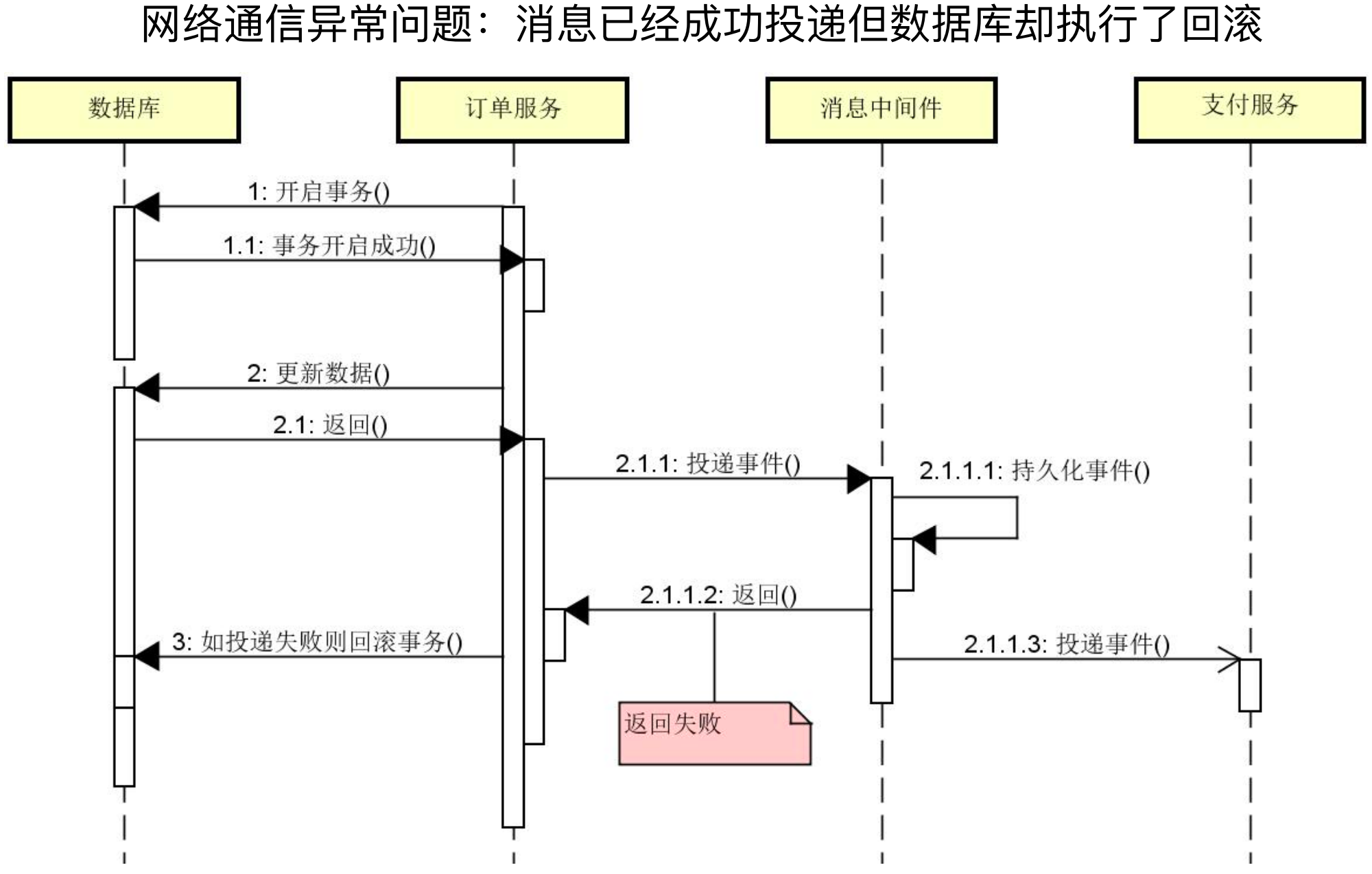
业务操作和发布消息流程 - 异常2:
针对消息可靠性的问题,可靠事件模式的解决方案如下图所示:
首先使用本地事务保证业务数据和事件数据同时成功或同时失败,然后在使用事件数据进行时间发送和确认,这样就保证了业务数据和消息发送的数据一致性。
而事件消费者获取事件进行消费,但是由于消息可能被重复发送,因此需要考虑幂等操作。
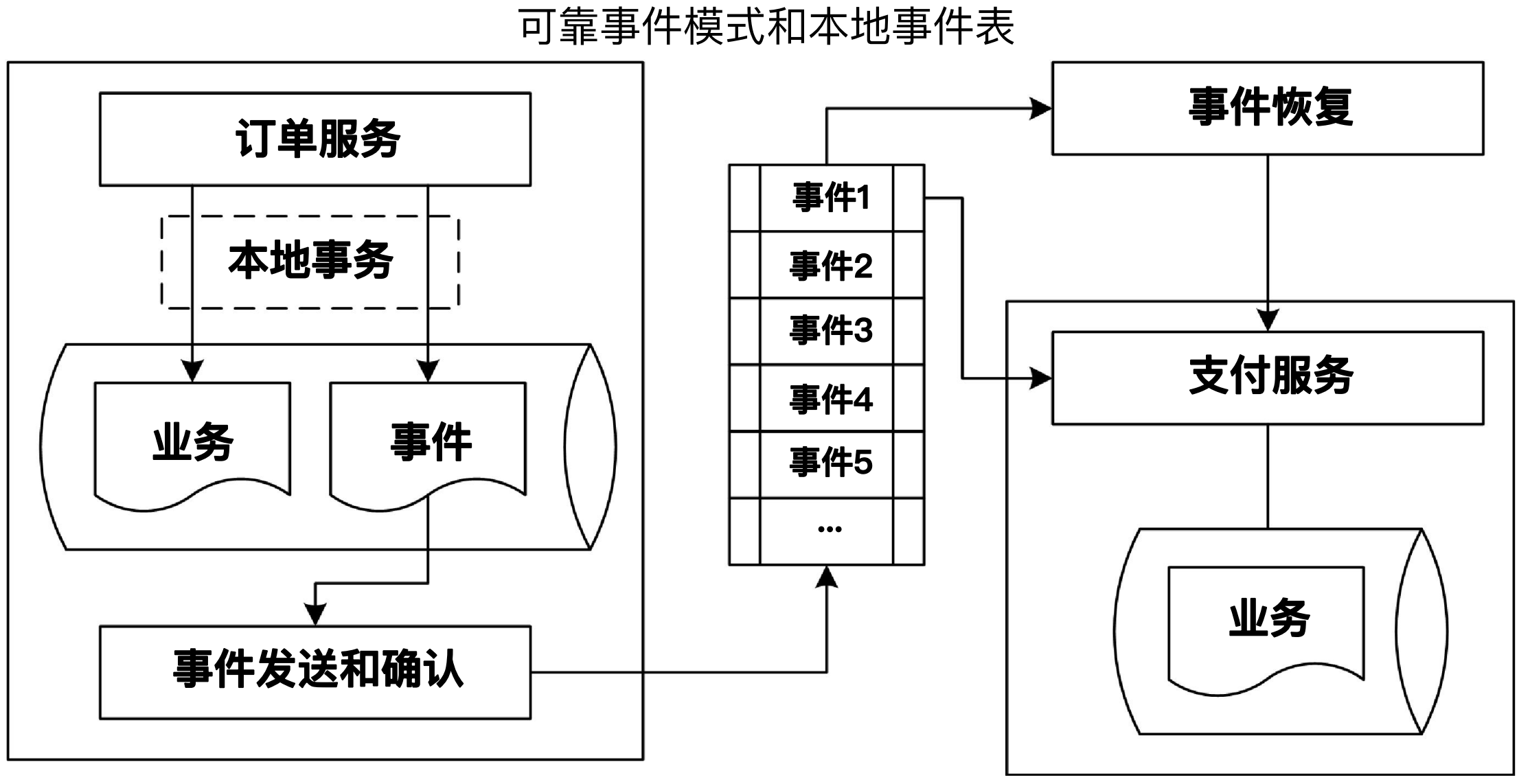
以上的流程只是可靠事件模式是一种抽象,不同的工具可以有不同的实现方式。但是对于可靠性事件模式的组成描述的非常贴切,例如以下组件的划分和责任:
本地事件表:业务操作时需要将业务数据和事件保存在同一个本地事务中;保存事件
事件确认组件:事件确认表现为一种定时机制,用于处理事件没有被成功发送的场景;重发事件。
事件恢复组件:事件恢复组件同样是一种定时机制,根据本地事件表中的事件状态,专门处理状态为已确认但已超时的事件;更新事件状态
(二)RocketMQ事务消息
事务消息的作用是在消息发送方和消息接收方都保证消息的处理和本地事务同时成功或同时失败。例如在消息发送方,其解决了执行本地事务与发送消息的原子性问题;保证本地事务执行成功,消息一定发送成功。在消息接收方,解决了接收消息与本地事务的原子性问题;保证接收消息成功后,本地事务一定执行成功。因此事务消息完美的解决了可靠模式流程中可能出现的问题。
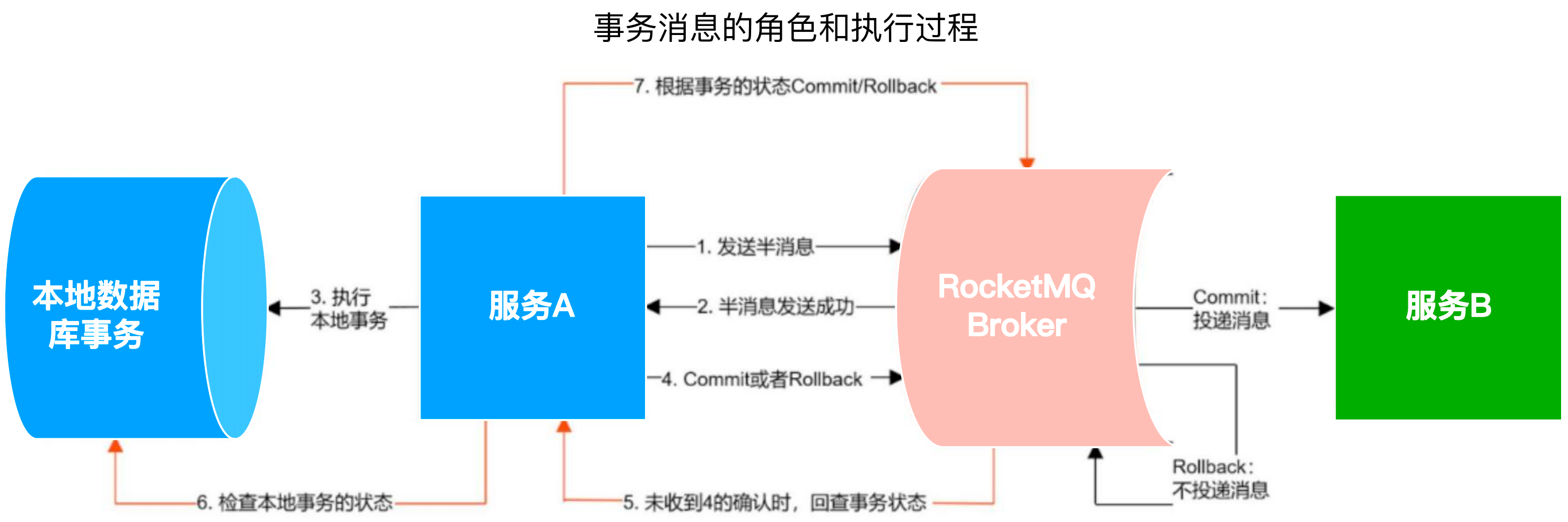
事务消息发布流程:
发送方发送一个事务消息给Broker,此时消息被存入半事务消息 topic,即半消息,该 topic 的消息不会消费者消费,;
Broker 返回发送成功给发送方
发送方执行本地事务,例如操作数据库
如果本地事务执行成功,发送 commit 给 Broker,RocketMQ 会将这条消息从半事务消息 topic 转到实际的业务 topic,这条消息就可以被接收方消费;如果本地事务执行失败,发送 rollback 给 Broker,RocketMQ 会删除半事务消息 topic 中的这条消息
如果发送方在本地事务过程中,出现服务挂掉,网络闪断或者超时,那Broker将无法收到确认结果,此时RocketMQ将会不停的询问发送方来获取本地事务的执行状态,即事务回查,并根据事务回查的结果来决定Commit或Rollback,这样就保证了消息发送与本地事务同时成功或同时失败。
executeLocalTransaction {
执行本地事务
如果失败就选择回滚事务,反之提交事务
}
checkLocalTransaction {
实现事务回查
根据事务执行记录判断,已执行则提交事务
}
(三)基于RocketMQ实现可靠事件
首先需要初始化环境,即创建事务执行记录表,该表的作用有两个,分别是实现事务回查和业务层幂等控制。
CREATE TABLE `tx_record` (
`tx_no` varchar(64) NOT NULL COMMENT '事务Id',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`tx_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='事务记录表'
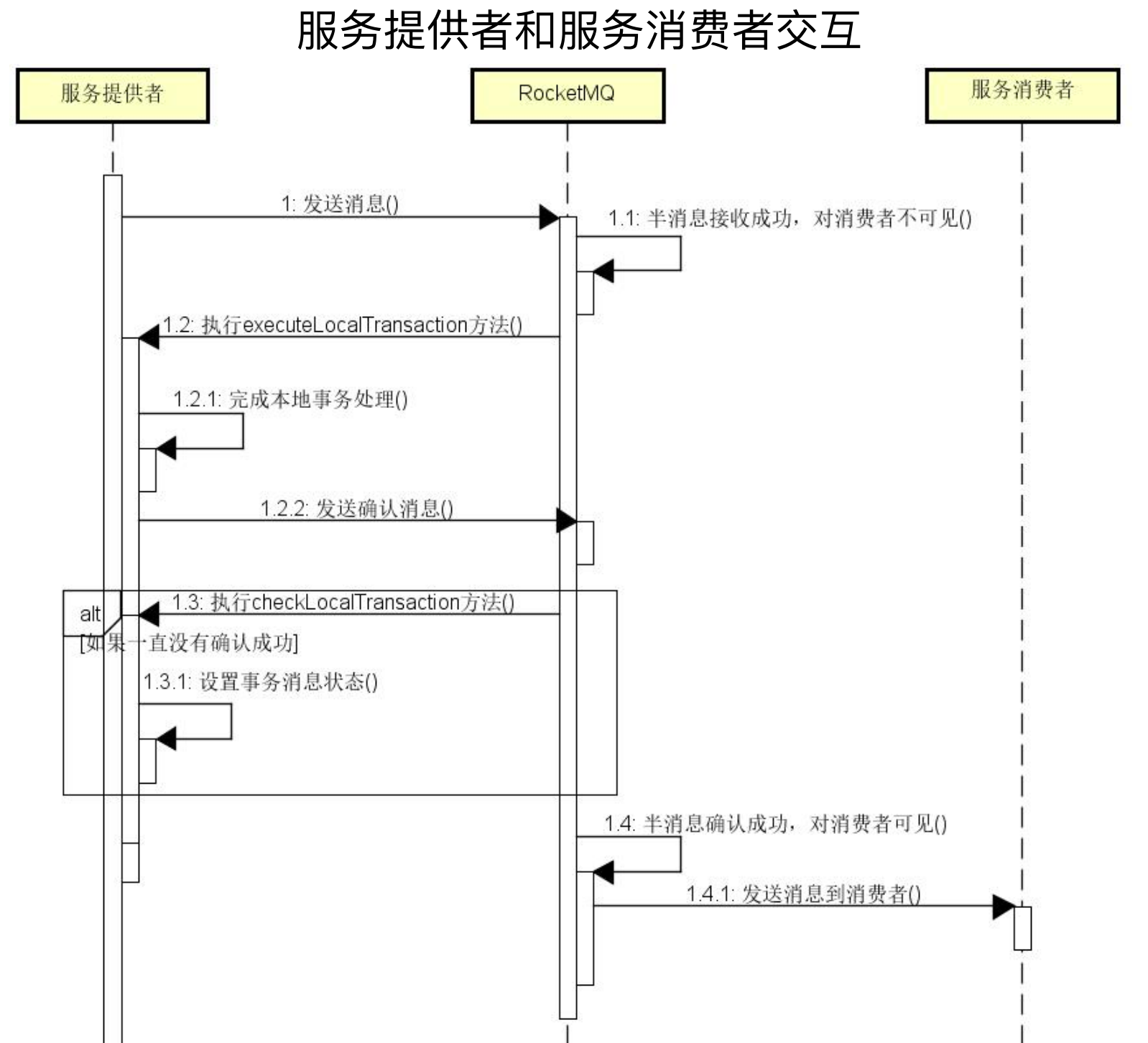
事务消息开发工作主要是 TransactionListener接口,其包含了本地事务执行方法 executeLocalTransaction 和本地事务回查 checkLocalTransaction 方法,这两个方法会被RocketMQ 自动调用。
本地事务执行方法executeLocalTransaction的作用是执行本地事务,发送半事务消息成功后会指向该方法。
本地事务执行成功或失败,会向 RocketMQ 发送事务确认或事务回滚消息。
如果未向RocketMQ发送本地事务执行成功或执行失败的确认消息,RocketMQ会调用回查方法checkLocalTransaction,然后再根据事务执行记录判断,如果已执行则提交事务,如果没有提交则回滚事务。
如果消费者处理事务消息时出现异常,RocketMQ会进行重试操作,直到消息消费和本地事务处理都成功。
如果要实现服务提供者,必须要有业务服务实现类和TransactionListener实现类,TransactionListener提供事务执行和事务状态回查的作用,对于事务执行来说,TransactionListener是一个入口,然后会调用业务服务实现类做本地事务处理,做本地事务处理时会处理事务执行记录表,然后发送消息;而事务状态回查则提供了事务回查机制,查询事务执行记录表来查看事务是否提交成功。
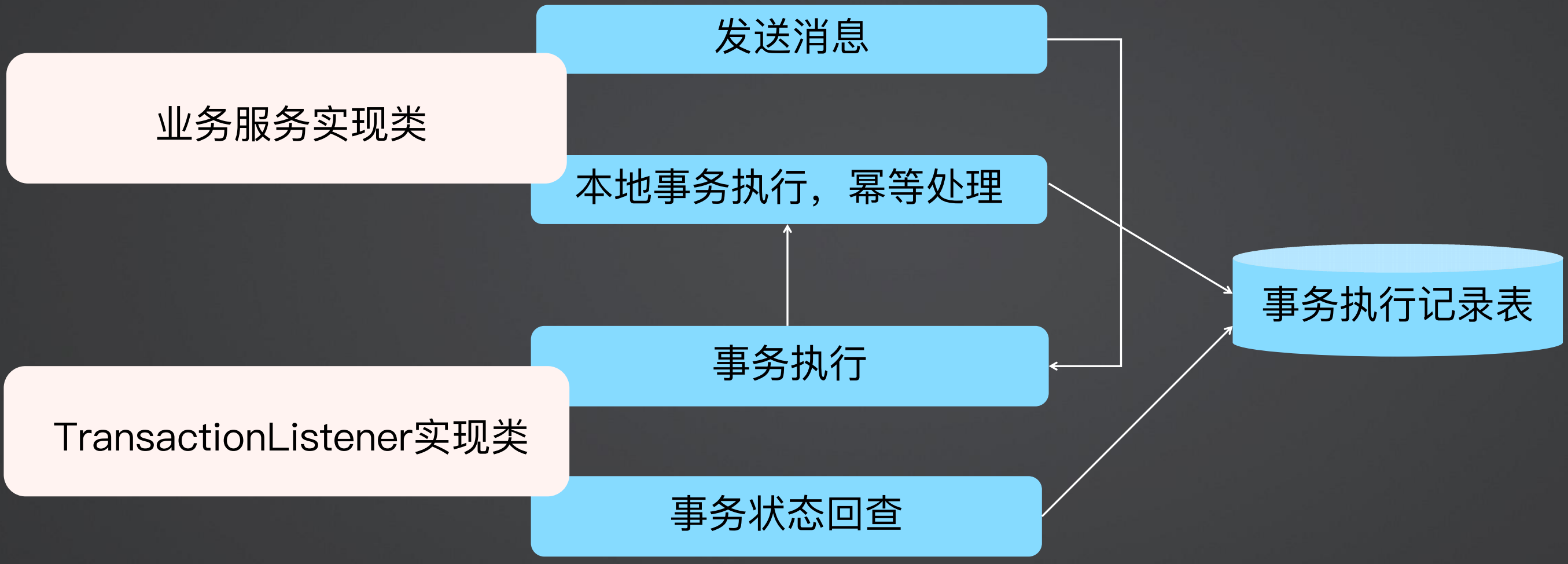
如果实现服务消费者,业务有消息消费实现类和业务服务实现类,消息消费实现类执行消息处理逻辑,然后调用业务服务实现类执行本地事务,最终处理事务执行记录表。

可靠事件模式和RocketMQ事务消息总结:
生产者保证本地事务与消息发送的原子性,消费者事务参与方接收消息的可靠性。
(四)客服系统案例演进
1、创建事务表
在事务消息的生产者和消费者所用到的数据库中均创建一张事务表。
CREATE TABLE `tx_record` (
`tx_no` varchar(64) NOT NULL COMMENT '事务Id',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`tx_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='事务记录表'
2、生产者发送消息
在业务调用时,只发送事务消息,不做业务逻辑处理,发送事务消息使用sendMessageInTransaction进行发送。
@Override
public void generateTicket(AddTicketReqVO addTicketReqVO) throws BizException {
TicketGeneratedEvent ticketGeneratedEvent = createTicketGeneratedEvent(addTicketReqVO);
String messageJson = JSON.toJSONString(ticketGeneratedEvent);
Message<String> message = MessageBuilder.withPayload(messageJson).build();
rocketMQTemplate.sendMessageInTransaction("product_group_ticket", "topic_ticket", message, null);
}
3、发送者业务处理与消息回查
发送者需要实现RocketMQLocalTransactionListener接口,重写其中的执行本地事务方法executeLocalTransaction和消息回查方法checkLocalTransaction。
@Component
@Slf4j
@RocketMQTransactionListener(txProducerGroup = "product_group_ticket")
public class ProductListener implements RocketMQLocalTransactionListener {
@Autowired
private ICustomerTicketService customerTicketService;
@Autowired
private TxRecordMapper txRecordMapper;
@Override
public RocketMQLocalTransactionState executeLocalTransaction(Message message, Object o) {
try{
// 消息转换
TicketGeneratedEvent ticketGeneratedEvent = converEvent(message);
// 执行本地事务
customerTicketService.doGenerateTicket(ticketGeneratedEvent);
// 告诉 RocketMQ 事务提交成功
return RocketMQLocalTransactionState.COMMIT;
} catch (Exception e){
// 本地事务执行失败,告诉 RocketMQ 事务提交失败
return RocketMQLocalTransactionState.ROLLBACK;
}
}
@Override
public RocketMQLocalTransactionState checkLocalTransaction(Message message) {
// 消息转换
TicketGeneratedEvent ticketGeneratedEvent = converEvent(message);
// 查看事务是否提交
boolean isTxNoExists = Objects.nonNull(txRecordMapper.findTxRecord(ticketGeneratedEvent.getTxNo()));
// 如果事务已提交,返回 COMMIT
if(isTxNoExists){
return RocketMQLocalTransactionState.COMMIT;
}
// 如果事务没有提交,返回 ROLLBACK
return RocketMQLocalTransactionState.UNKNOWN;
}
private TicketGeneratedEvent converEvent(Message message) {
String messageString = new String((byte[]) message.getPayload());
TicketGeneratedEvent ticketGeneratedEvent = JSON.parseObject(messageString, TicketGeneratedEvent.class);
return ticketGeneratedEvent;
}
}
在执行本地事务方法executeLocalTransaction中,除了处理业务逻辑外,还需要向事务表插入一条数据。
如果整个事务提交成功,则返回commit,如果事务提交失败,则返回rollback。
RocketMQ接收到commit或rollback后会做对应的处理。
@Override
@Transactional(rollbackFor = Exception.class)
public void doGenerateTicket(TicketGeneratedEvent ticketGeneratedEvent) {
int i = 1/0;
// 幂等操作
if(Objects.nonNull(txRecordMapper.findTxRecord(ticketGeneratedEvent.getTxNo()))){
return;
}
// 插入工单
CustomerTicket customerTicket = CustomerTicketConverter.INSTANCE.convertVO(ticketGeneratedEvent);
customerTicket.setStatus(1);
save(customerTicket);
txRecordMapper.addTxRecord(ticketGeneratedEvent.getTxNo());
}
而消息回查则是rocketMQ在没有收到commit或rollback时回查消息生产者,即查询事务数据在数据库是否存在,如果存在,说明事物提交成功,返回commit,如果不存在,则还不确定事务是否提交,则返回unknow。
3、消息消费者
对于消息的消费者,和普通消息没有什么区别,直接订阅消费即可。
@Component
@Slf4j
@RocketMQMessageListener(consumerGroup = "product_group_ticket", topic = "topic_ticket")
public class Consumer implements RocketMQListener<String> {
@Autowired
private IChatRecordService chatRecordService;
@Override
public void onMessage(String s) {
TicketGeneratedEvent ticketGeneratedEvent = JSON.parseObject(s, TicketGeneratedEvent.class);
chatRecordService.generateChatRecord(ticketGeneratedEvent);
}
}
-----------------------------------------------------------
---------------------------------------------
朦胧的夜 留笔~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号