
Redis性能调优策略
一、服务端优化
(一)限制Redis内存大小
需要使用maxmemory来设置Redis的最大内存,例如 maxmemory 1GB
在64位操作系统中,Redis的内存大小是没有限制的,因为maxmemory配置项是被注释掉的,这样就会导致在Redis内存不足时,Redis会使用磁盘作为其虚拟内存,而当操作系统将Redis所用的内存分配至磁盘时,将会阻塞Redis进程,到处Redis出现延迟,从而影响Redis的整体性能,因此我们要限制Redis的内存大小为一个固定的值,并且该值不能大于服务器的内存。当Redis的运行达到此值时会触发内部的淘汰策略,从而将内存回收。
首先说一下淘汰策略LRU和LFU:
LRU(最近最少被使用):新数据插入链表头部;当命中缓存时,将数据移动到链表头部;当链表满时,将链表尾部数据丢弃
LFU(最少使用):新数据插入链表头部,并设置访问次数,并按照访问次数排序;没插入或者命中一次就记一次数,然后重新排序;如果链表满时,从链表尾部删除;
二者对比:LFU和LRU的侧重点不同,LRU侧重的是最近被访问的数据不删除,而LFU是保证访问频率最高的数据不被删除,但是LFU有一个缺点,就是如果在某一个时段,某个key的访问频率非常高,那么该KEY就会变为热点数据,但是实际上该KEY在其他时间节点不会被用到,那么会造成这些数据不会被删除。
Redis4.0之后有8种淘汰策略:
| 淘汰策略 | 说明 |
| noeviction | 不淘汰任何数据,当内存不足时,新增操作会报错,Redis默认淘汰策略 |
| allkeys-lru | 淘汰整个键值对中最久未使用的数据 |
| allkeys-random | 随即淘汰任意值 |
| volatile-lru | 淘汰所有设置了过期时间的key中最久的key |
| volatile-random | 随机淘汰所有设置了过期时间的key |
| volatile-ttl | 优先淘汰最早过期的key |
| volatile-lfu |
淘汰所有设置了过期时间的key中使用最少的key(4.0之后新增) |
| allkeys-lfu | 淘汰所有key中的最少被使用的key(4.0之后新增) |
(二)使用 lazy free 特性
lazy free特性是Redis4.0新增的一个非常实用的功能,他可以理解为惰性删除或延迟删除,意思就是在删除的时候提供异步删除的功能,他把删除key的操作放在BIO单独的子线程处理中,以减少删除操作对Redis主线程的阻塞,同时可以有效的避免删除大的key时带来的性能和可用性问题。
lazy free对应四种场景,默认都是关闭的:
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
replica-lazy-flush no
lazyfree-lazy-eviction:表示当Redis运行内存超过maxmemory时,是否开启 lazy free 机制删除。
lazyfree-lazy-expire:表示设置了过期时间的key,是否开启 lazy free 机制删除。
lazyfree-lazy-server-del:有些指令在操作已存在的key时,是否开启 lazy free机制删除。这个需要特别说明一下,有些指令,会自带一个隐式的del命令,例如rename指令,当目标key存在时,会先删除目标key,再创建一个新的key,如果目标key是一个 big key 时,就会造成阻塞删除的情况,因此使用该配置来设置是否要在该种情况下开启 lazy free 机制删除数据。
slave-lazy-flush:针对slave进行全量同步数据时,slave在加载master上的RDB前,会使用flushall来清理自己的数据,该配置用来设置该种场景下是否要开启 lazy free 机制删除数据。
这里比较建议开启前三种 lazy free 配置,这样就可以有效的提高主线程的执行效率。
(三)使用 slowlog 优化耗时命令
我们可以使用slowlog功能,找出最耗时的Redis命令进行优化,以提升Redis的运行速度,慢查询有两个重要的配置项:
slowlog-log-slower-than:用于设置慢查询的评定时间,也就是说执行时间超过改时间的命令,将会被当成慢查询记录在日志中,它的执行时间是微妙
slowlog-max-len:用来配置慢查询日志的最大记录数
slowlog-log-slower-than 10000
# There is no limit to this length. Just be aware that it will consume memory.
# You can reclaim memory used by the slow log with SLOWLOG RESET.
slowlog-max-len 128
我们可以根据实际的业务情况进行响应的配置,其中慢日志是按照插入顺序倒叙存入慢查询日志中的。
我们可以使用 slowlog get n 来获取相关的慢查询日志,再找到这些慢查询对应的业务进行相关优化。
127.0.0.1:6388> slowlog get 10
(empty list or set)
(四)检查数据持久化策略
Redis的持久化策略有RDB、AOF和混合持久化方式(4.0之后新增),由于RDB和AOF各有利弊,RDB可能会造成一定的数据丢失,AOF由于文件较大,会影响Redis的启动速度,因此如果是Redis4.0及以上版本,可以直接使用混合持久化方式。
同样,如果在业务中,Redis不需要持久化数据库时,可以关闭持久化,这样可以有效地提升Redis的运行速度,不会出现间歇性卡顿的问题。
(五)使用分布式架构来增加读写速度
Redis的分布式架构有主从同步、哨兵模式、Redis Cluster集群,主从同步可以将写操作放在master上处理,可以将读操作放在slave上处理,因此极大的提高了redis的处理性能;而Sentinel是对主从同步的一个升级,解决了单点故障以及故障迁移的问题;而RedisCluster集群,在Redis3.0推出,解决了redis的扩展问题,并且将独写操作使用hash分布到了不同的redis服务器上,更大的提高了redis命令的操作性能。
从选择上,首选Redis Clluster集群的实现方案。
(六)使用物理机而非虚拟机
在虚拟机中运行Redis服务器,因为和物理机共享一个物理端口,并且一台物理机可以有多个虚拟机在运行,因此在内存占用上和网络延迟方面会有很糟糕的表现,我们可以通过 ./redis-cli -- intrinsic-latency 100 命令来超看延迟时间,如果对Redis性能要求很高的话,应尽可能在物理机上直接部署Redis服务器。
[root@liconglong-aliyun redis-5.0.4]# ./src/redis-cli -p 6388 --intrinsic-latency 100
Max latency so far: 1 microseconds.
Max latency so far: 11 microseconds.
Max latency so far: 13 microseconds.
Max latency so far: 21 microseconds.
Max latency so far: 57 microseconds.
Max latency so far: 136 microseconds.
Max latency so far: 416 microseconds.
Max latency so far: 498 microseconds.
Max latency so far: 536 microseconds.
Max latency so far: 577 microseconds.
Max latency so far: 692 microseconds.
(七)禁用 THP 特性
Linux kernel在2.6.38内核增加了Transparent Huge Pages(THP)特性,支持大内存页2M分配,默认开启。
当开启了THP时,fork的速度会变慢,fork之后每个内存页由原来的4KB变为2MB,会大幅增加重写期间父进程的内存消耗,同时每次写命令引起的复制内存页放大了512倍,会拖慢写操作的执行时间,导致大量写操作慢查询,例如简单的incr命令也会出现在慢查询中,因此Redis建议将此特性禁用,禁用方法如下:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
二、客户端优化
(一)设置键值的过期时间
我们应该根据实际的业务情况,对键值对设置合理的过期时间,这样Redis会自动的清楚过期的键值对,从而达到节省内存占用的效果,可以避免键值对过多的堆积,频繁触发内存淘汰策略。
Redis有四个命令可以设置键的存活时间或过期时间:
expire:用于设置key还剩余多少秒过期
pexpire:用于设置key还有多少毫秒过期
expireat:用于设置key的过期时间(到期的具体秒数时间戳)
pexpireat:用于设置key的过期时间(到期的具体毫秒时间戳)
127.0.0.1:6388> set d1 va
OK
127.0.0.1:6388> set d2 va
OK
127.0.0.1:6388> set d3 va
OK
127.0.0.1:6388> set d4 va
OK
127.0.0.1:6388> expire d1 100
(integer) 1
127.0.0.1:6388> pexpire d2 100000
(integer) 1
127.0.0.1:6388> ttl d1
(integer) 83
127.0.0.1:6388> ttl d2
(integer) 91
127.0.0.1:6388> expireat d3 1612363856
(integer) 1
127.0.0.1:6388> ttl d3
(integer) 87127.0.0.1:6388> pexpireat d4 1612364096000
(integer) 1
127.0.0.1:6388> ttl d4
(integer) 112
(二)禁用长耗时的查询命令
Redis绝大多数的读写命令的时间复杂度都是在O(1)到O(N)之间,其中O(1)就可以放心使用,但是O(N)就要当心了,因为N表示不确定性,数据越大,查询的速度就会越慢,因为Redis只用一个线程来做数据查询,如果这些指令非常耗时,就会造成Redis的阻塞,那么就会造成大量的延时。
要避免O(N)类的命令对Redis性能造成的影响,就要从以下几个方面进行改造:
1、禁止使用key * 命令;
2、避免一次查询所有成员,要使用 scan 命令进行分批的、游标式的遍历
3、通过机制严格空指Hset、Set、Scorted Set 等数据结构的大小
4、将排序、并集、交集等操作放在客户端执行,以减少Redis服务器的运行压力
5、删除一个大的数据时,可能会需要很长的时间,所以建议用异步删除的方式unlink,他会启动一个新的线程来删除目标数据,而不是阻塞Redis主线程。
(三)避免大量数据同时失效
Redis过期Key的删除使用的是贪心策略,其会在一秒内进行10次扫描(改配置可以在redis.conf文件中配置,默认配置是 hz 10),redis会随机抽取20个key,删除这20个key中过期的key,如果过期的key比重超过25%,则重复执行该流程,直到比重低于25%为止。
那么如果在同一时期如果存在大量的key一起过期,就会导致Redis多次循环持续扫描删除过期key,直到被删除的数据足够多(redis的过期数据不再很密集,随机抽取低于25%),才会停止,在此过程中,由于循环和删除的原因,会导致Redis的独写出现明显的卡顿,卡顿的另一种原因是内存管理器需要频繁回收内存,因此也会消耗一定的CPU。
为了避免因为这种情况导致的卡顿现象,我们要预防大量的key在同一时刻一起过期,简单的解决方案就是在过期时间的基础上加一个指定范围的随机数。
(四)使用 Pipeline 批量操作数据
Pipeline(管道技术)是客户端提供的一种批处理技术,用于一次处理多个Redis命令,从而提高整个交互的性能。
(五)使用连接池
在客户端的使用上,我们尽量使用Pipeline技术外,还需要尽量使用Redis连接池,而不是频繁的创建、销毁Redis连接,这样就可以减少网络传输次数和减少非必要的调用命令。
三、设计优化
1、估算Redis内存使用量
要估算redis中的数据占据的内存大小,需要对redis的内存模型有比较全面的了解,下面以最简单的字符串类型来举例说明:
假设有90000个键值对,每个key的长度是12个字节,每个value的长度也是12个字节,且键值都不是整数类型。
然后我们可以预估一下这90000个键值对占用的空间,首先,我们可以判定字符串类型使用的是embstr;90000个键值对占用的空间只要可以分为两部分,一部分是90000个dictEntry占据的字符串,一部分是键值对所需要的bucket空间。
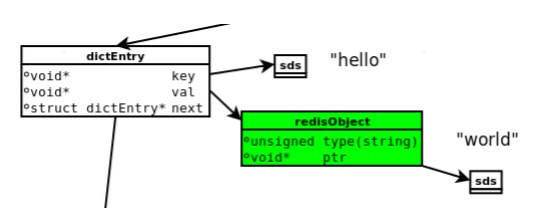
每个dictEntry占据的空间包括:一个dictEntry结构、一个key、一个redisObject、一个value
dictEntry结构:24个字节,jemalloc会分配32个字节的内存块(64位操作系统下,一个指针8字节,一个dictEntry由三个指针组成)
key:12个字节,所以SDS需要 12 + 4 = 16 个字节(SDS的长度=4 + 字符串长度),jemalloc会分配16个字节的内存块
redisObject:16字节,jemalloc会分配16个字节的内存块(固定长度:4bit + 4bit + 2bit + 4byte + 8byte = 16byte)
value:12个字节,所以SDS占16个字节,原理同key
综上,一个dictEntry所占的空间为: 32+16+16+16 = 80 个字节。
bucket空间:
bucket数组大小为大于90000的最小的2的n次方,是131072,每个bucket元素(bucket中存储的是指针元素)为8字节(因为64位操作系统中指针大小位8个字节)。
因此可以推算出,90000个键值对占据的内存大小为 90000*80 + 131072*8 = 82488576
2、优化内存占用
了解了redis的内存模型,对优化redis内存有很大的帮助,下面从4个角度来进行优化:
(1)利用jemalloc特性进行优化
以上面讲述的90000个键值对的例子,由于jemalloc分配的空间是不连续的,因此KV字符串变化一个字节,可能会引起占用内存的很大变化,在设计时可以利用这一点。例如,如果key的长度是13,则SDS为17个字节,那么jemalloc就会分配32个字节;如果将key的长度缩减为12个字节,则SDS为16个字节,jemalloc也会分配16个字节,这样每个key所占用的空间就可以缩小一半。
(2)使用整型/长整型
如果使用整型或长整型,Redis会使用int类型(8个字节)存储来替代字符串类型,可以节省更多空间,因此在可以使用整型或长整型代替字符串的场景下,尽量使用整型或长整型。
(3)共享对象
利用共享对象,可以减少对象的创建,同时也减少了redisObject的创建,从而节省空间。
目前Redis中的共享对象只包括10000个整数(0-9999),可以通过调整REDIS_SHARED_INTEGERS参数提高共享对象的个数;例如将REDIS_SHARED_INTEGERS提高到20000,那么0-19999就都是共享对象。例如文章的浏览次数,基本上都是20000次以内,因此就可以将REDIS_SHARED_INTEGERS设置为20000,以便节省空间。
(4)缩短键值对的存储长度
键值对的长度是和性能成反比的,比如我们做一组写入数据的性能测试,执行结果如下:

从数据可以看出,在key不变的情况下,value值越大操作效率就越慢,因为Redis对于同一种数据类型会使用不同的内部编码进行存储,比如字符串的内部编码就有三种:int、embstr、raw,这是因为Redis是想通过不同的编码实现效率和空间的平衡,然而数据量越大使用的内部编码就越复杂,而越复杂的内部编码存储的性能就越低。
这还只是写入时的速度,当键值对内容较大时,还会带来以下几个问题:
内容越大,需要的持久化时间就越长,需要挂起的时间越长,Redis的性能就越低。
内容越大,在网络上传输的内容就越多,需要的时间就越长,整体的运行速度就越低
内容越大,占用的内存就越多,就会更频繁的触发内存淘汰机制,从而给Redis带来更多的运行负担。
综上所示,在尽量保证完整语义的同时,我们要尽量的缩短键值对的存储长度,必要时要对数据进行序列化和压缩再存储,以Java为例,序列化我们可以使用protostuff或kryo,压缩我们可以使用snappy。
-----------------------------------------------------------
---------------------------------------------
朦胧的夜 留笔~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号