
[分布式系统学习]阅读笔记 Distributed systems for fun and profit 抽象 之二
本文是阅读 http://book.mixu.net/distsys/abstractions.html 的笔记。
第二章的题目是"Up and down the level of abstraction"。这一章里面,作者主要介绍了分布式系统里面的一个重要概念:CAP理论。
什么是CAP理论呢?就是说在任何情况下,分布式系统只能满足下面三项中的两个:
- 一致性(Consistency),这里指的强一致性。
- 可用性(Availability)。
- 对网络分割容错(Partition tolerance)。
这三者不能同时满足。
接下来是详细内容。
--------------------下面是本次新闻联播的详细内容------------------------------
抽象(Abstraction)
要讨论理论,就不能不聊到抽象。作者在这里文艺了一把。首先在哲学意义上讨论了抽象。
当我们说X比Y更加抽象,我们在说什么?
首先,和Y相比,X并没有引入新的东西。X甚至可能移除了一些东西,显得更加可控。
其次,X在某些程度上更容易理解。
作者开始掉书袋了。啧啧。尼采说过:
Every concept originates through our equating what is unequal. No leaf ever wholly equals another, and the concept "leaf" is formed through an arbitrary abstraction from these individual differences, through forgetting the distinctions; and now it gives rise to the idea that in nature there might be something besides the leaves which would be "leaf" - some kind of original form after which all leaves have been woven, marked, copied, colored, curled, and painted, but by unskilled hands, so that no copy turned out to be a correct, reliable, and faithful image of the original form.
这句话的大概意思,斗胆翻译如下:
我们从各异的事物中总结出其的共性,从而产生了概念。世界上没有完全相同的两片树叶,但是”树叶“这个概念却是我们忽略世界上千万的不同的叶子的差别,抽象而成的。这说明,有一些本质的东西让树叶成为”树叶“,而这些本质,原始的存在, 仿佛是被一双技巧拙劣的双手标记,扭曲,拷贝,上色,成为我们看到的一片片树叶。它们面目全非,完全不是本质存在的正确,可靠和可信的反映。
抽象,本质上,是假的。每个具体的个体都是唯一的。但是抽象让世界更加可控。所以如果我们周围看到的都是本质,那么我们从中推论出来的结果会广泛适用。反之,类似推论出来的不可能的结果(impossibility result)则表明,在一些限制和假设下,我们是不能解决某些问题的。
所以抽象就是为了让事物等价,忽略某些现实生活中并不本质的东西。但是我们怎么知道该忽略那些呢?
我们没法提前知道。
我们在做系统设计的时候,每忽略一些事实,我们就冒险引入一些错误和性能问题。然后我们就不得不换一条路。那么,对分布式系统来说,那些本质我们不得不考虑呢?这就是系统模型设计要解决的问题啦。
系统模型
分布式系统的程序有下面几个特点:
- 在独立的节点上运行
- 节点之间通过网络连接,所以可能存在不确定性和消息丢失
- 程序之间不共享内存or时钟
那么,
- 每个节点同时运行程序
- 信息本地化:节点能较快访问本地的信息,而全局的信息有可能凹凸了。
- 节点有可能失灵(Fail)和恢复
- 消息可能延迟或者丢失,消息丢失和节点失灵这两个蛮难区分
- 节点之间的时间不同步
系统模型就是:
对分布式系统实现的环境和设施的基本假设。
一个强壮的系统模型做最少的假设,其算法容错能力出众。而较弱的系统模型,假设更多,但是实现起来可能更加容易理解。比如假设节点从来不失灵,那么算法不就很简单咯,但是写出来就没考虑节点失灵的错误处理了。
系统模型中的节点(Nodes)
节点上提供了计算和储存资源。
- 可执行程序
- 存储数据到内存(失灵丢失)和磁盘(失灵不丢失)
- 本地时钟
这里的节点,一般系统都假设,要么失灵(Fail),就是完全crash;要么正常。还有一种假设是拜占庭将军问题。就是说节点失灵不是完全crash,而是发送一些错误信息。后者比较少见,暂时假设不会发生。
节点之间的通信的假设
通信链路连接不同的节点,允许消息相互传播。对通信的假设不多。这里主要是区分下节点失灵(Fail)和网络分割(Network Partition)。

左边是节点失灵,右边是网络分割。很好理解。
一些算法会假设网络通信总是可靠的。不过总体来说,我们还是认为网络不可靠,消息会丢失和延迟。
时间和序列的假设
不同节点接受到的消息序列可能是完全不同的。我们可以假设所有节点上的时间都完全一致,或者,做如下假设。
- 同步系统模型 假设所有node的时序都是一样的。消息总是可以在一定时间内传递。
- 异步系统模型 时序不可靠
显然异步系统模型更加接近真实时间,同时更加难以实现。
-----------------------核心内容(必考,敲黑板)----------------------------
一致性问题(The Consensus problem)
多台计算机(或者节点)达到一致表明:
- 共同同意(Agreement):每个进程(Process,这里就是指独立运行分布式程序的节点)必须同意某值(Agree on some value)。
- 完整性(Integrity):每个进程都选择同意某值。同时,如果它们都选择同意某值,那么该值一定是其中某些进程提出的。
- 可终结(Termination):所有的进程最终都选择某一值。
- 有效性(Validity):如果所有正确的进程都提出某值,那么正确的进程将决定该值。
FLP impossibility result
假设如下:
- 节点 Fail by crash (不会出现拜占庭将军问题)
- 网络可靠
- 异步系统模型 消息可能无限delay
在上面的假设下,FLP 表明,
即使消息永远不会丢失,即使最多只有一个进程失效(Crash),在异步系统模型下,也不存在一个确定性的分布式算法。
假设存在这种算法,那么任意延迟某消息(在异步系统模型中是允许的),在这段时间内该算法无法让进程确定选择某值。我也不是太理解这个解释。所以放下原文。
This result means that there is no way to solve the consensus problem under a very minimal system model in a way that cannot be delayed forever. The argument is that if such an algorithm existed, then one could devise an execution of that algorithm in which it would remain undecided ("bivalent") for an arbitrary amount of time by delaying message delivery - which is allowed in the asynchronous system model. Thus, such an algorithm cannot exist.
FLP 不可能结果表明,我们需要在异步系统模型中做折中。在解决一致性问题的时候,当消息没办法保证传递,算法需要放弃safety或者livness。 这里原文中使用的safety可能是指consistency,liveness 则是availability。
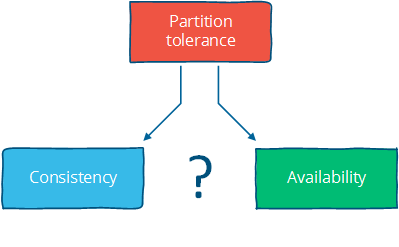
CAP理论
该理论有三个性质。
- 一致性(Consistency):所有节点在同一时刻看到同样的值(注意这里指的强一致性)
- 可用性(Availability):某些节点失效并不影响剩余节点运行
- 对网络分割容错(Partition tolerance):即使因为网络分割或者节点失效造成的消息丢失,系统正常运行
上面三个性质,只有两个可以同时满足。如下图。

同时满足三个性质的系统是不存在的。
比如你要强一致,并且保证高可用性,任何节点失效系统都不失效,那么对网络分割就没办法容忍了,每条消息都不能丢失。
- CA(Consistency + Availability). 例如严格全法定人数协议,例如two-phase commit。 GFS是典型的2PC。
- CP(Consistency + Partition tolerance). 例如大多数法定人数协议,如果发生Partition,包含较少node的部分将不可用。例如Paxos。VMware的 vSAN 作为分布式存储系统,也属于这类应用。
- AP (Availibity + Partition tolerance). 弱一致系统。例如Dynamo。
CA和CP都是强一致系统。差别是CA是没有办法handle网络分割的。而CP在一个2n+1的系统中容忍n个节点失灵。
CA系统没办法区分是网络问题还是节点问题,所以遇到消息丢失就只有停止write,以防止divergence(一份copy四处不同)。
CP系统通过在Partition两处构建不对称node数,只保留节点多的那部分Partition,节点少的那部分就处于不可用状态,不允许write。
另一个角度来看CAP系统的话,我们始终要保证对网络分割的容错,
那只有两种选择了。要么实现强一致,放弃部分可用性(of minor partition);要么实现弱一致,保证可用性(那么在不同Partition,在同一时刻可能取到不同的值)
所以说,一致性和可用性是此消彼长的关系,是矛盾的统一体。强一致的设计要求,让我们不得不放弃可用性,因为在发生网络分割的时候,我们不可能在多个Partition还继续write,使不同Partition出现不一致。
强一致也是性能的敌人。要求每个节点都得到update,那么对普通操作,代价是很大的。
如果我们在网络分割发生时,坚持可用性,那么强一致是不可能的。当然,一致性模型不是只有强一致一种,我们还可以允许其他选择,比如:
Client-centric consistency models
Eventual consistency

 浙公网安备 33010602011771号
浙公网安备 33010602011771号