
[分布式系统学习]阅读笔记 Distributed systems for fun and profit 之一 基本概念
因为工作的原因,最近打算看一些分布式学习的资料。其中这个http://book.mixu.net/distsys/就是一篇非常适合分布式入门的介绍。
这个短小的材料有下面5个小的章节,图文并茂,也没有太难的概念,非常推荐。
- 基础知识。主要是一些基本概念,例如可扩展性(scalability),可用性(availability)(马上就要写成bilibili了),性能(performance),容错(fault tolerance)。
- 上下层的抽象。CAP,敲黑板,这个是个很入门和重要的理论。
- 时间和顺序。强调了这两者在分布式系统里,对一致的重要性。
- Replication 副本(不是游戏里面的):防止divergence。这个divergence是一致性的死对头。divergence是什么,大概是set(k, v)以后,get(k) = v1, v2, ... vn 了吧。
- Replication 副本:容忍divergence。如果系统旨在实现weak consistence,那么可以接受一定程度的divergence。
- 最后作者专业地列出了所有引用的论文。真是好人。
现在我从第一章做个笔记。(年龄大了,这年头不做笔记不行啊。。。)
我比较喜欢作者的风格,每次开篇或者强调的地方都用鲜艳的颜色和醒目字号标记出来。比如第一章的导言:
Distributed programming is the art of solving the same problem that you can solve on a single computer using multiple computers.
为什么要能用一台电脑完成的事情,我们有时候需要用多台电脑来做呢?
因为一台电脑的资源往往有限。随着问题规模增加,我们升级单台电脑的硬件都可能无法完成任务。那么为什么需要分布式系统呢?
我们的目标:可扩展性
数一数房间里面有多少人很简单,但是要计算全国的人口就非常困难了。作者给可扩展性下了下面的定义。
可扩展性就是某系统,网络或者进程利索能力地处理不断增长的工作量的能力,或者自身扩大以处理这种增长的能力。
性能(performace)/延时(latency) 不解释了大家都懂。不过作者这里给了个比喻蛮有趣:
延时就是存在但未发生。比如你被某空气传染的丧尸病毒感染了。延时就是你被感染的时间和你变成丧尸的时间差。又比如,延时可以是一个写操作发生到被读者看到的时间。
可用性(availability)/容错(fault tolerance)
这是分布式系统的第二个特点。可用性表示,有多少时间某系统是能正常工作的。分布式系统能够通过把很多不可靠的组件合在一起,在之上构建一个可靠的系统。
可用性也可以表示成:
Availability = uptime / (uptime + downtime)
那啥是容错呢?系统在发生错误的情况下正常工作的能力。容错主要的问题就是,定义你能想到的错误,然后进行系统or算法设计来容忍它们。高可用性和容错是分布式系统的对使用者的承诺。
在分布式系统中,是什么导致我们没法达成上面的目标?
- 单个节点的数量
- 节点之间的距离
抽象和模型
抽象让我们忽略一些真实世界的繁杂,从而把注意力集中在本质问题上。模型则是抽象的产物,描述分布式系统的关键属性。这个入门教程将要介绍下吗几个分布式模型的类型:
- 系统模型(异步/同步)
- 容错模型(crash-fail, paritions, 拜占庭)
- 一致性模型(强/弱一致性)
其实这些抽象和模型的建立,就是一个目标,让分布式系统表现得像“一个单节点的系统”。内部分布和表现集中,这是一个此消彼长的矛盾,给我们实现一个分布式系统造成了很多困难。如果一个系统并不做强烈地“表现得像单个系统”(高可用性和容错)
这样的承诺,那么性能会变得很好。
设计技巧:划分(Partition)和副本(Replicate)
我们的数据怎么分布在不同节点上,这是个问题。要让计算进行,我们需要定位数据并对他们进行操作。数据的操作有两种方式:
- Partition
- Replicate
Partition就是把我们的数据集打撒成不同几份,分开存储。而replicate则是把数据复制多份,分开存储。如下图(再次喜欢这个画风)
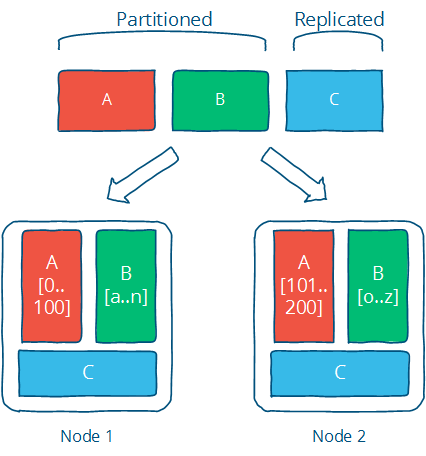
这个在存储里面的应用就是RAID0/1了,我们叫Stripe和Mirror。
Replication 允许我们实现可扩展性,性能和容错。不过这也是许多问题的源泉,因为我们面临的是多个独立的数据拷贝,他们需要在多台机器上保持同步。这就是说要实现某种一致性模型。
一致性模型的实现蛮重要。好的一致性模型对程序员(这里应该指的是Client,分布式系统的调用者)来说语义清楚,容易理解,同时也满足业务和设计的目标,例如高可用性或者强一致性。
仅有强一致模型允许你像使用单节点系统一样。其他一致性模型或多或少暴露了一些内部的实现。不过弱一致系统可以提高低延时和更高的可用性,并不一定难以理解,各有秋色罢了。
Summary
这章除了讲解一些概念,反复强调的一个问题就是如果解决在多台机器上实现一台机器的事务的矛盾。如果你暴露更多细节,表现得很”分布“,那么你性能就更好,但是理解起来可能会比较难。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号