出自https://www.brinnatt.com/social/%e7%ac%ac-4-%e7%ab%a0-netperf-%e7%bd%91%e7%bb%9c%e6%b5%8b%e8%af%95/
Netperf 是由惠普公司开发的,测试网络栈。即测试不同类型的网络性能的 benchmark 工具,大多数网络类型 TCP/UPD 端对端的性能,得到网络上不同类型流量的性能参数。Netperf 根据应用的不同可以进行不同模式的网络性能测试,即:批量数据传输模式和请求/应答模式。
Netperf 测试结果所反映的是一个系统能够以多快的速度向另外一个系统发送数据,以及另外一个系统能够以多快的速度接收数据。
工作原理:
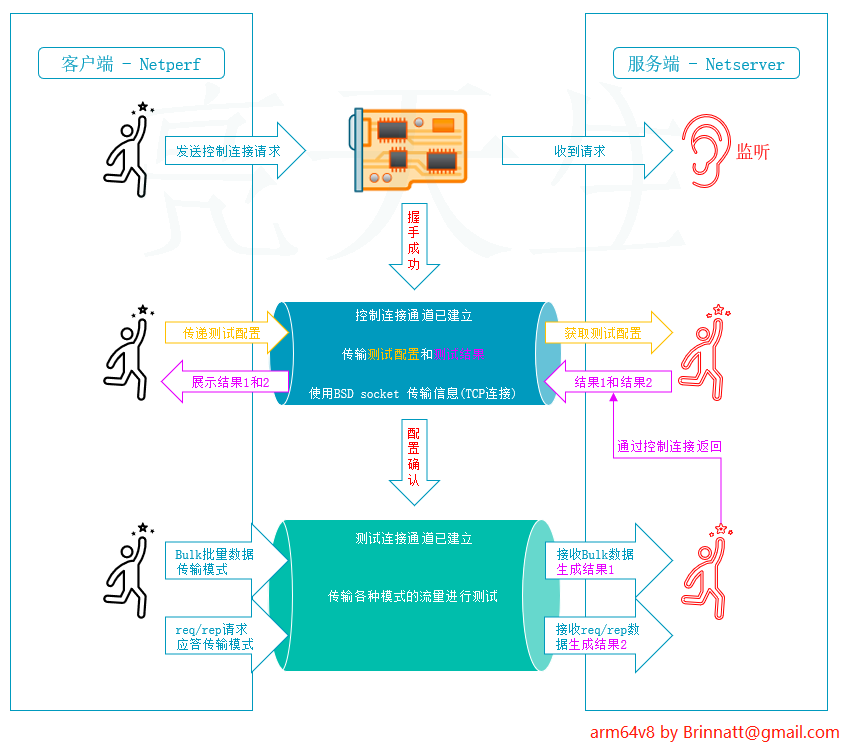
Netperf 工具以 client/server 方式工作。server 端是 netserver,用来侦听来自 client 端的连接,client 端是 netperf,用来向 server 发起网络测试。在 client 与 server 之间,首先建立一个控制连接,传递有关测试配置的信息,以及测试的结果;在控制连接建立并传递了测试配置信息以后,client 与 server 之间会再建立一个测试连接,进行来回传递特殊的流量模式,以测试网络的性能。
我自制了一个比较生动点的图描述这个原理过程:
网络性能测量的五项指标:
- 可用性(availability):测试网络性能的第一步是确定网络是否正常工作,最简单的方法是使用 ping 命令。通过向远端的机器发送 icmp echo request,并等待接收 icmp echo reply 来判断远端的机器是否连通,网络是否正常工作。
- Ping 命令有非常丰富的命令选项,比如 -c 可以指定发送 echo request 的个数,-s 可以指定每次发送的 ping 包大小 。
- 响应时间(response time):ping 命令的 echo request/reply 一次往返所花费时间就是响应时间。有很多因素会影响到响应时间,如网段的负荷、网络主机的负荷、广播风暴、工作不正常的网络设备等等。
- 网络利用率(network utilization):是指网络被使用的时间占总时间(即被使用的时间+空闲的时间)的比例。
- 网络吞吐量(network throughput):是指在某个时刻,在网络中的两个节点之间,提供给网络应用的剩余带宽。网络吞吐量非常依赖于当前的网络负载情况。因此为了得到正确的网络吞吐量,最好在不同时间(一天中的不同时刻,或者一周中不同的天)分别进行测试,只有这样才能得到对网络吞吐量的全面认识。
- 网络带宽容量(network bandwidth capacity):与网络吞吐量不同,网络带宽容量指的是在网络的两个节点之间的最大可用带宽。这是由组成网络设备的能力所决定的。
4.1、Netperf 安装
官网:https://hewlettpackard.github.io/netperf/
下载地址:https://github.com/HewlettPackard/netperf
[root@arm64v8 ~]# git clone https://github.com/HewlettPackard/netperf.git
正克隆到 'netperf'...
remote: Enumerating objects: 5252, done.
remote: Counting objects: 100% (324/324), done.
remote: Compressing objects: 100% (113/113), done.
remote: Total 5252 (delta 232), reused 235 (delta 210), pack-reused 4928
接收对象中: 100% (5252/5252), 16.83 MiB | 976.00 KiB/s, 完成.
处理 delta 中: 100% (3928/3928), 完成.
[root@arm64v8 ~]#
[root@arm64v8 ~]# yum install automake autoconf texinfo gcc -y
[root@arm64v8 ~]# cd netperf/
[root@arm64v8 netperf]# ./autogen.sh
configure.ac:28: installing './compile'
[root@arm64v8 netperf]#
[root@arm64v8 netperf]# ./configure
[root@arm64v8 netperf]# make && make install- 默认安装路径是 /usr/local 下的各目录,安装完以后,会生成两个工具 netserver 和 netperf。
- 注意:测试过程中服务端和客户端都需要安装 netperf,服务端使用 netserver 启动后,客户端就可以使用 netperf 来测试网络的性能。
4.2、Netperf 语法
服务端
服务器端启动服务,执行 netserver 命令:
[root@brinnatt ~]# netserver
Starting netserver with host 'IN(6)ADDR_ANY' port '12865' and family AF_UNSPEC-
默认情况下 netserver 开启端口号为 12865,可以通过以下命令指定服务端口(如果服务端指定端口,则客户端也需要指定服务器端口):
[root@brinnatt ~]# netserver -D -p 8888
客户端
客户端执行 netperf 相关命令即可,netperf 语法格式为:
Usage: netperf [global options] -- [test options]
全局命令行参数包括如下选项:
| 参数 | 说明 |
|---|---|
| -H host | 指定远端运行 netserver 的 server IP 地址 |
| -l testlen | 指定测试的时间长度(秒) |
| -t testname | 指定进行的测试类型(TCP_STREAM,UDP_STREAM,TCP_RR,TCP_CRR,UDP_RR) |
局部参数包括如下选项:
| 参数 | 说明 |
|---|---|
| -s size | 设置本地系统的 socket 发送与接收缓冲大小 |
| -S size | 设置远端系统的 socket 发送与接收缓冲大小 |
| -m size | 设置本地系统发送测试分组的大小 |
| -M size | 设置远端系统接收测试分组的大小 |
| -D | 对本地与远端系统的 socket 设置 TCP_NODELAY 选项 |
| -r req,resp | 设置 request 和 reponse 分组的大小 |
查看 linux 操作系统 socket 缓冲区大小的默认值,在 /proc 虚拟文件系统中有配置:
tcp
[root@arm64v8 ~]# cat /proc/sys/net/ipv4/tcp_wmem
4096 16384 4194304
// 第一个表示最小值,第二个表示默认值,第三个表示最大值。
// 4kb, 16kb, 4M
[root@arm64v8 ~]# cat /proc/sys/net/ipv4/tcp_rmem
4096 131072 6291456
// 第一个表示最小值,第二个表示默认值,第三个表示最大值。
// 4kb, 128kb 6M- 综上所述,读缓冲区默认为 128kb,写缓冲区默认为 16kb;读缓冲区最大为 6M,写缓冲区最大为 4M。
udp
[root@arm64v8 ~]# cat /proc/sys/net/core/rmem_max
2097152
[root@arm64v8 ~]# cat /proc/sys/net/core/wmem_max
2097152
[root@arm64v8 ~]# cat /proc/sys/net/core/rmem_default
2097152
[root@arm64v8 ~]# cat /proc/sys/net/core/wmem_default
20971524.3、Netperf 测试
服务端 IP 地址和网卡信息:
[root@brinnatt ~]# ip -4 add show dev enp11s0f0
3: enp11s0f0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
inet 10.47.73.2/24 brd 10.47.73.255 scope global enp11s0f0
valid_lft forever preferred_lft forever
[root@brinnatt ~]#
[root@brinnatt ~]# ethtool enp11s0f0
Settings for enp11s0f0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supported pause frame use: Symmetric
Supports auto-negotiation: Yes
Supported FEC modes: Not reported
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised pause frame use: Symmetric
Advertised auto-negotiation: Yes
Advertised FEC modes: Not reported
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 1
Transceiver: internal
Auto-negotiation: on
MDI-X: on (auto)
Supports Wake-on: pumbg
Wake-on: g
Current message level: 0x00000007 (7)
drv probe link
Link detected: yes
[root@brinnatt ~]# 客户端 IP 地址和网卡信息:
[root@arm64v8 ~]# ip -4 add show dev enp11s0f0
3: enp11s0f0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
inet 10.47.73.11/24 brd 10.47.73.255 scope global noprefixroute enp11s0f0
valid_lft forever preferred_lft forever
[root@arm64v8 ~]#
[root@arm64v8 ~]# ethtool enp11s0f0
Settings for enp11s0f0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supported pause frame use: Symmetric
Supports auto-negotiation: Yes
Supported FEC modes: Not reported
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised pause frame use: Symmetric
Advertised auto-negotiation: Yes
Advertised FEC modes: Not reported
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 1
Transceiver: internal
Auto-negotiation: on
MDI-X: on (auto)
Supports Wake-on: pumbg
Wake-on: g
Current message level: 0x00000007 (7)
drv probe link
Link detected: yes
[root@arm64v8 ~]#4.3.1、批量网络流量的性能测试
批量数据传输典型的例子有 ftp 和其它类似的网络应用(即一次传输整个文件)。根据使用传输协议的不同,批量数据传输又分为 TCP 批量传输和 UDP 批量传输。
4.3.1.1、TCP_STREAM 测试
Netperf 缺省情况下进行 TCP 批量传输,即 -t TCP_STREAM。测试过程中 netperf 向 netserver 发送批量的 TCP 数据分组,以确定数据传输过程中的吞吐量。
-
测试 60 秒内 TCP 批量数据传输表现
[root@arm64v8 ~]# netperf -t TCP_STREAM -H 10.47.73.2 -l 60 MIGRATED TCP STREAM TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 10.47.73.2 () port 0 AF_INET Recv Send Send Socket Socket Message Elapsed Size Size Size Time Throughput bytes bytes bytes secs. 10^6bits/sec 87380 16384 16384 60.02 925.22 [root@arm64v8 ~]#
-
- 从上面两个示例中可以看出,当减小测试分组的大小为 4096 和增加测试分组的大小为 131072 后,吞吐量几乎没有变化。 由此可以说明网络中间的路由器不存在缓冲区的问题。
4.3.1.2、UDP_STREAM 测试
用来测试进行 UDP 批量传输时的网络性能。需要特别注意的是,此时测试分组的大小不得大于 socket 的发送与接收缓冲大小,否则 netperf 会报错:
-
测试 60 秒内 UDP 批量数据传输表现
[root@arm64v8 ~]# netperf -t UDP_STREAM -H 10.47.73.2 -l 60 MIGRATED UDP STREAM TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 10.47.73.2 () port 0 AF_INET Socket Message Elapsed Messages Size Size Time Okay Errors Throughput bytes bytes secs # # 10^6bits/sec 2097152 65507 60.00 111039 0 969.84 229376 60.00 66092 577.26 [root@arm64v8 ~]#
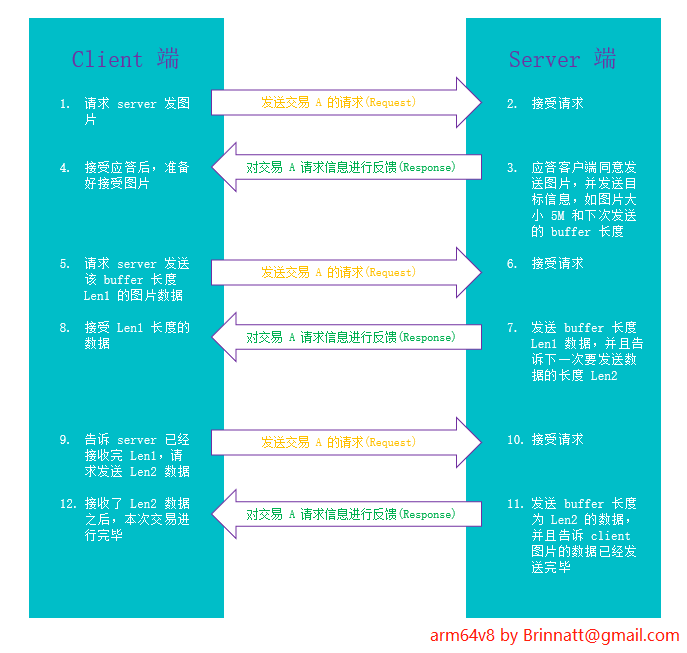
4.3.2、测试请求/应答网络流量的性能
另一类常见的网络流量类型是应用在 client/server 结构中的 request/response 模式。在每次交易(transaction)中,client 向 server 发出小的查询分组,server 接收到请求,经处理后返回大的结果数据。如下图所示:
4.3.2.1、TCP_RR 测试
TCP_RR 方式的测试对象是多次 TCP request 和 response 的交易过程,但是它们发生在同一个 TCP 连接中,这种模式常常出现在数据库应用中。数据库的 client 程序与 server 程序建立一个 TCP 连接以后,就在这个连接中传送数据库的多次交易过程。
-
测试 60 秒内 TCP_RR 数据传输表现
[root@arm64v8 ~]# netperf -t TCP_RR -H 10.47.73.2 -l 60 MIGRATED TCP REQUEST/RESPONSE TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 10.47.73.2 () port 0 AF_INET : first burst 0 Local /Remote Socket Size Request Resp. Elapsed Trans. Send Recv Size Size Time Rate bytes Bytes bytes bytes secs. per sec 16384 131072 1 1 60.00 10203.70 16384 87380 [root@arm64v8 ~]#
-
- 从结果中可以看出,由于 request/reponse 分组的大小增加了,导致了交易率明显的下降。
- 注:相对于实际的系统,这里交易率的计算没有充分考虑到交易过程中的应用程序处理时延,因此结果往往会高于实际情况。
4.3.2.2、TCP_CRR 测试
与 TCP_RR 不同,TCP_CRR 为每次交易建立一个新的 TCP 连接。最典型的应用就是 HTTP,每次 HTTP 交易是在一条单独的 TCP 连接中进行的。因此需要不停地建立新的 TCP 连接,并且在交易结束后断开 TCP 连接,交易率一定会受到很大的影响。
-
测试 60 秒内 TCP_CRR 数据传输表现
[root@arm64v8 ~]# netperf -t TCP_CRR -H 10.47.73.2 -l 60 MIGRATED TCP Connect/Request/Response TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 10.47.73.2 () port 0 AF_INET Local /Remote Socket Size Request Resp. Elapsed Trans. Send Recv Size Size Time Rate bytes Bytes bytes bytes secs. per sec 16384 131072 1 1 60.00 5011.02 16384 87380 [root@arm64v8 ~]#
4.3.2.3、UDP_RR 测试
UDP_RR 方式使用 UDP 分组进行 request/response 的交易过程。由于没有 TCP 连接所带来的负担,所以我们推测交易率会有一定的提升。
-
测试 60 秒内 UDP_RR 数据传输表现
[root@arm64v8 ~]# netperf -t UDP_RR -H 10.47.73.2 -l 60 MIGRATED UDP REQUEST/RESPONSE TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 10.47.73.2 () port 0 AF_INET : first burst 0 Local /Remote Socket Size Request Resp. Elapsed Trans. Send Recv Size Size Time Rate bytes Bytes bytes bytes secs. per sec 2097152 2097152 1 1 60.00 20055.03 229376 229376 [root@arm64v8 ~]#
-
- 从结果中可以看出,如果发送和接收使用 1024 bytes(大包)的话会对性能产生一定影响。
A、附录
A1、iperf 测试
iPerf 系列工具执行的是实时测量,以确定 IP 网络上可实现的最大带宽。它支持计时、协议以及缓存等各种参数的搭配。每次测试都会报告吞吐率、丢包率以及其它参数表现。
iPerf 常用的版本有 iPerf2 和 iPerf3。iPerf3 在 iPerf2 的基础上新增了一些功能,例如发送方/接收方角色互换,以 JSON 格式输出结果,零拷贝方式传输数据等等。也去掉了 iPerf2 中所支持少许功能,例如双向测试,以逗号为分隔符输出结果等。
实际上根据官方解释,iPerf3 是一个从头开始的新实现,其目标是创建一个更小、更简单的代码库,以及一个可以在其他程序中使用的功能库版本。注意 iPerf3 并不向后兼容 iPerf2,而且官方不再支持 iPerf2,不过有一些爱好者也在维护 iPerf2。总之更多最新信息请参考 iPerf3。
官方地址:https://software.es.net/iperf/
源码托管地址:https://github.com/esnet/iperf
源码下载地址:https://downloads.es.net/pub/iperf/
A2、iPerf3 安装
[root@arm64v8 ~]# tar xf iperf-3.10.1.tar.gz
[root@arm64v8 ~]# cd iperf-3.10.1/
[root@arm64v8 iperf-3.10.1]#
[root@arm64v8 iperf-3.10.1]# ./configure
[root@arm64v8 iperf-3.10.1]# make
[root@arm64v8 iperf-3.10.1]# make installA3、iPerf3 测试
iPerf3 中的可选参数比较多,具体可以参见其用户手册:https://iperf.fr/iperf-doc.php
A3.1、iPerf3 工作模式和参数
iPerf3 工作时需要指定 Server 模式或 Client 模式,通过不同的参数来区别(-s 和 -c)。iPerf3 所支持的功能也都通过设置不同的参数来实现。iPerf3 的参数分为 3 类:通用参数、Server 端参数、Client 端参数。通用参数为 Server 端和 Client 端都可以使用的参数。
通用参数:
-p, --port #: Server 端监听、Client 端连接的端口号,默认是5201端口;
-f, --farmat [k|m|g|K|M|G]: 指定带宽输出单位,"[k|m|g|K|M|G]"分别表示以Kbits, Mbits, Gbits, KBytes, MBytes,GBytes显示输出结果。
默认是Mbits。
eg:iperf3 -c 192.168.12.168 -f M
-i, --interval #: 指定每次报告之间的时间间隔,单位为秒。
eg:iperf3 -c 192.168.12.168 -i 2
-F, --file name: 指定文件作为数据流进行带宽测试。
如果使用在 Client 端,发送该文件用作测试;
如果使用在 Server 端,则是将数据写入该文件,而不是丢弃;
eg:iperf3 -c 192.168.12.168 -F web-ixdba.tar.gz
-A, --affinity n/n,m: CPU亲和性,可以将具体的iperf3进程绑定对应编号的逻辑CPU,避免iperf3进程在不同的CPU间调度。
-B, --bind host: 绑定指定的网卡接口;
-V, --verbose: 运行时输出更多细节;
-J, --json: 运行时以 JSON 格式输出结果;
--logfile file: 输出到文件;
-d, --debug: 以 debug 模式输出结果;
-v, --version: 显示版本信息并退出;
-h, --help: 显示帮助信息并退出。Server 端参数:
-s, --server: 以 Server 模式运行;
-D, --daemon: 在后台以守护进程运行;
-I, --pidfile file: 指定 pid 文件;
-1, --one-off: 只接受 1 次来自 Client 端的测试,然后退出。Client 端参数:
-c, --client: 以 Client 模式运行,并指定 Server 端的地址;
-u, --udp: 表示采用UDP协议发送报文,不带该参数表示采用TCP协议;
-b, --bandwidth #[KMG][/#]: 限制测试带宽。UDP 默认为 1Mbit/秒,TCP 默认无限制;
-t, --time #: 以时间为测试结束条件进行测试,默认为 10 秒;
-n, --bytes #[KMG]: 以数据传输大小为测试结束条件进行测试;
-k, --blockcount #[KMG]: 以传输数据包数量为测试结束条件进行测试;
-l, --len #[KMG]: 读写缓冲区的长度,TCP 默认为 128K,UDP 默认为 8K;
--cport: 指定 Client 端运行所使用的 TCP 或 UDP 端口,默认为临时端口;
-P, --parallel #: 测试数据流并发数量;
-R, --reverse: 反向模式运行(Server 端发送,Client 端接收);
-w, --window #[KMG]: 设置套接字缓冲区大小,TCP 模式下为窗口大小;
-C, --congestion: 设置 TCP 拥塞控制算法(仅支持 Linux 和 FreeBSD );
-M, --set-mss #: 设置 TCP/SCTP 最大分段长度(MSS,MTU 减 40 字节);
-N, --no-delay: 设置 TCP/SCTP no delay,屏蔽 Nagle 算法;
-4, --version4: 仅使用 IPv4;
-6, --version6: 仅使用 IPv6;
-S, --tos N: 设置 IP 服务类型(TOS,Type Of Service);
-L, --flowlabel N: 设置 IPv6 流标签(仅支持 Linux);
-Z, --zerocopy: 使用 “zero copy”(零拷贝)方法发送数据;
-O, --omit N: 忽略前 n 秒的测试;
-T, --title str: 设置每行测试结果的前缀;
--get-server-output: 从 Server 端获取测试结果;
--udp-counters-64bit: 在 UDP 测试包中使用 64 位计数器(防止计数器溢出)。iPerf3 功能十分强大,支持的参数特别多。但是在实际使用中,并不需要同时使用这么多参数。使用时,根据实际需求来设置关键参数就可以了。
注意:iPerf3 版本迭代比较快,每个版本的参数多多少少有一些区别,不过针对整体使用没有任何障碍,如果设置参数时,有一些问题,查看 man iperf3 即可解决。
A3.2、iPerf3 用例
A3.2.1、环境准备
Server 端 IP 地址:10.47.73.2
Client 端 IP 地址:10.47.73.11
A3.2.2、测试 TCP 吞吐量
-
Server 端开启 iperf3 的服务器模式,指定 TCP 端口:
[root@brinnatt ~]# iperf3 -s -i 10 -p 478 ----------------------------------------------------------- Server listening on 478 (test #1) -----------------------------------------------------------
A3.2.3、测试 UDP 吞吐量
带宽测试通常采用 UDP 模式,因为能测出极限带宽、时延抖动、丢包率。
在进行测试时,首先以链路理论带宽作为数据发送速率进行测试。例如,从客户端到服务器之间的链路的理论带宽为 1000Mbps,先用 -b 1000M 进行测试,得到测试结果(包括实际带宽,时延抖动和丢包率)。再以实际带宽(假如 956 Mbits/sec)作为数据发送速率进行测试,会发现时延抖动和丢包率比第一次好很多,重复测试几次,就能得出稳定的实际带宽。
-
Server 端开启 iperf3 的服务器模式
[root@brinnatt ~]# iperf3 -s -i 10 -p 478
- Jitter 为抖动,在连续传输中的平滑平均值差。
- Lost 为丢包数量。
- Total Datagrams 为传输总包数量。
再以 956 Mbits/sec 进行测试,如下:
[root@arm64v8 ~]# iperf3 -u -c 10.47.73.2 -b 956M -t 60 -p 478
......
[ 5] 58.00-59.00 sec 114 MBytes 956 Mbits/sec 82537
[ 5] 59.00-60.00 sec 114 MBytes 956 Mbits/sec 82503
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Jitter Lost/Total Datagrams
[ 5] 0.00-60.00 sec 6.68 GBytes 956 Mbits/sec 0.000 ms 0/4951591 (0%) sender
[ 5] 0.00-60.00 sec 6.68 GBytes 956 Mbits/sec 0.016 ms 0/4951575 (0%) receiver
iperf Done.A4、生产测试
A4.1、硬件环境
| 配置 | x86 | arm64-single | arm64-double |
|---|---|---|---|
| CPU | X86(Gold 6138) | arm64-64core | arm64-128core |
| MEM | 256G | 256G | 256G |
| SYS | Centos8.4 | Centos8.4 | Centos8.4 |
| NET CARD | Intel Corporation I350 Gigabit | Intel Corporation I350 Gigabit | Intel Corporation I350 Gigabit |
A4.2、测试结果
| 协议 | X86(Gold 6138) | arm64-64core | arm64-128core |
|---|---|---|---|
| tcp 传输速率 | 994 Mbits/sec | 995 Mbits/sec | 992 Mbits/sec |
| udp 传输速率 | 948 Mbits/sec | 944 Mbits/sec | 956 Mbits/sec |
-
查看 netserver 命令帮助:
[root@brinnatt ~]# netserver -h Usage: netserver [options] Options: -h Display this text -D Do not daemonize -d Increase debugging output -f Do not spawn chilren for each test, run serially -L name,family Use name to pick listen address and family for family -N No debugging output, even if netperf asks -p portnum Listen for connect requests on portnum. -4 Do IPv4 -6 Do IPv6 -v verbosity Specify the verbosity level -V Display version information and exit -Z passphrase Expect passphrase as the first thing received [root@brinnatt ~]# -
- 从 netperf 的结果输出中,我们可以知道以下的一些信息:
- 远端系统(即 server)使用大小为 87380 字节的 socket 接收缓冲;
- 本地系统(即 client)使用大小为 16384 字节的 socket 发送缓冲;
- 向远端系统发送的测试分组大小为 16384 字节;
- 测试的时间为 60 秒。
- 吞吐量的测试结果为 925.22 Mbits/秒。
- 在缺省情况下,netperf 向 netserver 发送的测试分组大小为本地系统所使用的 socket 发送缓冲大小,测试时间为 10 秒。
- 如果怀疑路由器由于缺乏足够的缓冲区空间,使得转发大的分组时存在问题,就可以增加测试分组(-m)的大小,以观察吞吐量的变化。
- 然后减小测试分组的大小,如果吞吐量有了较大的提升,则说明在网络中间的路由器确实存在缓冲区的问题。
- 从 netperf 的结果输出中,我们可以知道以下的一些信息:
-
测试分组为 4096,观察吞吐量的变化
[root@arm64v8 ~]# netperf -t TCP_STREAM -H 10.47.73.2 -l 60 -- -m 131072 MIGRATED TCP STREAM TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 10.47.73.2 () port 0 AF_INET Recv Send Send Socket Socket Message Elapsed Size Size Size Time Throughput bytes bytes bytes secs. 10^6bits/sec 87380 16384 131072 60.03 925.22 [root@arm64v8 ~]# netperf -t TCP_STREAM -H 10.47.73.2 -l 60 -- -m 4096 MIGRATED TCP STREAM TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 10.47.73.2 () port 0 AF_INET Recv Send Send Socket Socket Message Elapsed Size Size Size Time Throughput bytes bytes bytes secs. 10^6bits/sec 87380 16384 4096 60.02 925.21 -
- 测试结果说明:接收的 66092 少于发送的 111039,吞吐量也有差别
- UDP_STREAM 方式的结果中有两行测试数据:
- 第一行显示的是本地系统的发送统计,这里的吞吐量表示 netperf 向本地 socket 发送分组的能力,但是我们知道 UDP 是不可靠的传输协议,发送出去的分组数量不一定等于接收到的分组数量。
- 第二行显示的就是远端系统接收的情况,由于 client 与 server 通过交换机连接,远端系统的 socket 缓冲大小不同于本地系统的 socket 缓冲区大小,而且由于 UDP 协议的不可靠性,远端系统的接收吞吐量要远远小于发送出去的吞吐量。
-
不用大于系统默认的 socket 缓存,大于协调值 65507 一点点都报错,如下
[root@arm64v8 ~]# netperf -t UDP_STREAM -H 10.47.73.2 -l 60 MIGRATED UDP STREAM TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 10.47.73.2 () port 0 AF_INET Socket Message Elapsed Messages Size Size Time Okay Errors Throughput bytes bytes secs # # 10^6bits/sec 2097152 65507 60.00 124664 0 1088.85 229376 60.00 77182 674.13 [root@arm64v8 ~]# netperf -t UDP_STREAM -H 10.47.73.2 -l 60 -- -m 65508 MIGRATED UDP STREAM TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 10.47.73.2 () port 0 AF_INET send_data: data send error: Message too long (errno 90) netperf: send_omni: send_data failed: Message too long [root@arm64v8 ~]# -
- 从 netperf 的结果输出中可以看出:第一行显示本地系统的情况,第二行显示的是远端系统的信息,平均的交易率(transaction rate)为 10203.70 次/秒。
- 注意默认情况下每次交易中的 request 和 response 分组的大小都为 1 个字节,不具有实际意义。
-
通过使用 -r 参数测试
[root@arm64v8 ~]# netperf -t TCP_RR -H 10.47.73.2 -l 60 -- -r 128,8192 MIGRATED TCP REQUEST/RESPONSE TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 10.47.73.2 () port 0 AF_INET : first burst 0 Local /Remote Socket Size Request Resp. Elapsed Trans. Send Recv Size Size Time Rate bytes Bytes bytes bytes secs. per sec 16384 131072 128 8192 60.00 4454.73 16384 87380 [root@arm64v8 ~]# -
- 从结果中可以看出,每次重新建立 TCP 连接,效率明显下降。即使是使用 1 个字节的 request/response 分组,交易率也明显的降低了,只有 5011.02 次/秒。
-
通过使用 -r 参数测试
[root@arm64v8 ~]# netperf -t TCP_CRR -H 10.47.73.2 -l 60 -- -r 32,64 MIGRATED TCP Connect/Request/Response TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 10.47.73.2 () port 0 AF_INET Local /Remote Socket Size Request Resp. Elapsed Trans. Send Recv Size Size Time Rate bytes Bytes bytes bytes secs. per sec 16384 131072 32 64 60.00 4978.18 16384 87380 [root@arm64v8 ~]# -
- 交易率为 20055.03,高过 TCP_RR 的数值,也符合预期。如果出现了相反的结果,即交易率反而降低了,也不需要担心,因为这说明了在网络中,路由器或其它的网络设备对 UDP 采用了与 TCP 不同的缓冲区空间和处理技术。
-
通过使用 -r 参数测试
[root@arm64v8 ~]# netperf -t UDP_RR -H 10.47.73.2 -l 60 -- -r 1024,1024 MIGRATED UDP REQUEST/RESPONSE TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 10.47.73.2 () port 0 AF_INET : first burst 0 Local /Remote Socket Size Request Resp. Elapsed Trans. Send Recv Size Size Time Rate bytes Bytes bytes bytes secs. per sec 2097152 2097152 1024 1024 60.00 11076.18 229376 229376 [root@arm64v8 ~]# -
Client 端启动 iperf3 的客户端模式,连接服务端:
[root@arm64v8 ~]# iperf3 -c 10.47.73.2 -i 10 -t 60 -p 478 Connecting to host 10.47.73.2, port 478 [ 5] local 10.47.73.11 port 55976 connected to 10.47.73.2 port 478 [ ID] Interval Transfer Bitrate Retr Cwnd [ 5] 0.00-10.00 sec 1.10 GBytes 943 Mbits/sec 0 380 KBytes [ 5] 10.00-20.00 sec 1.10 GBytes 942 Mbits/sec 0 437 KBytes [ 5] 20.00-30.00 sec 1.10 GBytes 941 Mbits/sec 0 437 KBytes [ 5] 30.00-40.00 sec 1.10 GBytes 941 Mbits/sec 0 437 KBytes [ 5] 40.00-50.00 sec 1007 MBytes 844 Mbits/sec 2 667 KBytes [ 5] 50.00-60.00 sec 1.10 GBytes 942 Mbits/sec 0 667 KBytes - - - - - - - - - - - - - - - - - - - - - - - - - [ ID] Interval Transfer Bitrate Retr [ 5] 0.00-60.00 sec 6.47 GBytes 926 Mbits/sec 2 sender [ 5] 0.00-60.00 sec 6.46 GBytes 925 Mbits/sec receiver iperf Done. [root@arm64v8 ~]# -
- Interval 表示时间间隔。
- Transfer 表示时间间隔里面传输的数据量。
- Bitrate 表示时间间隔里的传输速率。
- Retr 表示重传次数
- Cwnd 表示窗口大小
-
测试多线程 TCP 吞吐量,以太网属于争用机制,多线程测试具有一定实际意义:
[root@arm64v8 ~]# iperf3 -c 10.47.73.2 -i 10 -t 60 -p 478 -P 30 -
进行上下行带宽测试(双向传输)
[root@arm64v8 ~]# iperf3 -c 10.47.73.2 -i 10 -t 60 -p 478 -P 30 -d -
Client 端启动 iperf3 的客户端模式,连接服务端
[root@arm64v8 ~]# iperf3 -u -c 10.47.73.2 -b 1000M -t 60 -p 478 ...... [ 5] 58.00-59.00 sec 114 MBytes 958 Mbits/sec 82723 [ 5] 59.00-60.00 sec 114 MBytes 958 Mbits/sec 82717 - - - - - - - - - - - - - - - - - - - - - - - - - [ ID] Interval Transfer Bitrate Jitter Lost/Total Datagrams [ 5] 0.00-60.00 sec 6.69 GBytes 958 Mbits/sec 0.000 ms 0/4960529 (0%) sender [ 5] 0.00-60.00 sec 6.68 GBytes 956 Mbits/sec 0.016 ms 6244/4960077 (0.13%) receiver iperf Done. -
- 通过跟上面对比,丢包率变成了 0,更接近真实带宽。
-
测试多线程 UDP 吞吐量
[root@arm64v8 ~]# iperf3 -u -c 10.47.73.2 -b 956M -t 60 -p 478 -P 30 -
- 如果没有指定发送方式,iPerf3 客户端只会使用单线程。
- 多线程得到的结果丢包率比较严重。
-
进行上下行带宽测试(双向传输)
[root@arm64v8 ~]# iperf3 -u -c 10.47.73.2 -b 956M -t 60 -p 478 -P 30 -d

 浙公网安备 33010602011771号
浙公网安备 33010602011771号