🏆【Alibaba中间件技术系列】「Sentinel技术专题」分布式系统的流量防卫兵的基本介绍(入门源码介绍)
推荐资料
Sentinel 是什么?
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
Sentinel 具有以下特征:
丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Apache Dubbo、gRPC、Quarkus 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。同时 Sentinel 提供 Java/Go/C++ 等多语言的原生实现。
完善的 SPI 扩展机制:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
Maven的pom中配置
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-core</artifactId>
<version>x.y.z</version>
</dependency>
main函数
public class Demo {
public static void main(String[] args) throws InterruptedException {
initFlowRules();
while (true) {
Thread.sleep(10);
Entry entry = null;
try {
entry = SphU.entry("HelloWorld");
/*您的业务逻辑 - 开始*/
System.out.println("hello world");
/*您的业务逻辑 - 结束*/
} catch (BlockException e1) {
/*流控逻辑处理 - 开始*/
System.out.println("block!");
/*流控逻辑处理 - 结束*/
} finally {
if (entry != null) {
entry.exit();
}
}
}
}
private static void initFlowRules(){
List<FlowRule> rules = new ArrayList<>();
FlowRule rule = new FlowRule();
rule.setResource("HelloWorld");
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
// Set limit QPS to 20.
rule.setCount(20);
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
}
介绍总结说明
- 当出现被阻塞和限流的情况会出现输出进入BlockException区域
- 没有被限流的场景会出现直接执行相关的操作业务逻辑。
自定义的rule
从demo中看,是由FlowRuleManager把规则load进来的:
FlowRuleManager.loadRules(rules);
点进去看,应该是注册了一堆listener然后告知他们配置有更新
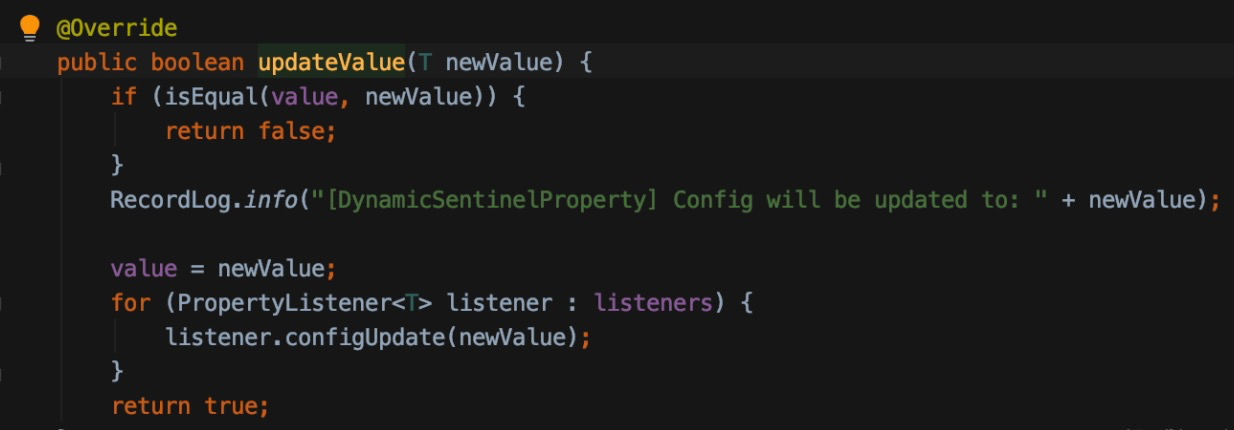
加载规则
demo中是通过新建
entry = SphU.entry(“HelloWorld”);

对资源名称“HelloWorld”包装了一下,然后跳进这个entry函数
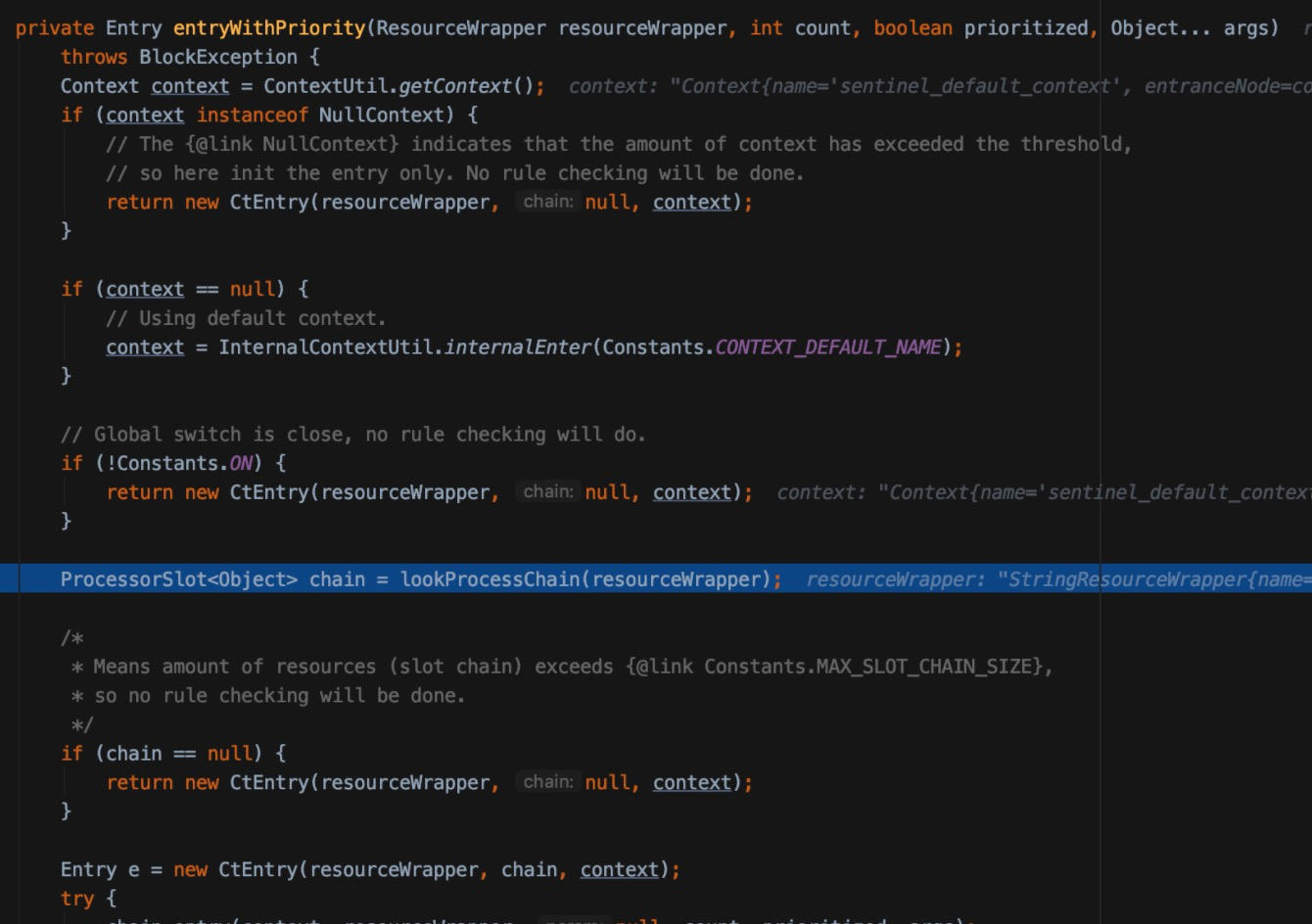
找一下处理链(责任链模式),这里是DefaultProcessorSlotChain,然后chain.entry再跳进去:
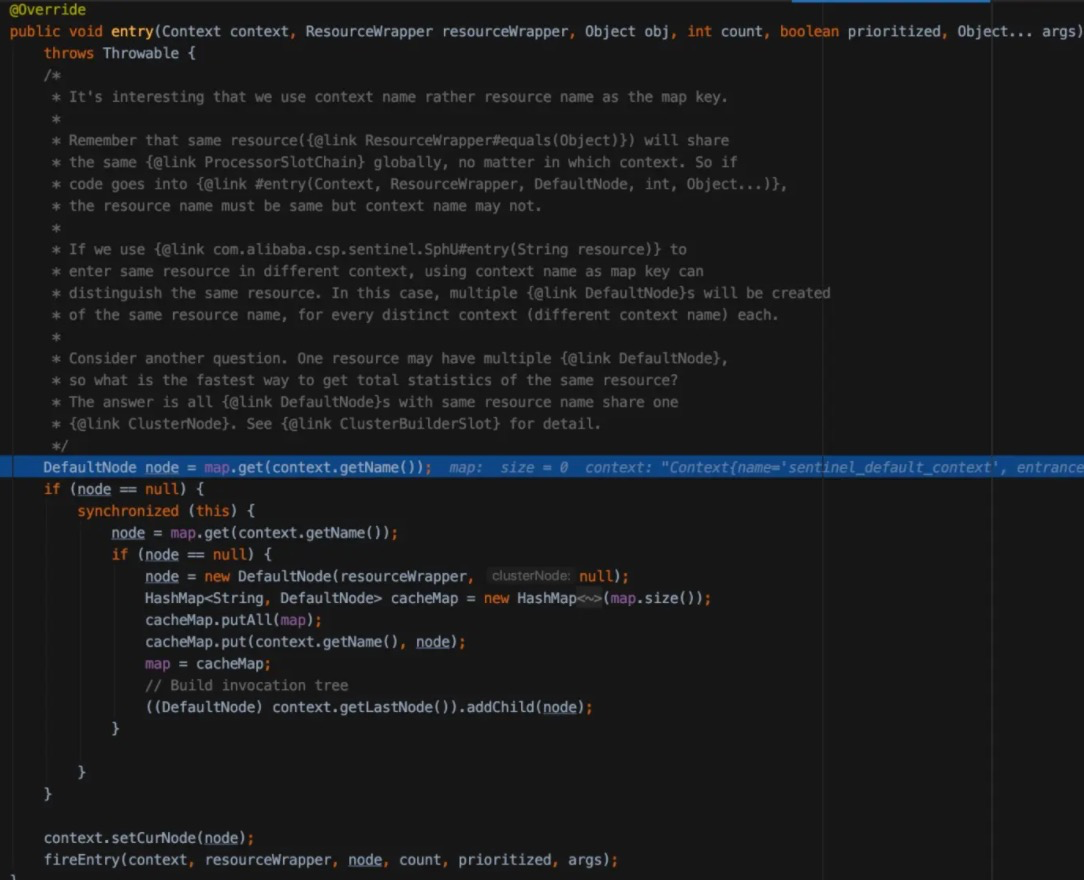
用context的名字而不是resource的名字作为key去查规则。
在这个最简单的demo里,没有context只有resource。所以以resource的名字作为key去查。发现也是null,然后创建了一个DefaultNode,然后把这个新的node放进去map里了。然后走到最后一行,最后调了SPI了,会在每个SPI的责任链里做不同的处理
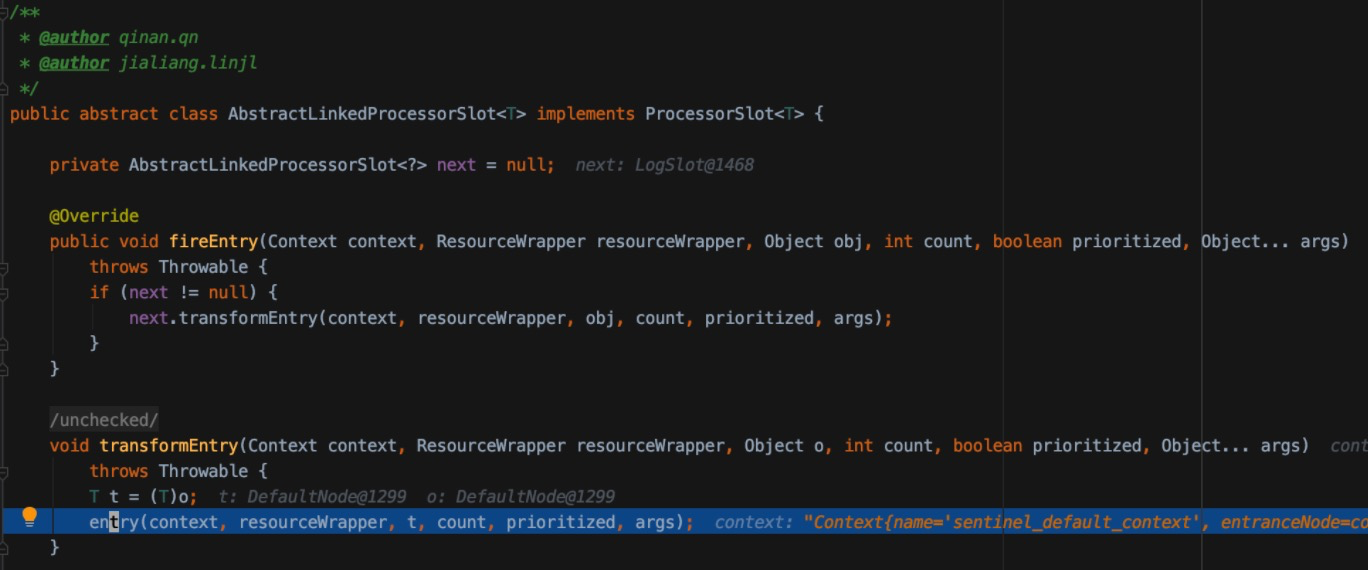
在 Sentinel 里面,所有的资源都对应一个资源名称(resourceName),每次资源调用都会创建一个 Entry 对象。Entry 可以通过对主流框架的适配自动创建,也可以通过注解的方式或调用 SphU API 显式创建。Entry 创建的时候,同时也会创建一系列功能插槽(slot chain),这些插槽有不同的职责,例如:
- NodeSelectorSlot 负责收集资源的路径,并将这些资源的调用路径,以树状结构存储起来,用于根据调用路径来限流降级;
- ClusterBuilderSlot 则用于存储资源的统计信息以及调用者信息,例如该资源的 RT, QPS, thread count 等等,这些信息将用作为多维度限流,降级的依据;
- StatisticSlot 则用于记录、统计不同纬度的 runtime 指标监控信息;
- FlowSlot 则用于根据预设的限流规则以及前面 slot 统计的状态,来进行流量控制;
- AuthoritySlot 则根据配置的黑白名单和调用来源信息,来做黑白名单控制;
- DegradeSlot 则通过统计信息以及预设的规则,来做熔断降级;
- SystemSlot 则通过系统的状态,例如 load1 等,来控制总的入口流量;
总体的框架如下:
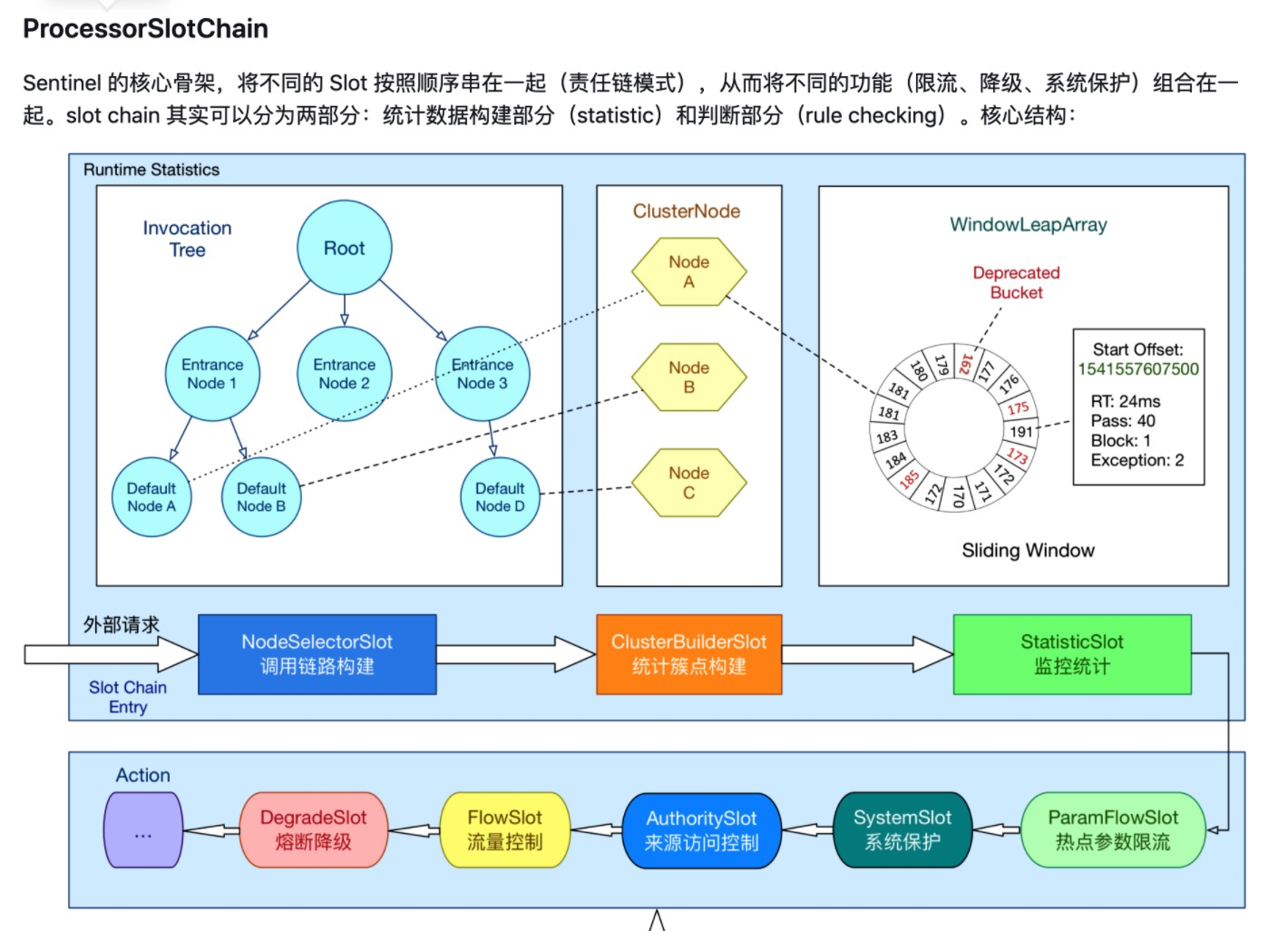
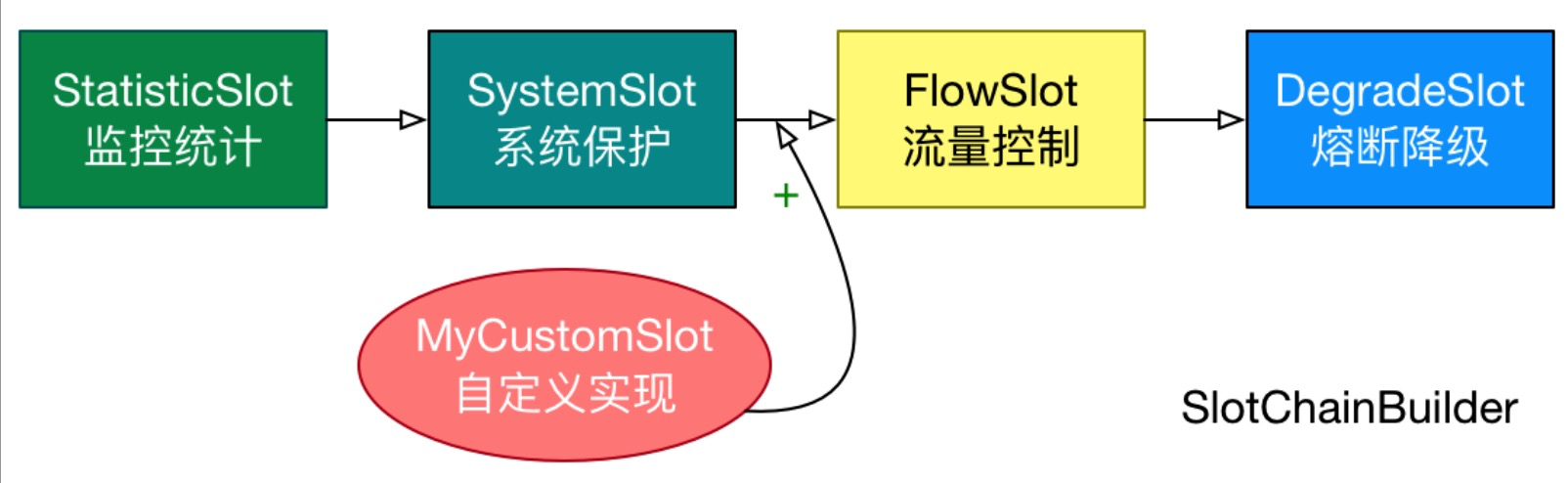
Sentinel 将 ProcessorSlot 作为 SPI 接口进行扩展(1.7.2 版本以前 SlotChainBuilder 作为 SPI),使得 Slot Chain 具备了扩展的能力。您可以自行加入自定义的 slot 并编排 slot 间的顺序,从而可以给 Sentinel 添加自定义的功能。
Sentinel的限流原理
限流效果,对应有DefaultController快速失败
- WarmUpController慢启动(令牌桶算法)
- RateLimiterController(漏桶算法)
滑动时间窗口算法
固定时间窗口算法
即比如每一秒作为一个固定的时间窗口,在一秒内最多可以通过100个请求,那么在统计数据的时候,如果0-500ms没有请求,而500-1000ms有100个请求,那么这一百个请求都能通过,在1000-1500ms的时候,又有100个请求过来了,它依然能够通过,因为在1000ms的时候又开启了一个新的固定时间窗口。
500-1500ms这一秒内有了200个请求,但是它依然能够通过,所以这就会造成数据统计的不准确性,并不能保证在任意的一秒内都使得通过请求数小于100。
普通的滑动窗口做法
因为固定时间窗口带来的数据同的不准确性,就会造成可能局部的时间压力过高,所以就需要采用滑动窗口算法来进行统计,滑动窗口时间算法意思就是,从请求过来的时刻开始,统计往前一秒中的数据,通过这个数据来判断是否进行限流等操作。
准确性就会有很大的提升,但是由于每一次请求过来都需要重新统计前一秒的数据,就会造成巨大的性能损失。所以这也是他的不合理的地方。
由于固定时间窗口带来的不准确性和普通滑动窗口带来的性能损失的缺点,所以Sentinel对这两种方案采取了折中的方案。
Sentinel的滑动时间窗口算法
在Sentinel中会将原本的固定的时间窗口划分成很多更小的样本窗口,每一次请求的数据都会被保存在小的样本窗口中去,而每一次获取的时候都会去获取这些样本时间窗口中的数据,从而不需要进行重新统计,就减小了性能损耗,同时时间窗口被细粒度化了,不准确性也会降低很多。
在统计插槽StatisticsSlot类中有ArrayMetric的类的成员变量,用于统操作和获取统计数据,而ArrayMetric类有一个成员变量LeapArray data,并提供了一些操作这个成员变量data信息的方法。
LeapArray提供两个参数sampleCount样本数量,intervalInMs 间隔时间,意思就是在这一段的间隔时间内,被分成了sampleCount个样本去分别进行统计,默认间隔时间是1s,sampleCount是2。
下面看看LeapArray的一部分源码,它也是实现滑动窗口最为重要的地方。
public abstract class LeapArray<T> {
//每一个样本窗口的时间长度
protected int windowLengthInMs;
//一个滑动窗口被划分成了多少个样本
protected int sampleCount;
//时间窗口的时间长度
protected int intervalInMs;
private double intervalInSecond;
//一个样本窗口数组,将一个滑动窗口划分为sampleCount个样本窗口的数组
protected final AtomicReferenceArray<WindowWrap<T>> array;
//部分代码省略
}
在LeapArray有这几个成员变量:
- 每一个样本窗口的时间长度
- 一个滑动窗口被划分成的样本数量
- 滑动时间窗口的时间长度
- 样本窗口数组
public WindowWrap<T> currentWindow(long timeMillis) {
if (timeMillis < 0) {
return null;
}
//计算当前样本窗口的在array中的索引,以当前时间除以样本时间长度,获得timeId
//再将TimeId对数组长度取余,得到索引,这就相当于把array当做了一个样本窗口圆环,就像官网上的图一样
int idx = calculateTimeIdx(timeMillis);
// 计算当前时间的样本窗口的开始时间
long windowStart = calculateWindowStart(timeMillis);
while (true) {
WindowWrap<T> old = array.get(idx);
if (old == null) {
//如果原来这个位置的样本窗口就是null的,就说明以前还没有网array的这个位置放过样本窗口,
// 这时就新建一个样本窗口用cas操作放到数组的这个位置,并返回该窗口
WindowWrap<T> window = new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
if (array.compareAndSet(idx, null, window)) {
// Successfully updated, return the created bucket.
return window;
} else {
// Contention failed, the thread will yield its time slice to wait for bucket available.
Thread.yield();
}
} else if (windowStart == old.windowStart()) {
//如果计算出来的窗口开始时间和现在存在的这个串口开始时间是一样的,就说明目前正处于这个样本窗口的时间内
//直接返回当前样本窗口
return old;
} else if (windowStart > old.windowStart()) {
//如果计算出来的窗口开始时间大于现在存在的样本窗口开始时间,就说明现存的样本窗口已经过时了
//这边相当于在array数组圆环上不断旋转着设置新的样本窗口,要去生成新的样本窗口把以前的老的给覆盖了
if (updateLock.tryLock()) {
try {
// 获取到锁,再去覆盖样本窗口,防止并发更新问题
return resetWindowTo(old, windowStart);
} finally {
updateLock.unlock();
}
} else {
// 没有获取到就让出cpu一小段时间再回去重新尝试获取锁
Thread.yield();
}
} else if (windowStart < old.windowStart()) {
// Should not go through here, as the provided time is already behind.
return new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));
}
}
}
LeapArray中有一个currentWindow方法,用于获取当前样本窗口,它的逻辑是这样的:
-
计算当前样本窗口的在array中的索引,以当前时间除以样本时间长度,获得timeId。
-
再将TimeId对数组长度取余,得到索引,这就相当于把array当做了一个样本窗口圆环,就像官网上的图一样,这样所有的时间窗口都会在这个数组里进行循环。
-
获取当前时间所对应的样本窗口开始时间,与目前数组中的样本窗口进行比较。
-
如果数组最终该索引不存在样本窗口,就创建一个样本窗口放到数组中
-
如果计算出来的窗口开始时间和现在存在的这个串口开始时间是一样的,就说明目前正处于这个样本窗口的时间内,直接返回该窗口就好了。
-
如果计算出来的窗口开始时间大于现在存在的样本窗口开始时间,就说明现存的样本窗口已经过时了,需要重新覆盖一个新的样本窗口。
在LeapArray里,最重要的就是这个样本窗口数组,它将一个完整的滑动时间窗口划分成了sampleCount个样本窗口WindowWrap,而样本窗口WindowWrap的结构如下:
public class WindowWrap<T> {
/**
* Time length of a single window bucket in milliseconds.
*/
//该样本窗口的长度
private final long windowLengthInMs;
/**
* Start timestamp of the window in milliseconds.
*/
//该样本窗口开始的时间
private long windowStart;
/**
* Statistic data.
*/
//每一个样本窗口里统计的数据都存在这儿
private T value;
/**
* 其余代码省略
*/
}
每一个样本窗口都包含了三个数据:
- 该样本窗口的时间长度
- 该样本窗口开始的时间
- 每一个样本窗口里统计的数据
这就是滑动窗口的原理,而每次需要对统计数据做操作的时候,就会获取当前滑动窗口的样本窗口,并对样本窗口里面的数据进行操作。简单的示范一下调用的一个流程:
首先统计数据,直接可以去看StatisticSlot插槽,因为这个插槽本身就是做这个统计数据相关的事情的
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,
boolean prioritized, Object... args) throws Throwable {
try {
// Do some checking.
//会一层一层的去执行完所有的slot规则检查
fireEntry(context, resourceWrapper, node, count, prioritized, args);
// Request passed, add thread count and pass count.
//如果到这里了就说明规则检查圈通过了,可以做成功的统计了
//添加成功的线程数
node.increaseThreadNum();
//添加成功通过的请求数量
node.addPassRequest(count);
if (context.getCurEntry().getOriginNode() != null) {
// Add count for origin node.
context.getCurEntry().getOriginNode().increaseThreadNum();
context.getCurEntry().getOriginNode().addPassRequest(count);
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
//一个资源对应一个ClusterNode,给他添加全局的统计
Constants.ENTRY_NODE.increaseThreadNum();
Constants.ENTRY_NODE.addPassRequest(count);
}
// Handle pass event with registered entry callback handlers.
for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onPass(context, resourceWrapper, node, count, args);
}
} catch (PriorityWaitException ex) {
node.increaseThreadNum();
if (context.getCurEntry().getOriginNode() != null) {
// Add count for origin node.
context.getCurEntry().getOriginNode().increaseThreadNum();
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseThreadNum();
}
// Handle pass event with registered entry callback handlers.
for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onPass(context, resourceWrapper, node, count, args);
}
} catch (BlockException e) {
//添加被Block的线程和请求数量的相关统计
context.getCurEntry().setBlockError(e);
// 添加被阻塞数量
node.increaseBlockQps(count);
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().increaseBlockQps(count);
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseBlockQps(count);
}
// Handle block event with registered entry callback handlers.
for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onBlocked(e, context, resourceWrapper, node, count, args);
}
throw e;
} catch (Throwable e) {
// Unexpected internal error, set error to current entry.
context.getCurEntry().setError(e);
throw e;
}
}
在StatisticSlot的Entry方法中,就会添加成功的数量统计,或者根据各种不同的异常,添加不同的数据统计,如请求成功通过的话,就会调用node.addPassRequest(count),而它最后会去调用ArrayMetric类的addPass方法,获取当前的样本时间窗口,并在当前的样本时间窗口上进行数据统计操作。
@Override
public void addPass(int count) {
//获取当前样本窗口,在它上面添加一个成功的统计
WindowWrap<MetricBucket> wrap = data.currentWindow();
wrap.value().addPass(count);
}
总结介绍
内部的模块通过责任链的设计模式串联起来,每个模块实现相应的功能。同时每个模块都是通过SPI实现的,我们可以自定义SPI然后插入到处理流程中间。
其中比较重要的模块,StatisticSlot,利用滑动窗口的算法计算窗口时间内的运行数据(如qps),同时内部使用了高性能的数据结构LeapArray,支持高并发写多读少的场景
本文来自博客园,作者:洛神灬殇,转载请注明原文链接:https://www.cnblogs.com/liboware/p/15659053.html,任何足够先进的科技,都与魔法无异。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号