爬取百度搜索风云榜
爬取2020年9月23日的百度热搜风云榜
设计方案
1.目标是爬取百度搜索风云榜
2.对爬取的数据进行数据清洗
3.清洗后数据的分析和可视化
实现思路:1.到所要爬取的网页使用f12查看源代码,查取所要爬取的数据的路据
2.使用get或post进行数据的爬取
3.提取有用的数据
4.使用pandas库将数据转化为二维表
5.使用pandas库进行数据清洗和回归方程的绘制
6.使用matplotlib库进行数据可视化
打开所要爬取的网页:http://top.baidu.com/
Htmls页面解析:

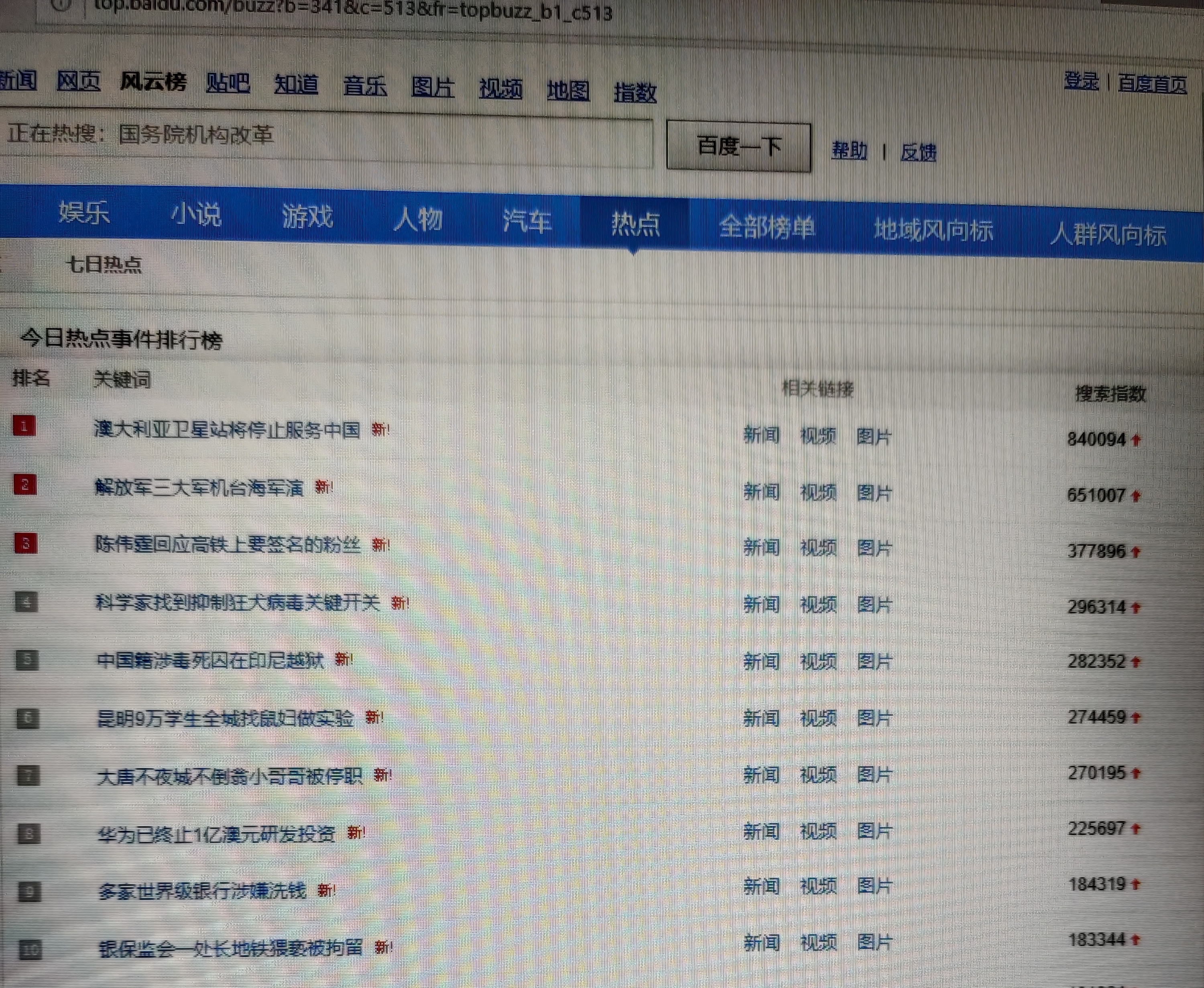
数据的爬取与采集:
import requests
from bs4 import BeautifulSoup
import bs4
import pandas as pd
titles=[]
hots=[]
top=[]
url='http://top.baidu.com/buzz?b=341&c=513&fr=topbuzz_b1_c513' #选择要爬取的网站
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/69.0.3497.100 Safari/537.36'}#伪装爬虫
r=requests.get(url) #获得url信息
r.raise_for_status()
r.encoding = r.apparent_encoding #根据内容分析出的编码方式,备选编码;
html = r.text #获得的HTML文本
table = BeautifulSoup(html,"html.parser").find("table") #对获得的文本进行html解析,查找<table>内的信息
soup=BeautifulSoup(html,'lxml')
for m in soup.find_all(class_="keyword"):
titles.append(m.get_text().strip())
for n in soup.find_all(class_="icon-rise"):
hots.append(n.get_text().strip())
for k in soup.find_all(class_="first"):
top.append(k.get_text().strip())
final=[top,titles,hots]
print(final)
df=pd.DataFrame(final,index=["排名","标题","热度数据"]) #使用工具使其可视化
print(df.T)
S="D:/ 百度排行榜.xlsx"
df.T.to_excel(S)


对数据进行清洗:
#数据清洗 print('\n====各列是否有缺失值情况如下:====') print(df.isnull()) #统计空值情况 print(df.duplicated()) #查找重复值 print(df.isna().head()) print(df.describe()) #描述数据
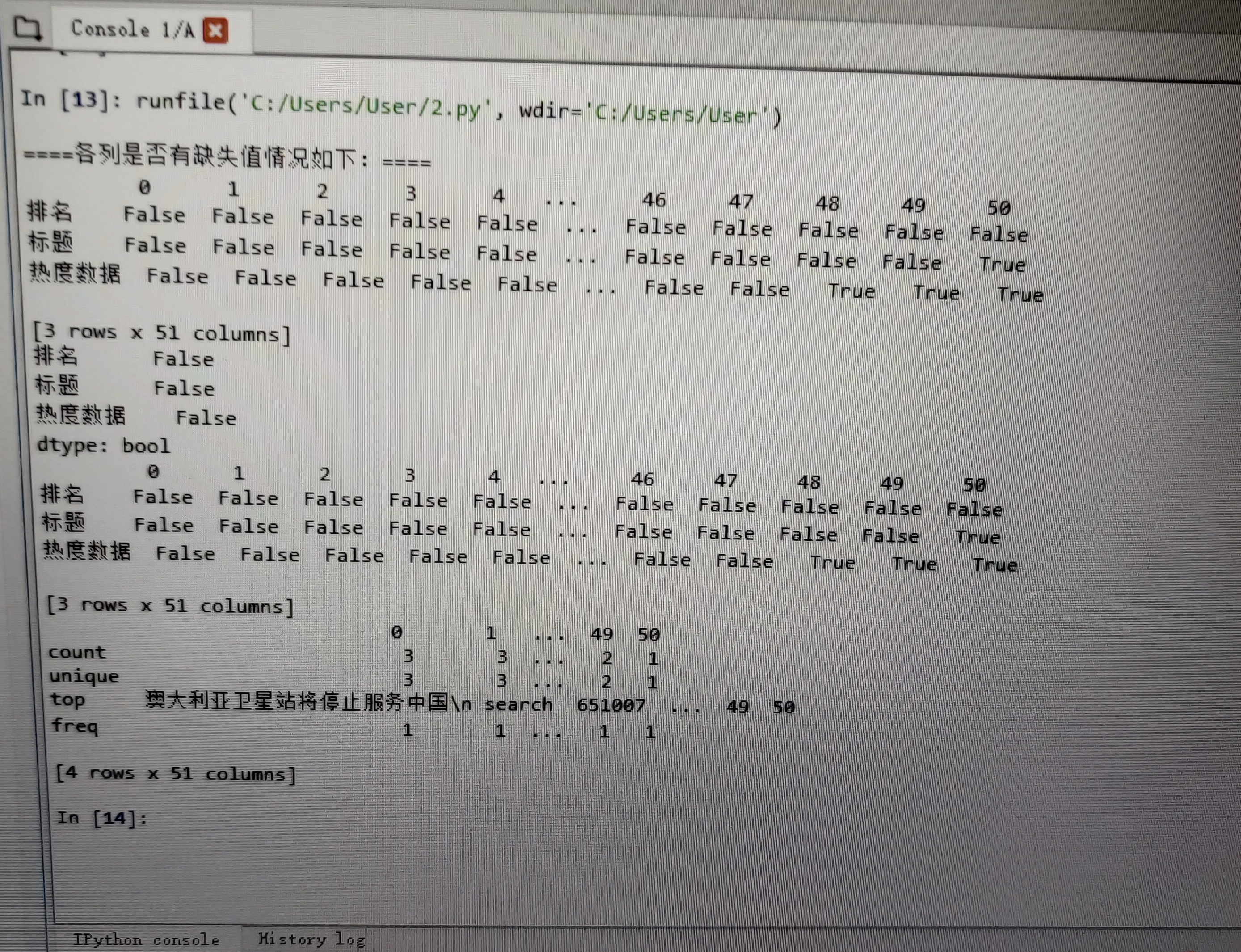
数据可视化:
import matplotlib.pyplot as plt import matplotlib matplotlib.rcParams['font.sans-serif']=['SimHei'] x =['澳大利亚卫星站将停止服务中国','解放军三大军机台海军演','陈伟霆回应高铁上要签名的粉丝','科学家找到抑制狂犬病毒关键开关','中国籍涉毒死囚在印尼越狱'] y=[1,2,3,4,5] plt.tight_layout() plt.plot(x,y) plt.xlabel("标题") plt.ylabel("排名") plt.title('Top5热点') plt.xticks(rotation=-15)#将x轴标题倾斜防止重叠 plt.show()

2.柱状图
plt.rcParams['font.family']=['sans-serif'] plt.rcParams['font.sans-serif']=['SimHei'] plt.bar(['澳大利亚卫星站将停止服务中国','解放军三大军机台海军演','陈伟霆回应高铁上要签名的粉丝','科学家找到抑制狂犬病毒关键开关','中国籍涉毒死囚在印尼越狱'], [840094,651007,377896,296314,282352]) plt.legend() plt.xlabel("热搜事件") plt.ylabel("热度指数") plt.title('Top5热点') plt.xticks(rotation=-15) plt.show()
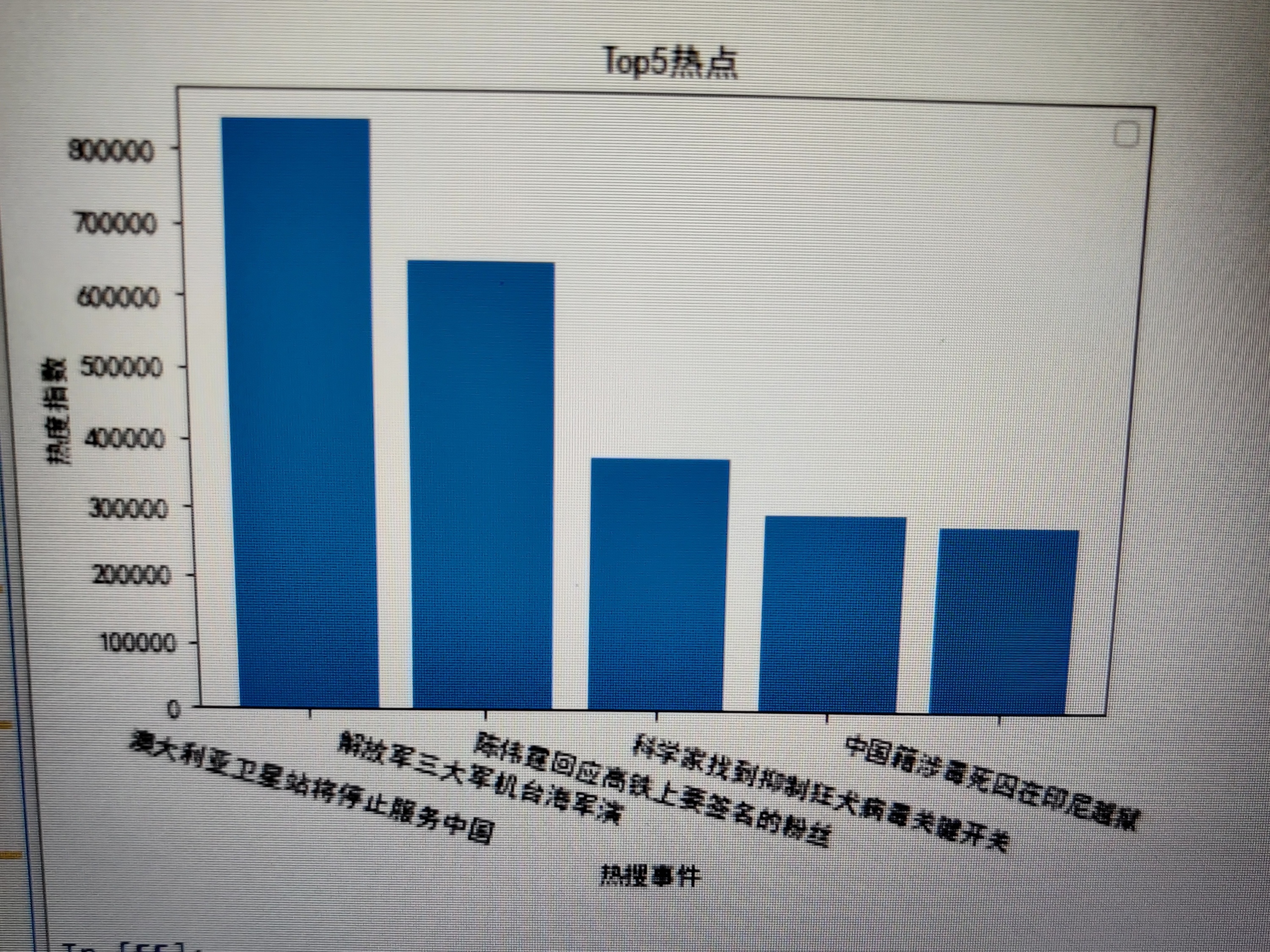
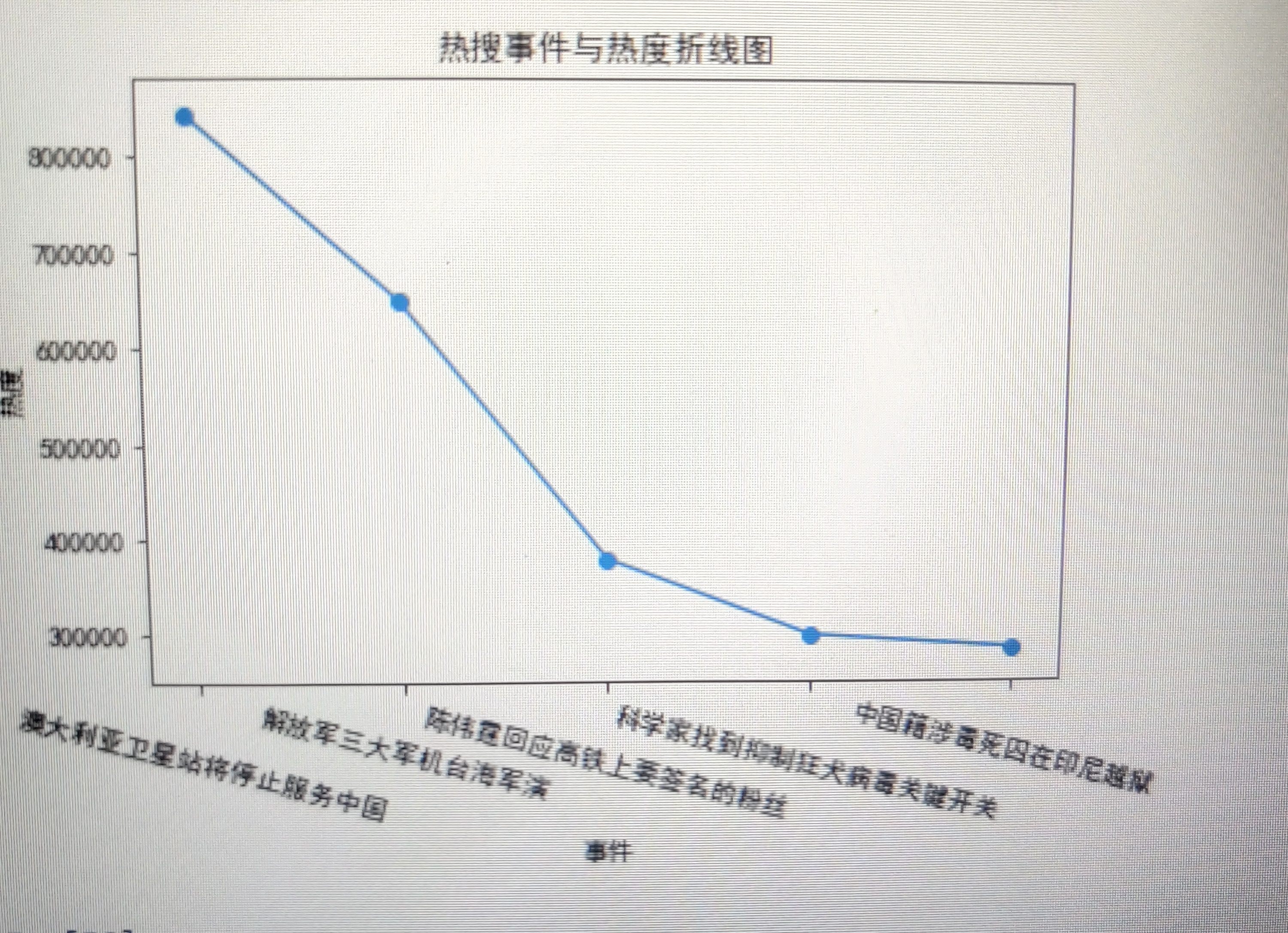
3.折线图
def line_diagram(): x = ['澳大利亚卫星站将停止服务中国','解放军三大军机台海军演','陈伟霆回应高铁上要签名的粉丝','科学家找到抑制狂犬病毒关键开关','中国籍涉毒死囚在印尼越狱'] y = [840094,651007,377896,296314,282352] plt.xlabel('事件') plt.ylabel('热度') plt.plot(x,y) plt.scatter(x,y) plt.title("热搜事件与热度折线图") plt.xticks(rotation=-15) plt.show() line_diagram()
4.
def Scatter_point(): x = ['澳大利亚卫星站将停止服务中国','解放军三大军机台海军演','陈伟霆回应高铁上要签名的粉丝','科学家找到抑制狂犬病毒关键开关','中国籍涉毒死囚在印尼越狱'] y = [1,2,3,4,5] plt.scatter(x,y,color='pink', s=25, marker="o") plt.xlabel("事件") plt.ylabel("热度") plt.title("热搜事件与热度散点图") plt.xticks(rotation=-15) plt.show() Scatter_point()

5.回归方程
import numpy as np import pandas as pd import matplotlib.pyplot as plt import matplotlib from scipy.optimize import leastsq chinese=matplotlib.font_manager.FontProperties(fname='C:/Windows/Fonts/simsun.ttc') filename="D:/ 百度排行榜.xlsx" colnames=[',',"排名","标题","热度数据"] df=pd.read_excel(filename,skiprows=1,names=colnames) print(df) X=df.排名 Y=df.热度数据 def func(p, x): a, b, c= p return a*x*x+b*x+c def error(p, x, y): return func(p, x) - y p0=[1978,20] def main(): plt.figure(figsize=(10,6)) p0=[1980,300,1] Para=leastsq(error,p0,args=(X,Y)) a,b,c=Para[0] print("a=", a,"b=", b,"c=", c) plt.figure(figsize=(10,6)) plt.scatter(X, Y, color="green", label="样本数据",linewidth=2) x=np.linspace(100000,600000,300) y=a*x*x+b*x+c plt.plot(X,Y,color="red",label=u"拟合直线",linewidth=2) plt.title(" 百度排行榜 ") plt.grid() plt.legend() plt.show() main()

所有代码汇总如下:
import requests from bs4 import BeautifulSoup import bs4 import pandas as pd titles=[] hots=[] top=[] url='http://top.baidu.com/buzz?b=341&c=513&fr=topbuzz_b1_c513' #选择要爬取的网站 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/69.0.3497.100 Safari/537.36'}#伪装爬虫 r=requests.get(url) #获得url信息 r.raise_for_status() r.encoding = r.apparent_encoding #根据内容分析出的编码方式,备选编码; html = r.text #获得的HTML文本 table = BeautifulSoup(html,"html.parser").find("table") #对获得的文本进行html解析,查找<table>内的信息 soup=BeautifulSoup(html,'lxml') for m in soup.find_all(class_="keyword"): titles.append(m.get_text().strip()) for n in soup.find_all(class_="icon-rise"): hots.append(n.get_text().strip()) for k in soup.find_all(class_="first"): top.append(k.get_text().strip()) final=[top,titles,hots] print(final) df=pd.DataFrame(final,index=["排名","标题","热度数据"]) #使用工具使其可视化 print(df.T) S="D:/ 百度排行榜.xlsx" df.T.to_excel(S) #数据清洗 print('\n====各列是否有缺失值情况如下:====') print(df.isnull()) #统计空值情况 print(df.duplicated()) #查找重复值 print(df.isna().head()) print(df.describe()) #描述数据 import matplotlib.pyplot as plt 1.import matplotlib matplotlib.rcParams['font.sans-serif']=['SimHei'] x =['澳大利亚卫星站将停止服务中国','解放军三大军机台海军演','陈伟霆回应高铁上要签名的粉丝','科学家找到抑制狂犬病毒关键开关','中国籍涉毒死囚在印尼越狱'] y=[1,2,3,4,5] plt.tight_layout() plt.plot(x,y) plt.xlabel("标题") plt.ylabel("排名") plt.title('Top5热点') plt.xticks(rotation=-15)#将x轴标题倾斜防止重叠 plt.show()plt.rcParams['font.family']=['sans-serif'] plt.rcParams['font.sans-serif']=['SimHei'] plt.bar(['澳大利亚卫星站将停止服务中国','解放军三大军机台海军演','陈伟霆回应高铁上要签名的粉丝','科学家找到抑制狂犬病毒关键开关','中国籍涉毒死囚在印尼越狱'], [840094,651007,377896,296314,282352]) plt.legend() plt.xlabel("热搜事件") plt.ylabel("热度指数") plt.title('Top5热点') plt.xticks(rotation=-15) plt.show()def line_diagram(): x = ['澳大利亚卫星站将停止服务中国','解放军三大军机台海军演','陈伟霆回应高铁上要签名的粉丝','科学家找到抑制狂犬病毒关键开关','中国籍涉毒死囚在印尼越狱'] y = [840094,651007,377896,296314,282352] plt.xlabel('事件') plt.ylabel('热度') plt.plot(x,y) plt.scatter(x,y) plt.title("热搜事件与热度折线图") plt.xticks(rotation=-15) plt.show() line_diagram()def Scatter_point(): x = ['澳大利亚卫星站将停止服务中国','解放军三大军机台海军演','陈伟霆回应高铁上要签名的粉丝','科学家找到抑制狂犬病毒关键开关','中国籍涉毒死囚在印尼越狱'] y = [1,2,3,4,5] plt.scatter(x,y,color='pink', s=25, marker="o") plt.xlabel("事件") plt.ylabel("热度") plt.title("热搜事件与热度散点图") plt.xticks(rotation=-15) plt.show() Scatter_point()import numpy as np import pandas as pd import matplotlib.pyplot as plt import matplotlib from scipy.optimize import leastsq chinese=matplotlib.font_manager.FontProperties(fname='C:/Windows/Fonts/simsun.ttc') filename="D:/ 百度排行榜.xlsx" colnames=[',',"排名","标题","热度数据"] df=pd.read_excel(filename,skiprows=1,names=colnames) print(df) X=df.排名 Y=df.热度数据 def func(p, x): a, b, c= p return a*x*x+b*x+c def error(p, x, y): return func(p, x) - y p0=[1978,20] def main(): plt.figure(figsize=(10,6)) p0=[1980,300,1] Para=leastsq(error,p0,args=(X,Y)) a,b,c=Para[0] print("a=", a,"b=", b,"c=", c) plt.figure(figsize=(10,6)) plt.scatter(X, Y, color="green", label="样本数据",linewidth=2) x=np.linspace(100000,600000,300) y=a*x*x+b*x+c plt.plot(X,Y,color="red",label=u"拟合直线",linewidth=2) plt.title(" 百度排行榜 ") plt.grid() plt.legend() plt.show() main()
结论:通过对主题数据的可视化我发现其主要是运用图形来直观地看出数据的大小变化。人们对外国对中国的动态关注更多。这些都能直观体现出来了。
总结:完成这次作业后,我发现了自己在Python中知识的缺漏,也因为这些缺漏导致一些作业要求可能有些错误,所以我一定在今后的Python学习中多学多问,增长自己的见识,弥补自己的不足。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号