爬取百度热搜榜并把数据可视化
1.目标爬取百度热搜榜(百度热搜榜网址:https://top.baidu.com)
2.对爬取的数据进行清洗和分析
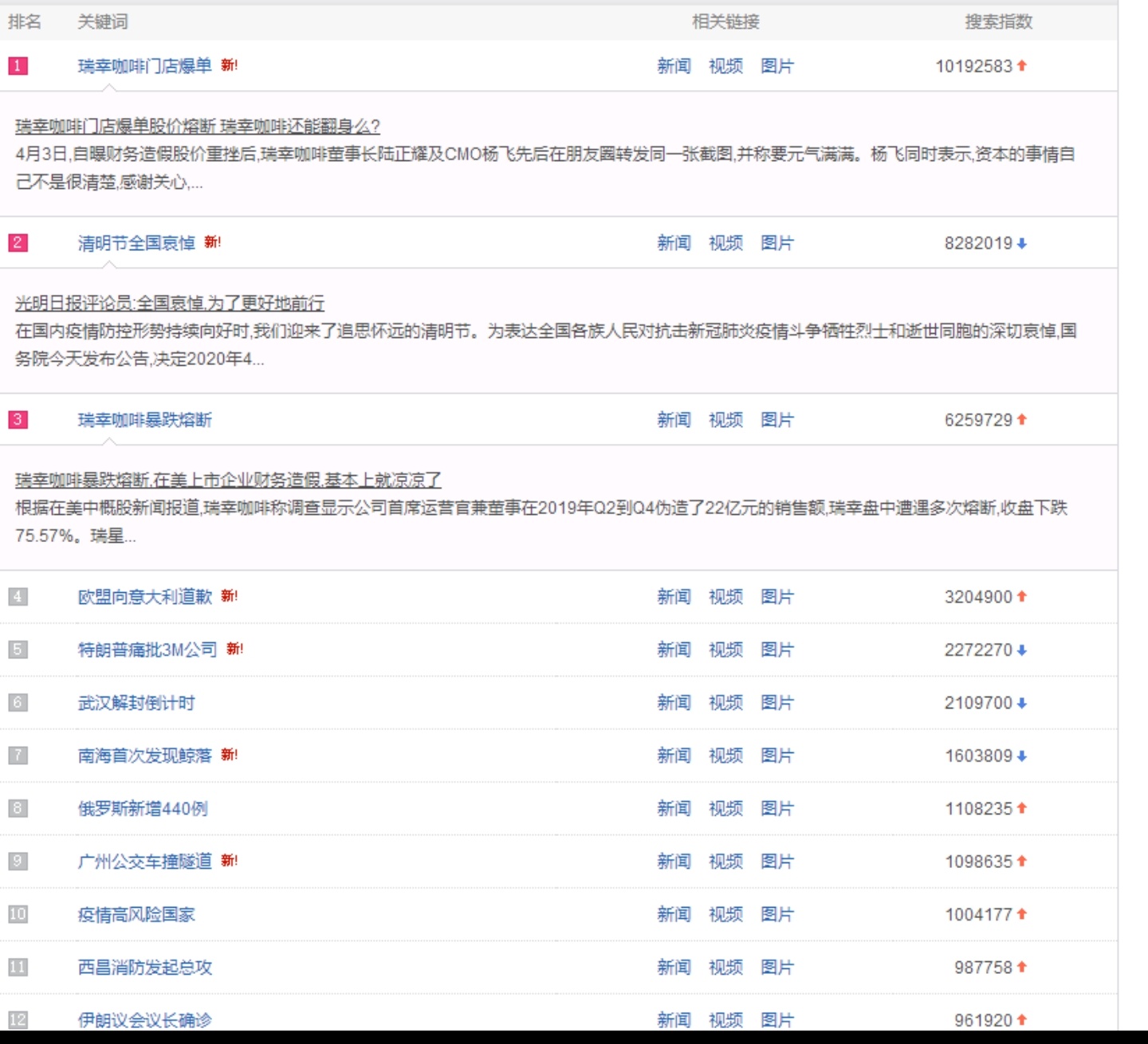
爬取网站的“关键词”“相关链接”“搜索指数”
3.进行数据可视化
实现思路:1.到该网页使用f12查看源代码,查找所要爬取的数据。
2.使用get或post进行数据爬取。
3.提取有用的数据。
4.使用pandas库将数据转化为二维表。
5.使用pandas库进行数据的清洗
6.使用matplotlib库进行数据可视化。
技术难点:爬取数据以及对数据的转化。
1.源代码
URL:http://top.baidu.com.
2爬取代码如下
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
from scipy.optimize import leastsq
import requests2020-04-2420:57:32
from bs4 import BeautifulSoup
import pandas as pd
import csv
import jieba
import wordcloud
import requests
from lxml import etree
head = {}
url = "http://top.baidu.com/buzz?b=341&fr=topindex
head["User-Agent"] = "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:63.0) Gecko/20100101 Firefox/63.0"
head["Accept"]= "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"
head["Accept-Language"]= "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2"
head["Connection"] = "keep-alive"
def main():
print("百度热搜top:
res = requests.get(url , headers = head)
with open("html.txt", "wb") as f:
f.write(res.content)
html = etree.parse('html.txt' , etree.HTMLParser(encoding='gbk')
top_list = html.xpath('//a[@class="list-title"]/text()'
num_search = html.xpath('//span[@class="icon-rise"]/text()'
for i , j in zip(top_list[:10] , num_search[:10]):
print(i ,"搜索指数为:" , j )
if __name__ == '__main__'
main()
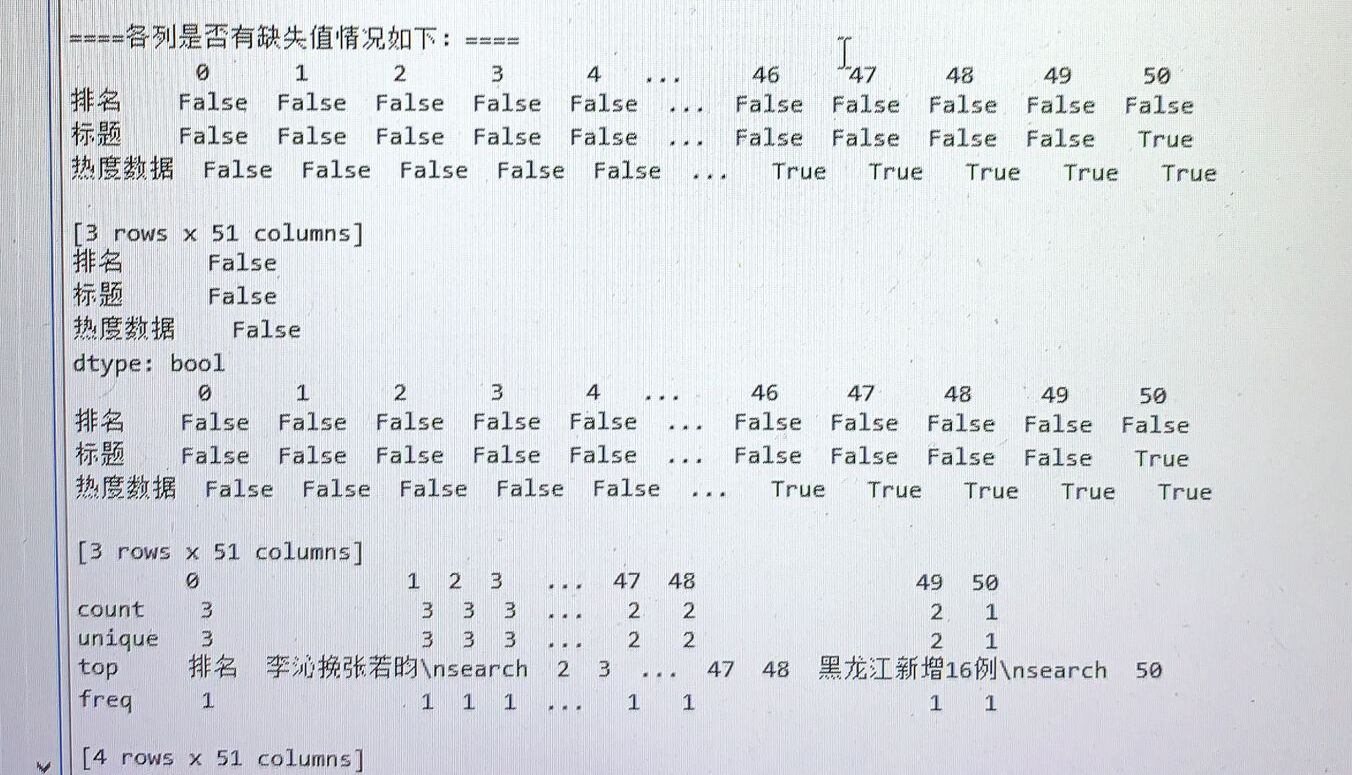
对数据进行清洗:
1 import pandas as pd 2 kugou=pd.DataFrame(pd.read_excel('data.xls')) 3 kugou.head() 4 kugou.drop(1,axis=0,inplace=True) 5 kugou.head()
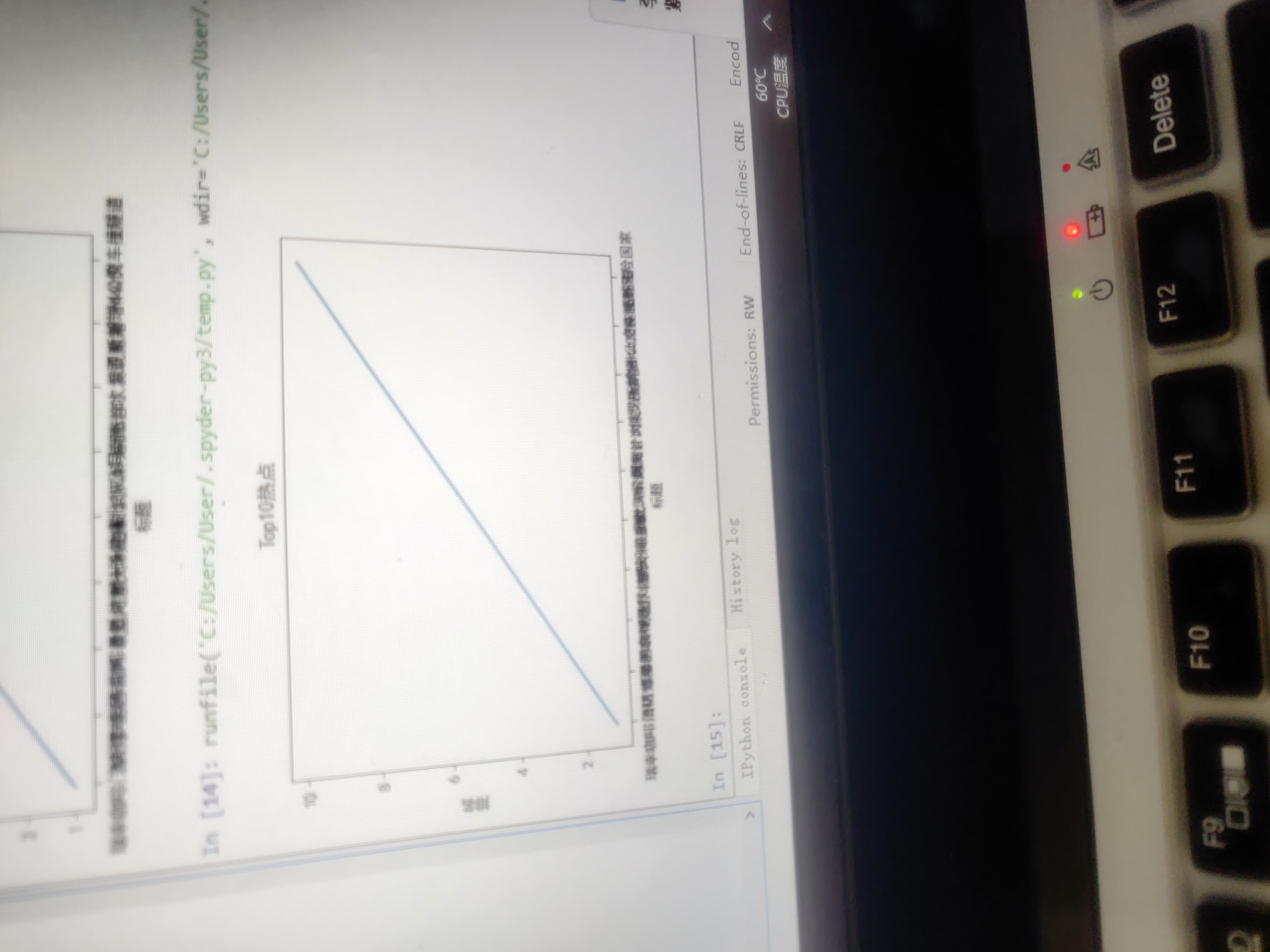
一元方程:
import matplotlib.pyplot as plt import matplotlib matplotlib.rcParams['font.sans-serif']=['SimHei'] x=['瑞幸咖啡门店爆单','清明节全国哀悼','瑞幸咖啡暴跌熔断','欧盟向意大利道歉','特朗普痛批3M公司','武汉解封倒计时','南海首次发现鲸落',"俄罗斯新增440例","广州公交车撞隧道","疫情高风险国家"] y = [1,2,3,4,5,6,7,8,9,10] plt.plot(x,y) plt.xlabel("标题") plt.ylabel("排名") plt.title('Top10热点') plt.show()
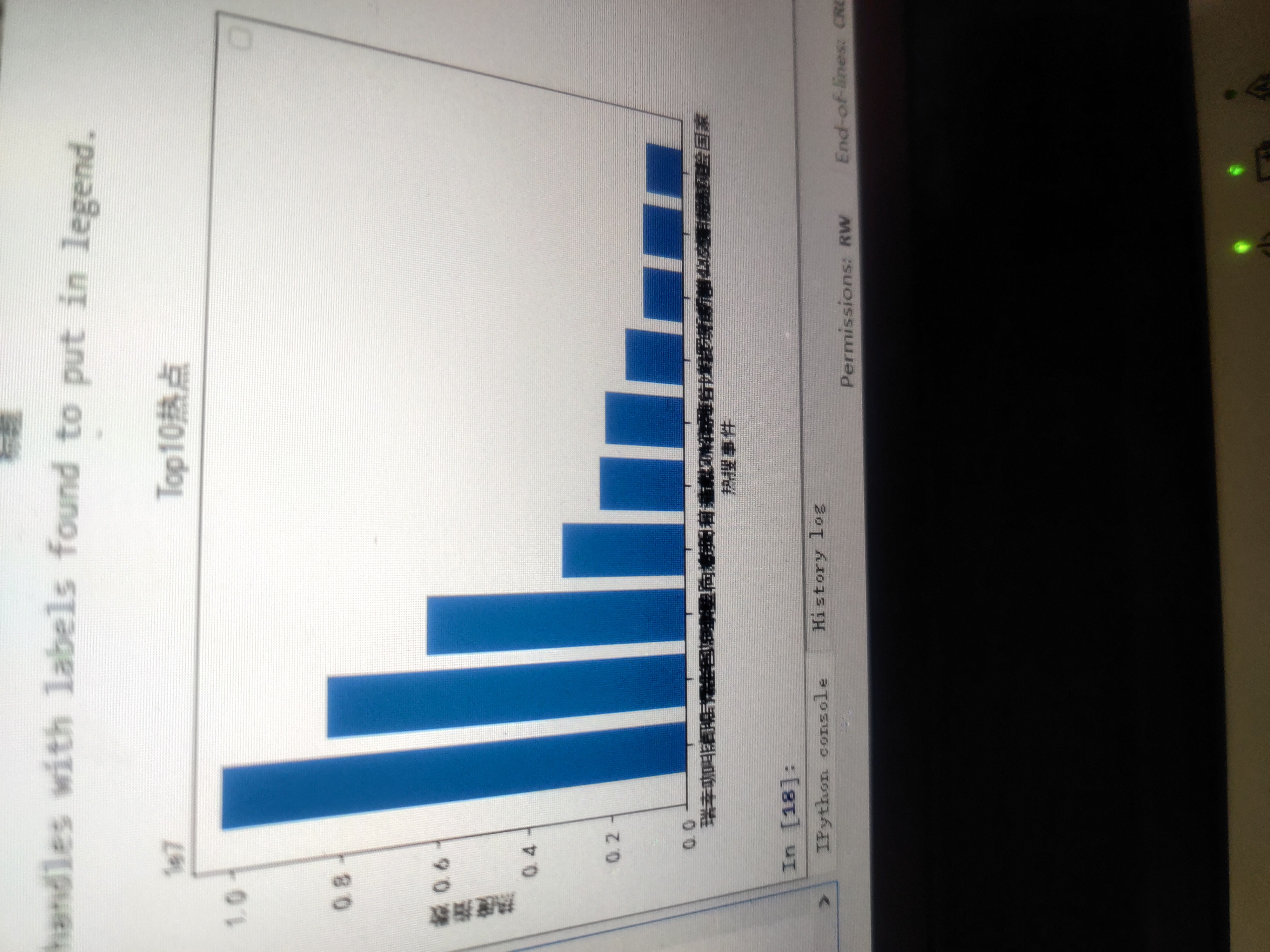
柱状图:
plt.rcParams['font.family']=['sans-serif']
plt.rcParams['font.sans-serif']=['SimHei']
plt.bar(['瑞幸咖啡门店爆单','清明节全国哀悼','瑞幸咖啡暴跌熔断','欧盟向意大利道歉','特朗普痛批3M公司','武汉解封倒计时','南海首次发现鲸落',"俄罗斯新增440例","广州公交车撞隧道","疫情高风险国家"], [10192583,8282019,6259729,3204900,2272270,2109700,1603809,1108235,1098635,1004177])
plt.legend()
plt.xlabel("热搜事件")
plt.ylabel("热度指数")
plt.title('Top10热点')
plt.show()
散点图:
def Scatter_point():
x = ['瑞幸咖啡门店爆单','清明节全国哀悼','瑞幸咖啡暴跌熔断','欧盟向意大利道歉','特朗普痛批3M公司','武汉解封倒计时','南海首次发现鲸落',"俄罗斯新增440例","广州公交车撞隧道","疫情高风险国家"]
y = [1,2,3,4,5,6,7,8,9,10]
plt.scatter(x,y,color='pink', s=25, marker="o")
plt.xlabel("事件")
plt.ylabel("热度")
plt.title("热搜事件与热度散点图")
plt.show()
Scatter_point()

折线图:
def line_diagram(): x = ['瑞幸咖啡门店爆单','清明节全国哀悼','瑞幸咖啡暴跌熔断','欧盟向意大利道歉','特朗普痛批3M公司','武汉解封倒计时','南海首次发现鲸落',"俄罗斯新增440例","广州公交车撞隧道","疫情高风险国家"] y = [10192583,8282019,6259729,3204900,2272270,2109700,1603809,1108235,1098635,1004177] plt.xlabel('事件') plt.ylabel('热度') plt.plot(x,y) plt.scatter(x,y) plt.title("热搜事件与热度折线图") plt.show() line_diagram()

最后汇总部分代码,并附上完整代码:
import requests from lxml import etree head = {} url = "http://top.baidu.com/buzz?b=341&fr=topindex" head["User-Agent"] = "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:63.0) Gecko/20100101 Firefox/63.0" head["Accept"]= "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8" head["Accept-Language"]= "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2" head["Connection"] = "keep-alive" def main(): print("百度热搜top: ") res = requests.get(url , headers = head) with open("html.txt", "wb") as f: f.write(res.content) html = etree.parse('html.txt' , etree.HTMLParser(encoding='gbk')) top_list = html.xpath('//a[@class="list-title"]/text()') num_search = html.xpath('//span[@class="icon-rise"]/text()') for i , j in zip(top_list[:10] , num_search[:10]): print(i ,"搜索指数为:" , j ) if __name__ == '__main__': main() import matplotlib.pyplot as plt import matplotlib matplotlib.rcParams['font.sans-serif']=['SimHei'] x=['瑞幸咖啡门店爆单','清明节全国哀悼','瑞幸咖啡暴跌熔断','欧盟向意大利道歉','特朗普痛批3M公司','武汉解封倒计时','南海首次发现鲸落',"俄罗斯新增440例","广州公交车撞隧道","疫情高风险国家"] y = [1,2,3,4,5,6,7,8,9,10] plt.plot(x,y) plt.xlabel("标题") plt.ylabel("排名") plt.title('Top10热点') plt.show() plt.rcParams['font.family']=['sans-serif'] plt.rcParams['font.sans-serif']=['SimHei'] plt.bar(['瑞幸咖啡门店爆单','清明节全国哀悼','瑞幸咖啡暴跌熔断','欧盟向意大利道歉','特朗普痛批3M公司','武汉解封倒计时','南海首次发现鲸落',"俄罗斯新增440例","广州公交车撞隧道","疫情高风险国家"], [10192583,8282019,6259729,3204900,2272270,2109700,1603809,1108235,1098635,1004177]) plt.legend() plt.xlabel("热搜事件") plt.ylabel("热度指数") plt.title('Top10热点') plt.show() def Scatter_point(): x = ['瑞幸咖啡门店爆单','清明节全国哀悼','瑞幸咖啡暴跌熔断','欧盟向意大利道歉','特朗普痛批3M公司','武汉解封倒计时','南海首次发现鲸落',"俄罗斯新增440例","广州公交车撞隧道","疫情高风险国家"] y = [1,2,3,4,5,6,7,8,9,10] plt.scatter(x,y,color='pink', s=25, marker="o") plt.xlabel("事件") plt.ylabel("热度") plt.title("热搜事件与热度散点图") plt.show() Scatter_point() def line_diagram(): x = ['瑞幸咖啡门店爆单','清明节全国哀悼','瑞幸咖啡暴跌熔断','欧盟向意大利道歉','特朗普痛批3M公司','武汉解封倒计时','南海首次发现鲸落',"俄罗斯新增440例","广州公交车撞隧道","疫情高风险国家"] y = [10192583,8282019,6259729,3204900,2272270,2109700,1603809,1108235,1098635,1004177] plt.xlabel('事件') plt.ylabel('热度') plt.plot(x,y) plt.scatter(x,y) plt.title("热搜事件与热度折线图") plt.show() line_diagram() import matplotlib.pyplot as plt import matplotlib matplotlib.rcParams['font.sans-serif']=['SimHei'] x=['瑞幸咖啡门店爆单','清明节全国哀悼','瑞幸咖啡暴跌熔断','欧盟向意大利道歉','特朗普痛批3M公司','武汉解封倒计时','南海首次发现鲸落',"俄罗斯新增440例","广州公交车撞隧道","疫情高风险国家"] y = [1,2,3,4,5,6,7,8,9,10] plt.plot(x,y) plt.xlabel("标题") plt.ylabel("排名") plt.title('Top10热点') plt.show()
结论:通过此次Python作业,我感受到了Python语言的强大魅力,发现它比其他语言更容易上手,相对比较简单。
总结:完成这次作业后,我发现了自己在Python中知识的缺漏,也因为这些缺漏导致一些作业要求我实在无法完成,所以我一定在今后的Python学习中多学多问,增长自己的见识,弥补自己的不足。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号