

mysql 深度分页
mysql 分页查询使我们常见的需求 ,但是随着页数的增加查询性能会逐渐下降,尤其是到深度分页的情况。我们可以把分页分为两个步骤,1.定位偏移量,2.获取分页条数的 数据。
所以当数据较大页数较深时就涉及一次需要耗费较长时间的操作。所以mysql深度分页的 问题该如何解决呢 ?
首先我们来看一个简单的查询:
SELECT * FROM events WHERE date > '2010-01-01T00:00:00-00:00' AND event = 'editstart' ORDER BY date LIMIT 50000 50;
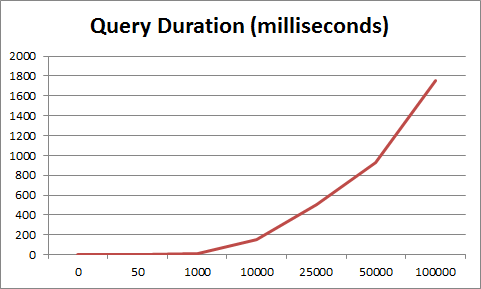
可以发现在一定页数后时间延时非常明显。结合相关文章我们的解决方式可以大致分为以下几种.
思路:
既然分页查询时,定位偏移量较慢,我们可不可以减少这个偏移量的定位,使其始终曲线的前半部分,即在较少偏移量的场景。
方法一:以结果作为条件,已查询条件的变化换取分页的不变。
分页查询我们一般都是逐渐往后翻页的,那么我们可以很清晰的知道,在当前查询页的最后一条数据的时间点,那么,以此时间点再查询20条,那么 我们当前的页数就同样还是0,以时间点的推移换取页数的不变,减少其偏移量的计算。
我们可以创建索引 index(date,id), id就是我们上一次的返回结果。
具体示例如下:
SELECT *FROM events WHERE (date,id) > ('2010-07-12T10:29:47-07:00',111866) AND event = 'editstart' ORDER BY date, id LIMIT 50000 50
以上方法的局限性:
1.id最好是主键,是否有这样自增长的字段,或者说带顺序变化特性的列。
2.无法适应下一次分页页数与上一次相差较大,如由第一页突然跳转到50万页。
优点:可以适合复杂查询条件查询的场景。不需要改变sql语句结构
方法二:
采用子查询模式,其原理依赖于覆盖索引,当查询的列,均是索引字段时,性能较快,因为其只用遍历索引本身。我们自己创建的非主键索引,都是非聚集索引,其不包含非索引字段,所以数据结构较小,系统能快速遍历。我们知道索引时b+树结构,系统能很容易的知道866613,位于索引树的位置。
##查询语句 select id from product limit 866613, 20 ##优化方式一 SELECT * FROM product WHERE ID > =(select id from product limit 866613, 1) limit 20 ##优化方式二 SELECT * FROM product a JOIN (select id from product limit 866613, 20) b ON a.ID = b.id
局限性:
依赖于主键的自增长特性。
不适合复杂查询条件的分页逻辑,复杂查询条件很难做到,索引包含全部查询字段,容易漏掉部分数据。
方法三:
复合索引:其原理同样是索引覆盖的思想,只不过是其以查询条件的一份作为索引,最终的索引字段是主键id。这种场景严格依赖于索引的顺序。查询的结果也不能包含非索引字段,需再走一次子查询。
可以参考博客:https://blog.csdn.net/yalishadaa/article/details/72861309
关于深度分页:
针对复杂的查询逻辑,一般从数据的 偏移量着手,减少偏移量的定位时间。
简单的查询逻辑,可以从索引覆盖的思想着手,先确定查询数据的主键id,再由id找相关的数据,索引能解决的 就不要加给业务逻辑了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号