
20194220 实验四《Python程序设计》实验报告
20194220 2019-2020-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 1942
姓名: 梁勇
学号:20194220
实验教师:王志强
实验日期:2020年6月7日
必修/选修: 公选课
1.实验内容
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等
我选择了,爬虫获取数据
2. 实验过程及结果
首先看书了解爬虫
爬虫的原理是从一个链接开始发送HTTP请求来连接,然后得到内容。
爬虫执行流程:
1、发送请求request
2、获取响应内容 response
3、解析内容
做好准备工作
1、下载urllib模块
windows可以使用下列命令进行安装
pip install urllib(其实我的python3.8自带了这个模块,直接导入就好了)
2、学习Request函数的使用
开始构思
1、首先想好要抓取什么网站,因为想不到什么,就干脆去找豆瓣排行榜
2、确定URL格式
我要抓取的豆瓣电影 Top 250,地址是https://movie.douban.com/top250?start=
3、进行页面抓取
页面抓取需要用刚才导入的urllib库。
因此先定义一个类名MovieTop,然后在类中定义好获取页面的方法和初始化方法:
class MovieTop(object):
def __init__(self):
self.start = 0
self.param = '&filter='
self.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64)'}
self.movie_list = []
self.file_path = 'D:\综合实践.txt'
def get_page(self):
try:
url = 'https://movie.douban.com/top250?start=' + str(self.start)
req = request.Request(url, headers = self.headers)
response = request.urlopen(req)
page = response.read().decode('utf-8')
page_num = (self.start + 25)//25
print(f'正在抓取第{str(page_num)}页数据...')
self.start += 25
return page
except request.URLError as e:
if hasattr(e,'reason'):
print(f'抓取失败,失败原因:{e.reason}')
4、可以提取信息了,但是信息是杂乱而且很多的,就用re模块的compile函数和正则表达式(书里面教的)
def get_movie_info(self):
pattern = re.compile(u'<div.*?class"item">.*?'
+ u'<div.*?class"pic">.*?'
+ u'<em.*?class="">(.*?)</em>.*?'
+ u'<div.*?class="info">.*?'
+ u'<span.*?class="title">(.*?)'
+ u'</span>.*?<span.*?class="title">(.*?)</span>.*?'
+ u'<span.*?class="other">(.*?)</span>.*?</a>.*?'
+ u'<div.*?class="bd">.*?<p.*?class="">.*?'
+ u'导演:(.*?) .*?<br>'
+ u'(.*?) / (.*?) / '
+ u'(.*?)</p>.*?<div.*?class="start">.*?'
+ u'<span.*?'
+ u'class="rating_num".*?property="v:average">'
+ u'(.*?)</span>.*?'
+ u'.*?<span>(.*?)人评价</span>.*?'
+ u'<p.*?class="quote">.*?'
+ u'<span.*?class="inq">(.*?)'
+ u'</span>.*?</p>',re.S)
5、然后抓取了信息,就可以写入文件了,写入文件的步骤很简单,就是用os模块和file操作类别的用法(w的写入,write,open等)
(也可以在这个函数定义中加入try方便我们看到如果抓取失败的操作结果和原因)
def wrtie_text(self):
print('开始向文件写入数据……')
file = open(self.file_path,'w',encoding='utf-8')
try:
for movie in self.movie_list:
file.write('电影排名:'+ movie[0] +"\r\n")
file.write('电影名称:'+ movie[1] +'\r\n')
file.write('外文排名:'+ movie[2] +'\r\n')
file.write('电影别名:'+ movie[3] +'\r\n')
file.write('导演姓名:'+ movie[4] +'\r\n')
file.write('上映年份:'+ movie[5] +'\r\n')
file.write('制作国家/地区:'+ movie[6] +'\r\n')
file.write('电影类别:'+ movie[7] +'\r\n')
file.write('电影评分:'+ movie[8] +'\r\n')
file.write('参评人数:'+ movie[9] +'\r\n')
file.write('简短影评:'+ movie[10] +'\r\n\r\n')
print('抓取结果写入文件成功……')
except Exception as e:
print(e)
finally:
file.close()
6、很多网站有反爬虫机制,对于爬虫请求会拒绝,所以可以伪装成浏览器,通过修改HTTP包中的header实现,比如:
self.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64)'}
下面是源代码:
from urllib import request
import re
import os
class MovieTop(object):
def __init__(self):
self.start = 0
self.param = '&filter='
self.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64)'}
self.movie_list = []
self.file_path = 'D:\综合实践.txt'
def get_page(self):
try:
url = 'https://movie.douban.com/top250?start=' + str(self.start)
req = request.Request(url, headers = self.headers)
response = request.urlopen(req)
page = response.read().decode('utf-8')
page_num = (self.start + 25)//25
print(f'正在抓取第{str(page_num)}页数据...')
self.start += 25
return page
except request.URLError as e:
if hasattr(e,'reason'):
print(f'抓取失败,失败原因:{e.reason}')
def get_movie_info(self):
pattern = re.compile(u'<div.*?class"item">.*?'
+ u'<div.*?class"pic">.*?'
+ u'<em.*?class="">(.*?)</em>.*?'
+ u'<div.*?class="info">.*?'
+ u'<span.*?class="title">(.*?)'
+ u'</span>.*?<span.*?class="title">(.*?)</span>.*?'
+ u'<span.*?class="other">(.*?)</span>.*?</a>.*?'
+ u'<div.*?class="bd">.*?<p.*?class="">.*?'
+ u'导演:(.*?) .*?<br>'
+ u'(.*?) / (.*?) / '
+ u'(.*?)</p>.*?<div.*?class="start">.*?'
+ u'<span.*?'
+ u'class="rating_num".*?property="v:average">'
+ u'(.*?)</span>.*?'
+ u'.*?<span>(.*?)人评价</span>.*?'
+ u'<p.*?class="quote">.*?'
+ u'<span.*?class="inq">(.*?)'
+ u'</span>.*?</p>',re.S)
while self.start <= 225:
page = self.get_page()
movies = re.findall(pattern,page)
for movie in movies:
self.movie_list.append([movie[0],movie[1],
movie[2].lstrip(' / '),
movie[3].lstrip(' / '),
movie[4],
movie[5].lstrip(),
movie[6],
movie[7].lstrip(),
movie[8],
movie[9],
movie[10]])
def wrtie_text(self):
print('开始向文件写入数据……')
file = open(self.file_path,'w',encoding='utf-8')
try:
for movie in self.movie_list:
file.write('电影排名:'+ movie[0] +"\r\n")
file.write('电影名称:'+ movie[1] +'\r\n')
file.write('外文排名:'+ movie[2] +'\r\n')
file.write('电影别名:'+ movie[3] +'\r\n')
file.write('导演姓名:'+ movie[4] +'\r\n')
file.write('上映年份:'+ movie[5] +'\r\n')
file.write('制作国家/地区:'+ movie[6] +'\r\n')
file.write('电影类别:'+ movie[7] +'\r\n')
file.write('电影评分:'+ movie[8] +'\r\n')
file.write('参评人数:'+ movie[9] +'\r\n')
file.write('简短影评:'+ movie[10] +'\r\n\r\n')
print('抓取结果写入文件成功……')
except Exception as e:
print(e)
finally:
file.close()
def main(self):
print('开始从豆瓣电影抓取数据……')
self.get_movie_info()
self.wrtie_text()
print('抓取数据完毕……')
dou_ban_spider = MovieTop()
dou_ban_spider.main()
下面是运行的结果:

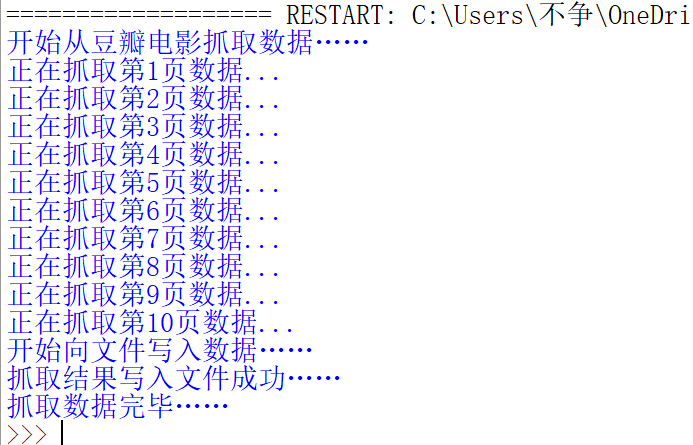
我们再对比之前抓取的界面的数据:
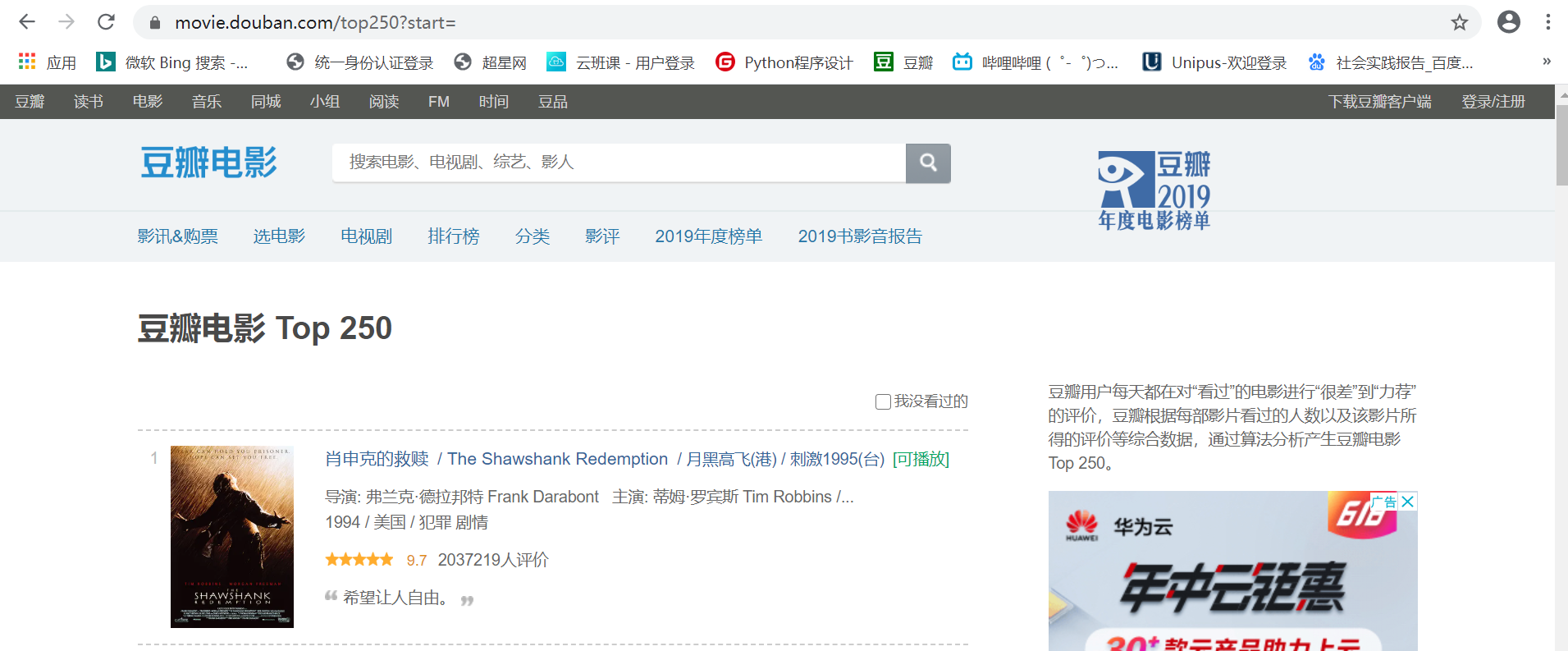
显然,是一致的,而且没有抓取错误。
3. 实验过程中遇到的问题和解决过程
- 问题1:一直各类型报错
- 问题1解决方案:重新检查一遍语法和关键词,用debug逐步探查
- 问题2:文件写入失败
- 问题2解决方案:忘记导入os库
- 问题3:初始页面信息太多了,难找到自己想要的
- 问题3解决方法:用re模块中的compile函数和正则表达式
全课总结(课程感想体会、意见和建议等)
我很高兴,也很荣幸在电科院能够听到王志强老师的课。还记得最初知道王老师是在“格致论坛”,王老师一上台,一下子困意全无了,实在是有趣,让我一个文科生,听到这云里雾里的“区块链”,也能提起一些兴趣。
在知道我们至少要报一门自然科学的消息后,我想着,python这几年发展势头那么火热,就选了,也算是机缘巧合,在这能够再遇王老师。
犹且记,第一堂课,王老师给我们写了对着门课的期望,我写下的是“做一个会一点点的文科生”;
不敢忘,王老师看到了我的话,并且做出了“无论文科生还是理科生,都可以学习python,我相信文科生也能学好的,加油”的鼓励;
那天后,我就去买了《python3.7从零开始学》的教材,并且认真学习,每次作业都不拖拉,还算是对得起自己的诺言和对得起老师的鼓励!
值得一提的是,在学习过程中,老师这种让我们自己看视频,每个周抽查布置作业的方式对我而言还是比较新奇的,既让我们有了自由支配的时间学习,也宽松了提交作业的时间,方便了我们自己发现问题、寻找答案、解决问题,也强化了我们的能力。
同时,老师也拿出了10分,作为加分,有2分的是英语打卡,我也十分勤勉的完成了,也收获了词汇量,还是十分感谢老师的。而其他的加分,也有分在“录视频教方法”中,虽然我才疏学浅,无缘这8分。但是对于这种方式来鼓励大家的积极性,我还是十分佩服老师的。
其实,对于课程感想和体会,我认为,对于我来说,最大的收获就是,“我竟然可以”!在一次次的学习实验中,我不断的突破自己给自己设下的“文科生”局限,积极寻求方法和同学指导,也在一次次很迷茫不知怎么做的时候,也没用长时间放纵、沉寂,而是看书和视频,自己动手,并且学习别人的编译风格,搞得更加的简洁明了。我想这便是最大的收获。
我将终身记得这门课,我也将终身学习这门知识。
待到未来闲暇,也希望能了解更多,也希望遇见喜欢的人能给他编一个小程序。
感谢!一谢python!二谢王志强老师的鼓励!三谢我自己没有放弃!
参考资料
《python3.7从0开始学》刘宇宙 编著,清华大学出版社
https://www.jianshu.com/p/2411490d6464
https://www.runoob.com/python3/python3-file-methods.html
