

这篇作业的要求来源于https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
1.选取了
歌曲:Sidewalks
歌手:The Weeknd / Kendrick Lamar
的歌曲评论
这首歌是来自与一个热门主播的常用BGM
1.数据导入
数据来自之前拍虫大作业的数据,将爬取txt数据转化为csv
import csv
with open('C:\\Users\\Administrator\\Desktop\\abcd.csv', 'w') as csvfile:
spamwriter = csv.writer(csvfile, dialect='excel')
# 读要转换的txt文件,文件每行各词间以@@@字符分隔
with open('C:\\Users\\Administrator\\Desktop\\abcd.txt', 'r') as filein:
for line in filein:
line_list = line.strip('\n').split('@@@')
spamwriter.writerow(line_list)
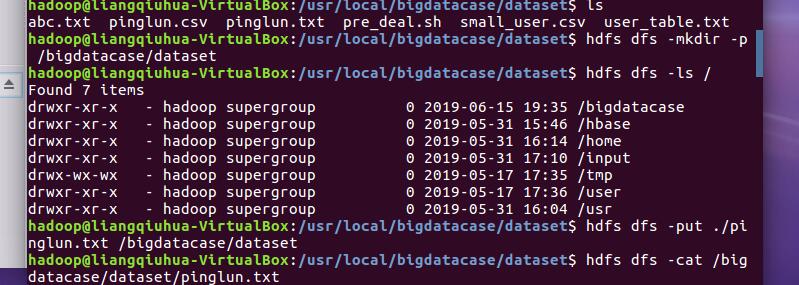
文件名为pinglun.csv,pinglun.txt并且上传到hdfs中
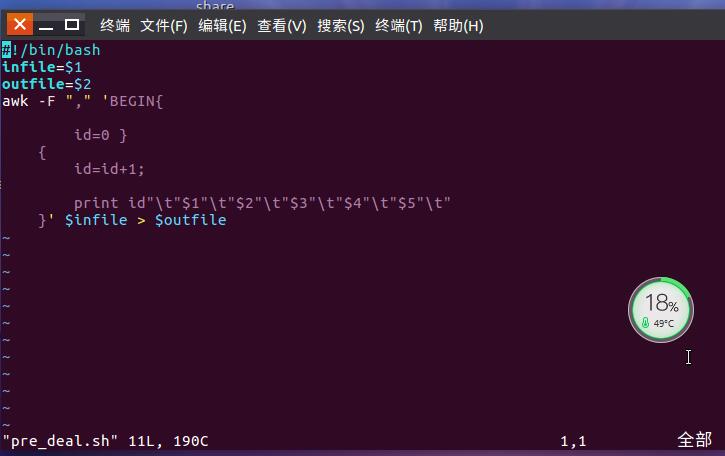
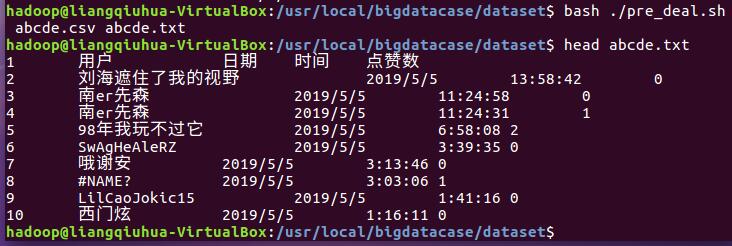
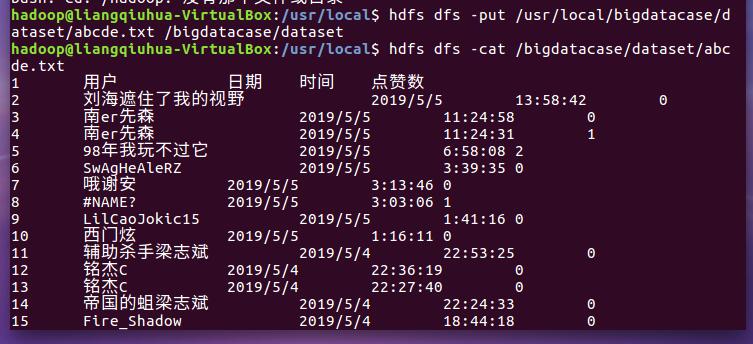
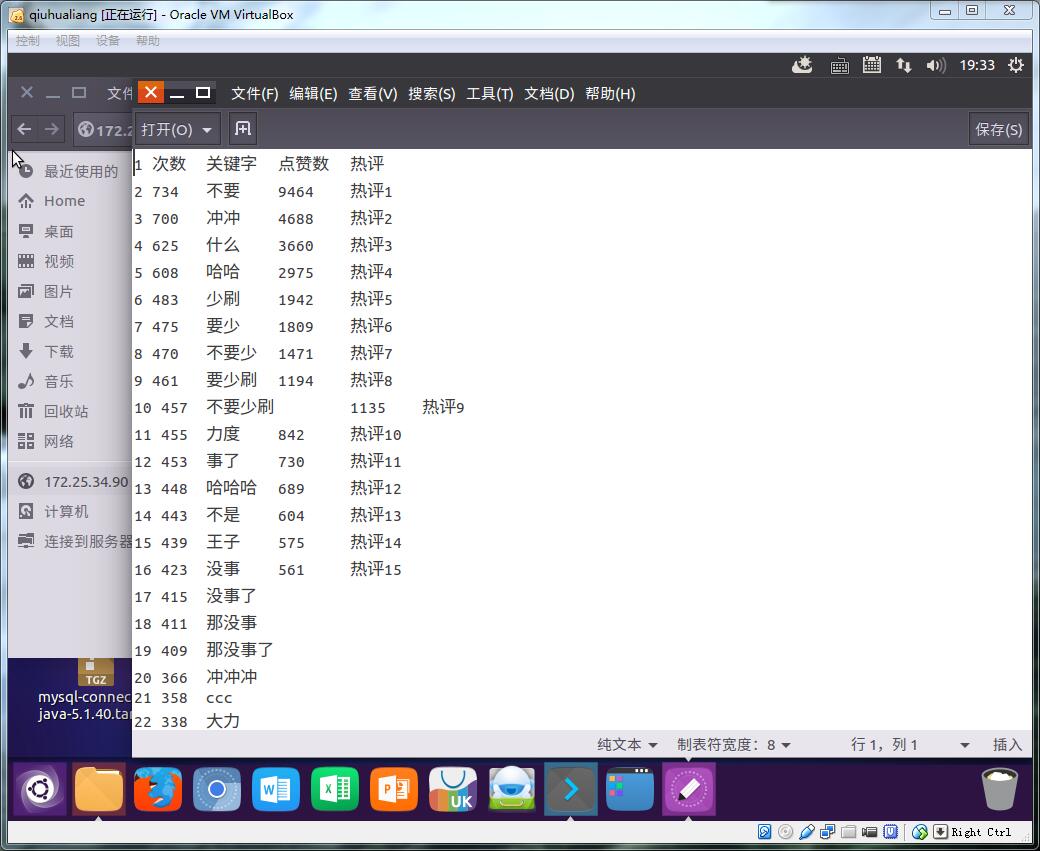
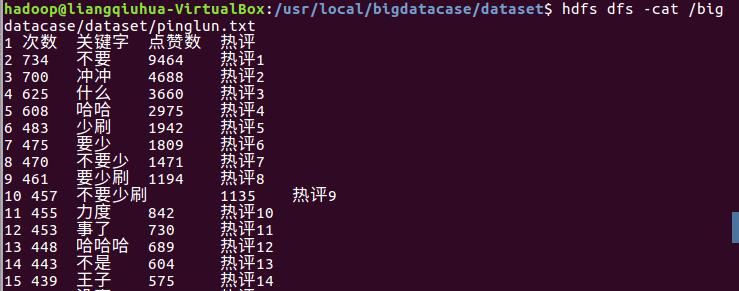
以上是打开文件后的情况
2.hadoop,mysql,hive 服务打开

3.在hive中进行数据操作
(1)首先创建一张pinglun.bigdata_user的数据表

(2)用语句进行操作:
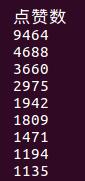
以热评点赞数排序 列名为dianzanshu
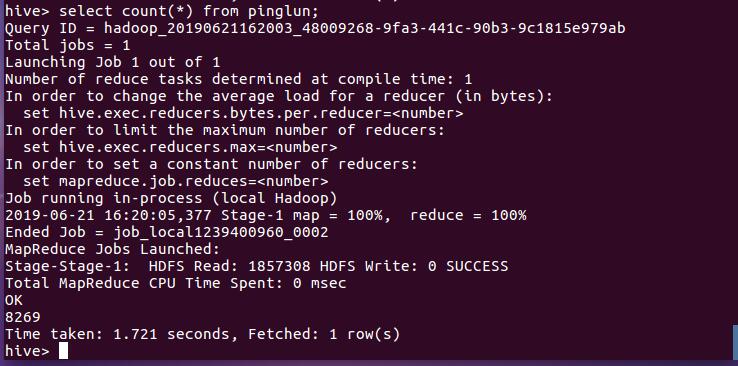
查看一共有多少条热评, 结果8269
列出关键字列名为guanjianzi

查看关键字有没“梁秋华” ,并没有

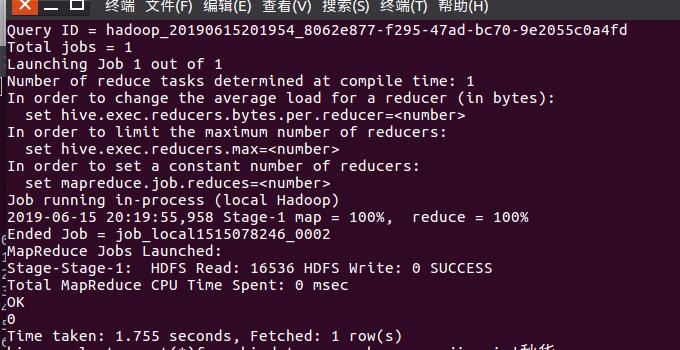
查看热评1的点赞数


查看c在热评中出现的次数


查看用户名‘包‘在数据库表出现’次数
 ’
’
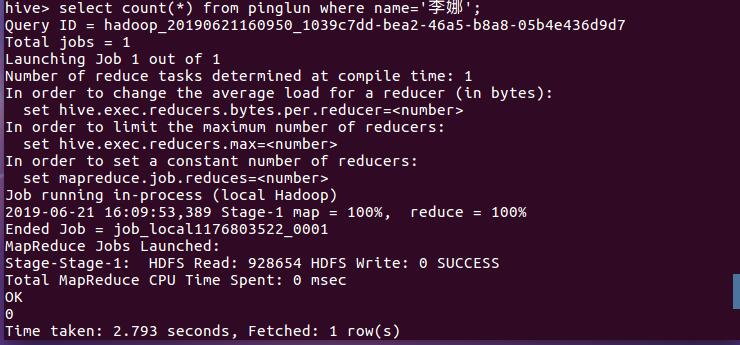
查看有无李娜这个用户名
4.总结
总体来说,我们这次大作业结合了几乎一大半学期的知识,首先是利用python爬取自己感兴趣的数据(我爬取的是虎牙某主播的BGM网易云音乐评论),将数据通过HDFS传入数据库中,再利用MYSQL和HIVE对数据进行处理分析。
说一下遇到的问题:
(1)导入txt或者csv文件在Hadoop中打开时,会出现乱码,结果是在外部自己电脑处理数据时应该注意编码方式Utf-8
(2)在数据分析处理时出现了许多NULL,在进行数据表查询的时候出现了问题
(3)对数据的预处理真的是一个难题,对脚本pre_deal.sh不理解
