
python常用函数
enumerate函数


,Python内建了⼀个enumerate函数,可以返 回(i, value)元组序列: for i, value in enumerate(collection): # do something with value 当你索引数据时,使⽤enumerate的⼀个好⽅法是计算序列(唯 ⼀的)dict映射到位置的值: In [83]: some_list = ['foo', 'bar', 'baz'] In [84]: mapping = {} In [85]: for i, v in enumerate(some_list): ....: mapping[v] = i In [86]: mapping Out[86]: {'bar': 1, 'baz': 2, 'foo': 0}
sorted函数
sorted函数可以从任意序列的元素返回⼀个新的排好序的列表: In [87]: sorted([7, 1, 2, 6, 0, 3, 2]) Out[87]: [0, 1, 2, 2, 3, 6, 7] In [88]: sorted('horse race') Out[88]: [' ', 'a', 'c', 'e', 'e', 'h', 'o', 'r', 'r',
zip函数
1.zip可以将多个列表、元组或其它序列成对组合成⼀个元组列 表: In [89]: seq1 = ['foo', 'bar', 'baz'] In [90]: seq2 = ['one', 'two', 'three'] In [91]: zipped = zip(seq1, seq2) In [92]: list(zipped) Out[92]: [('foo', 'one'), ('bar', 'two'), ('baz', 'three')] 2.zip可以处理任意多的序列,元素的个数取决于最短的序列: In [93]: seq3 = [False, True] In [94]: list(zip(seq1, seq2, seq3)) Out[94]: [('foo', 'one', False), ('bar', 'two', True)] 3.zip的常⻅⽤法之⼀是同时迭代多个序列,可能结合enumerate 使⽤: In [95]: for i, (a, b) in enumerate(zip(seq1, seq2)): ....: print('{0}: {1}, {2}'.format(i, a, b)) ....: 0: foo, one 1: bar, two 2: baz, three 4.给出⼀个“被压缩的”序列,zip可以被⽤来解压序列。也可以当 作把⾏的列表转换为列的列表。这个⽅法看起来有点神奇: In [96]: pitchers = [('Nolan', 'Ryan'), ('Roger', 'Clemens'), ....: ('Schilling', 'Curt')] In [97]: first_names, last_names = zip(*pitchers) In [98]: first_names Out[98]: ('Nolan', 'Roger', 'Schilling') In [99]: last_names Out[99]: ('Ryan', 'Clemens', 'Curt')
reversed函数
reversed可以从后向前迭代⼀个序列: In [100]: list(reversed(range(10))) Out[100]: [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
字典
1.字典可能是Python最为重要的数据结构。它更为常⻅的名字是哈 希映射或关联数组。它是键值对的⼤⼩可变集合,键和值都是 Python对象。创建字典的⽅法之⼀是使⽤尖括号,⽤冒号分隔键 和值: 创建字典1:⽤序列创建字典 mapping = {} for key, value in zip(key_list, value_list): mapping[key] = value 创建字典2: In [101]: empty_dict = {} In [102]: d1 = {'a' : 'some value', 'b' : [1, 2, 3, 4]} In [103]: d1 创建字典3: In [121]: mapping = dict(zip(range(5), reversed(range(5)))) In [122]: mapping Out[122]: {0: 4, 1: 3, 2: 2, 3: 1, 4: 0} 2. 你可以像访问列表或元组中的元素⼀样,访问、插⼊或设定字典 中的元素: In [104]: d1[7] = 'an integer' In [105]: d1 Out[105]: {'a': 'some value', 'b': [1, 2, 3, 4], 7: 'an integer'} In [106]: d1['b'] Out[106]: [1, 2, 3, 4] 3.可以⽤del关键字或pop⽅法(返回值得同时删除键)删除值: In [108]: d1[5] = 'some value' In [109]: d1 Out[109]: {'a': 'some value', 'b': [1, 2, 3, 4], 7: 'an integer', 5: 'some value'} In [110]: d1['dummy'] = 'another value' In [111]: d1 Out[111]: {'a': 'some value', 'b': [1, 2, 3, 4], 7: 'an integer', 5: 'some value', 'dummy': 'another value'} In [112]: del d1[5] In [113]: d1 Out[113]: {'a': 'some value', 'b': [1, 2, 3, 4], 7: 'an integer', 'dummy': 'another value'} In [114]: ret = d1.pop('dummy') In [115]: ret Out[115]: 'another value' In [116]: d1 Out[116]: {'a': 'some value', 'b': [1, 2, 3, 4], 7: 'an integer'} 4.keys和values是字典的键和值的迭代器⽅法。虽然键值对没有 顺序,这两个⽅法可以⽤相同的顺序输出键和值: In [117]: list(d1.keys()) Out[117]: ['a', 'b', 7] In [118]: list(d1.values()) Out[118]: ['some value', [1, 2, 3, 4], 'an integer'] 5.⽤update⽅法可以将⼀个字典与另⼀个融合:update⽅法是原地改变字典,因此任何传递给update的键的旧 的值都会被舍弃。 In [119]: d1.update({'b' : 'foo', 'c' : 12}) In [120]: d1 Out[120]: {'a': 'some value', 'b': 'foo', 7: 'an integer', 'c':12})
get
1. if key in some_dict: value = some_dict[key] else: value = default_value 等价于 value = some_dict.get(key, default_value)
通过⾸字⺟,将⼀个列表中的单词分类:
方法1: In [123]: words = ['apple', 'bat', 'bar', 'atom', 'book'] In [124]: by_letter = {} In [125]: for word in words: .....: letter = word[0] .....: if letter not in by_letter: .....: by_letter[letter] = [word] .....: else: .....: by_letter[letter].append(word) .....: In [126]: by_letter Out[126]: {'a': ['apple', 'atom'], 'b': ['bat', 'bar', 'book']} 方法2: setdefault⽅法 for word in words: letter = word[0] by_letter.setdefault(letter, []).append(word) 方法3:分类函数 from collections import defaultdict by_letter = defaultdict(list) for word in words: by_letter[word[0]].append(word)
有关集合操作
集合是⽆序的不可重复的元素的集合。你可以把它当做字典,但 是只有键没有值。 1. 可以⽤两种⽅式创建集合:通过set函数或使 ⽤尖括号set语句: In [133]: set([2, 2, 2, 1, 3, 3]) Out[133]: {1, 2, 3} In [134]: {2, 2, 2, 1, 3, 3} Out[134]: {1, 2, 3} 2. 集合⽀持合并、交集、差分和对称差等数学集合运算。考虑两个 示例集合: In [135]: a = {1, 2, 3, 4, 5} In [136]: b = {3, 4, 5, 6, 7, 8} 合并是取两个集合中不重复的元素。可以⽤union⽅法,或者| 运算符: In [137]: a.union(b) Out[137]: {1, 2, 3, 4, 5, 6, 7, 8} In [138]: a | b Out[138]: {1, 2, 3, 4, 5, 6, 7, 8} 交集的元素包含在两个集合中。可以⽤intersection或&运算 符: In [139]: a.intersection(b) Out[139]: {3, 4, 5} In [140]: a & b Out[140]: {3, 4, 5}
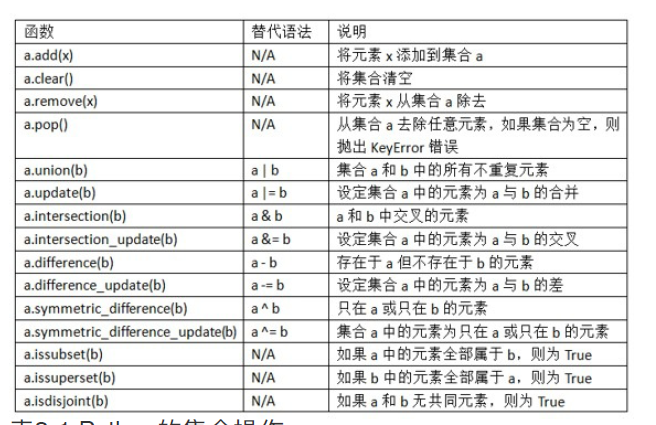
1. 所有逻辑集合操作都有另外原地实现⽅法,它可以直接⽤结果替 代集合的内容。对于⼤的集合,这么做效率更⾼: In [141]: c = a.copy() In [142]: c |= b In [143]: c Out[143]: {1, 2, 3, 4, 5, 6, 7, 8} In [144]: d = a.copy() In [145]: d &= b In [146]: d Out[146]: {3, 4, 5} 2. 集合的内容相同时,集合才对等: In [153]: {1, 2, 3} == {3, 2, 1} Out[153]: True
列表、集合和字典推导式
1.列表推导式 列表推导式是Python最受喜爱的特性之⼀。它允许⽤户⽅便的从 ⼀个集合过滤元素,形成列表,在传递参数的过程中还可以修改 元素。形式如下: [expr for val in collection if condition] 它等同于下⾯的for循环; result = [] for val in collection: if condition: result.append(expr) 例如:将列表中的字符转换为大写 In [154]: strings = ['a', 'as', 'bat', 'car', 'dove', 'python'] In [155]: [x.upper() for x in strings if len(x) > 2] Out[155]: ['BAT', 'CAR', 'DOVE', 'PYTHON'] 2.字典推导式(对字典的key进行操作) dict_comp = {key-expr : value-expr for value in collection if condition} a=dict(zip(range(5),reversed(range(5)))) print(a) b={key+1 for key in a if key>2} print(b) 3.集合推导式 set_comp = {expr for value in collection if condition}
strip
#!/usr/bin/python # -*- coding: UTF-8 -*- str = "00000003210Runoob01230000000"; print str.strip( '0' ); # 去除首尾字符 0 str2 = " Runoob "; # 去除首尾空格 print str2.strip();
restrip
Python rstrip() 删除 string 字符串末尾的指定字符(默认为空格). #!/usr/bin/python str = " this is string example....wow!!! "; print str.rstrip(); str = "88888888this is string example....wow!!!8888888"; print str.rstrip('8'); 输出结果: this is string example....wow!!! 88888888this is string example....wow!!!
sub函数
1. re是regular expression的所写,表示正则表达式 sub是substitute的所写,表示替换; re.sub是个正则表达式方面的函数,用来实现通过正则表达式,实现比普通字符串的replace更加强大的替换功能; 举个最简单的例子: 如果输入字符串是: inputStr = "hello 111 world 111" replacedStr = inputStr.replace("111", "222") "hello 222 world 222" 2. re.sub(pattern, repl, string, count=0, flags=0) eg. inputStr = "hello 123 world 456" replacedStr = re.sub("\d+", "222", inputStr) count参数:匹配个数
title()方法语法:
#!/usr/bin/python str = "this is string example....wow!!!"; print str.title();
lambda函数
def short_function(x): return x * 2 equiv_anon = lambda x: x * 2
⽣成器表达式也可以取代列表推导式,作为函数参数:
In [191]: sum(x ** 2 for x in range(100))#只需要把列表推导式的[]变为()即可 Out[191]: 328350 In [192]: dict((i, i **2) for i in range(5)) Out[192]: {0: 0, 1: 1, 2: 4, 3: 9, 4: 16}
itertools模块
In [193]: import itertools In [194]: first_letter = lambda x: x[0] In [195]: names = ['Alan', 'Adam', 'Wes', 'Will', 'Albert', 'Steven'] In [196]: for letter, names in itertools.groupby(names, first_letter) print(letter, list(names)) # names is a generator A ['Alan', 'Adam'] W ['Wes', 'Will'] A ['Albert'] S ['Steven']


 浙公网安备 33010602011771号
浙公网安备 33010602011771号