

ElasticStack系列之二 & ElasticStack整体架构
1. ElasticSearch的几个基本概念

<1. Index
类似于mysql数据库中的database
<2. Type
类似于mysql数据库中的table表,es中可以在Index(database)中建立多个type(table),其中每个type结构可以使不同的,通过mapping进行映射。
<3. Document
由于es存储的数据是文档型的,一条数据对应一篇文档即相当于mysql数据库中的一行数据row,一个文档中可以有多个字段也就是mysql数据库一行可以有多列。
<4. Field
es中一个文档中对应的多个列与mysql数据库中每一列对应
<5. Mapping
可以理解为mysql或者solr中对应的schema,只不过有些时候es中的mapping增加了动态识别功能,感觉很强大的样子,其实实际生产环境上不建议使用,最好还是开始制定好了对应的schema为主。
<6. indexed
就是名义上的建立索引。mysql中一般会对经常使用的列增加相应的索引用于提高查询速度,而在es中默认都是会加上索引的,除非你特殊制定不建立索引只是进行存储用于展示,这个需要看你具体的需求和业务进行设定了。
<7. Query DSL
类似于mysql的sql语句,只不过在es中是使用的json格式的查询语句,专业术语就叫:QueryDSL
<8. GET/PUT/POST
分别类似与mysql中的select/update/delete......
2. ElasticSearch整体架构图
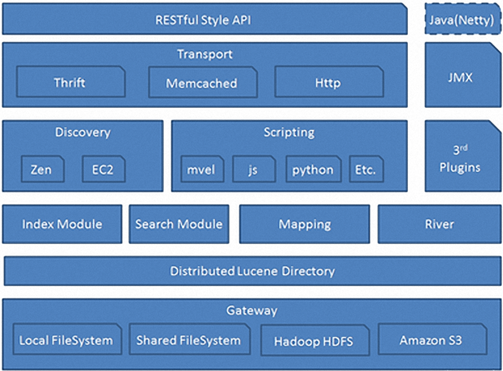
从下往上逐层讲解:
1. Gateway层
es用来存储索引文件的一个文件系统且它支持很多类型,例如:本地磁盘、共享存储(做snapshot的时候需要用到)、hadoop的hdfs分布式存储、亚马逊的S3。它的主要职责是用来对数据进行长持久化以及整个集群重启之后可以通过gateway重新恢复数据。
gateway.type: local/none
gateway.recover_after_nodes: 8
gateway.expected_nodes: 10
gateway.recover_after_time: 5m
上面这个配置是表示本地磁盘同步,目的是为了防止集群恢复时不发生意想不到的问题。gateway.expected_nodes: 10 --> 表示预期整个集群完整恢复是10个数据节点,而recover_after_nodes:8 --> 表示恢复的时候必须当节点恢复8个以上的时候才开始恢复同步恢复数据,但是此时不是立马就恢复数据,需要看gateway.recover_after_time: 5m参数,当节点恢复够8个节点时,需要等待5分钟,如果5分钟之内预期的10个节点都恢复了就立马恢复数据;如果等待超过5分钟预期的10个节点没有完全恢复完毕,则也进行恢复数据。后续剩余的节点再恢复起来,则集群再将剩余的节点加入到集群中重新同步。
注意:以上配置都是基于2.2.x版本,截止到2017/3/4 为止,ELK版本都为5.2.2,已经将gateway配置全局参数去掉了,但是也有相对应的参数可以进行设置,该思想需要我们注意,为后续的优化做储备。
2. Distributed Lucene Directory
Gateway上层就是一个lucene的分布式框架,lucene是做检索的,但是它是一个单机的搜索引擎,像这种es分布式搜索引擎系统,虽然底层用lucene,但是需要在每个节点上都运行lucene进行相应的索引、查询以及更新,所以需要做成一个分布式的运行框架来满足业务的需要。
3. 四大模块组件
districted lucene directory之上就是一些es的模块,Index Module是索引模块,就是对数据建立索引也就是通常所说的建立一些倒排索引等;Search Module是搜索模块,就是对数据进行查询搜索;Mapping模块是数据映射与解析模块,就是你的数据的每个字段可以根据你建立的表结构通过mapping进行映射解析,如果你没有建立表结构,es就会根据你的数据类型推测你的数据结构之后自己生成一个mapping,然后都是根据这个mapping进行解析你的数据;River模块在es2.0之后应该是被取消了,它的意思表示是第三方插件,例如可以通过一些自定义的脚本将传统的数据库(mysql)等数据源通过格式化转换后直接同步到es集群里,这个river大部分是自己写的,写出来的东西质量参差不齐,将这些东西集成到es中会引发很多内部bug,严重影响了es的正常应用,所以在es2.0之后考虑将其去掉。
4. Discovery、Script
es4大模块组件之上有 Discovery模块:es是一个集群包含很多节点,很多节点需要互相发现对方,然后组成一个集群包括选主的,这些es都是用的discovery模块,默认使用的是 Zen,也可是使用EC2;es查询还可以支撑多种script即脚本语言,包括mvel、js、python等等。
5. Transport协议层
再上一层就是es的通讯接口Transport,支持的也比较多:Thrift、Memcached以及Http,默认的是http,JMX就是java的一个远程监控管理框架,因为es是通过java实现的。
6. RESTful接口层
最上层就是es暴露给我们的访问接口,官方推荐的方案就是这种RESTful接口,直接发送http请求,方便后续使用nginx做代理、分发包括可能后续会做权限的管理,通过http很容易做这方面的管理。如果使用java客户端它是直接调用api,在做负载均衡已经权限管理还是不太好做。
3. ElasticSearch各节点的认识

masternode:true datanode:true 既可以masternode也可以datanode
masternode:true datanode:false 只可以masternode
masternode:false datanode:true 只可以datanode
masternode:false datanode:false 只可以clientnode
master node:负责整个集群的管理,包括元数据的管理、新节点的加入和退出,所以 masternode 是整个集群中最重要的,相当于人的大脑一样,集群所有的更新管理都是由 master 来做的,而es是分布式系统,需要保证 masternode 高可用,所以需要配置多个 master 被选者即凡是你将 masternode 设置为 true 那么它们都是备选,当前的 masternode 挂掉 ElasticSearch 就会从其余备选的 node 中选出一个作为新的 masternode。
data node:它不负责元数据的管理、新节点的加入和退出,这都是 master 通知它来干的事情,即 master 让它干什么它就干什么,且 master 会将元数据发给 datanode 存储一份,同样的也会给 clientnode 发送一份元数据,由上图也可以看出来,当请求发送给 clientnode,clientnode 直接发送给 datanode 它是不需要通过 masternode 转发的。这里有一个好处就是可以避免单点故障的,(了解 hadoop 的就知道,namenode 也即 ElasticSearch 中的 master,它所有的原信息都存放在 namenode 上,不管是查询还是导入数据都是通过 namenode 查询定位才导入,这样可想而知当你的集群规模大且数据量比较大对应的 QPS 特别高的情况下,那你的 namenode 压力就特别大了。即使集群可以水平扩展但是 namenode 是瓶颈),而 ElasticSearch 就不需要,因为不管是 datanode 还是 clientnode 每个节点上都存有元信息,可以直接知道哪个数据在哪个分片上,这里不需要 masternode。datanode 只负责对数据的索引、查询、存储方面的需求。
masternode 一般 10G 就算高的了,但是 datanode 和 clientnode 需要配置高点,一般配置为 32G 左右
client node:它即不负责元数据管理、新节点加入和退出,也不负责存储数据。一般用 clientnode 做为查询使用,即用户发送的请求都放到 clientnode 上,clientnode 再将不同的查询发送到不同的 datanode 上进行查询,查询返回结构后再在 clientnode 做一次加工,例如再此基础上在做一次分组、统计或者排序等等的工作,然后再返回给客户端。clientnode 可以看做是客户端和es之间的一个过滤器或者交互人。
4. ElasticSearch 集群健康状态
我们可以通过命令得到集群的健康状态:
| 颜色 | 意义 |
| green | 所有主要分片(primary shard) 和复制分片都可用 |
| yellow | 所有主要分片可用(primary shard),但不是所有复制分片都可用 |
| red | 不是所有的主要分片都可用 |
有时候会有这种情况,当我们在自己电脑上启动一个实例节点,之后我们创建一个索引,指定:3主1从 --> 6个节点。之后我们通过命令查看发现集群状态是 yellow,即表示所有的主分片启动完成且运行正常,集群可以正常处理任何请求,但是复制分片还没有全部可用。事实上所有的3个复制分片现在都还是 unassigned 状态,它们还未被分配给节点。因为在同一个节点上保存相同的数据副本是没有必要的,如果这个节点故障了,那所有的数据副本也会丢失。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号