
HashMap1.7 vs 1.8
jdk 由 1.7 升级到 1.8 底层改动很大,今天我们先来看一下其中一个基本结构 hashmap 的优化改动。那么具体hashmap1.7 和 hashmap1.8 有哪些区别呢?
1. JDK1.7用的是头插法,而 JDK1.8及之后使用的都是尾插法
那么他们为什么要这样做呢?
因为 JDK1.7 是用单链表进行的纵向延伸,当采用头插法就是能够提高插入的效率,效率高的原因:
1. 头插法不需要遍历到链表尾部插入,节省了一定的遍历时间
2. 我们一般认为后插入的数据比较热,所以当遇到查询节点的时候可能会节省遍历查询对比的时间
3. resize后链表可能倒序; 并发resize可能产生循环链。为什么会出现环形链表死循环问题呢?
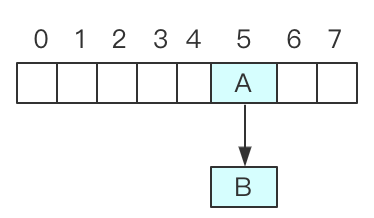
假设初始 map 大小为 8,threadA 和 threadB 两个线程想 hashMap 中添加数据,假设 threadA 获取了执行权,向 hashmap 插入数据的时候开始扩容,此时创建了一个新的数组,还没来得及转移旧的数据,此时的状态为:
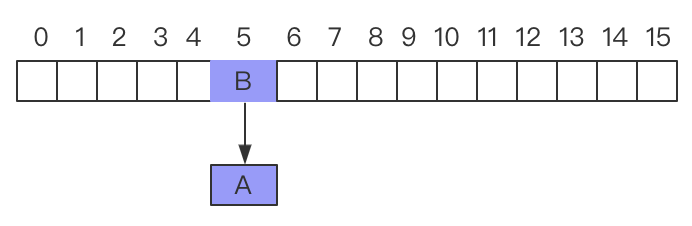
此时 threadB 开始执行,假设 threadB 开始执行之后,添加数据的时候又开始扩容,此时 threadB 创建新数组通过完成了所有的操作,此时状态:
假设此时 threadA 获取到执行权,那么 threadA 开始执行,此时 threadA 还是如下图所示,状态没有发生变化:
那么,此时我们可以看到数据 A 指向 B,刚才 threadB 执行完成之后数据 B 执行 A,此时就形成了循环列表为:
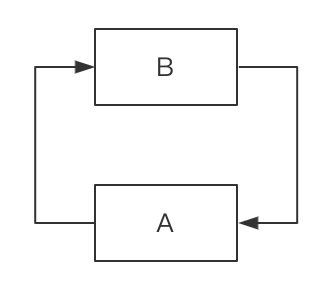
在 JDK1.8 之后使用尾插法方式插入数据,能够避免出现逆序且链表死循环的问题。
2. 扩容后数据迁移流程(transfer)不一样
首先我们需要知道,hashmap 底层在计算下标位置的时候算法都是一样的,都是直接用 hash值 和 需要扩容的二进制数进行 & 运算,在计算 indexOf 的即应该存放的哪个下标位置的时候使用计算公式为:hash值 & (length-1)
这里有必要解释一下 jdk 源码为什么使用 & 的方式来计算,按照我们正常的思维方式不应该是 hash % length 吗?
其实 hash%length == hash&(length-1),而 & 操作是 % 操作运算速度提升了一个量级,故为什么 jdk 源码使用了 & 操作来计算 indexOf。
为了有同学还不理解两者为什么相等,这里用实际例子来解释:
我们hashmap 默认初始值大小为 16,那么 length=16 转为二进制是:10000, 假设 hash 值为 25 转为 二进制是:11001 即:
初始数据:11001
数组长度: 1111
按位 & : 1001
取模运算: 1001
结论:11001 & 1111 = 1001 (25 & (16 - 1))
11001 % 1000 = 1001 (25 % 16)
这就是为什么扩容的时候为啥一定必须是2的多少次幂的原因所在,因为如果只有2的n次幂的情况时,length -1 最后一位二进制数才一定是1,这样能最大程度减少hash碰撞。
但是 jdk1.7 扩容后迁移的流程:
1. 首先新创建 2*length 大小的新数组
2. 将原来老数组上的数据挨个拍的迁移到新的数组上
jdk1.8 扩容后的迁移的流程有个技巧性的优化:
1. 首先新创建 2 * length 大小的新数组
2. 扩容前的原始位置 + 扩容的大小值,这种方式就相当于只需要判断Hash值的新增参与运算的位是0还是1就直接迅速计算出了扩容后的储存方式,非常的高效。这里有必要解释一下
重新回顾一下我们👆刚解释的 hash%length == hash&(length-1) 公式,那么我们试想一下,当 length 扩大为 2*length,从二进制上观察可以发现扩容后后几位不会发生变化,只是高位又增加了以为,例如:刚开始 length=16 扩容后为 32,(length-1) 二进制变化也就是高位多加了即:15-->31 | 1111-->11111
以上面的例子来看,那么我们的思路就来了,既然扩容后二进制后四位没有发生变化,只是在第 5 位多增加了一位,那么我们是否可以这样认为:
凡是小于 length 的值都可以直接指向(因为 hash&(length-1) 不会发生变化,即当前数据的下标位置不会发生变化),大于 length 的值只需要看新增参与运算的位是 0 还是 1,是 0 就不变,是 1 就相应的增加对应扩容的值,具体如下图所示:

总结详情如下图所示:
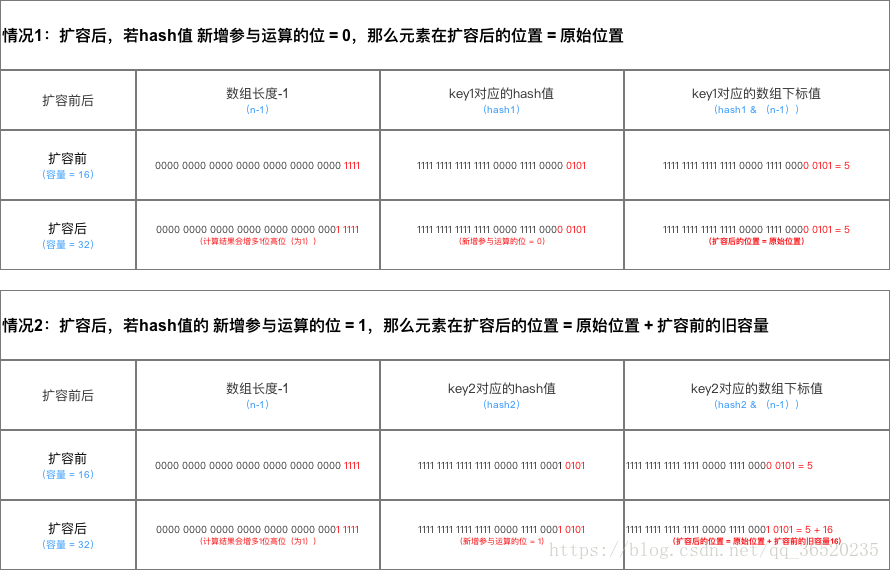
由上图可知:在计算hash值的时候,JDK1.7用了9次扰动处理=4次位运算+5次异或,而JDK1.8只用了2次扰动处理=1次位运算+1次异或。
3. JDK1.7 和 JDK1.8 存储结构不同
JDK1.7 的时候使用的是:数组+ 单链表的数据结构。
JDK1.8及之后时,使用的是:数组+链表+红黑树的数据结构(当链表的深度达到8的时候,也就是默认阈值,就会自动扩容把链表转成红黑树的数据结构来把时间复杂度从O(n) 变成O(logN) 提高了效率)
4. JDK1.7 和 JDK1.8 扩容与插入数据顺序不同
JDK1.7 中先进行扩容后进行插入,而在 JDK1.8 中是先进行插入后进行扩容。
JDK1.7 中:先扩容后插入
当你发现你插入的桶是不是为空,如果不为空说明存在值就发生了hash冲突,那么就必须得扩容,但是如果不发生Hash冲突的话,说明当前桶是空的(后面并没有挂有链表),那就等到下一次发生Hash冲突的时候在进行扩容,但是当如果以后都没有发生hash冲突产生,那么就不会进行扩容了,减少了一次无用扩容,也减少了内存的使用
JDK1.8 中:先插入后扩容
主要是因为对链表转为红黑树进行的优化,因为你插入这个节点的时候有可能是普通链表节点,也有可能是红黑树节点
如果是链表节点,是否达到了 链表转化为红黑树的阈值是8,如果没有那么就还可以继续插入。
如果是红黑树节点,需要看插入红黑树节点是否还能满足当前是红黑树的特性,如果还能继续满足即还没有达到扩容的临界条件。、
这里提到了 “链表转化为红黑树的阈值是8”,为什么会是 8,而不是其它数值呢?
我们可以从jdk 源码中的注释部分分析得出:容器中节点分布在hash桶中的频率遵循泊松分布,桶的长度超过8的概率非常非常小。所以作者应该是根据概率统计而选择了8作为阀值
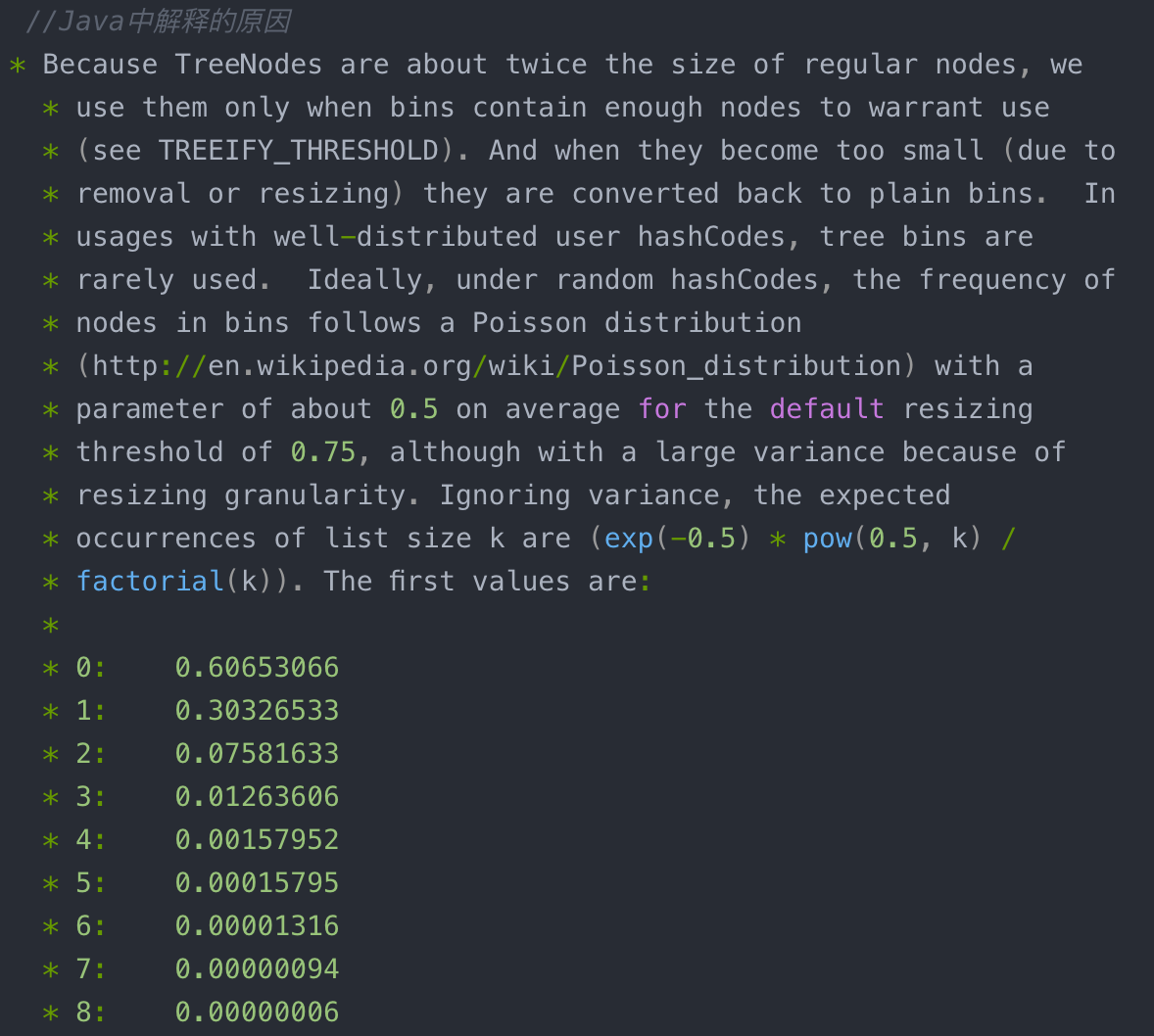
这里再总结一些面试长问的问题:
1、哈希表如何解决Hash冲突?
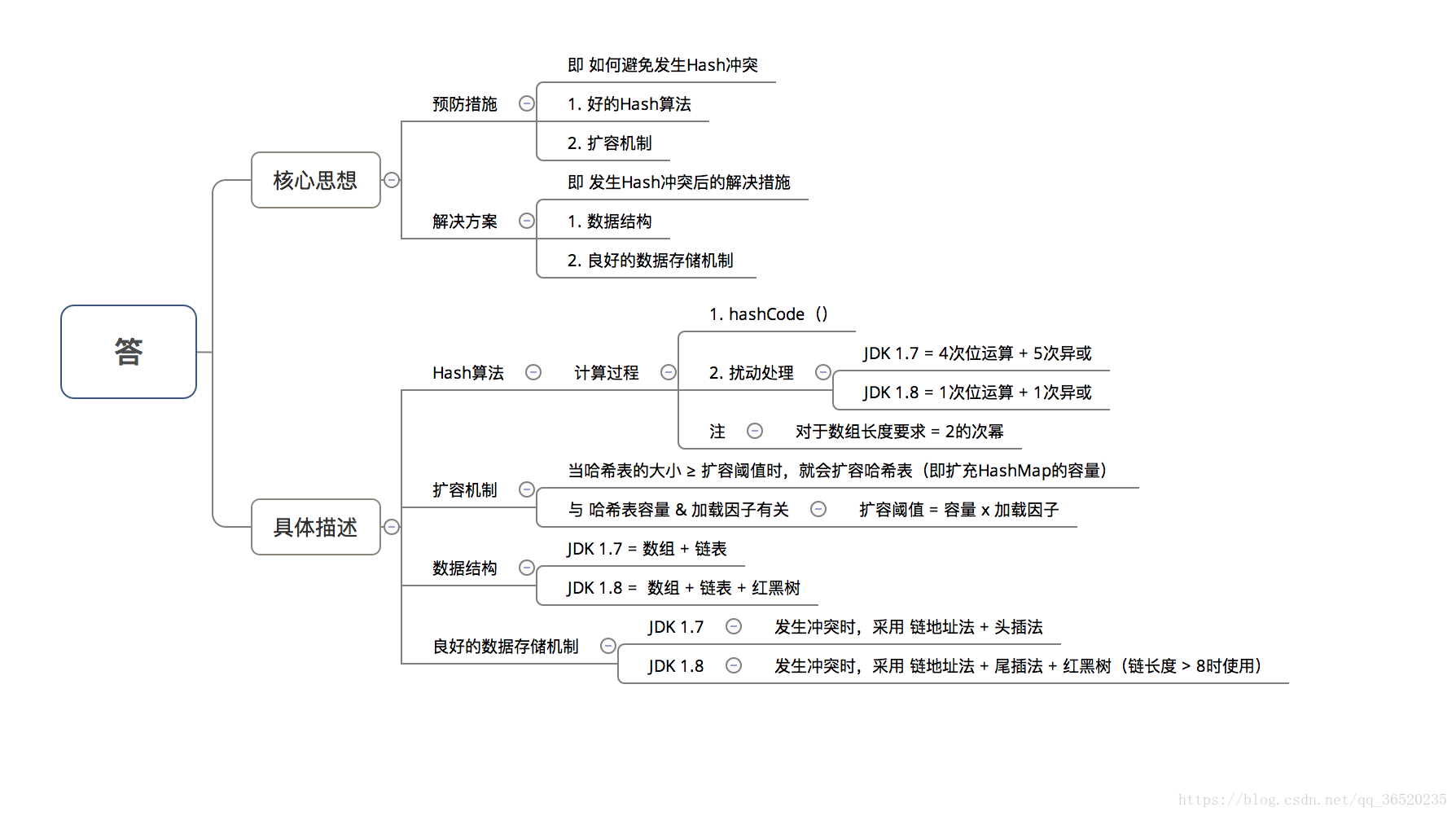
2、为什么HashMap具备下述特点
1. 键-值(key-value)都允许为空
2. 线程不安全
3. 不保证有序
4. 存储位置随时间变化
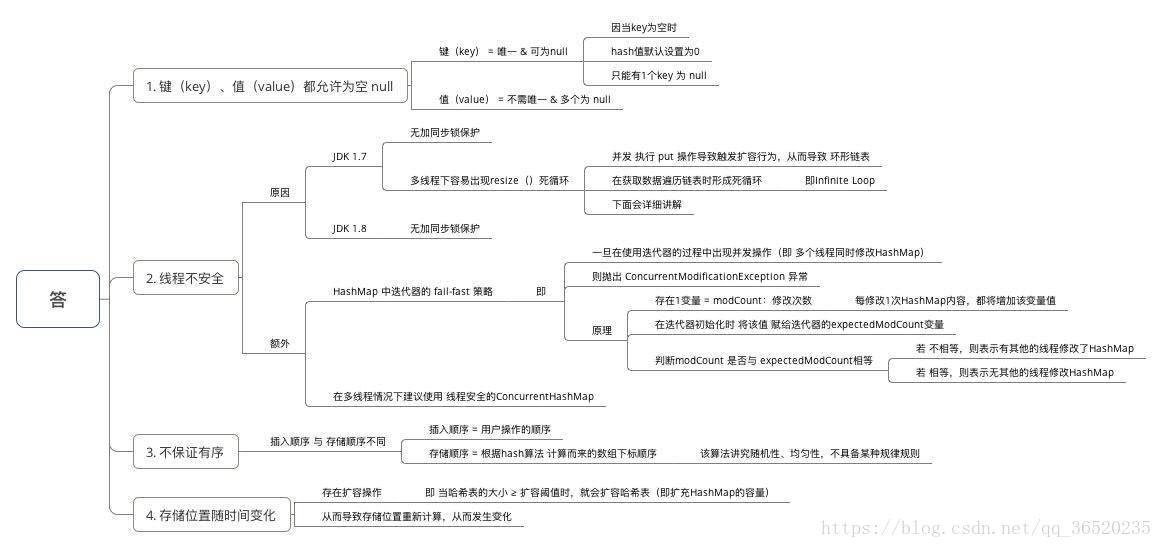
3、为什么 HashMap 中 String、Integer 这样的包装类适合作为 key 键

4、HashMap 中的 key若 Object类型, 则需实现哪些方法?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号