系统结构综合实践期末大作业 第22组
一、选题简介
选题
垃圾分类
选题理由
1、很多城市有要求垃圾分类,也有许多人因为不知道垃圾如何分类而感到烦扰。目前虽然已经有很多垃圾分类的APP,但是都是根据输入名称后搜索进行的。我们想要开发一个能直接拍照识别物品,无需打字搜索的产品。
2、我们进行树莓派应用搜索后,发现基本都是基于人脸识别的应用,我们便思考能否将人脸识别进行扩展到各类物体识别,从而定下这个题目。
二、设计
整体流程

核心代码
训练数据集构建
def __init__(self, img_paths, labels, batch_size, img_size,is_train):
assert len(img_paths) == len(labels), "len(img_paths) must equal to len(lables)"
assert img_size[0] == img_size[1], "img_size[0] must equal to img_size[1]"
## (?,41)
self.x_y = np.hstack((np.array(img_paths).reshape(len(img_paths), 1), np.array(labels)))
self.batch_size = batch_size
self.img_size = img_size
self.is_train = is_train
if self.is_train:
train_datagen = ImageDataGenerator(
rotation_range = 30, # 图片随机转动角度
width_shift_range = 0.2, #浮点数,图片宽度的某个比例,数据提升时图片水平偏移的幅度
height_shift_range = 0.2, #浮点数,图片高度的某个比例,数据提升时图片竖直偏移的幅度
shear_range = 0.2, # 剪切强度(逆时针方向的剪切变换角度)
zoom_range = 0.2, # 随机缩放的幅度,
horizontal_flip = True, # 随机水平翻转
vertical_flip = True, # 随机竖直翻转
fill_mode = 'nearest'
)
self.train_datagen = train_datagen
# # 训练集数据增强
if self.is_train:
indexs = np.random.choice([0,1,2],batch_x.shape[0],replace=True,p=[0.4,0.4,0.2])
mask_indexs = np.where(indexs==1)
multi_indexs = np.where(indexs==2)
if len(multi_indexs):
# 数据增强
multipy_batch_x = batch_x[multi_indexs]
multipy_batch_y = batch_y[multi_indexs]
train_datagenerator = self.train_datagen.flow(multipy_batch_x,multipy_batch_y,batch_size=self.batch_size)
(multipy_batch_x,multipy_batch_y) = train_datagenerator.next()
batch_x[multi_indexs] = multipy_batch_x
batch_y[multi_indexs] = multipy_batch_y
if len(mask_indexs[0]):
# 随机遮挡
mask_batch_x = batch_x[mask_indexs]
mask_batch_y = batch_y[mask_indexs]
mask_batch_x = np.array([self.cutout_img(img) for img in mask_batch_x])
batch_x[mask_indexs] = mask_batch_x
batch_y[mask_indexs] = mask_batch_y
# 预处理
batch_x =np.array([preprocess_input(img) for img in batch_x])
return batch_x, batch_y
# 训练集随机增强图片
train_sequence = BaseSequence(train_img_paths, train_labels, batch_size, [input_size, input_size],is_train=True)
validation_sequence = BaseSequence(validation_img_paths, validation_labels, batch_size, [input_size, input_size],is_train=False)
return train_sequence,validation_sequence
模型初始化
base_model = ResNet50(weights="imagenet",
include_top=False,
pooling=None,
input_shape=(FLAGS.input_size, FLAGS.input_size, 3),
classes=FLAGS.num_classes)
for layer in base_model.layers:
layer.trainable = False
model = add_new_last_layer(base_model,FLAGS.num_classes)
model.compile(optimizer="adam",loss = 'categorical_crossentropy',metrics=['accuracy'])
模型微调
def setup_to_finetune(FLAGS,model,layer_number=149):
# K.set_learning_phase(0)
for layer in model.layers[:layer_number]:
layer.trainable = False
# K.set_learning_phase(1)
for layer in model.layers[layer_number:]:
layer.trainable = True
# Adam = adam(lr=FLAGS.learning_rate,clipnorm=0.001)
Adam = adam(lr=FLAGS.learning_rate,decay=0.0005)
model.compile(optimizer=Adam,loss='categorical_crossentropy',metrics=['accuracy'])
模型训练
history_tl = model.fit_generator( #fit_generator函数接受批量数据,执行反向传播,并更新模型中的权重,生成器函数
train_sequence, #一个generator或Sequence实例,为了避免在使用multiprocessing时直接复制数据。
steps_per_epoch = len(train_sequence), #从generator产生的步骤的总数(样本批次总数)
epochs = FLAGS.max_epochs, #训练次数
verbose = 1, #日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录,数据化模式,输出训练结果
validation_data = validation_sequence, #生成验证集的生成器
max_queue_size = 10, #生成器队列的最大容量
shuffle=True #打乱数据
)
history_tl = model.fit_generator( #生成器函数
train_sequence,
steps_per_epoch = len(train_sequence),
epochs = FLAGS.max_epochs*2,
verbose = 1,
callbacks = [#ModelCheckpoint按照验证集的准确率进行保存
ModelCheckpoint('./output/best.h5', #文件路径
monitor='val_loss', #需要监视的值,通常为:val_acc 或 val_loss 或 acc 或 loss
save_best_only=True, #保存单个模型
mode='min' #在save_best_only=True时决定性能最佳模型的评判准则,当检测值为val_loss时,模式应为min。
),
ReduceLROnPlateau(monitor='val_loss',
factor=0.1, #默认0.1
patience=10, #几个epoch不变时,才改变学习速率,默认为10
mode='min'),
EarlyStopping(monitor='val_loss', patience=10),
],
validation_data = validation_sequence,
max_queue_size = 10,
shuffle=True
)
模型预测
def prediction_result_from_img(model,imgurl):
# 加载分类数据
with open("./garbage_classify/garbage_classify_rule.json", 'r') as load_f:
load_dict = json.load(load_f)
if re.match(r'^https?:/{2}\w.+$', imgurl):
test_data = preprocess_img_from_Url(imgurl,FLAGS.input_size) # url获取图片数组信息
else:
test_data = preprocess_img(imgurl,FLAGS.input_size)
tta_num = 5
predictions = [0 * tta_num]
for i in range(tta_num):
x_test = test_data[i]
x_test = x_test[np.newaxis, :, :, :]
prediction = model.predict(x_test)[0]
# print(prediction)
predictions += prediction
pred_label = np.argmax(predictions, axis=0)
print('-------深度学习垃圾分类预测结果----------')
print(pred_label)
print(load_dict[str(pred_label)])
print('-------深度学习垃圾分类预测结果--------')
return load_dict[str(pred_label)]
系统部署
dockerfile

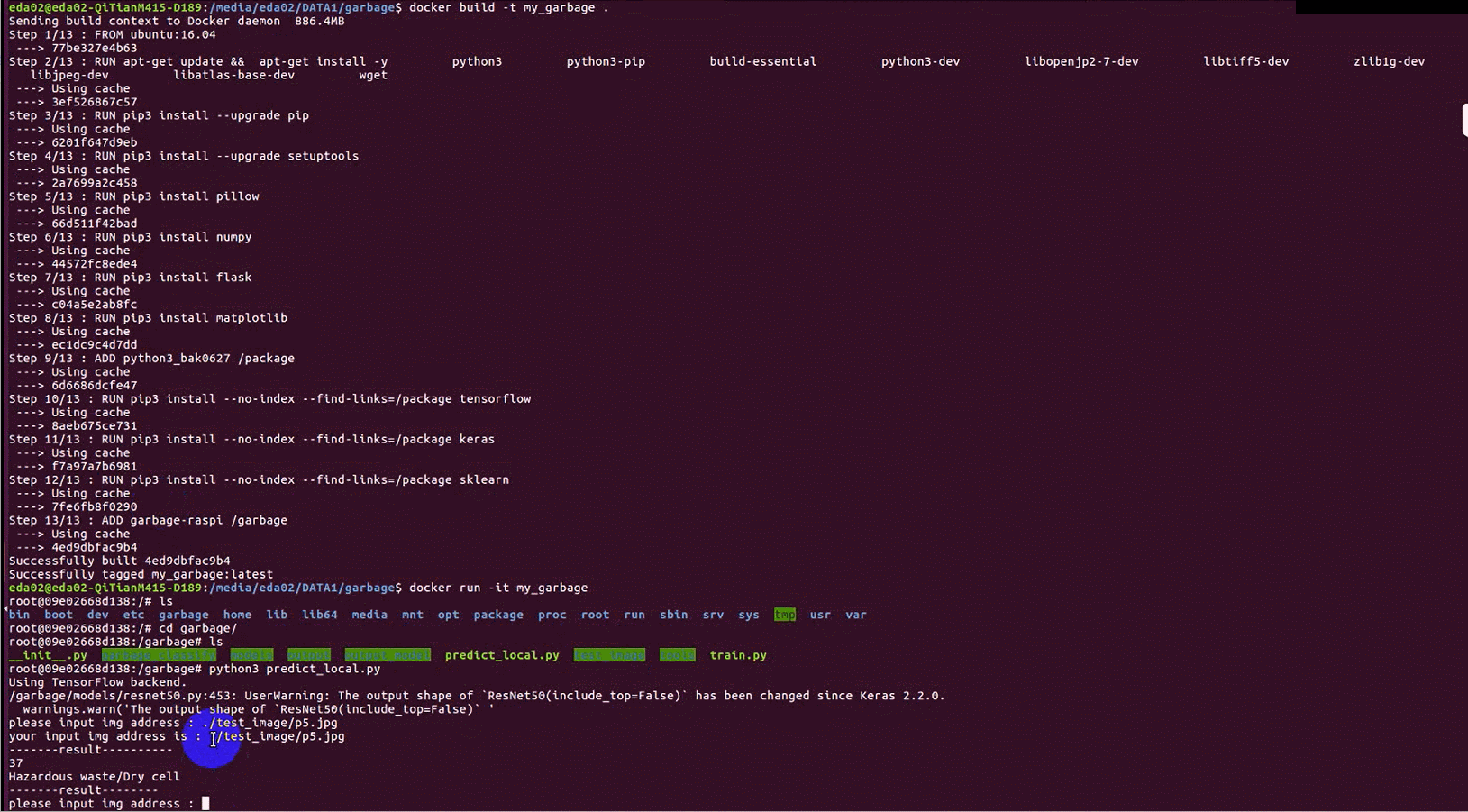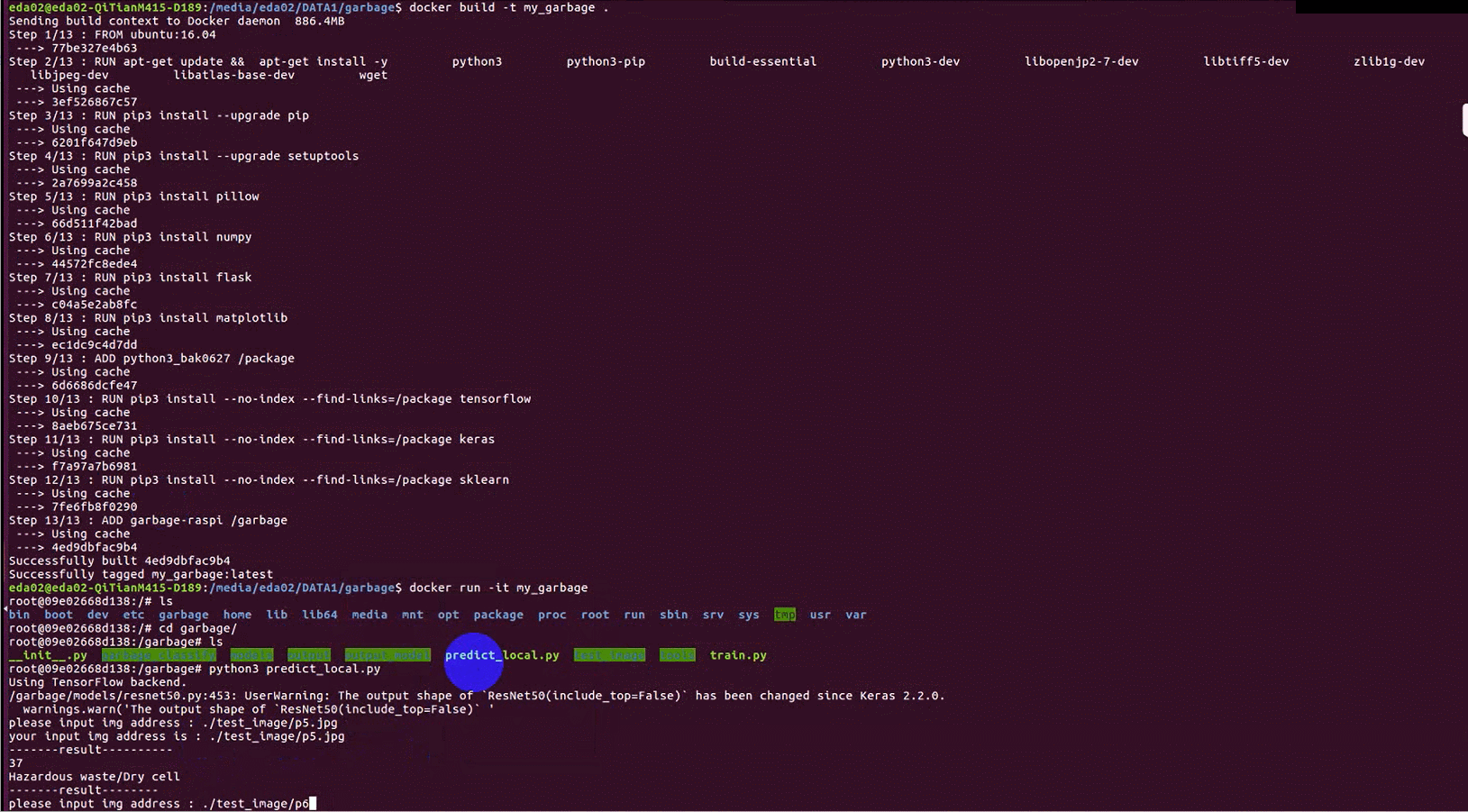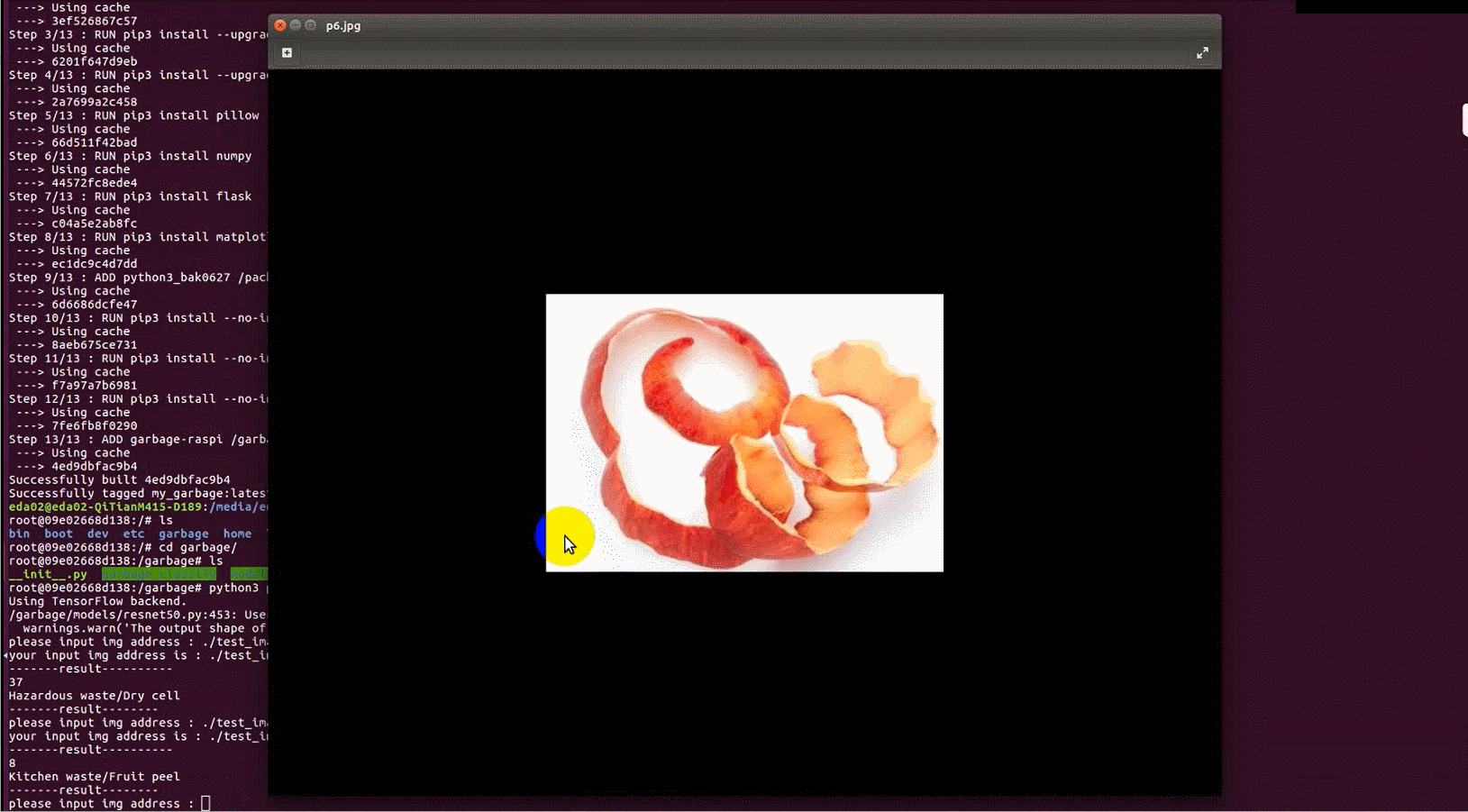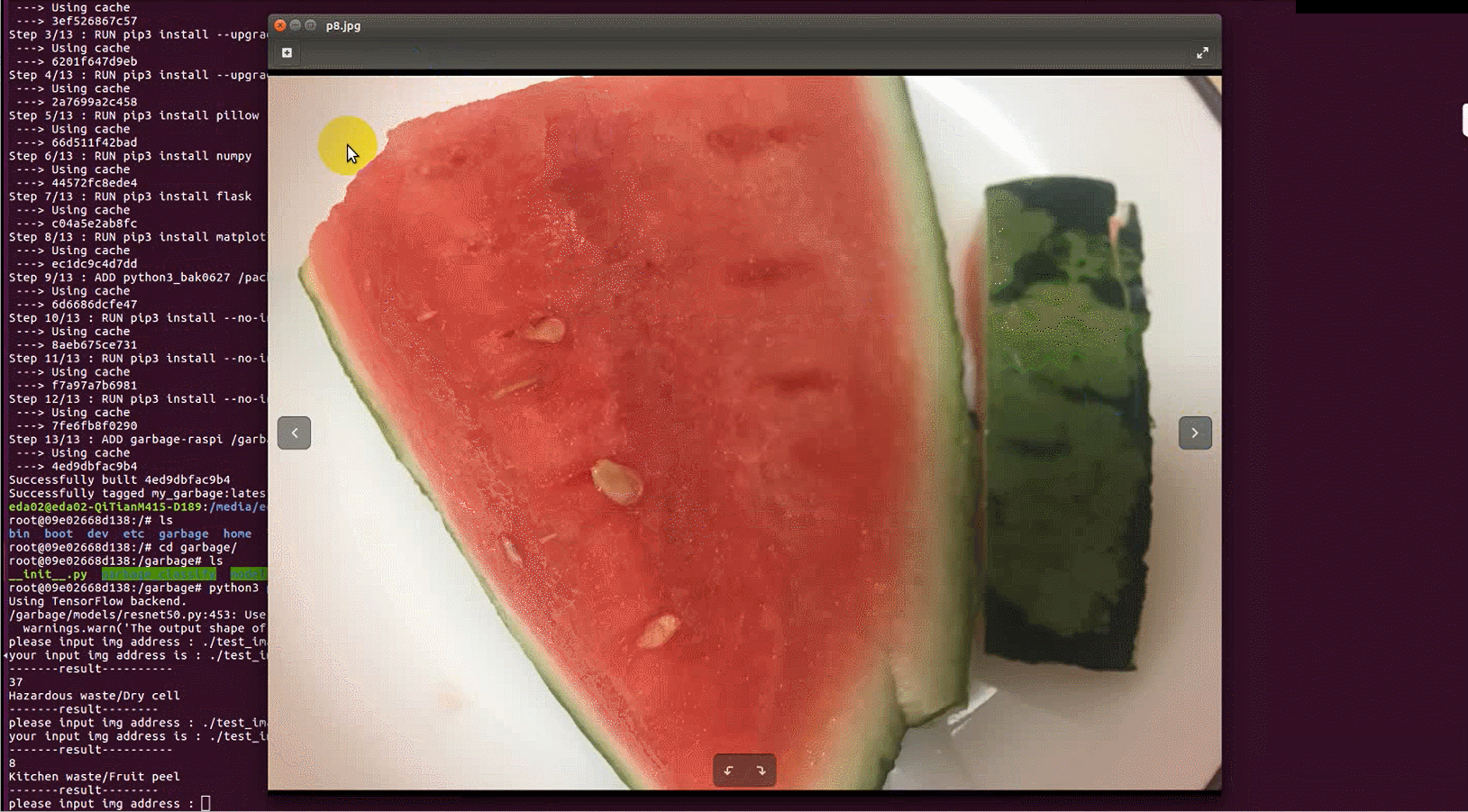
docker build -t my_garbage .

python3 predict_local.py

运行结果
检测干电池

检测果皮
组内分工+贡献比
| 学号 | 姓名 | 任务分工 | 贡献比例 |
|---|---|---|---|
| 031702539 | 李清宇 | 模型训练代码编写 | 1 |
| 031702547 | 汪佳祥 | 数据收集,打包微服务 | 1 |
| 031702521 | 杨忠燎 | 数据处理代码编写 | 1 |
| 031702208 | 叶艳玲 | resnet50模型代码编写 | 1 |
| 031702212 | 王星雨 | 模型预测代码编写 | 1 |
| 031702509 | 李享 | 相关资料学习与收集 | 1 |
总结
李清宇
这次实验最大的挑战就是我们队里没有人学过关于神经网络相关的内容,所以我们几乎是从零开始,实验过程是相当艰难的,甚至一度想要换题。但是多亏汪佳祥同学夜以继日的努力督促和鼓舞,大家才坚持了下来。每天下午都要展开小组会议,研究代码和讨论各自遇到的问题分享有用的学习资料。在这样的学习氛围下,我觉得自己的学习能力,团队协作能力都取得了非常明显的进步。
汪佳祥
经过本次的大作业实践,我更加体会到团队合作的重要性。我们对深度学习本身不是特别了解,经过这段时间的学习,能够一起实现出一个简单的垃圾分类模型,并利用这个模型进行预测。此外,我对于微服务也有了更多的体会,体会到微服务的妙处所在。通过本次实验,进一步加强了自己的编码能力以及团队协作能力,受益匪浅。
杨忠燎
在此次实验之前,只是对深度学习有一些理论知识的了解,但终究纸上得来终觉浅,绝知此事要躬行。通过跟视频的学习和Blog的参考,通过此次实验的实践,把理论知识得到了更深的加固,也学习到了很多新的方法和技能。毕竟之前实践部分没接触过,所以实践部分也算是从零开始。还好队友也很给力,我做的就是很基础的数据读入部分和预处理,所以我大部分时间是在优化数据处理上。这里也参考了很多博客方法,也学到了很多知识。也通过此次实验课,颇有收获。
叶艳玲
学习了两周的resnet50,两周的下午时间。其中遇到的最大的困难就是之前完全没有接触过深度学习这块带来的难以入手。
这次选题本来我们组员都认为垃圾分类与人脸识别类似,是有可以直接用的开源库的。结果真的做下来才发现根本不是一回事,一下子实验难度飞升,甚至后期无法部署到docker中让我们都认为前面的时间都白费了。但是没想到最后我们还是实现了,感谢组内小伙伴的坚持与毅力,让这个开题后我一度想换项目的实验成为可能。
王星雨
这次大作业对我们每个人来说都是一次比较大的挑战,所幸团队的大家都很努力完成自己负责的部分。经过这次实践,我初步接触了深度学习的相关知识,对神经网络的结构有了基本的了解,通过对Keras官方文档的阅读理解了它的许多功能,学习了选定一种骨架模型并在它的基础上进行迁移学习的流程,也加强了团队协作能力。原本意识到低估了工作量的我们还有过放弃这个项目的念头,没想到最后在大家的努力下还是在时限内完成了任务,感谢每天下午开会共同学习共同努力的队友们。
李享
通过本次时间,接触了一点深度学习的内容,看了许多资料视频,对深度学习有了些了解,基础理论知识感觉都快看到背下来了哈哈。其实还有很多东西没有弄明白,只能跟着资料糊里糊涂的做,用最笨的方法进行各种套用尝试,中间也出了很多问题,虽然最后识别准确率还不是很高,好在勉勉强强做完了。以前根本不敢碰深度学习相关的选题,这门课让我们有了更大胆的尝试,感谢系统结构综合实践这门课。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号