

第4篇: RDD学习
RDD(Resilient Distributed Dataset)弹性分布式数据集
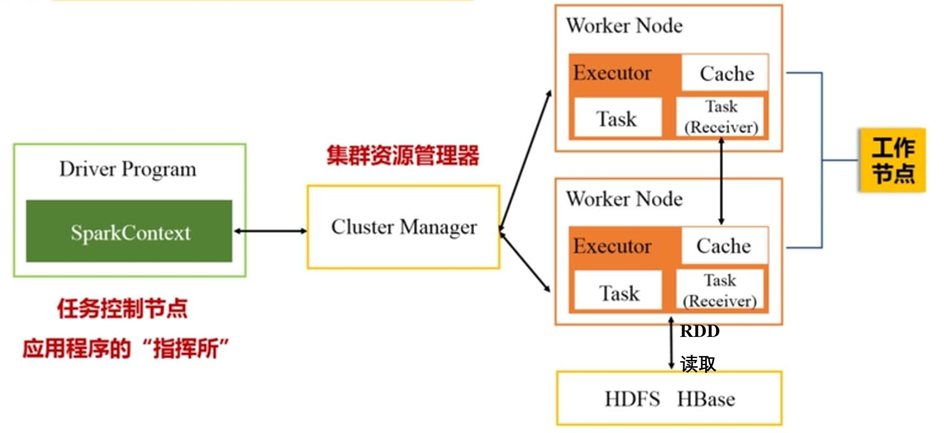
Spark程序如何工作:
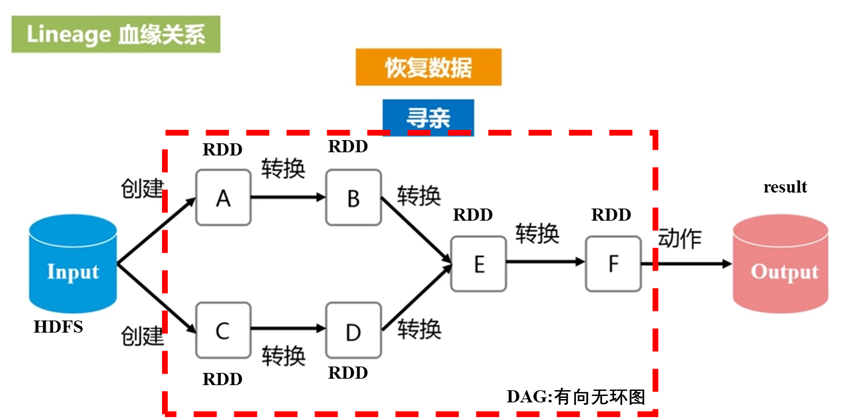
即:
step1: 从外部数据创建输入RDD
step2: 使用诸如filter()这样的转换操作对RDD进行转换,以定义新的RDD
step3: 告诉Spark对需要重用的中间结果RDD执行persist()操作
step4: 使用行动操作(如count(), first()等)来触发一次并行计算,Spark会计算进行优化后再处理。
第一部分:创建RDD
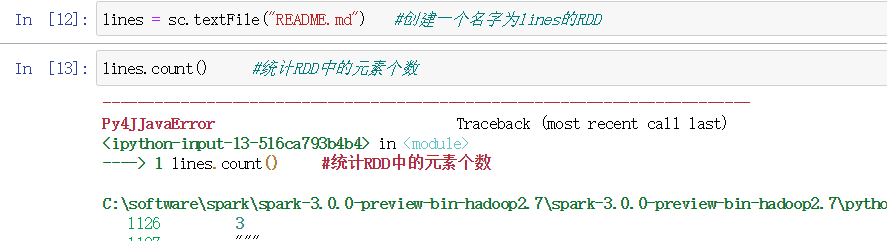
方式1 读取本地文件系统的数据集
最常用的 之前学过使用textFile()创建RDD
方式2 常用的较简单的操作是:把程序中一个已有的集合传给SparkContext的parallelize()方法
这方法需要将整个数据集先放在一台机器的内存中
lines = sc.parallelize(["pandas", "i like pandas"])
第二部分:RDD操作
转换操作和行动操作(根据返回值的类型来判断具体是转换操作还是行动操作!)
转换操作是返回一个新RDD的操作,如map() , filter();
转换操作是惰性求值,只有在行动给操作用到这些RDD时才会被计算。
例子:对一个数据为{1,2,3,3}的RDD进行基本的RDD转换操作
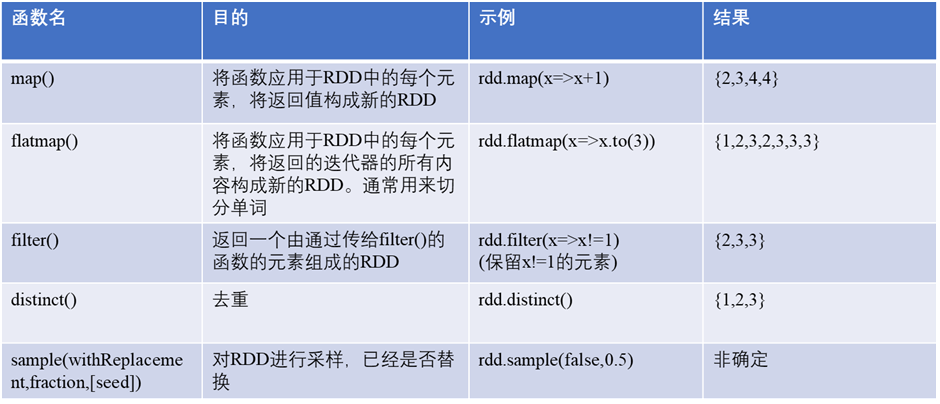
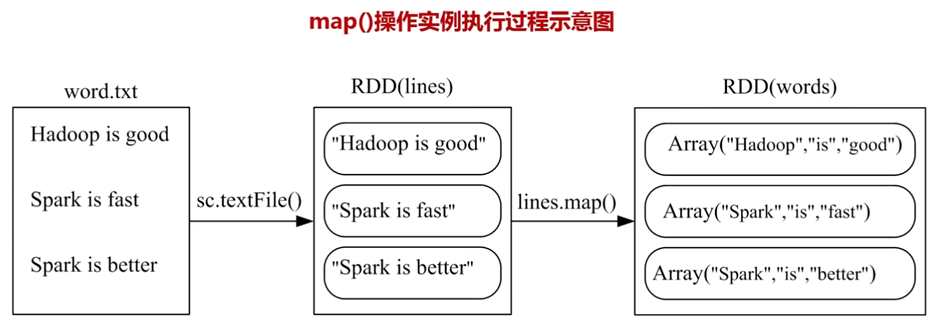
map例子: 对RDD中的每个元素计算,返回一个新的RDD
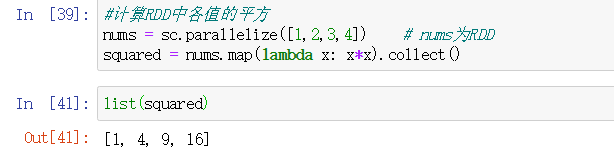
collect()将驱动器程序中的RDD全部取出来存放在内存里。如果内存不够大,则不使用此函数。
如果只是取出部分,可以使用take(10),取出10个数据到内存。
flatMap例子: flatMap()是对每个输入元素生成多个输出元素
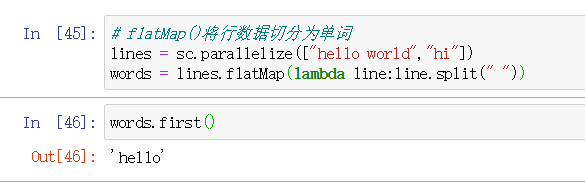
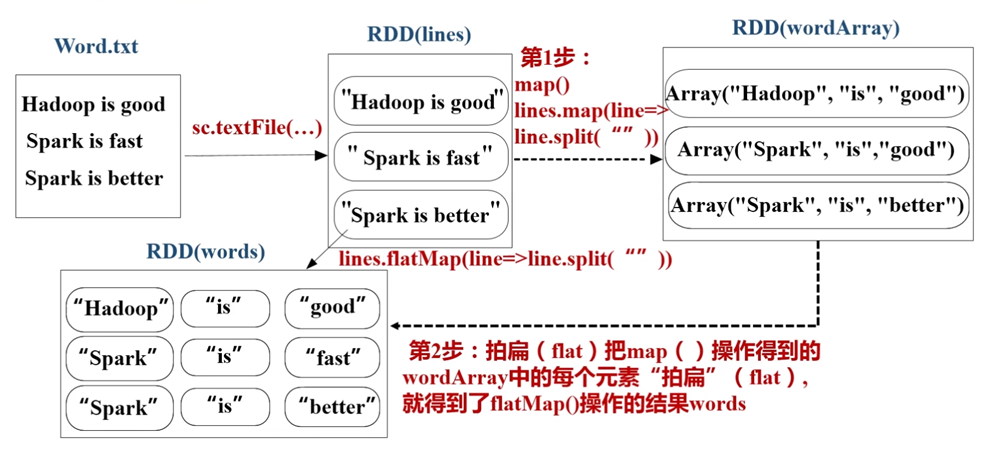
我们来对比一下map()和flatMap()的区别:

也就是说flatMap()将返回的迭代器“拍扁”; 而map()返回的是由列表组成的RDD
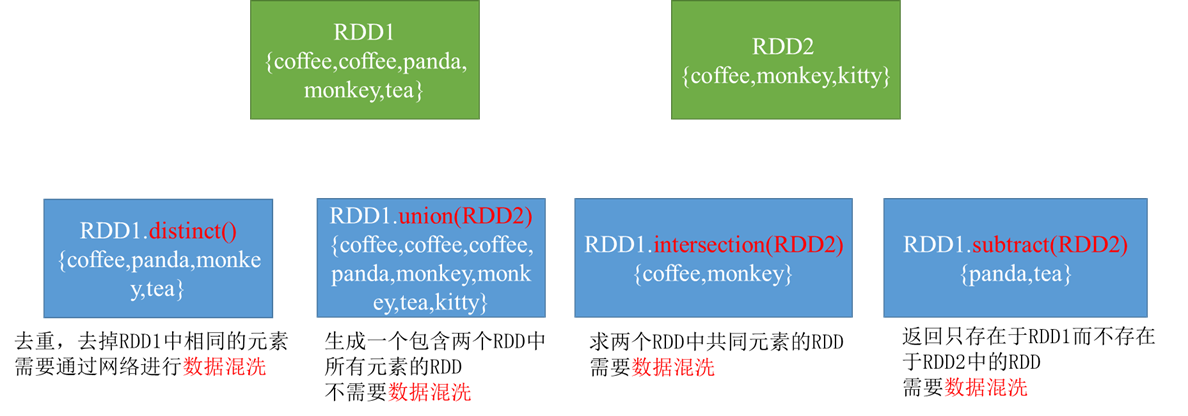
剩下的转换操作 distinct(), union(), intersection(), subtract()
见下图:
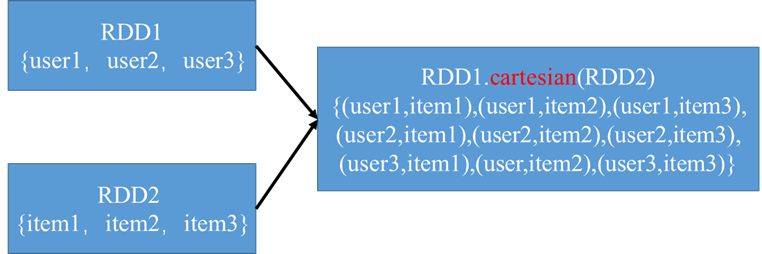
笛卡尔积cartesian() 笛卡尔积在我们希望考虑所有可能组合的相似度时比较有用,比如计算各用户对各种产品的于其兴趣程度,
如:
行动操作是返回结果或者将结果写入外部系统的操作,会触发实际的计算,如count(), first()
reduce() 累加或者累乘
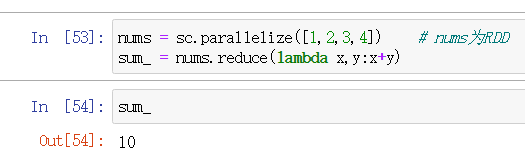
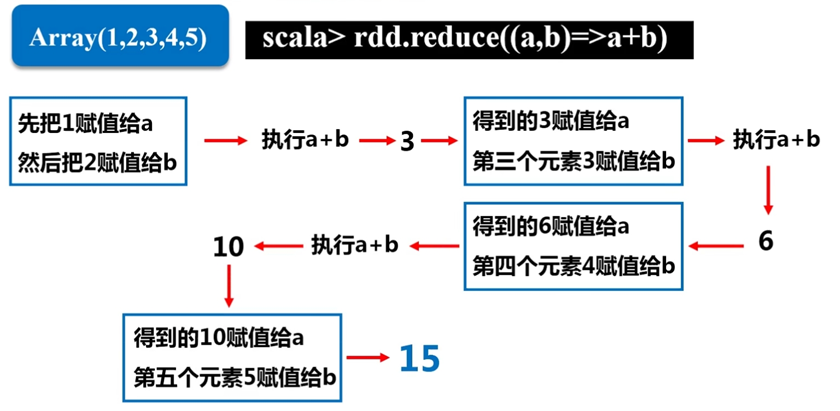
对一个数据为 rdd = {1,2,3,3} 的RDD进行基本的RDD行动操作。
这个aggregate()() 有些不理解
第三部分:持久化
为了避免多次计算同一个RDD,可以让Spark对数据进行持久化。
rdd.persist()
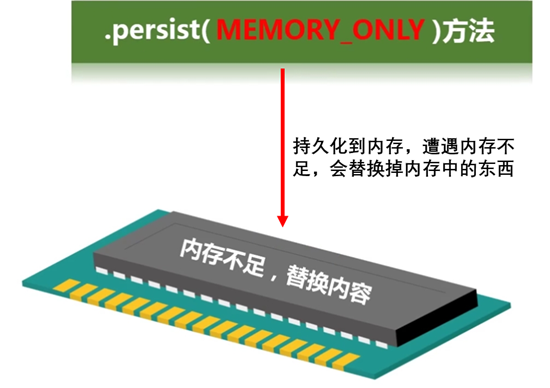
更换参数,可以持久化到磁盘
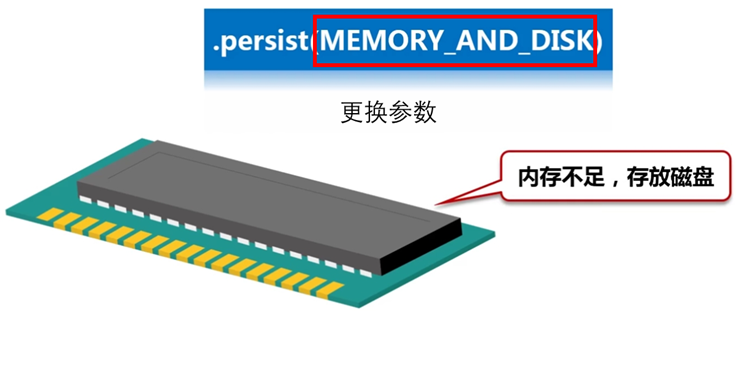

举例:

与之对应的,将持久化的RDD从缓存中移除
rdd.unpersist()
第四部分:分区
由于RDD的整个数据量是很大的,spark的一大特性就是对RDD数据分区,使数据分布到不同的工作节点上去
分区的好处:
(1) 增加并行度
(2)减少通讯开销
分区原则
分区的个数尽可能地等于集群中CPU核心数目
若CPU是8核的,那么数据也分8份,这样才会实现并行化。

如果分区数目为4,则有四个核被浪费
若分数数目为16,则有8个分区需要等待
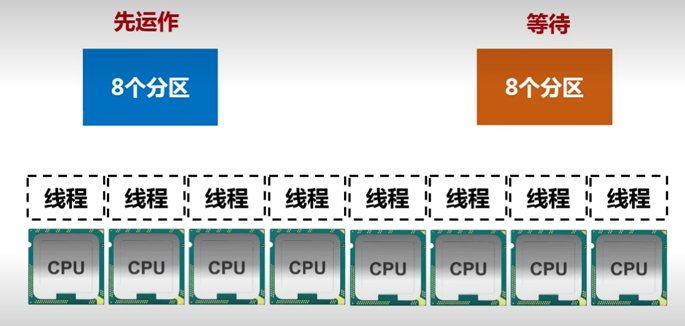
如何设置分区数目
如何用程序实现
(1)通过 sc.textFile(path,partitionNum)
(2) 通过 sc.parallelize()

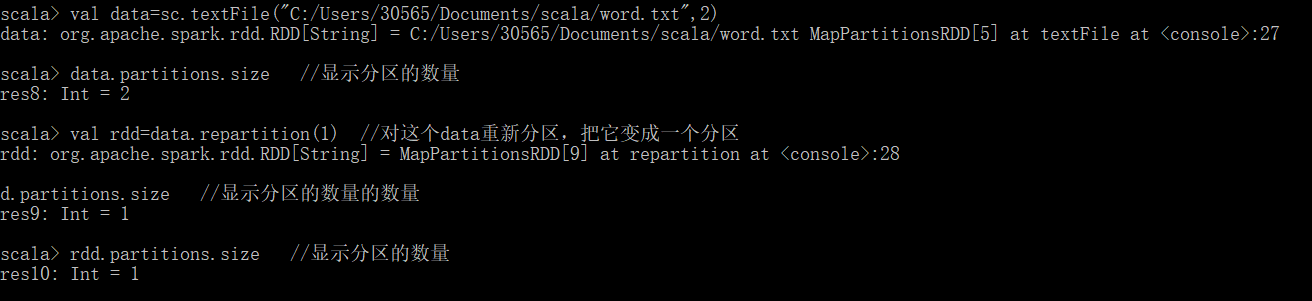
(3) 重新分区 .repartition()
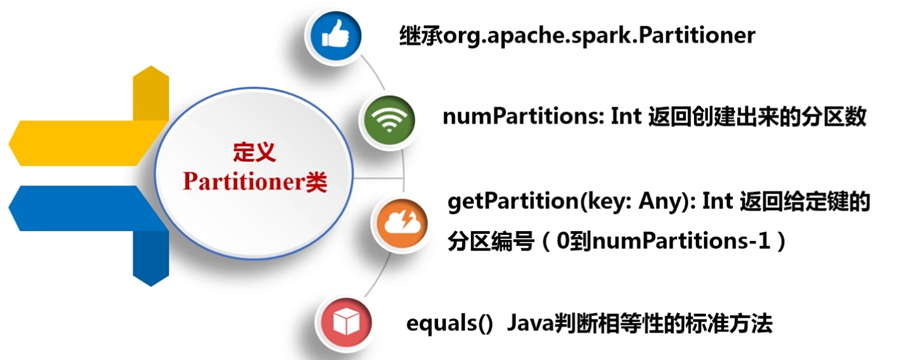
(4) 自定义分区

 浙公网安备 33010602011771号
浙公网安备 33010602011771号