- 接口测试经常会用到抓包工具,用来抓取接口测试中发送的HTTP请求信息和接收的响应信息。然后查看里面的具体内容。
- fiddler是一款常用的HTTP抓包工具,抓包原理是代理式抓包。
- Filters设置过滤项
![]()
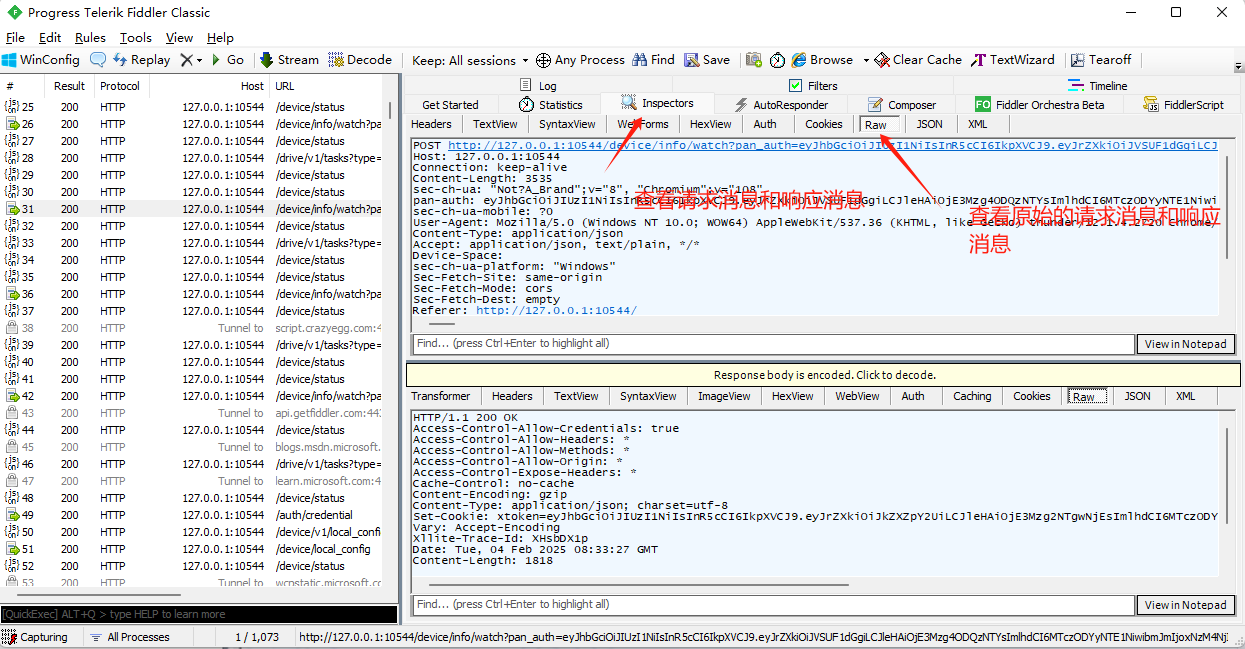
- Inspectors查看请求消息和响应消息,点击Raw查看原始的请求消息和响应消息
![]()
- 首先客户端得使用代理,Filder才能抓到包
- 浏览器抓包:可以通过其代理配置,指定使用fiddler作为代理,从而让fiddler抓到包。
- 手机抓包:
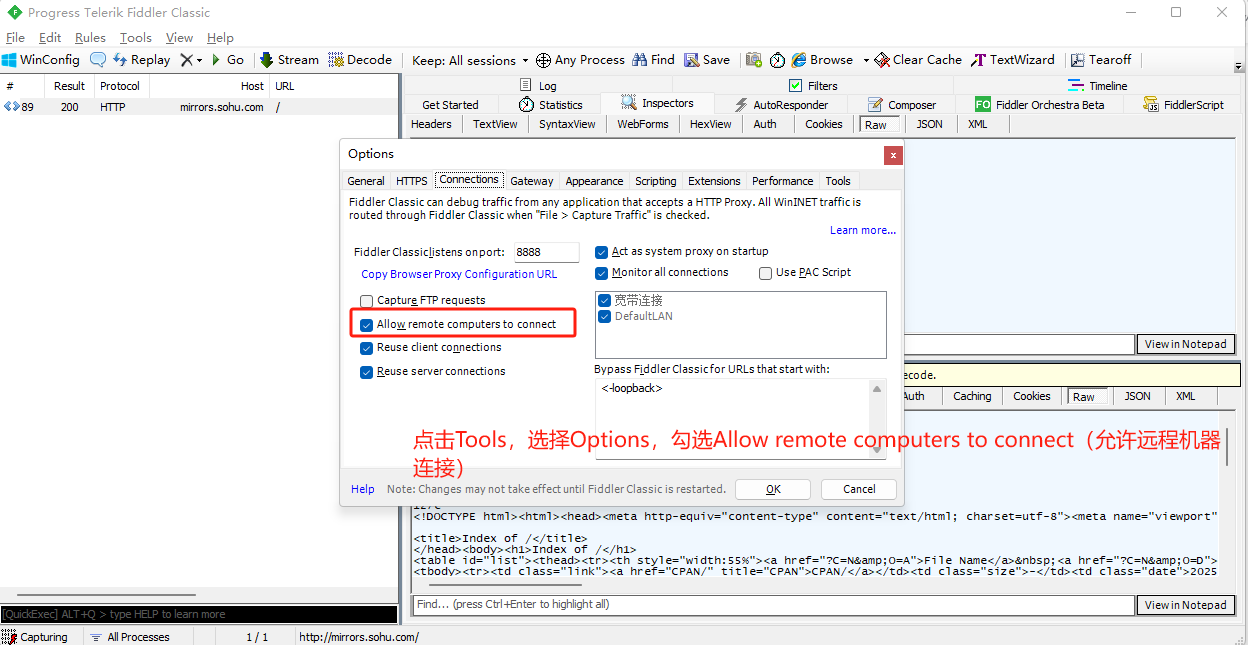
- 手机使用的WIFI和运行fiddler的电脑必须使用同一个子网
- 还得设置fiddler允许远程机器连接自己
![]()
- 然后手机上设置代理
- 代理的主机名就是运行fiddler的机器的ip地址,通过在机器上执行ipconfig获取
- 端口是fiddler监听端口:8888
- 缺省app是可以使用代理的
- 设置完成后,fiddler需要重启才能抓包
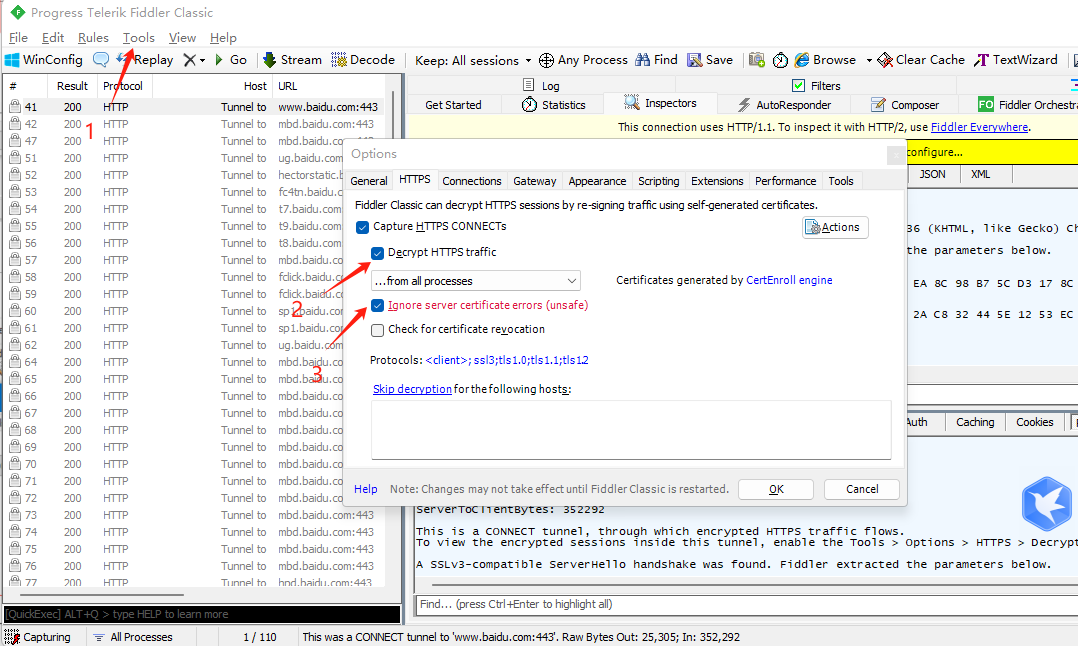
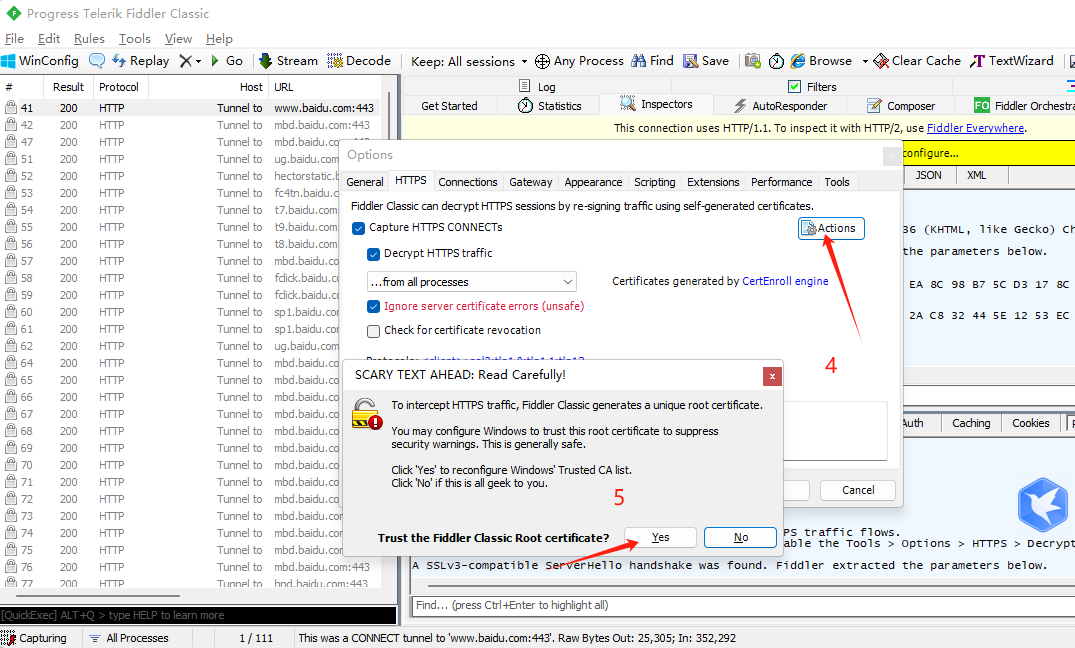
- Fiddler如果要捕获https请求,还需要一些额外的设置:
![]()
![]()
- 将证书下载后,导入到浏览器
- Fiddler左侧的session有很多都是不需要的,可以通过主机名来过滤,设置完成后点击Actions中的Run Filterset now立即生效
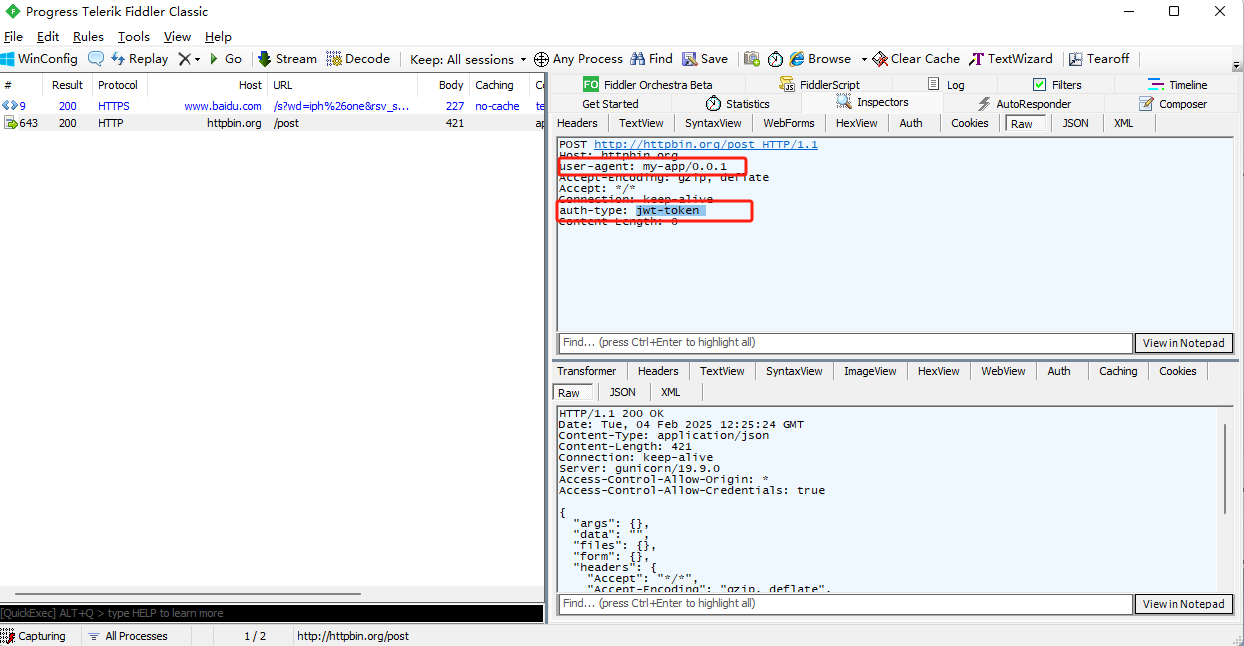
- 构建请求消息头:
1 import requests
2
3 headers = {
4 'user-agent': 'my-app/0.0.1',
5 'auth-type': 'jwt-token'
6 }
7
8 r = requests.post("http://httpbin.org/post", headers=headers)
9 print(r.text)
![]()
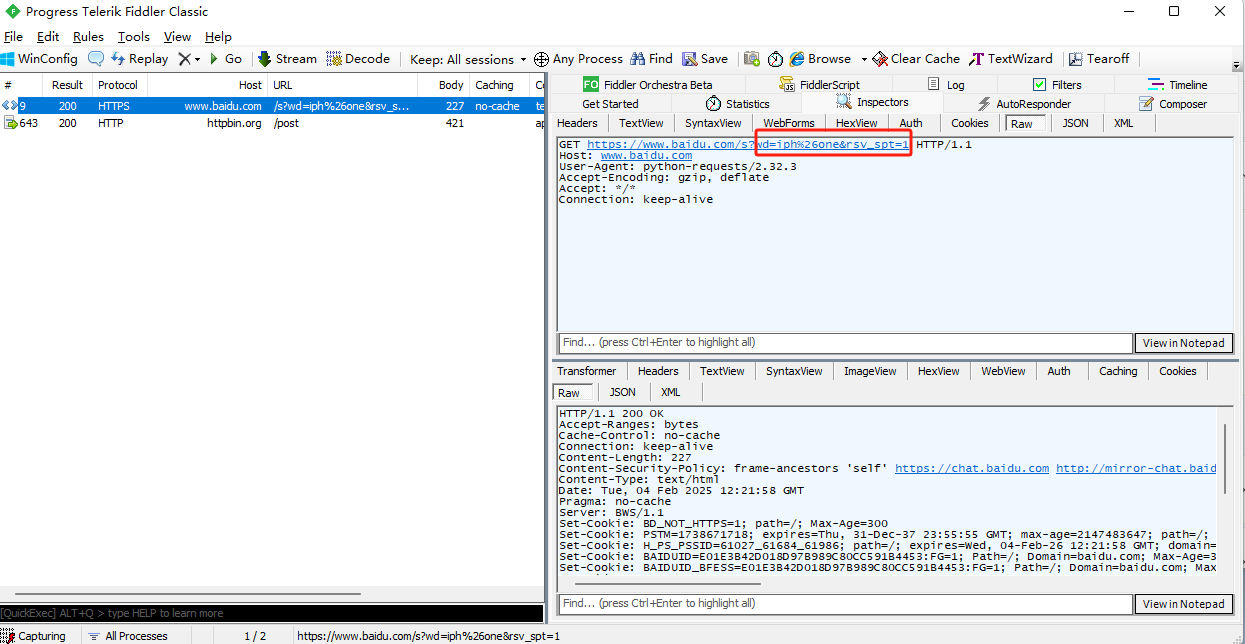
1 import requests
2 import os
3
4 urlpara = {
5 'wd': 'iph&one',
6 'rsv_spt': '1'
7 }
8 proxies = {
9 'http': 'http://127.0.0.1:8888',
10 'https': 'http://127.0.0.1:8888',
11 }
12
13 response = requests.get('https://www.baidu.com/s', params=urlpara, proxies=proxies, verify=False)
14 print(response.text)
![]()
1 import requests
2
3 proxies = {
4 'http': 'http://127.0.0.1:8888',
5 'https': 'http://127.0.0.1:8888',
6 }
7
8 payload = '''
9 <?xml version="1.0" encoding="UTF-8"?>
10 <WorkReport>
11 <Overall>良好</Overall>
12 <Progress>30%</Progress>
13 <Problems>暂无</Problems>
14 </WorkReport>
15 '''
16
17 r = requests.post("http://httpbin.org/post",
18 data=payload.encode('utf8'), proxies=proxies)
19 print(r.text)
- 专门用作HTTP测试的网站:http://httpbin.org/post
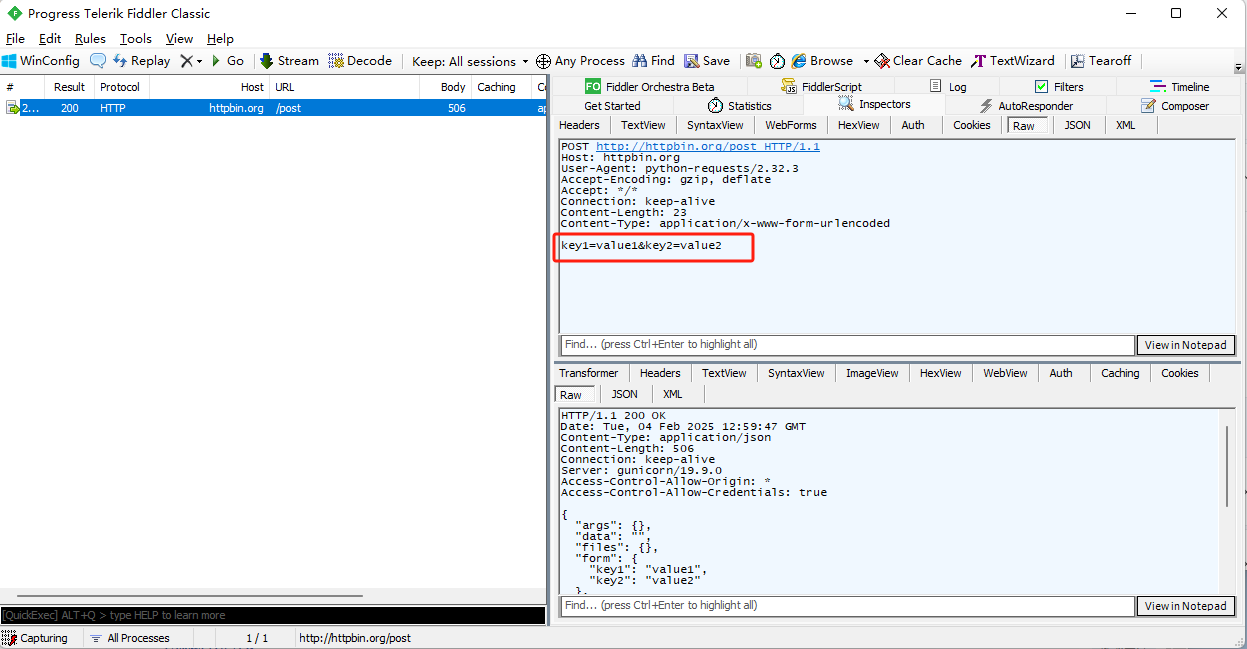
- requests库怎么传送urlencoded格式消息体:
1 import requests
2
3 proxies = {
4 'http': 'http://127.0.0.1:8888',
5 'https': 'http://127.0.0.1:8888',
6 }
7 payload = {'key1': 'value1', 'key2': 'value2'}
8
9 # 由于payload是urlencoded格式,会自动转成urlencoded格式,不需要额外的编码
10 r = requests.post("http://httpbin.org/post", data=payload)
11 print(r.text)
![]()
- 传递给data的一定是字典类型,才是urlencoded格式。
- json表示字符串只能用双引号,而Python字典表示字符串可以用单引号。
- json表示字符串最后一个元素不能有,,而Python可以有,。
- json中有对象、数组的概念
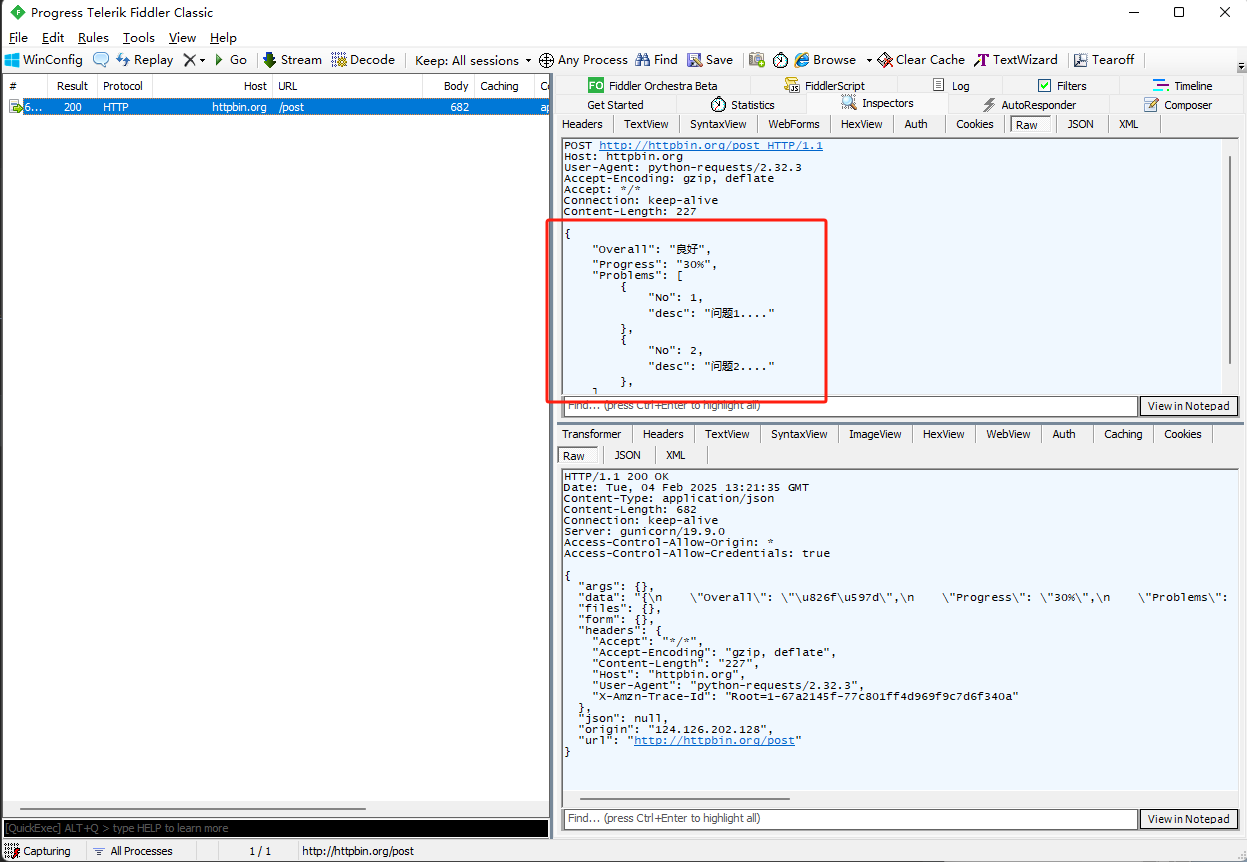
- requests库传送json格式的请求体:
- 第一种方法将json格式当成普通的字符串去传递,用utf-8编码成字节串:
![]()
1 import requests, json
2
3 proxies = {
4 'http': 'http://127.0.0.1:8888',
5 'https': 'http://127.0.0.1:8888',
6 }
7 payload = '''{
8 "Overall": "良好",
9 "Progress": "30%",
10 "Problems": [
11 {
12 "No": 1,
13 "desc": "问题1...."
14 },
15 {
16 "No": 2,
17 "desc": "问题2...."
18 },
19 ]
20 }'''
21
22 r = requests.post("http://httpbin.org/post", data=payload.encode('utf-8'), proxies=proxies)
- 第二种方法是将payload当成Python中的数据对象字典去处理,利用json的序列化方法将Python中的字典对象转换成字符串传输。
1 import requests, json
2
3 proxies = {
4 'http': 'http://127.0.0.1:8888',
5 'https': 'http://127.0.0.1:8888',
6 }
7 payload = {
8 "Overall": "良好",
9 "Progress": "30%",
10 "Problems": [
11 {
12 "No": 1,
13 "desc": "问题1...."
14 },
15 {
16 "No": 2,
17 "desc": "问题2...."
18 }
19 ]
20 }
21 # 这时payload被当做了Python的字典对象
22 # 调用json的dumps方法将Python中的对象转换成字符串
23 # 发送的数据其实是:{"Overall": "\u826f\u597d", "Progress": "30%", "Problems": [{"No": 1, "desc": "\u95ee\u98981...."}, {"No": 2, "desc": "\u95ee\u98982...."}]}
24 # 为什么中文问题变成了"\u826f\u597d"
25 # 这是因为在做json的dumps的时候缺省的会把里面非ASCII的字符,比如中文用对应的Unicode编码来表示,"\u826f\u597d"其实就是良好的Unicode表示法
26 # r = requests.post("http://httpbin.org/post", data=json.dumps(payload), proxies=proxies)
27 r = requests.post("http://httpbin.org/post", data=json.dumps(payload, ensure_ascii=False).encode(), proxies=proxies)
28 # ensure_ascii=False 会将所有的字符都编码,但是默认dumps会以默认的拉丁去编码还是会报错,所以最后还需要再编码下,encode默认的参数就是UTF-8
29 # {"Overall": "良好", "Progress": "30%", "Problems": [{"No": 1, "desc": "问题1...."}, {"No": 2, "desc": "问题2...."}]}
![]()
- requests库传送json格式的请求体终极方案:
1 import requests, json
2
3 proxies = {
4 'http': 'http://127.0.0.1:8888',
5 'https': 'http://127.0.0.1:8888',
6 }
7 payload = {
8 "Overall": "良好",
9 "Progress": "30%",
10 "Problems": [
11 {
12 "No": 1,
13 "desc": "问题1...."
14 },
15 {
16 "No": 2,
17 "desc": "问题2...."
18 }
19 ]
20 }
21
22 r = requests.post("http://httpbin.org/post", json=payload, proxies=proxies)
![]()
- 查看HTTP响应的状态码、响应头相关信息,响应头是一个类字典格式、响应的消息体
1 import requests
2
3 proxies = {
4 'http': 'http://127.0.0.1:8888',
5 'https': 'http://127.0.0.1:8888',
6 }
7 response = requests.get('http://mirrors.sohu.com/', proxies=proxies)
8 print(response.status_code)
9 print(response.headers['Server'])
10 print(response.text)
- requests库是以什么样的编码格式对数据进行解码的
- requests会根据响应的消息头比如Content-Type对编码格式做推测,但是有时候服务端并不一定会在消息头中指定编码格式。这时requests库可能推测有误,需要我们指定编码格式来解码。
- 响应头中指定了Content-Type的案例:
1 import requests
2
3 response = requests.get('http://mirrors.sohu.com/')
4 # response.encoding='utf8'
5 print(response.text)
6 print(response.encoding)
![]()
- 响应头中未指定Content-Type案例,最后是用ISO-8859-1解码的,有乱码,这时:
1 import requests
2
3 response = requests.get('https://www.byhy.net/', verify=False)
4
5 # response.encoding='utf8'
6 print(response.text)
7 print(response.encoding)
![]()
1 import requests
2
3 response = requests.get('https://www.byhy.net/', verify=False)
4
5 response.encoding='utf8'
6 print(response.text)
7 print(response.encoding)
- 解决Fiddler响应乱码:
- 点击Response body is encoded. Click to decode 或者选中工具栏上面的Decode。
![]()
1 import requests
2
3 response = requests.get('https://www.byhy.net/', verify=False)
4
5 response.encoding='utf8'
6 print(response.content)
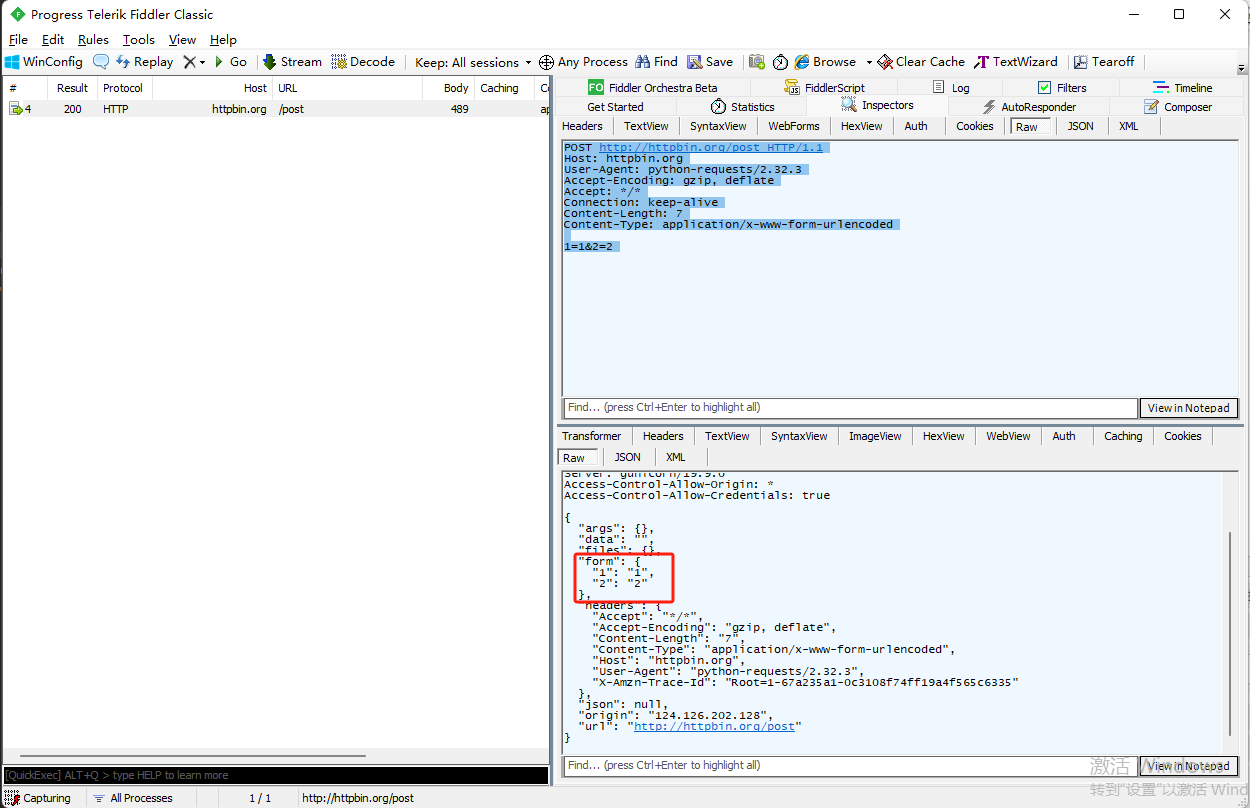
- loads是把json格式的字符串反序列化成Python中的数据对象,然后通过obj['form']就可以获取,如果不反序列化成Python中的对象,直接从json字符串中取出数据是很麻烦的。
1 import requests, json
2
3 response = requests.post("http://httpbin.org/post", data={1:1,2:2})
4 # loads是将json格式的字符串反序列化为Python中的数据对象
5 obj = json.loads(response.content.decode('utf-8'))
6 print(obj)
![]()
1 import json
2
3 # 假如HTTP响应的消息体中返回的是以下类型
4 text = '123' # 这其实也是一个json格式
5 obj = json.loads(text)
6 print(obj, type(obj)) # obj表示的是数字123
7 text = '"123"'
8 obj = json.loads(text)
9 print(obj, type(obj)) # obj表示的是字符串123
10
11 text = '["123",1,3]'
12 obj = json.loads(text)
13 print(obj, type(obj)) # obj表示的是列表
14
15 # 总结:任何一种Python中的数据对象,都可以被json反序列化出来
- requests库为我们提供了更方便的方法,可以使用Response对象的json方法,将其转换成Python中的数据对象,方便进行后续操作。底层也是调用json库中的loads。
1 import requests
2
3 response = requests.post("http://httpbin.org/post", data={1: 1, 2: 2})
4 obj = response.json()
5 print(obj['form']['2'])
![]()
- data中如果传入的是字符串,requests库会使用缺省编码latin-1编码为字节串放到http消息体中发送出去。
- 打印完成的HTTP消息:





 浙公网安备 33010602011771号
浙公网安备 33010602011771号