

Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks概述
0.前言
-
发表时间:arxiv2021(2021.5.5)
- 发表单位:清华大学图形学实验室Jittor团队
1.针对的问题
self-attention自身存在两个缺点:(1)计算量太大,计算复杂度与pixel的平方相关;(2)没有考虑不同样本之间的潜在关联,只是单独处理每一个样本,在单个样本内去捕获这类long-range dependency。
2.主要贡献
•一种新的注意机制,外部注意,具有O(n)的复杂性;它可以取代现有架构中的自我注意。它可以挖掘整个数据集的潜在关系,提供一个强烈的正则化作用,并提高注意机制的泛化能力。
•多头外部注意,这有利于构建一个全MLP架构;它在ImageNet-1K数据集上达到了79.4%的前1个精度。
•利用外部注意力对图像分类、目标检测、语义分割、实例分割、图像生成、点云分类和点云分割进行了广泛的实验。在计算量必须保持在较低水平的情况下,它获得了比原来的自我注意机制及其一些变体更好的结果。
3.方法
基于两个外部的,小的,可学习的和共享的存储器,用两个级联的线性层和归一化层取代了现有流行的学习架构中的Self-attention。
提出了一个external attention模块,仅仅通过两个可学习的external unit,就可以简化self-attention的时间复杂度,简化到与pixel数量线性相关;同时由于两个unit是external的,对于整个数据集来说都是shared,所以还可以隐式地考虑到不同样本之间的关联,学习整个数据集的特征。两个unit在实现的时候是两个linear layer,因此可以直接end2end优化。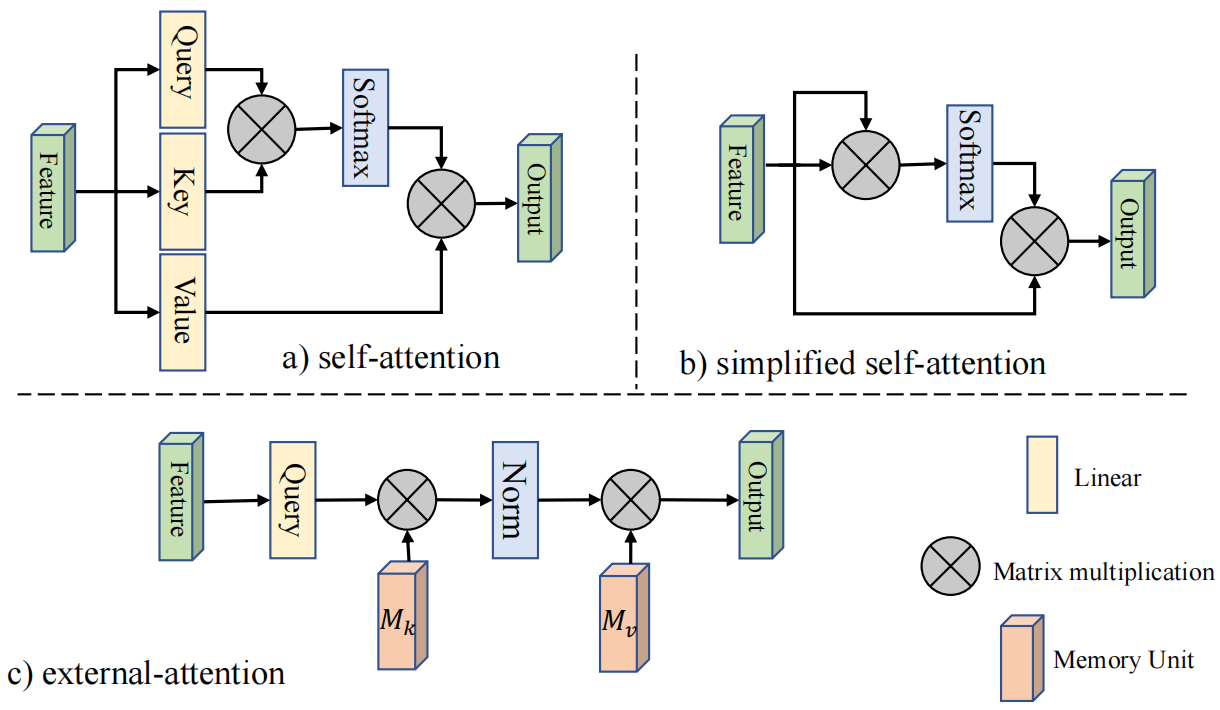
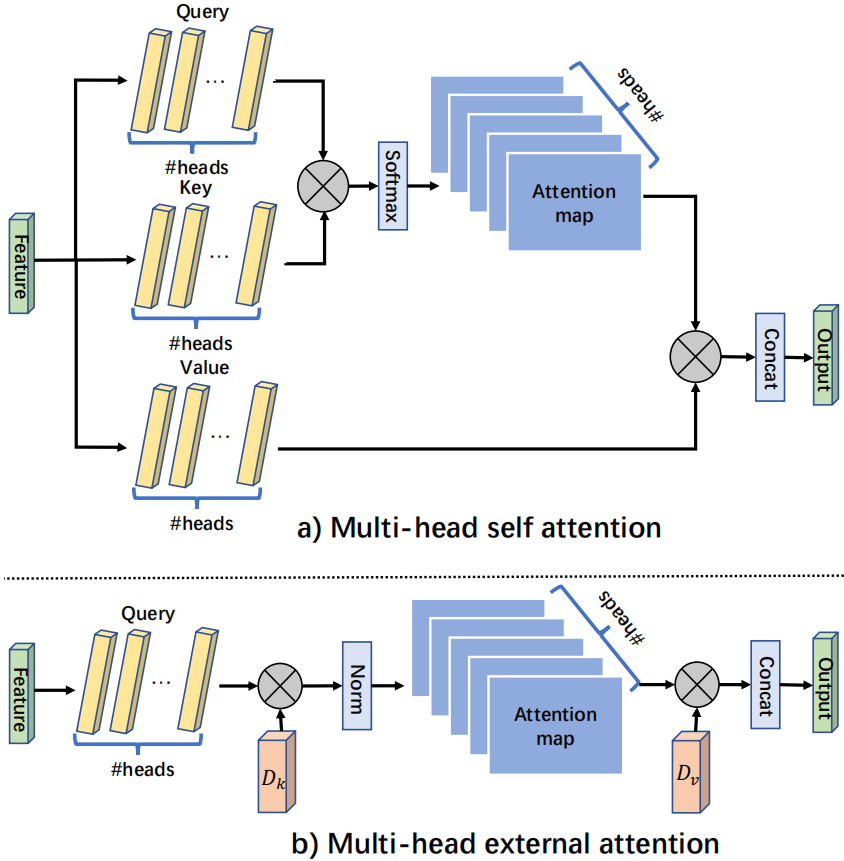
(a)和(b)分别表示经典的self-attention和简化版self-attention,计算复杂度均为O(dN2),N表示特征图pixel数,d表示feature维度,(c)为本文提出的external-attention。经作者观察发现,这两种方法都是建立一个N-to-N的attention关联,即attention map的生成。而attention map自身是稀疏的,也就是说只有很少量的pixel之间有关联,所以N-to-N的attention map可能会显得redundant。公式推理过程如下:
对于输入的Nxd维空间的特征向量F,自注意力机制使用基于自身线性变换的Query,Key和Value特征去计算自身样本内的注意力,并据此更新特征:
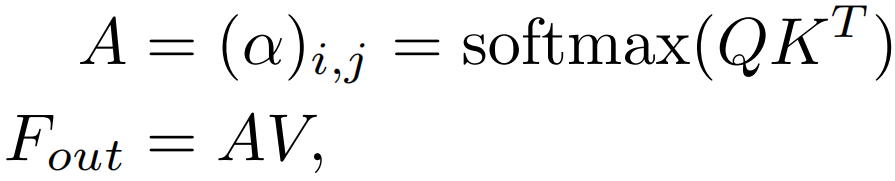
由于QKV是F的线性变换,简单起见,可以将自注意力计算公式简记如下:

这是 F 对 F 的注意力,也就是所谓的 Self-attention。如果希望注意力机制可以考虑到来自其他样本的影响,那么就需要一个所有样本共享的特征。为此,引入一个外部的Sxd维空间的记忆单元M,来刻画所有样本最本质的特征,并用M来表示输入特征。
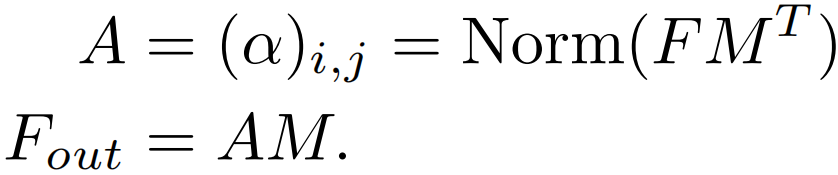
由于M的维度是Sxd,所以external attention的计算复杂度降为O(dSN),由于S是超参数,所以可以设置的远小于pixel数目N。这种新的注意力机制就是External-attention。可以发现,上面两个公式中的计算主要是矩阵乘法,就是常见的线性变换,一个自注意力机制就这样被两层线性层和归一化层代替了。作者还使用了之前工作中提出的Norm方式来避免某一个特征向量的过大而引起的注意力失效问题。
为了增强External-attention的表达能力,与自注意力机制类似,采用两个不同的记忆单元。

关于上面的Norm,attention map对于输入特征的scale比较敏感,因此作者没有采用简单的softmax,而是利用了一种double-normalization,分别对行和列进行归一化,公式如下:
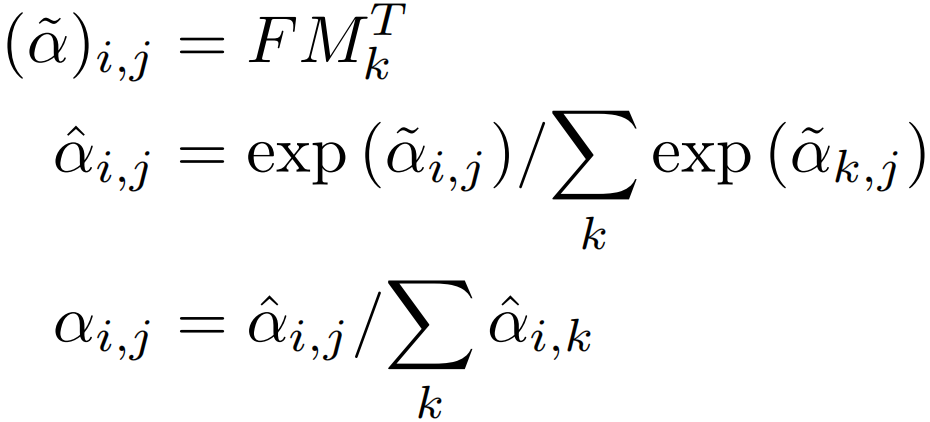
作者也使用了多头机制,与自注意力对比如下
公式如下
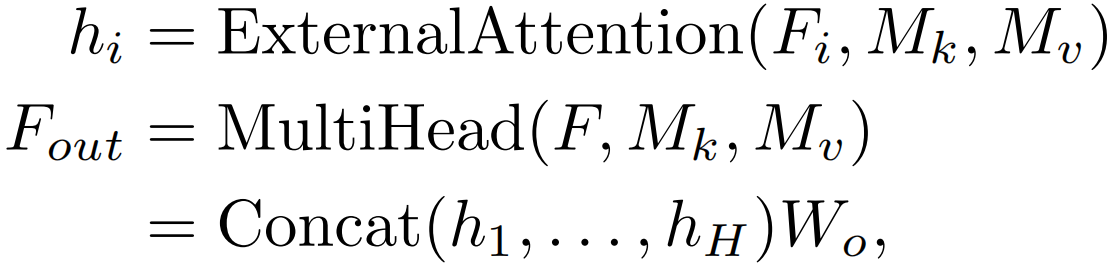
其中hi是第i个头,H是头的数量,Wo是一个线性变换矩阵,使输入和输出的维数一致。Mk∈RS×d和Mv∈RS×d是不同头的共享memory units。这种体系结构的灵活性能够在共享内存单元中的头H数量和元素S数量之间取得平衡,比如H扩大K倍,S减小K倍。
EANet模型结构如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号