Re-Attention Transformer for Weakly Supervised Object Localization
0.前言
摘要
弱监督目标定位是一项具有挑战性的任务,其目标是定位带有粗糙标注(如图像类别)的目标。现有的深度网络方法主要基于类激活图,只强调最具判别性的局部区域,忽略了整个目标。此外,新兴的基于transformer的技术不断强调背景,这阻碍了完整物体的识别能力。为了解决这些问题,我们提出了一种称为TRT(token refinement transformer)的再注意机制,该机制捕获了目标级语义,可以很好地指导定位过程。具体而言,TRT引入了一种新型的Token Priority Scoring Module(TPSM)来抑制背景噪声的影响,同时对目标物体进行聚焦。然后,将类激活映射作为语义感知输入,约束目标物体的注意力映射;在两个基准测试集上的大量实验表明,该方法相对于已有的具有图像类别标注的方法有更好的性能。
1介绍
近年来,在不同的下游应用中对弱监督条件下的激活图定位产生了浓厚的兴趣,例如样本图像级标注的激活图定位。弱监督学习得到了广泛的注意,因为它最小化了对细粒度标注的需求,从而减少了人为标注的工作量。尝试在仅使用图像类别监督的情况下定位目标,也称为弱监督目标定位(WSOL)。
深度神经网络(DNNs)的巨大进步也为WSOL任务带来了巨大的好处。其基础工作是类激活映射(Class Activation Mapping, CAM)[1],它允许分类神经网络通过计算最后一个卷积特征映射的加权和来突出感兴趣的部分。然而,由于CAM具有局部性[2,3,4,5],它只关注最具判别性的特征,而不是整个物体区域。为了缓解这一问题,研究者们做出了许多努力,如对抗擦除[6,7,8]、多任务联合训练[9]、新网络[10,11]和发散激活[12,4]。大多数基于CAM的方法都是先计算局部特征,然后获取相邻的物体块来包含整个目标。然而,CAM的潜在限制仍然存在,尽管这些方法确实鼓励更好的激活区域。另一个流行的替代方法是利用vision transformer[13]的远程依赖关系来查找目标定位。传统的基于transformer的块token生成方法是将图像分割成一系列有序的块,然后计算每一层的全局关系,这类方法容易受到背景无关性的影响。因此,Gao等人提出了TS-CAM[14],通过集成transformer和CAM来缓解这些缺点。如图1所示,CAM强调最判别的局部区域,而transformer将注意力从目标转移到背景区域。倒数第二列的结果表明,当前的集成方法不能处理这些问题,即使具有不错的性能。

图1:我们提出的token refinement transformer(TRT)与现有方法之间的比较。
本文提出一种基于token refinement transformer(简称TRT)的再注意策略,以更精确地把握感兴趣的目标。具体而言,为了抑制transformer中背景噪声的影响,TRT引入了token优先评分模块(token priority scoring module, TPSM)。接着,将类激活图作为语义感知引导,约束目标物体的注意力图。TPSM试图对transformer中注意力图获得的强响应重要区域进行重新评分,以尽可能减少混杂背景的影响。此外,我们还揭示了基于累积分布函数采样的自适应阈值策略优于常规阈值或topK策略。其贡献总结如下:
•我们提出了一种再注意机制,称为token refinement transformer(TRT),它突出了正确的兴趣目标。
•我们提出了一种基于累积重要性采样的自适应阈值策略,显著提高了WSOL任务中的性能。
•实验结果表明,与现有方法相比,在ILSVRC[15]和CUB-200-2011[16]的定性和定量结果都令人信服。
2相关工作
2.1基于cam的注意力图生成
类激活图(CAM[1])的重要工作是定位特定类别的判别区域。在本研究中,我们将CAM技术分为两类:基于激活的方法[1,17,18,19,20]和基于梯度的方法[21,22,23,24,25]。典型的基于激活的工作消除了对梯度的依赖,因为它们只需要访问类激活映射和通道级置信度。例如,Wang等人[17]提出了Score-CAM,它通过在激活图上执行的信道置信度的增加来计算重要性权重。此外,一个名为SS-CAM[18]的扩展版本使用平滑技术对图像中集中的目标物体提供了更好的事后解释,以获得更好的理解。此外,其他比较受欢迎的作品,如综合评分CAM (IS-CAM)[19],也试图缓解饱和和假置信度的问题,也取得了显著的效果。除了基于激活的方法,研究人员经常使用梯度信息来增强图像的显著性。基于梯度的方法根据特定类的反向传播梯度突出重要区域。然而,当同一类别的图像多次出现时,naive Grad-CAM[21]往往无法定位图像中的目标。Chattopadhyay等人提出了Grad-CAM++[22],通过在最终的特征图中对输出图像中特定区域的梯度进行像素级加权来克服上述问题。此外,smooth Grad-CAM++[23]的工作结合了smooth和Grad-CAM++[21],以实现对特征图的层、子集或特征图中的神经元子集的可视化。许多额外的技术,包括XGrad-CAM[24]、LayerCAM[25]等,也为该领域的进展做出了贡献,并取得了良好的效果。
2.2基于transformer的注意力图生成
Vision transformer[13,26,27,28]在近年的研究中受到越来越多的关注,如样本[29,30,31,32,33]、目标检测[34,35,36]、语义分割[37]等。然而,视觉变换是通过将图像分割为一系列有序的patch来生成token,并计算token之间的全局关系,这不可避免地会引入背景噪声。现有的工作已经在早期尝试探索细粒度数据集上token的重要性[38,39],以缓解全局问题。He等人[38]提出了一个部件选择模块,该模块将transformer的所有注意力权重集成到一个注意力图中,指导网络形成判别token。transformer层的分类token更注意解释不充分的全局信息,受此启发,Wang等人[39]提出了一种特征融合transformer,聚合各transformer层的主导token以补偿局部信息。此外,同时基于CAM和transformer对高亮区域进行刻面化的研究较少[40,14]。尽管已经取得了坚实的数值结果,但突出区域仍然带来了来自CAM和Transformer的问题。
2.3弱监督目标定位
传统的工作,如[41,42]将弱监督目标定位(WSOL)任务表述为多实例学习(MIL)问题。然而,典型的求解MIL问题的方法通常对初始化敏感,容易陷入局部最小,泛化误差大。因此,许多方法[43,44,45,42,46,47]都试图获得良好的初值或探索后处理中的refinement方法。近年来,深度神经网络(DNNs)已经取得了足够的进展来应对具有挑战性的WSOL任务,例如基于cam的方法[1,21]和基于transformer的方法[13,29,14]。而在本文中,我们顺应趋势,使用所提出的再注意机制来处理全局背景噪声和局部判别区域带来的问题。
3方法
在本节中,我们首先回顾vision transformer[13]的初步内容。然后,对提出的WSOL token refinement transformer(简称TRT)进行了详细的设计和实现。
3.1准备工作
让我们将I∈RW×H×3作为输入图像,我们根据patch大小P分割图像I,得到N个(N = [W/P ]×[ H/P ])非重叠扁平patch块xp∈![]() 。每个patch块xnp(n∈{1,...,N})在被输入到transformer块之前先线性投影到D维patch块嵌入。作为嵌入的一部分,引入了一个额外的可学习的类token zcls0∈R1×D。此外,我们加入了一个位置嵌入Epos∈R(N+1)×D,形成transformer的整个patch嵌入,如下:
。每个patch块xnp(n∈{1,...,N})在被输入到transformer块之前先线性投影到D维patch块嵌入。作为嵌入的一部分,引入了一个额外的可学习的类token zcls0∈R1×D。此外,我们加入了一个位置嵌入Epos∈R(N+1)×D,形成transformer的整个patch嵌入,如下:
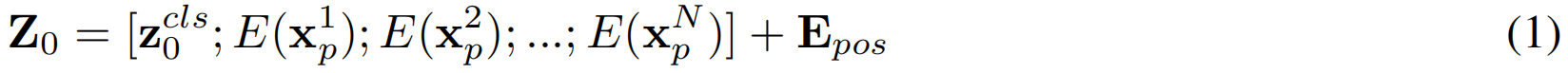
其中E(.)表示patch嵌入投影,Z0∈R(N+1)×D 是第一个transformer块的输入。
3.2概述
我们将Zl∈R(N+1)×D(l∈{1,...,L})定义为第l个transformer块的输出特征嵌入。如图2所示,倒数第二个transformer ZL−1的输出被输入到两个分支中,其中一个是token优先级评分模块(TPSM),其目的是使用所提出的自适应阈值策略再注意patch token,而另一个分支计算标准类激活映射。
在训练阶段,我们评估了常用交叉熵损失的两个分支的输出和ground-truth之间的不一致性。设zcL−1∈R1×D和zpL−1∈RN×D分别为倒数第二层的输出类token和patch token。对于CAM分支,我们将zpL−1 reshape为z'pL−1∈![]() ,作为后续卷积层的有效输入。之后,输出特征被全局平均池化,然后输入一个softmax层来得到分类预测pc。
,作为后续卷积层的有效输入。之后,输出特征被全局平均池化,然后输入一个softmax层来得到分类预测pc。
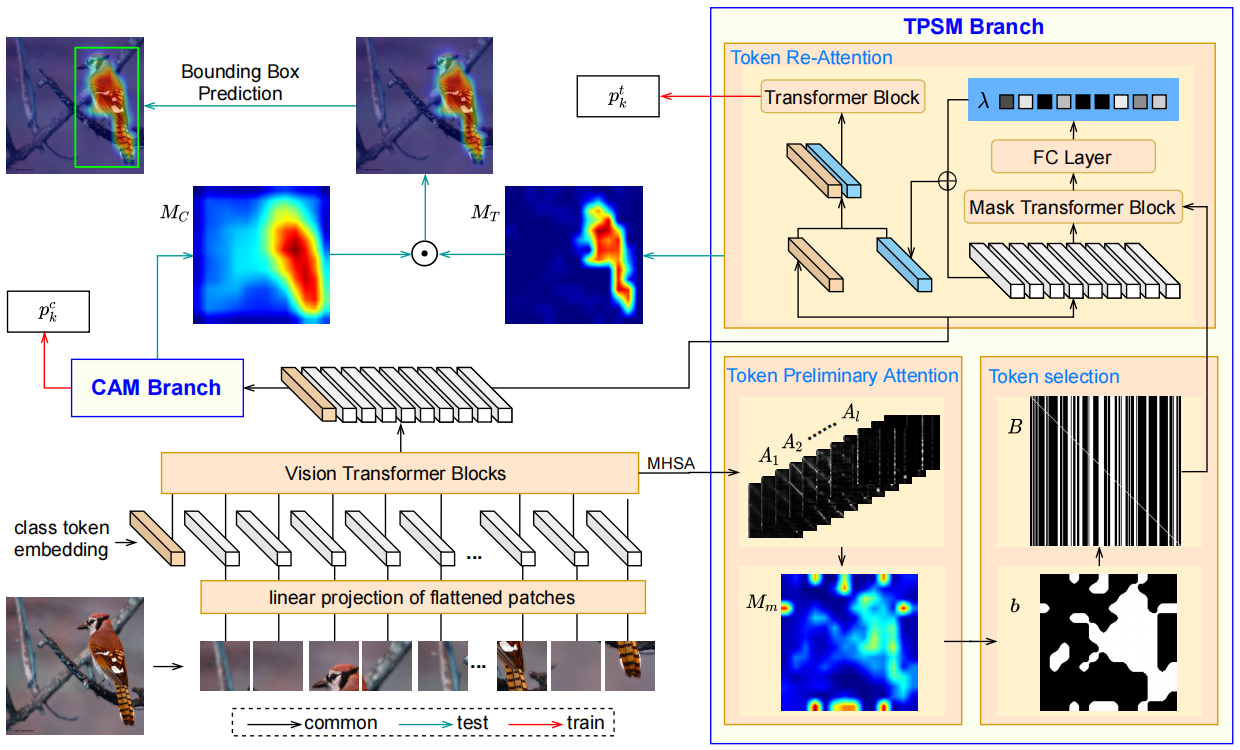
图2:token refinement transformer(TRT)框架。TRT分别由token优先级评分模块(TPSM)模块和CAM两个分支组成。TPSM试图生成对目标类贡献最大的上下文感知特性MT。引入CAM来获得判别特征MC。最后通过元素对M = MC MT的乘法得到注意映射M
对于TPSM分支,ZL−1(=[zcL−1;zpL−1])随后用再注意模块进行处理,得到分类概率pt。损失函数因此被定义为:

其中Lce为交叉熵损失函数。K为类别数。yk为类别标签k是否是观测物体正确的分类的二进制指示器(0或1)。pck和ptk分别表示CAM和TPSM分支中k类的输出概率。
在测试过程中,我们首先将zpL−1输入到TPSM中,通过对patch token执行再注意操作,获得上下文感知特征映射MT∈![]() 。更多的细节将在第3.3节中讨论。对应的,我们应用标准CAM生成特定类的激活映射MC∈
。更多的细节将在第3.3节中讨论。对应的,我们应用标准CAM生成特定类的激活映射MC∈![]() 。因此,注意力图可以通过以下方法获得:
。因此,注意力图可以通过以下方法获得:

其中![]() 表示面向元素的乘法操作。我们通过双线性插值进一步调整映射M的大小,使其与原始图像的大小相同。具体来说,我们使用[1]中描述的确定阈值将前景从背景中分离出来。然后我们寻找紧凑的边界框,它包围了前景像素中最多的相关区域。最后采用网格搜索的方法,将获取边界框的阈值更新为最优值。
表示面向元素的乘法操作。我们通过双线性插值进一步调整映射M的大小,使其与原始图像的大小相同。具体来说,我们使用[1]中描述的确定阈值将前景从背景中分离出来。然后我们寻找紧凑的边界框,它包围了前景像素中最多的相关区域。最后采用网格搜索的方法,将获取边界框的阈值更新为最优值。
3.3 Token优先级评分模块
我们的token优先级评分模块(TPSM)由三个组件组成,如图2所示。首先,利用transformer块上类token和patch token的远程依赖关系生成初步注意力图;然后引入自适应阈值策略,初步筛选出响应高的patch token注意力图。最后,对选中的token进行再注意操作,以捕获更有效的全局关系。我们将在以下三个小节中详细描述。
3.3.1 Token初步注意力
MHSA (Multi-head self-attention)[48]被广泛应用于transformer的远程依赖建模。我们首先计算第l个transformer块的初步自注意力:

其中Ql 和Kl 是从之前的输出Zl−1投影而来的query和key表示。D表示patch embedding的维数。T是一个转置算子。
我们随后研究了Al ∈R(1+N)×(1+N)的特性。我们发现,当等式2被优化时,第一行中记录类token对patch token依赖性的注意力向量被驱动以突出显示对象区域。我们将transformer块上的注意力向量聚合为m = ![]() Al[0, 1:]。然后将m∈R1×Nreshape为Mm∈
Al[0, 1:]。然后将m∈R1×Nreshape为Mm∈![]() 作为初步注意图,如图2所示。
作为初步注意图,如图2所示。
3.3.2 Token选择策略
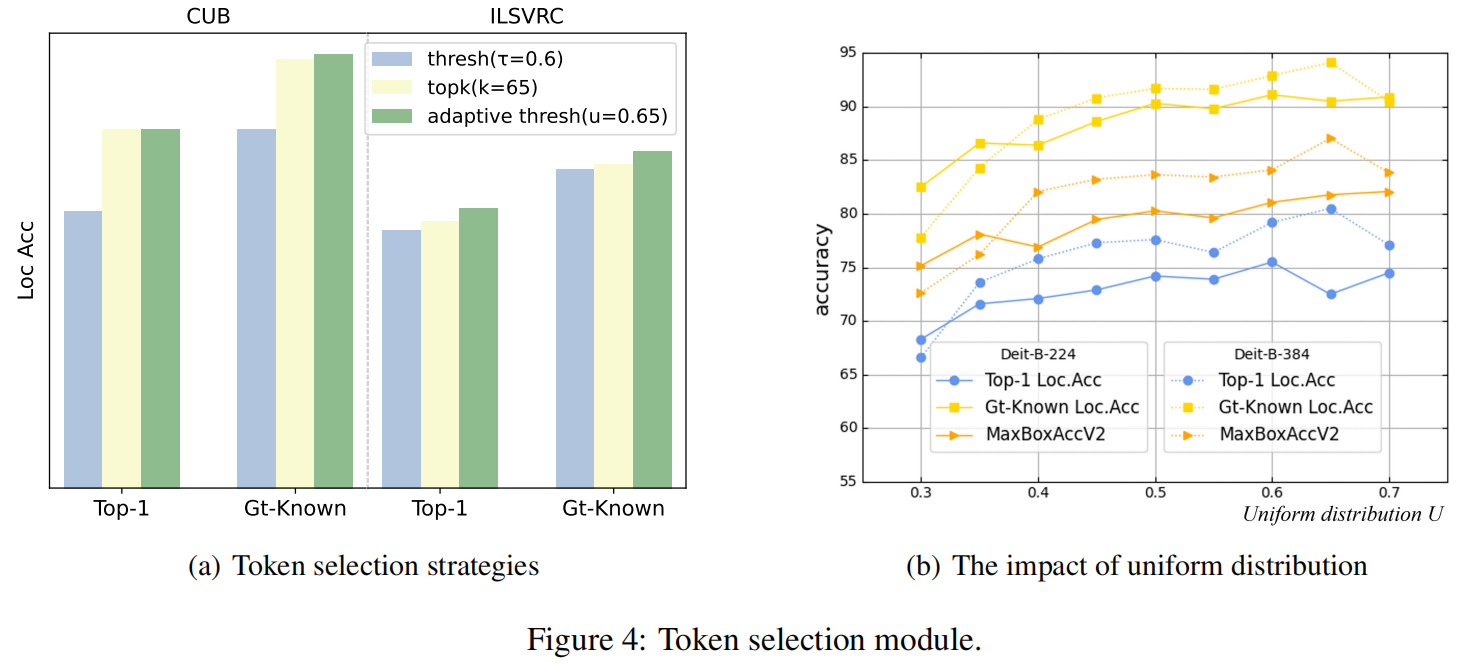
Token初步注意力在多头自注意力的注意力图基础上,考虑patchToken与类Token之间的累积依赖关系。如图2所示,我们被建议抑制无关的背景响应以突出目标区域。直观上,我们可以挑选出前k个最大的响应或超过固定阈值τ的响应。然而,我们通过实验发现,这两种基本策略在实践中并不奏效。因此,我们提出了一种基于累积重要性采样的自适应阈值策略,可以显著提高性能。
我们首先计算m的累积分布函数F,并定义严格的单调变换T: U ~[0,1] →R为反函数,从而
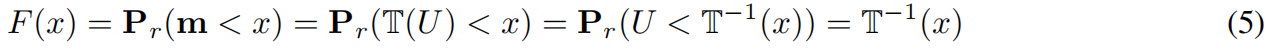
Pr 是概率函数。F被认为是T的反函数,或者T(u) = F−1(u), u ~[0,1]。因此,我们能够从F−1(u)产生自适应阈值τ'。我们表示b = [m > τ']为所选patch token存在的二进制掩码。
3.3.3 Token Re-Attention
设IN为大小为N的单位矩阵。为实现将注意力从背景转移到class-specific目标上的目的,我们生成了选择矩阵B∈RN×N用于token re-attention:

J ∈ RN×1 是一个其中每个元素都等于1的矩阵。⊗表示张量积。B是一个二进制矩阵,其中每一项为Bi,j 意味着第j个token将用于第i个token的更新。我们将transformer块中的自注意模块替换为掩码自注意模块,如下所示:
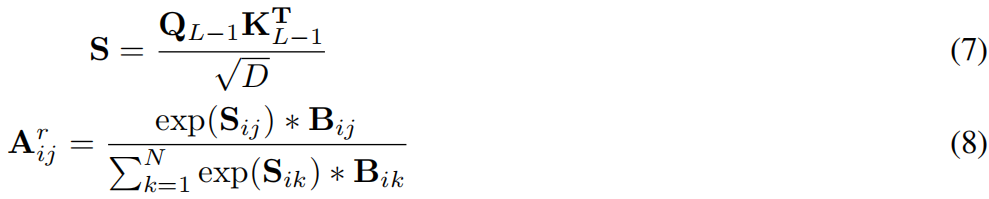
patch token zpL-1被提供给掩码transformer块,然后是全连接层和掩码softmax层,产生重要性权值λ。在训练阶段,利用patch token zpL−1计算重要性权重λ的加权和生成融合嵌入;我们进一步将class嵌入和融合嵌入连接输入到最终的transformer块中,以产生分类损失。在推断阶段,我们从修剪后的token的原始关系m中检索权值。因此,再注意向量定义为:


我们进一步reshape m'∈RN,以产生上下文感知的特征图MT∈![]() 。
。
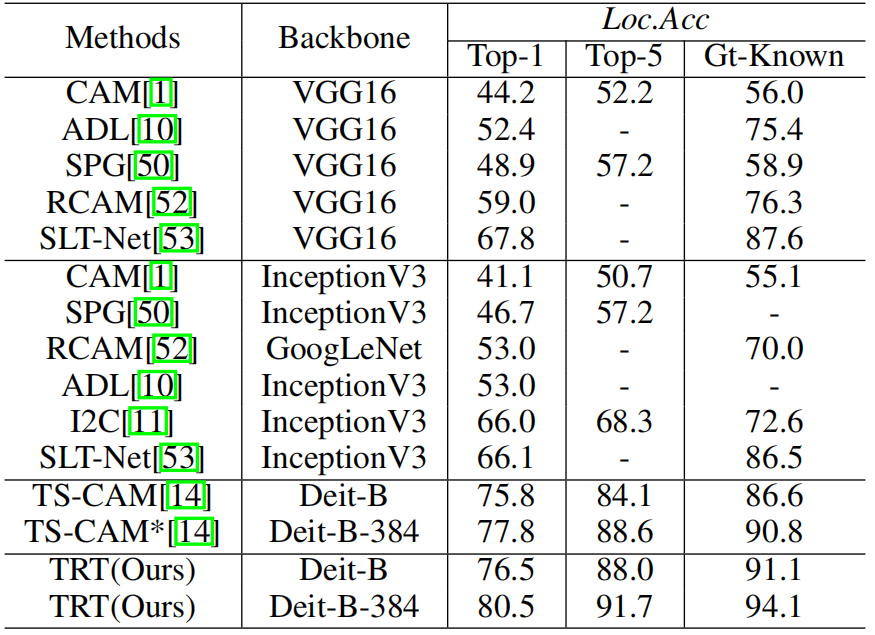
表1:CUB-200-2011 Loc.Acc指标的实验结果。
4实验
4.1实验设置
我们的方法是在4个32GB V100 gpu的PyTorch下实现的。使用Adam进行优化,权值衰减设置为5 × 10−4。使用的backbone是在ImageNet-1K[15]上预训练的Deit-Base[31]。我们在WSOL中两个常用的基准数据集(ILSVRC[15]和CUB-200-2011[16])上评估了我们提出的框架。对于CUB-200-2011[16],每个输入图像的大小被调整为256,并随机剪切为224。batch大小为128,自适应均匀阈值为0.65。我们同时训练了30个epoch的骨干和TPSM分支,然后固定骨干和TPSM分支的参数,并训练了另外15个epoch的CAM分支。对于ILSVRC[15],我们遵循[31]在输入上使用AutoAugment[49]。与CUB-200-2011类似,我们也在前12个epoch训练骨干和TPSM分支,并继续调CAM分支为10个epoch。*表示我们根据提供的代码重现结果,除非另有说明。我们采用与以往工作相同的评价指标:
•Gt-Known Loc。Acc[50]是ground truth类的定位精度,当预测箱与地面货车箱的IOU交集大于50%时,定位精度为正值。
•(/前5 Loc。Acc[15]表示Top-1/Top-5定位精度,满足以下条件:1)预测的类是正确的。2).预测箱与地面箱的IOU大于50%。
•无论分类结果如何,MaxBoxAccV2[51]对IOU阈值的平均定位精度为[30%,50%,70%]。
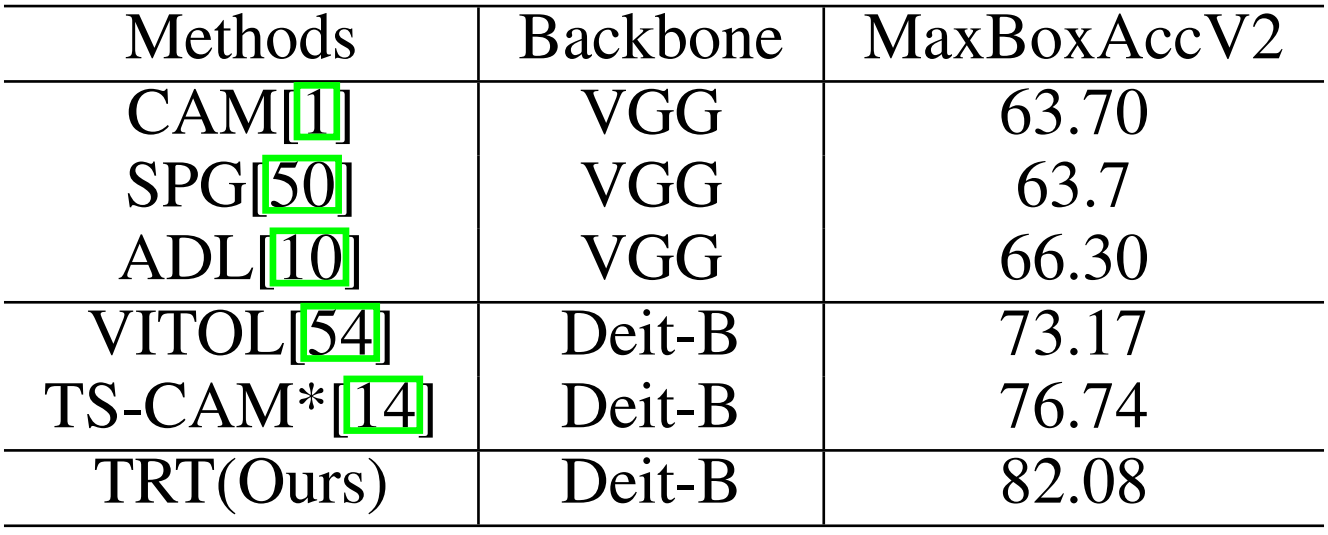
表2:MaxBoxAccV2在CUB-200-2011上的实验结果。
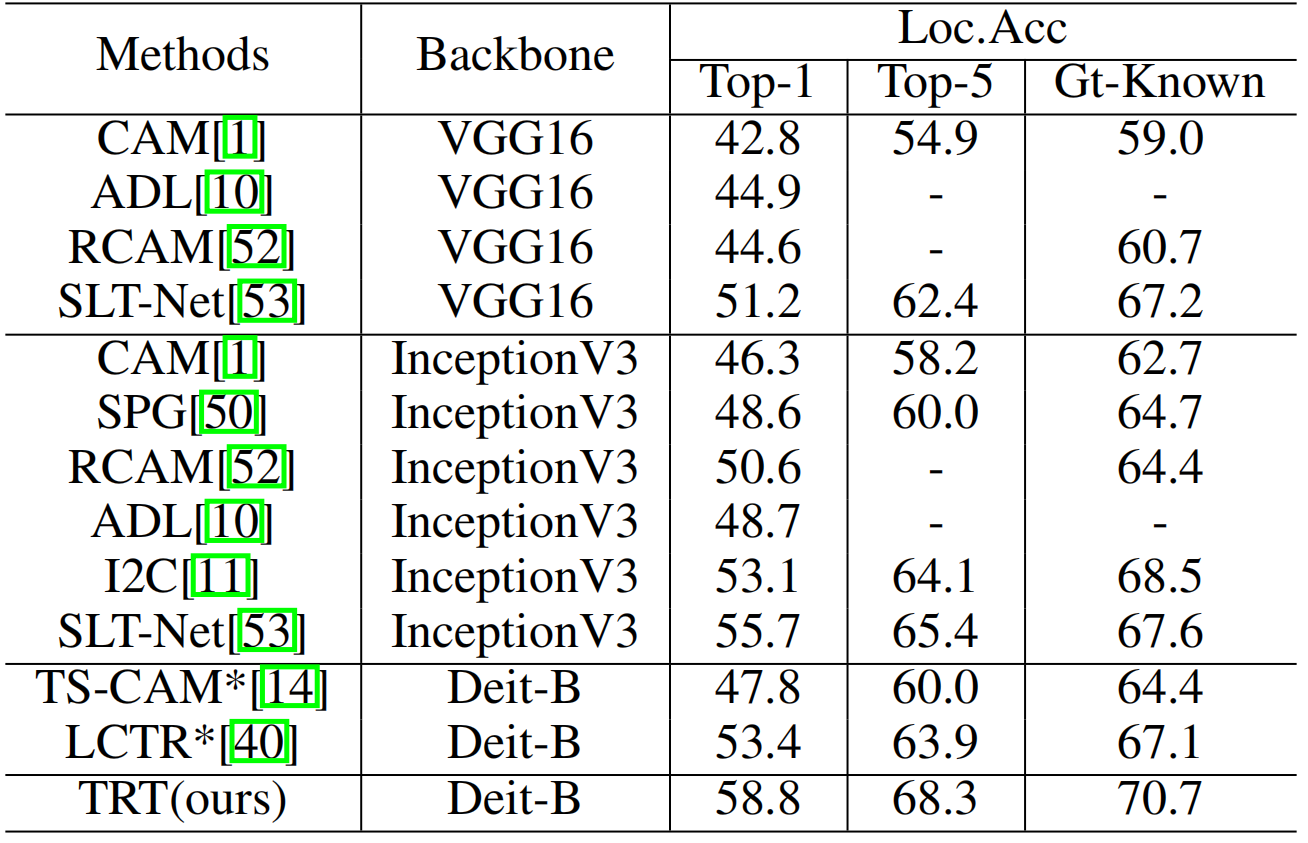
表3:Loc.Acc指标在ILSVRC上的实验结果。
4.2与先进方法的比较
表1和表2展示了我们在CUB-200-2011上提出的TRT框架的竞争性结果。总的来说,与现有方法相比,我们的方法在所有指标上都取得了显著的性能。具体来说,TRT在Gt-Known中以较大的优势优于最先进的方法,其定位精度为91.1%,而87.6%。我们还可以观察到,当使用更高质量的图像时,它比其他方法的好处更突出。至于ILSVRC,表3表明,TRT优于现有的基于CAM和基于transformer的方法。图3说明了定性结果。与基于CAM和基于transformer的技术相比,我们产生的注意力图显示出更多地集中在目标上的视觉优势。
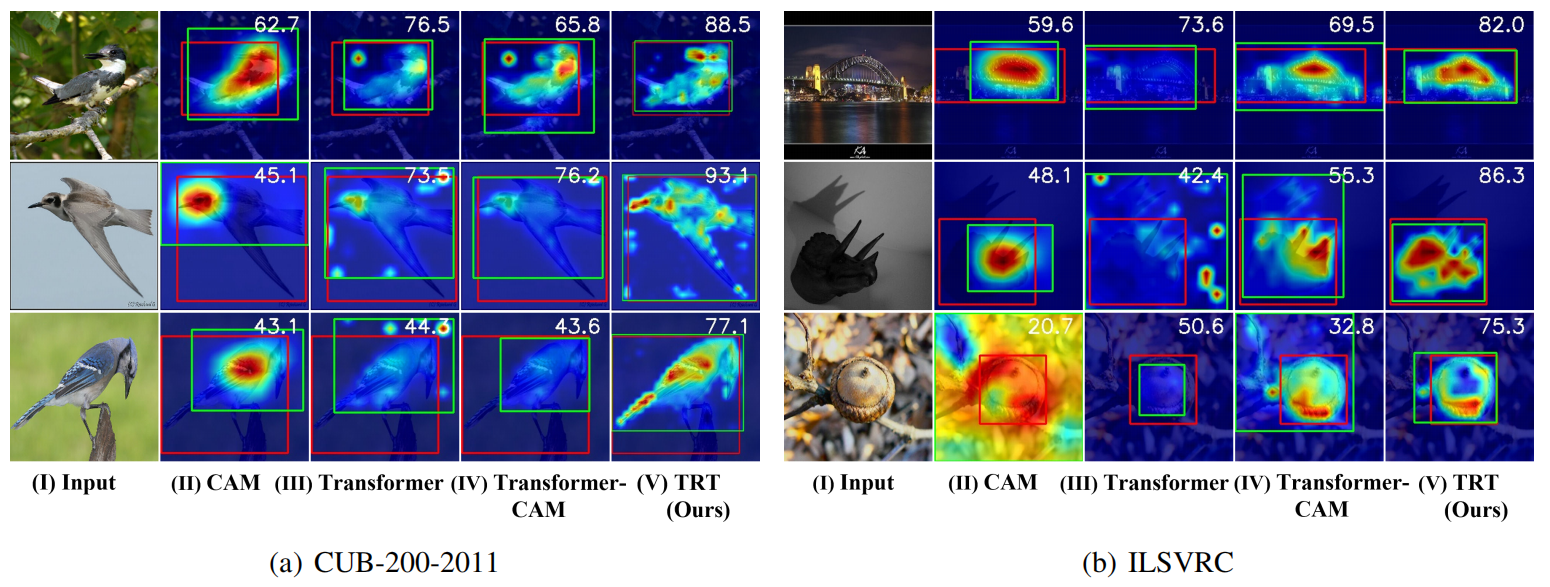
图3:定位地图在CUB-200-2011和ILSVRC数据集上的可视化。
4.3消融研究
在本节中,我们进行了消融研究,以验证我们提出的方法的有效性。首先,如图图4 (a)所示考察了不同token选择策略对性能的影响。实验结果强调了所提出的自适应阈值方法的必要性。图4 (b)经验地告诉我们在CUB-200-2011上的默认设置为u(=0.65)。此外,我们还对再注意模块进行了消融。图5所示的定性和定量的结果都表明,前面提到的re-attention block在framework中起到了至关重要的作用。
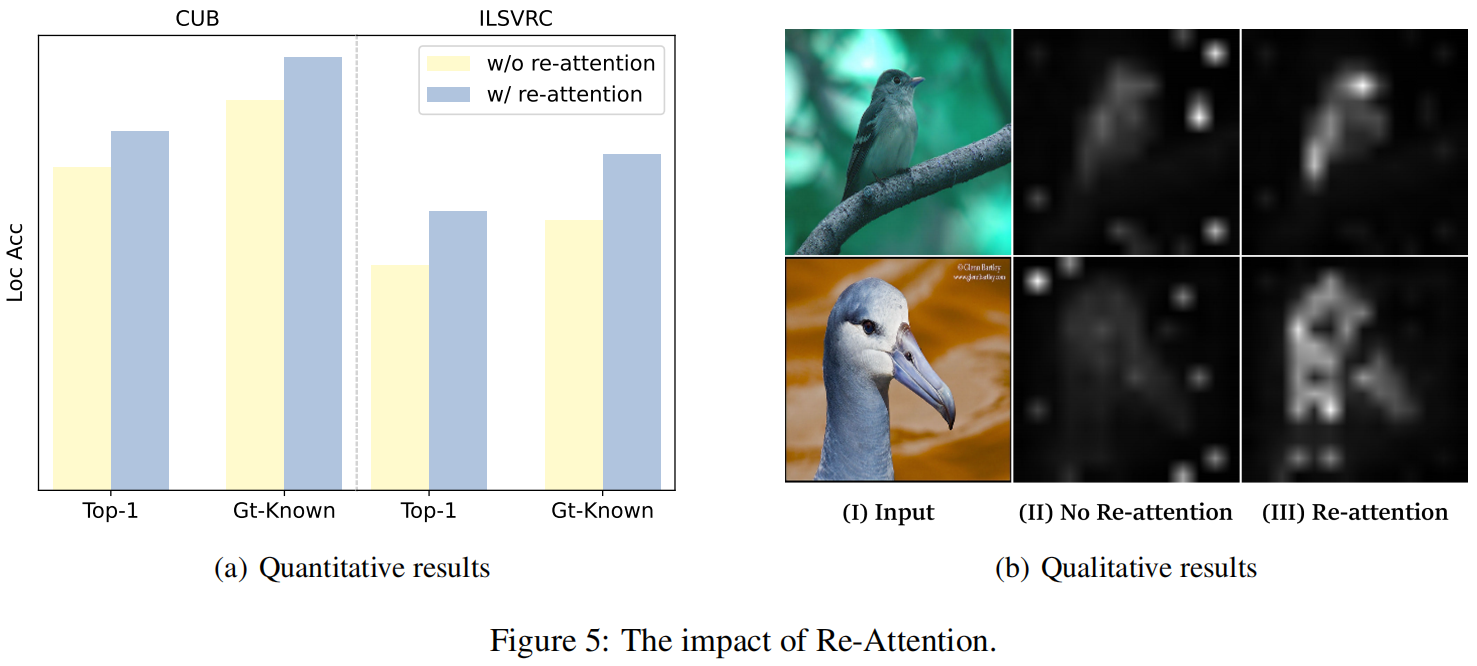
(a)定量结果(b)定性结果图
5结论
引入了一种再注意方法——token refinement transformer,简称TRT,该方法捕获WSOL任务的目标级语义。为了减少背景噪声对目标物体的影响,TRT引入了token优先级评分模块(TPSM)。然后,结合类激活图作为指导对生成的上下文感知特征图进行修正。在两个基准测试上的大量实验表明,我们提出的方法优于现有的方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号