Foreground-Action Consistency Network for Weakly Supervised Temporal Action Localization
0. 前言
摘要
作为高级视频理解的一项挑战性任务,弱监督时间动作定位越来越受到人们的关注。由于只有视频注释,大多数现有方法寻求通过由分类进行定位的框架来处理这项任务,该框架通常采用选择器来选择动作的高概率片段或前景。然而,现有的前景选择策略存在只考虑前景与动作之间的单向关系这一主要局限,不能保证前景动作的一致性。在本文中,我们提出了一个基于I3D主干网的FAC-Net框架,在该框架上增加了三个分支,分别为class-wise前景分类分支,class-agnostic注意力分支和多示例学习分支。首先,我们的class-wise前景分类分支将动作和前景之间的关系规则化,以最大限度地实现前背景分离。此外,采用class-agnostic注意力分支和多示例学习分支对前景动作一致性进行正则化,帮助学习有意义的前景分类器。在每个分支中,我们引入了一种混合注意力机制,该机制为每个片段计算多个注意力分数,以关注判别和非判别片段,从而捕获完整的动作边界。在THUMOS14和ActivityNet1.3上的实验结果证明了我们方法的SOTA性能。
1.介绍
视频中的时间动作定位已经广泛应用于各个领域[39,38]。此任务旨在沿时间维度将未剪辑视频中的动作示例定位。大多数现有的方法[45,35,42,49,4,18,20]都是以全监督的方式进行训练的。然而,这种对帧级注释的要求不适合实际应用,因为对大规模视频进行密集注释既昂贵又耗时。为了解决这个困难,弱监督方法[14,1,41]被开发出来,只有视频级别的标签,更容易注释。在各种弱监督方法中,视频级类别标签最容易收集,因此最常用[41,26,31]。
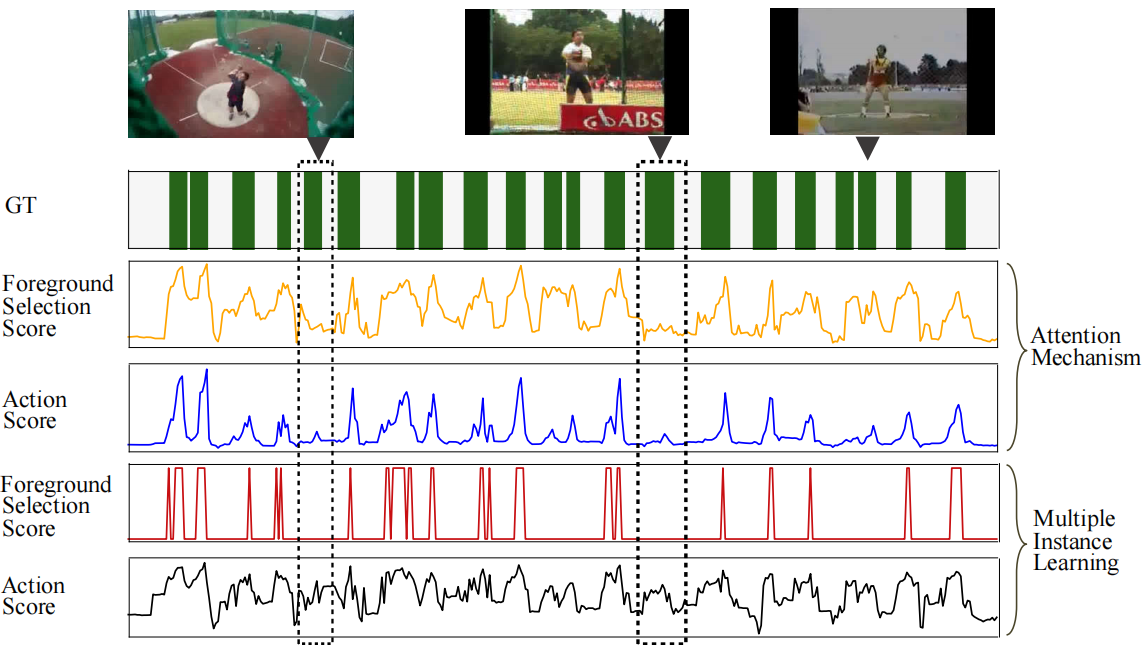
图1。“掷链球”动作的一个例子。条形码是ground-truth(GT)。下面的折线图是前景选择分数和帧分类分数。我们展示了两种有代表性的方法STPN[31](注意力机制)和W-TALC[26](多示例学习)的结果。显然,这些方法无法保证前景动作的一致性,从而导致结果受损。
由于缺乏帧级注释,现有工作主要采用通过定位进行分类的流程[41,44],其中一个重要组成部分是选择器,用于选择具有高动作概率的片段,即前景。现有的前景选择机制可分为两种主要策略,即注意力机制[26,19]和多示例学习(MIL)[31]。然而,这两种策略都有其固有的缺点。如图1所示,注意力机制(class-agnostic注意力或class-wise注意力)通常存在分类和检测之间的差异[37,50,19],即注意力集中在最具辨别力的动作片段上,或错误地集中在背景片段上。另一方面,多示例学习应该依赖于一个时序top-k pooling操作,但是不能保证所有的top-k片段都是前景,因为数字k通常是由人类定义的。总之,现有的方法缺乏保持前景和动作之间一致性的能力,也就是说,前景和动作应该是相互包容的。
在这项工作中,我们提出通过显式建模和正则化前景动作一致性来解决动作定位问题。考虑到现有前景选择策略只考虑前景与动作之间的单边关系,我们提出了进一步考虑双边关系的框架。基于一个公共视频主干,我们的方法在其上附加了三个分支。第一个分支被命名为类级前景分类分支(CW分支,第3.2节),旨在对动作与前景关系进行建模。同时,它的作用类似于噪声对比估计(NCE)[6,28],它实际上最大化了前景特征和ground-truth动作特征之间的互信息下限(MI),从而实现更好的前景背景分离。第二个分支(CA分支,第3.3节)引入了一种class-agnostic注意力机制,该机制对反向前景到动作的关系进行建模,以补充第一个分支,从而建立前景动作的一致性。此外,它还可以学习语义上有意义的前景特征。第三个分支(MIL分支,第3.4节)是一个类似MIL的流程,用于进一步改进视频分类,并促进CW分支的class-wise注意力学习。
在每个分支中,我们采用一种混合注意力机制来简化注意力学习,并促进精确的前景预测。除了关注视频中的关键帧外,混合注意力机制还可以学习适应辨别力较弱的片段,这有助于捕捉准确的动作边界。为了评估我们方法的有效性,我们在两个基准上进行了实验,THUMOS14[11]和ActivityNet1.3[2]. 在这两个基准上的实验结果表明,它的性能优于最先进的方法。
我们的主要贡献有三个方面。(a) 为了提高前景预测的鲁棒性,我们引入了一种class-wise前景分类流程。该流程对现有方法大多忽略的前景动作一致性进行建模和正则化。(b) 我们提出了一种混合注意力机制来提高注意力学习,并帮助捕捉准确的动作边界。(c) 与现有方法相比,本文提出的class-wise前景分类流程可以起到补充作用,从而持续提高动作定位性能。
2.相关工作
全监督时序动作定位。与动作识别[12,36,40,3]不同,时间动作定位旨在定位动作示例的起点和终点,同时识别每个动作示例的动作类别。我们将完全监督的方法分为两类。第一类方法采用多阶段流程,包括提案生成,分类和提案细化。这些方法主要关注于提高提案的质量[5,18],以及学习稳健而准确的分类器[35,49]。在第二类中,方法旨在生成帧级粒度的动作标签[33,15,47],这需要额外的合并步骤来获得最终的时间边界。尽管这些方法取得了很好的性能,但它们严重依赖于帧注释。
弱监督时序动作定位。近年来,人们尝试用弱标记来解决时间动作定位问题。UntrimmedNet[41]提出选择具有注意力机制或多示例学习的相关片段,然后是大多数后续方法。
基于注意力的方法旨在利用注意力机制选择动作概率较高的片段。例如,STPN[26]在注意力序列上引入了稀疏正则化,以捕获视频的关键帧。3C Net[25]建议学习class-wise注意力,以获得计算中心损失的class-wise特征。一些方法[27,24,9]利用前景和背景的互补性来生成前景和背景注意力序列,以明确地建模背景。HAM-Net[10]提出了一种混合注意力机制,包括时序软,半软和硬注意力,以捕获完整动作示例。注意,我们的方法也利用了混合注意力机制,但与HAM-Net完全不同。首先,我们利用不同的温度值生成多个前景注意力序列,而HAM-Net主要通过阈值分割生成软,半软和硬注意力序列。其次,我们只生成前景注意力序列,而HAM-Net的硬注意力序列也包含背景片段。
基于MIL的方法[31,16,24]可以被视为基于多示例学习原理的硬选择机制。与自动学习注意力权重的基于注意力的方法不同,基于MIL的方法主要依靠top-k选择操作来选择包(视频)中的积极示例。然而,如上所述,无论是基于注意力的方法还是基于动作的方法都不能保持前景动作的一致性。
有一些方法已经注意到前景动作一致性的重要性。例如,RefineLoc[29]通过扩展之前的检测结果生成片段级硬伪标签,TSCN[48]从前景注意力序列生成伪ground-truth,EM-MIL[21]将伪标签生成置于期望最大化框架中。还有一些方法[27,24,10]试图使用类激活作为自上而下的监督来引导前景注意力的产生。相比之下,我们的方法不需要额外的监督来加强前景动作的一致性,理论上我们可以实现更好的前景背景分离。
3.提出的方法
在本节中,我们将详细介绍所提出的方法。所提出方法的概述如图2所示。
问题定义。V = {vt}Lt-1是一个时序长度为L的视频。假设我们有N个具有动作类别{yi}Ni=1标注的训练视频{Vi}Ni=1,其中yi是一个二进制向量,指示每个动作的存在/不存在。在推断过程中,对于一个视频,我们预测一组动作示例{(c,q,ts,te)},其中c表示预测的动作类别,q是置信度得分,ts和te表示开始时间和结束时间。
关系定义。(1) 前景动作的关系:前景与动作的单边关系,即前景必须是某种动作。(2) 动作前景关系:从动作到前景单边关系,即动作必须是前景。
概述。我们的方法有四个模块。基于I3D主干,我们利用特征嵌入模块(第3.1节)提取面向任务的特征。然后,在其top-k附加三个分支。第一个分支被命名为类级前景分类分支(CW分支,第3.2节),旨在对动作与前景关系进行建模。第二个分支(CA分支,第3.3节)引入了class-agnostic注意力机制,对反向前景到动作关系进行建模,以补充第一个分支,从而建立前景动作一致性。第三个分支(MIL分支,第3.4节)是一个MIL-like流程,用于改进视频分类,并促进CW分支的class-wise注意力学习。
3.1.特征嵌入模块
为了提取面向任务的特征,我们使用了一个包含两部分的特征嵌入模块。第一部分是预先训练好的网络,即I3D[3]。给定一个视频,我们首先通过固定主干网分别提取RGB特征和光流特征。在特征编码之后,我们使用两层时间卷积网络[31,19]来学习面向任务的特征Xe∈RT×D,其中T表示片段的数量,D是维度。
3.2.Class-Wise前景分类分支
如上所述,前景和动作应该一致且相互包容。然而,大多数现有的方法只考虑前景到动作关系,换言之,它们只利用了前景必须是动作这一先验知识。一个可能的结果是,获得的前景分数只关注判别动作片段。直观地说,前景和动作之间的合理关系应该是双边的,有必要进一步考虑动作与前景关系。受class-agnostic注意力流程[26,19,16]的启发,我们在方法中提出了一个对称流程,称为class-wise前景分类流程。
我们随机初始化一个动作分类器Wa∈R(C+1)×D和一个前景分类器Wf∈RD,其中C表示动作类别的数量,(C+1)类对应于背景。给定嵌入Xe,我们计算Xe和Wa之间的余弦相似性以获取类激活分数Sa∈RT×(C+1)
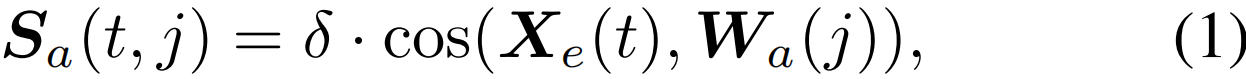
其中Xe(t)表示第t个片段的嵌入,δ是控制值大小的标量。
为了建立动作到前景关系,我们遵循动作片段也是前景片段的原则,计算class-wise注意力得分Aa∈RT×(C+1),用于将嵌入信息聚合到video-specific calss-wise特征Fa∈R(C+1)×D
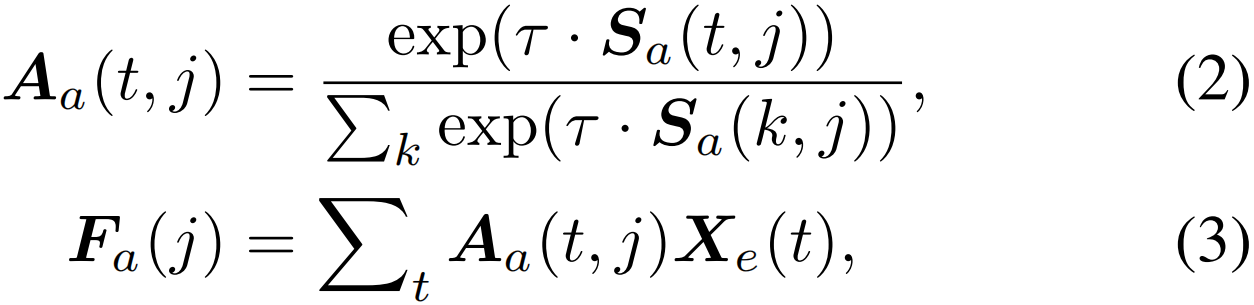
其中t表示第t个片段,j表示第j个类别,τ是控制softmax函数平滑度的温度超参数。显然,如果在视频中存在第j类动作,特征Fa(j)应该被识别为前景。相反,如果视频中没有该动作,则应将其归类为背景。这一观察促使我们为特征Fa引入前景分类过程。具体地说,给定前景分类器Wf,我们可以获得class-wise前景激活分数Ra∈RC+1和class-wise前景置信度Pa∈RC+1
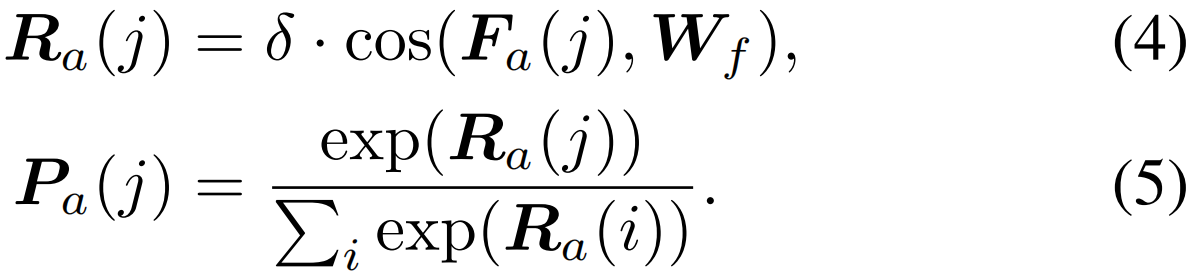
归一化交叉熵损失Lcw计算如下:
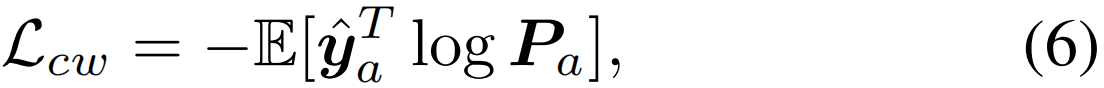
其中![]() 是归一化的ground-truth向量,y(C+1)=0。此时,我们实际上将多标签分类问题转化为多个二进制分类问题。
是归一化的ground-truth向量,y(C+1)=0。此时,我们实际上将多标签分类问题转化为多个二进制分类问题。
讨论:即使CW分支很简单,它在前景背景分离中也起着重要作用。
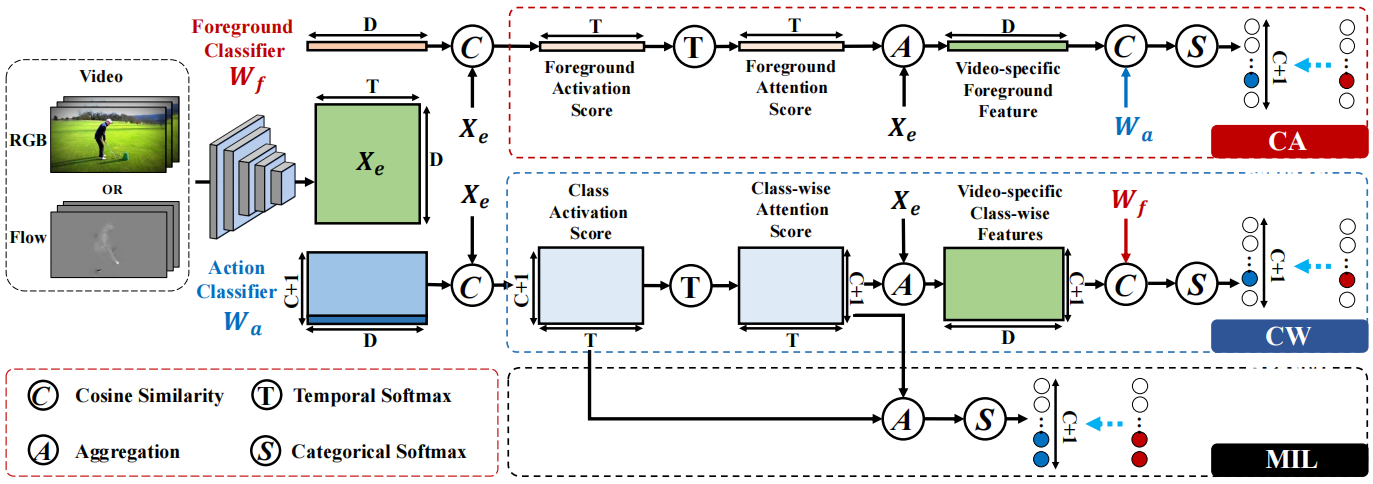
图2。我们的方法的概述。我们有三个主要的分支机构。类级的前景分类分支(CW分支)寻求建立从动作到前景关系,而class-agnostic的注意力流程(CA分支)则补充了从前景到第一个分支的动作的反向关系,从而建立前景-动作的一致性。多示例学习分支(MIL分支)是一个类似MIL的流程,为视频分类提供不同的视角,促进class-wise注意力的学习。关于混合注意力策略的详细信息,请见图3。
具体来说,我们可以将等式(5)转换为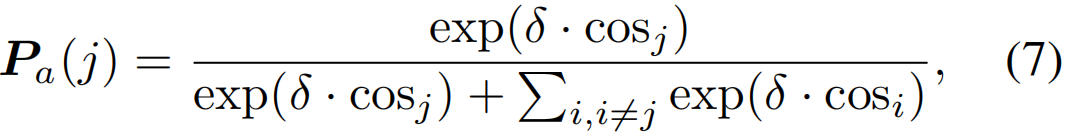
其中cosj是cos(Fa(j),Wf)的简化。如果视频中没有动作类别i(i≠j),则特征Fa(i)应为背景特征。所以前景有一个阳性样本(如果视频中只有一个类别),背景有C个阴性样本。因此,等式(7)类似于噪声对比估计(NCE)[6,28,7]过程,最小化等式(6)实际上最大化了前景分类器Wf和特征Fa(j)之间的互信息下限(MI)。此外,背景特征是从特征Fa(j)的同一视频中采样的,它们可以被视为难负样本,因为动作示例通常被视觉上相似的片段包围[19],这进一步保证了前景-背景分离。因此,CW分支不仅将action-to-foreground关系引入到我们的方法中,而且能够学习鲁棒性和区分性特征。然而,上面的分析应该基于一个有意义的前景特征,但是对于背景类,前景分类器的特征Wf和背景特征Wa(C+1)之间存在歧义,导致我们的实验中所示的性能较差。因此,增强Wf的前景意义至关重要。此外,CW分支只考虑从动作到前景单边关系,这不足以建立前景动作的一致性。
3.3.class-agnostic注意力分支
为了弥补从前景到动作关系的缺失,我们采用了一个class-agnostic注意力分支(CA分支),它还可以学习一个语义上有意义的前景分类器Wf,对CW分支起到补充作用。我们首先计算帧级前景激活分数Sf∈RT获得前景注意力分数Af∈RT:
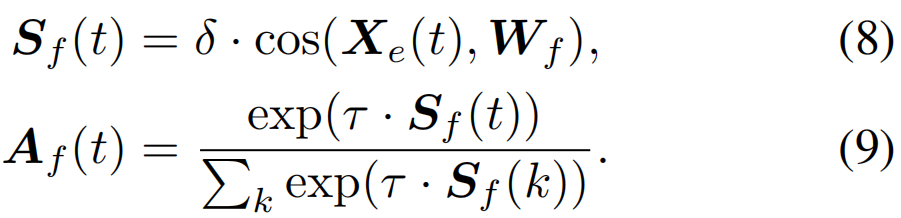
同样,我们可以获得特定于视频的前景特征Ff∈RD通过特征聚合过程
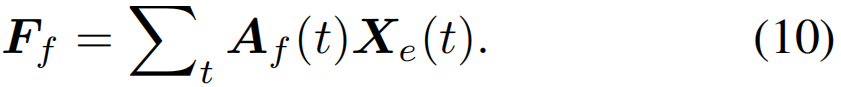
然后计算特征和动作分类器之间的余弦相似度,得到视频级别的类置信度Pf∈RC+1
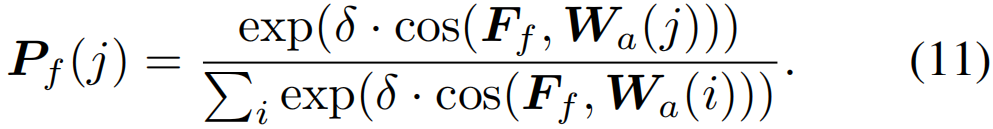
归一化交叉熵损失Lca计算如下:
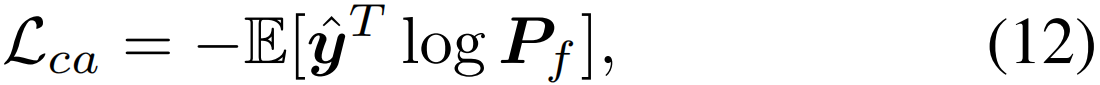
其中![]() 与CW分支相同,即y(C+1)=0。这样,CA分支与CW分支完全是对称流程,这也与它们引入的反向关系一致。
与CW分支相同,即y(C+1)=0。这样,CA分支与CW分支完全是对称流程,这也与它们引入的反向关系一致。
3.4.多示例学习分支
除了class-agnostic注意力流程外,多示例学习(MIL)流程也是CW分支的一个很好的补充。首先,MIL流程还考虑了从前景到动作的单边关系。
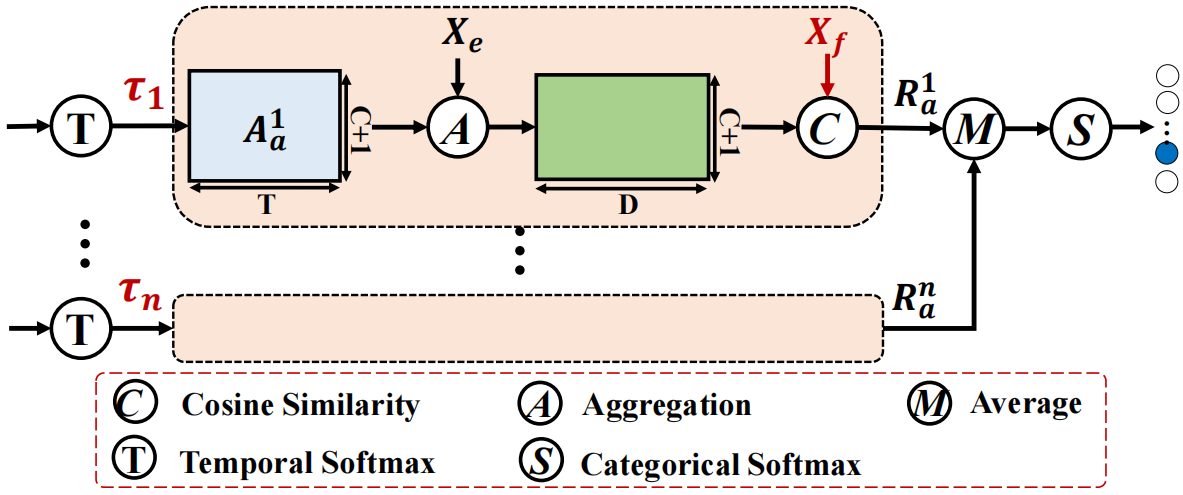
图3。CW分支的混合注意力策略说明。我们使用N个不同的τ来计算N个class-wise注意力分数{Aia}Ni=1,视频级前景激活分数{Ria}Ni=1求平均值以获得最终的前景激活分数,其他两个分支以同样的方式使用这种策略。
第二,MIL的时序top-k平均池化实际上是一种class-wise硬注意力操作,这有助于更好地学习CW分支中的class-wise注意力分数。此外,MIL更关心一个类是否出现在整个视频中,而class-agnostic注意力更多地关注局部(因为每个帧的聚合是线性的),这两条流程提供了两种不同的视角来对视频进行分类,并且在某种程度上是互补的。为了更好地将MIL流程引入到我们的框架中,我们将时序top-k平均池化更改为class-wise软注意力操作,即,我们共享类级注意力分数Aa(等式(2)),然后将帧级类激活分数Sa(等式(1))聚合为视频级类激活分数Rm∈RC+1
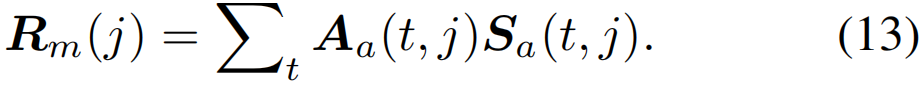
与CW分支和CA分支类似,我们可以得到其相应的预测Pm∈RC+1和归一化交叉熵损失Lmil。注意,由于背景片段存在于所有视频中,MIL分支的ground-truth y应该具有背景,即y(C+1)=1。
3.5.混合注意力
正如我们所见,注意力机制在我们的框架中起着重要作用。然而,即使我们努力构建前景动作一致性,我们发现注意力分数仍然不能很好地覆盖ground-truth。正如[19]所述,注意力得分倾向于关注有区别的前景片段和视觉上相似的背景片段。为了解决这个问题,同时保持基于注意力的结构,我们提出了一种混合注意力策略。动机来自于与[26]类似的观察,也就是说,一个动作可以通过识别一组关键帧来识别。如果我们能把注意力集中在关键帧上,误报率有望大大降低。为了实现这一点,我们采用了一种简单但有效的方法,即使用大温度超参数τ来产生注意力(例如,公式(2)和公式(9))。这样,注意力分数就会集中在高置信度的片段上。
然而,考虑到仅关键帧是不够的,假阴性也会增加。幸运的是,因为关键帧是由新的注意力分数(τ>1.0)建模的,所以原始的注意力分数(τ=1.0)必须容纳一些不太区分的动作片段,这为我们的方法提供了一种回退机制。因此,使用混合注意力策略将是提高性能的合理方法。如图3所示,对于CW分支,我们首先使用N个不同的τ来计算N个class-wise注意力分数{Aia}Ni=1。对每个class-wise注意力分数Aia,我们可以获得视频级前景激活分数Ria(等式(4))。最后,我们平均并使用softmax运算(等式(5))获得概率置信分数。其他两个分支以同样的方式使用混合注意力策略。
3.6.训练目标
我们的模型与三个视频级别的分类损失进行了联合优化。总损失函数如下所示:
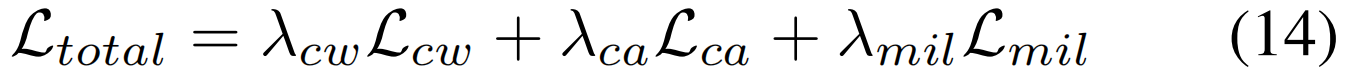
其中,λcw,λca和λmil是平衡超参数。我们的方法也可以在没有后台类的情况下工作。此时,我们使用原始ground-truth y∈RC
4.实验
4.1.数据集集合
我们在两个动作定位数据集THUMOS14[11]和ActivityNet1.3[2]上评估了我们的方法。请注意,我们仅使用视频级别类别标签进行训练。
THUMOS14。我们使用THUMOS14中的子集,该子集为20个类提供了帧注释。我们在验证集中的200个未修剪视频上训练模型,并在测试集中的212个未修剪视频上对其进行评估。
ActivityNet1.3。该数据集涵盖200项复杂的日常活动,提供10024个训练视频,4926个验证视频和5044个测试视频。我们使用训练集来训练我们的模型,使用验证集来评估我们的模型。
4.2.实施细节
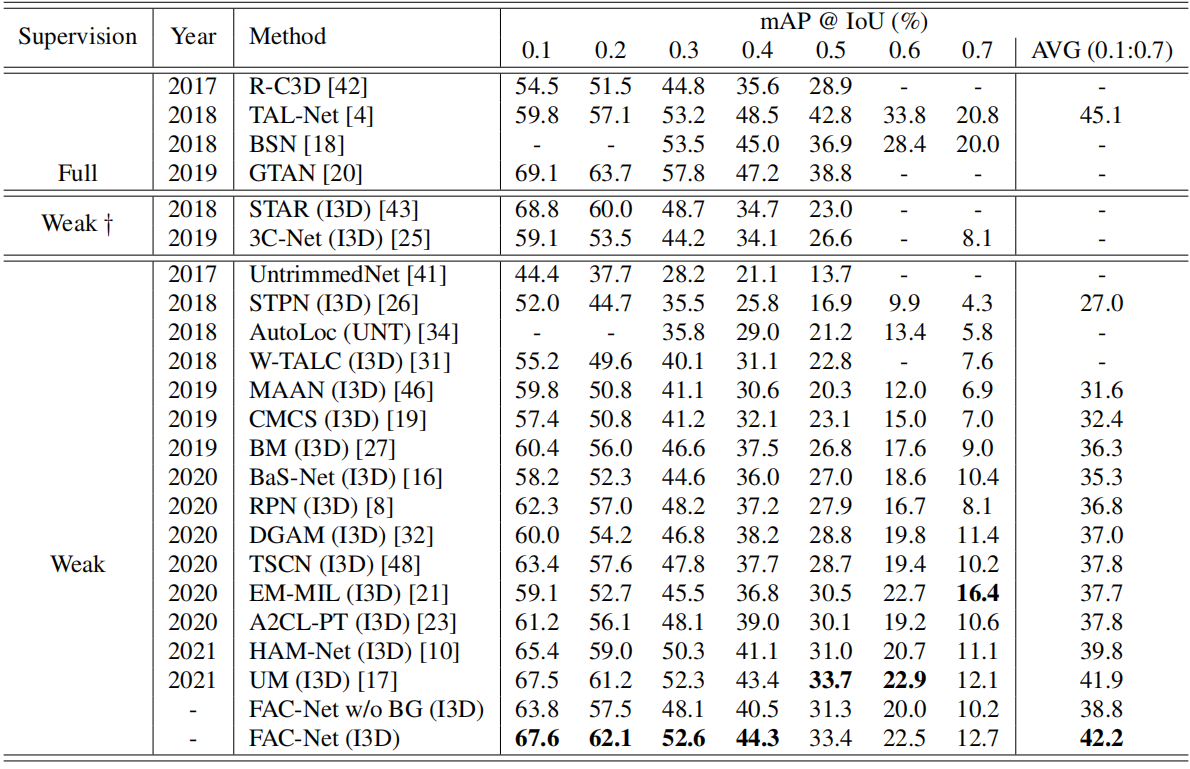
表1。对THUMOS14数据集上的检测性能进行比较。AVG列表示IoU阈值0.1:0.1:0.7下的平均mAP。Unt和I3D分别表示未网特征和I3D特征。†意味着该方法利用了额外的弱监督。FAC-Netw/oBG表示我们的方法不使用背景类。
模型细节。我们使用I3D[3]进行特征提取。用于提取面向任务特征的网络包含两层,输出通道分别为1024和1024。余弦相似性的比例因子δ设置为5.0。我们以三个头的方式使用混合注意力策略,温度超参数为1.0,2.0和5.0。在我们的模型中,我们使用ReLU作为激活函数,在所有激活函数之前使用退出层。
训练细节。我们的方法是用PyTorch[30]实现的。在训练期间,我们在小批量中循环播放每个视频,并累积梯度以处理可变的视频长度。我们使用Adam[13]来优化我们的模型,训练过程在100个阶段停止,学习率为0.0001。平衡超参数λcw,λca和λmil分别为1.0,0.1和0.1。
测试细节。我们将整个视频序列作为测试的输入。当定位动作示例时,类激活序列将被上采样到原始帧速率。我们拒绝类别概率Pf(j)(等式(11))低于0.1的类别。在[16]之后,我们使用一组阈值来获得预测的动作示例,然后我们执行非最大值抑制来移除rgb流和光流流之间的重叠段。
4.3.与最新技术的比较
如表1所示。在THUMOS14上,即使我们不采用背景类(即FAC Net w/o BG),我们的该方法仍然优于现有的背景建模方法[27,16],表明了构建前景动作一致性的有效性。此外,通过使用background类,我们的方法获得了新的最先进的性能,在最多IoU threholds和平均mAP下实现了地图增益。值得注意力的是,我们的方法在IoU 0.1和0.2下优于一些完全监督方法,体现了弱监督方法的潜力。
表2演示了在ActivityNet1.3数据集上的结果。正如我们所看到的,尽管架构简单,我们的方法仍能获得与SOTA相当的性能,并在平均mAP方面分别比完全监督的方法R-C3D[42]和TAL Net[4]高出11.3%和3.8%。
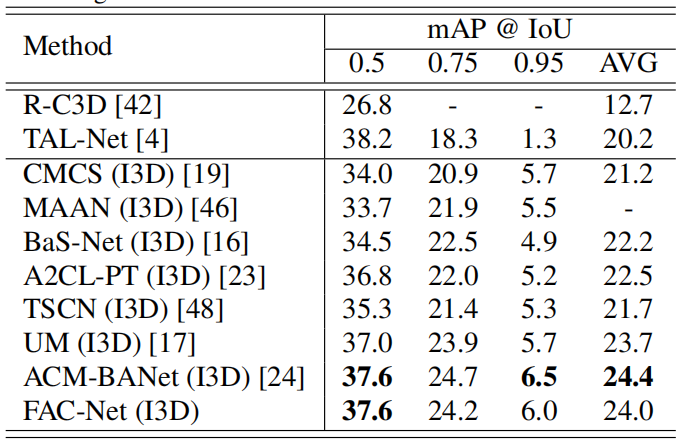
表2。ActivityNet1上的结果。3.验证集。AVG表示IoU阈值为0.5:0.05:0.95时的平均mAP。
4.4.消融实验
我们在THUMOS14数据集上进行了一系列消融研究,以分析每种成分的贡献。分支分析。要想弄清楚每个分支的贡献,我们应该考虑两个问题:个体分支的表现是什么?不同的分支之间是什么关系?在表3中,即使三个分支中的每一个只考虑前景和动作之间的单边关系,CW分支也获得了更好的性能(31.2%),表明动作和前景之间的关系更重要,这也可以加强前景-背景分离。此外,将任何两个分支组合起来都可以持续提高性能,从而显示出三个分支之间的互补关系。特别是,CW分支可以将CA分支和MIL分支的性能平均分别提高5.4%和4.8%。
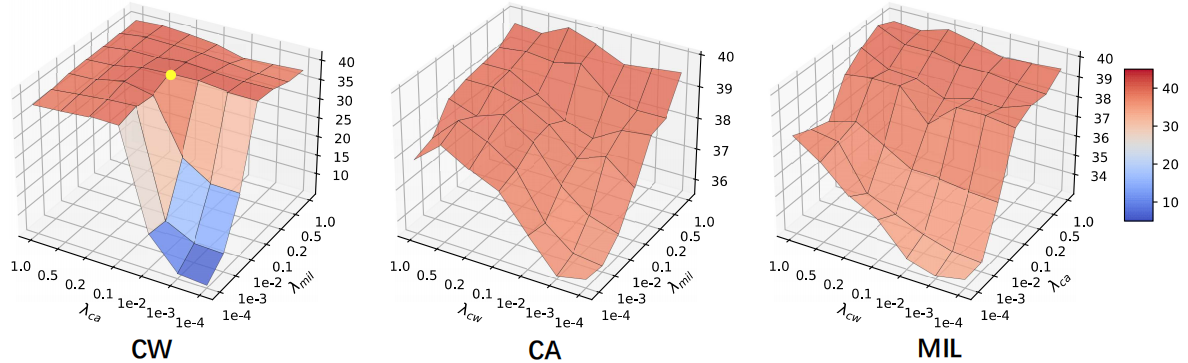
图4。关于平衡超参数λcw,λca和λmil的消融实验,我们在这些实验中使用了一个背景类。
在图4中,我们通过控制三个平衡超参数进一步探索了分支之间的关系。例如,当我们评估CW分支时,我们将λcw固定为1.0,并调整其他两个分支的平衡超参数。请注意,我们在这些实验中使用了一个背景类。我们可以发现,当λca和λmil很小时,性能下降到非常低的水平(约6%)。这是因为带有背景类的前景分类器Wf引起了前景和背景的歧义,导致性能低下。当λca和λmil较大时,性能对λcw不敏感,并保持在一个有希望的水平(40.0%以上)。此外,将CW分支作为主分支可以获得最佳结果,即使将其用作辅助分支,也可以提高性能。
为了直观地了解这三个分支,在图5中,我们可视化了不同分支组合下基础真相的前景激活分数(等式(8))和动作激活分数。添加CW分支后,前景激活分数可以更好地覆盖ground-truth,从而获得更准确的检测结果。
混合注意力的影响。通过表3,我们可以看到,混合注意力可以持续提高性能,尤其是对于单分支。另外,表4显示了关于注意力次数和温度超参数τ的消融实验。我们可以发现,关注的次数并不是越多越好,过多的关注会降低性能。类似地,一个较大的τ,例如10.0,也会对模型产生不利影响,使其过于关注有区别的片段。在图6中,我们还可视化了不同混合注意力设置下的前景激活分数和动作激活分数。显然,混合注意力的引入能够获得更准确的前景预测。

表3。THUMOS14数据集的消融研究。AVG列表示IoU阈值为0.1:0.7时的平均映射。
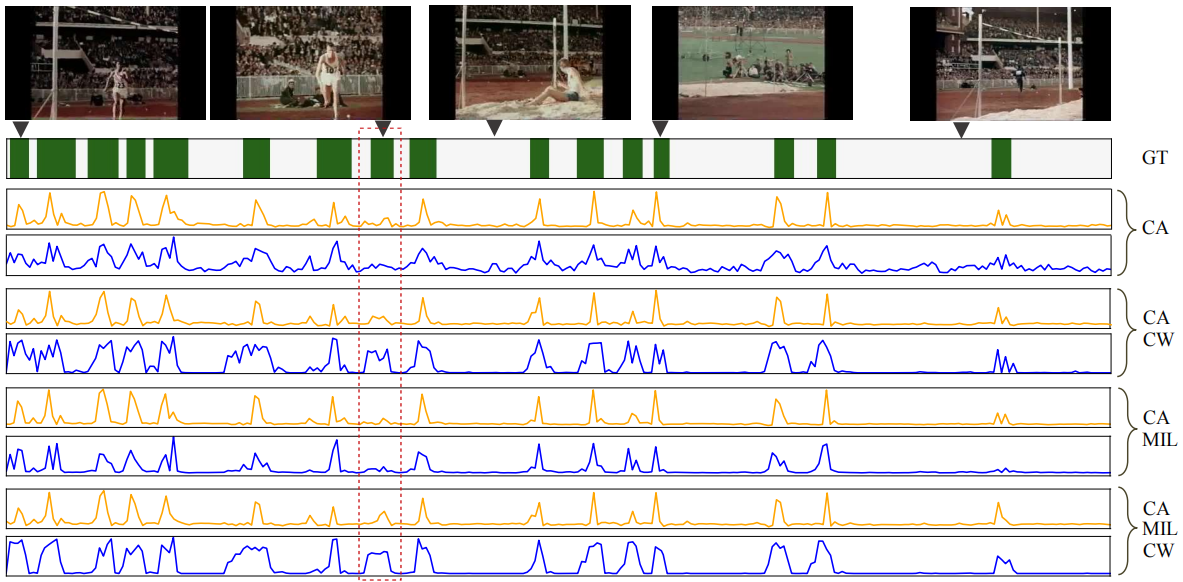
图5。不同模型设置下前景激活分数和动作激活分数的可视化。我们展示了THUMOS14中“撑杆跳”的一个例子。为了公平比较,我们不使用背景类。
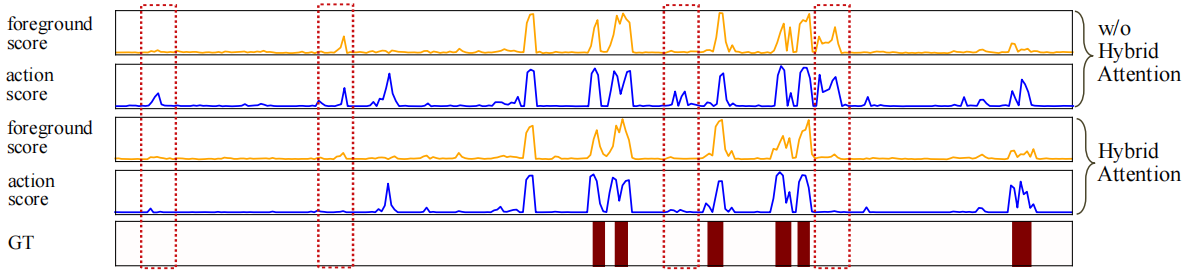
图6。前景激活分数和动作激活分数的可视化,不使用和使用混合注意力策略。我们展示了THUMOS14中“悬崖跳水”的一个例子。
CW分支的补充作用。鉴于现有方法忽略了对地面关系的作用,直观地说,CW分支可能对现有方法起到补充作用。在标签上。5.我们将CW分支插入到四种弱监督方法中。我们可以发现CW分支可以显著提高两种经典方法STPN[26]和W-TALC[31]的性能,分别提高了1.7%和1.9%。尽管BM[27]明确建模了背景,但CW分支可以进一步提高其性能。此外,最近的方法UM[17]的性能也可以得到改进。
图7。THUMOS14[11]的定性结果。我们显示:1)前景激活分数,2)ground-truth动作的激活分数,3)检测到的动作示例和4)ground-truth值。左图:高尔夫球挥杆的一个例子。右图:排球飙升运动的一个例子。
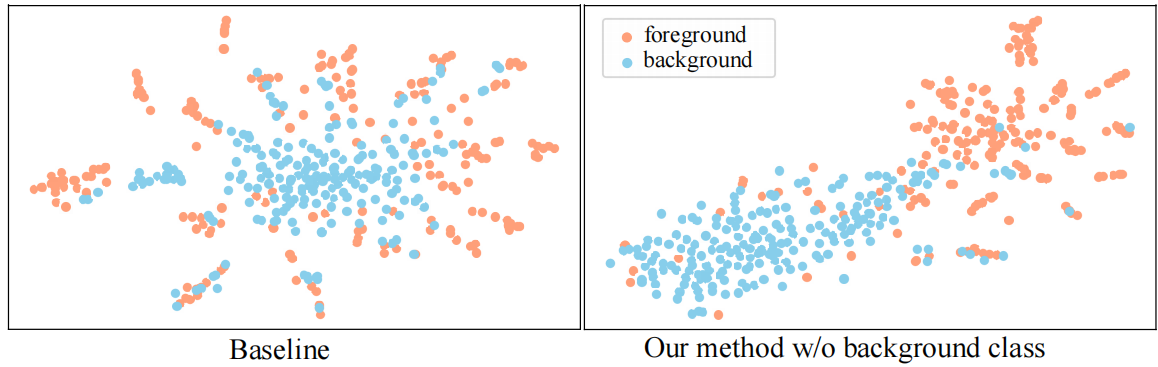
图8。在THUMOS14测试集上,通过t-SNE[22]可视化(a)仅CA分支和(b)我们的方法的嵌入特征的前景背景分离。请注意力,为了公平比较,我们在两种模型中都不使用后台类。
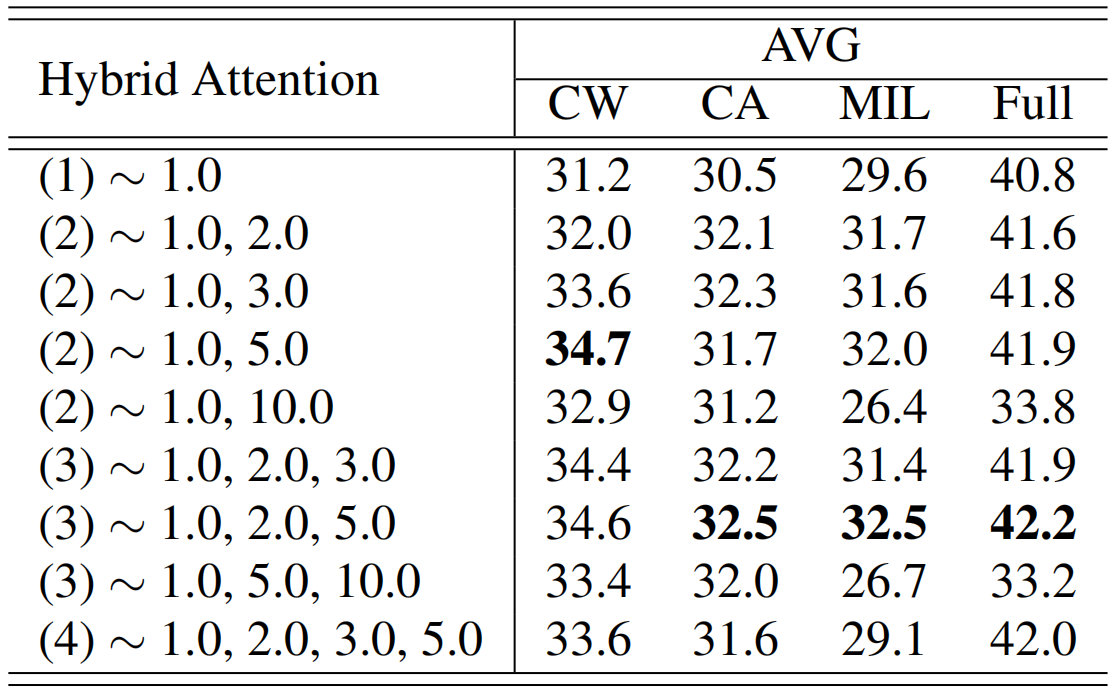
表4。在THUMOS14上评估杂交注意力。每行显示一个混合注意力设置,例如“(2)∼ 1.0,2.0“表示我们使用两个注意力分数,温度超参数分别为1.0和2.0。
4.5.定性结果
我们在图7中展示了一些检测到的动作示例。在高尔夫挥杆的第一个例子中,我们的方法只针对一个动作示例。在排球扣球的第二个例子中。尽管这个动作经常在视频中执行,但我们的方法成功地检测到了所有动作示例,这显示了处理密集动作发生的能力。正如我们所见,我们的方法显著抑制了背景的反应。此外,前景分数和动作分数是一致的,很好地覆盖了ground-truth。图8显示了特征Xe关于前景背景分离的可视化结果。如我们所见,我们的方法比基线模型能更好地分离前景和背景。
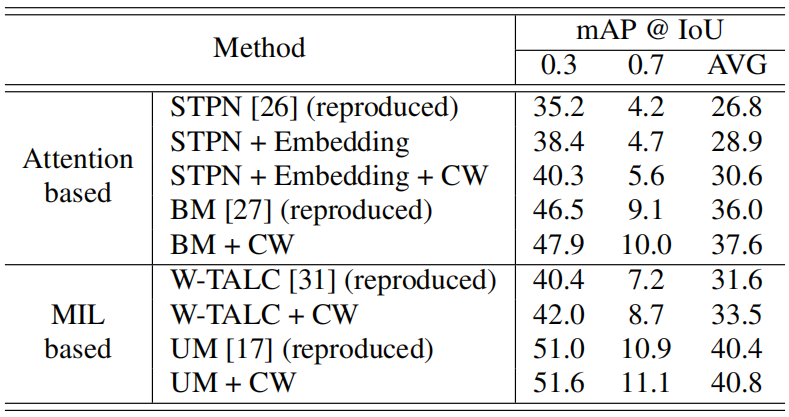
表5。评估CW分支机构的补充作用。注意,我们的方法需要学习面向任务的特性,这在STPN中是不可能的,因此我们展示了“STPN+嵌入”的结果,它表示STPN加上一个特征嵌入模块。
5.结论
我们提出了一种弱监督的动作定位方法,称为FAC-Net,它由三个分支组成。与现有的方法只考虑从前景到动作的单边关系不同,我们的方法考虑了动作和前景之间的双边关系。提出的基于类的前景分类分支引入了action-to-foreground关系,最大限度地实现了前景-背景分离。此外,还采用了class-agnostic注意力分支和多示例学习分支来调整前场动作的一致性,并学习有意义的前景特征。根据我们的实验,基于类的前景分类分支可以对现有方法起到补充作用,从而提高其性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号