Background-Click Supervision for Temporal Action Localization
0. 前言
摘要-弱监督时间动作定位的目的是从视频级标签中学习实例级动作模式,其中一个重大挑战是动作上下文混淆。为了克服这一挑战,最近的一项工作构建了一个行动点击监督框架。与传统的弱监督方法相比,它需要相似的标注代价,但可以稳定地提高定位性能。在本文中,通过揭示现有方法的性能瓶颈主要来自于背景错误,我们发现在背景视频帧上使用标签而不是在动作帧上使用标签可以训练出更强的动作定位器。为此,我们将动作点击监督转换为背景点击监督,并开发了一种新的方法,称为BackTAL。具体来说,BackTAL在背景视频帧上实现了两种建模,即位置建模和特征建模。在挖掘位置信息时,我们不仅在标注帧进行有监督的分类学习,也提出一个新颖的得分分离模块来增加动作帧和背景帧响应的差异性。在挖掘特征信息时,我们提出亲和力模块来衡量每帧和它邻近帧的相似性,以帮助每帧来动态地计算时序卷积,并获取更准确的动作模式。我们在三个基准数据集上进行实验,验证了所提方法具有更优异的时序动作定位性能,同时证明了背景单帧标注的合理性和有效性。代码在https://github.com/VividLe/BackTAL.
1 介绍
时序动作定位旨在通过预测相应的开始时间、结束时间和动作类别标签来发现动作实例[1]。这是一个具有挑战性但又实用的研究课题,对广泛的智能视频处理系统,如视频摘要[2],智能监督[3]具有潜在的好处。为了获得精确的定位性能,全监督的时间动作定位方法[4]、[5]、[6]、[7]从人类标注中学习。然而,数据标注过程繁重且昂贵;同时,很难保证不同标注者的动作边界是一致的。相比之下,弱监督方法[8]、[9]、[10]从视频级别的类别标签中学习,这些标签既便宜又方便获取。
本质上,大多数弱监督算法都遵循一个基本假设,即为视频级别分类提供更多置信度的视频片段更有可能是动作。然而,正如Shi等人[12]和Choe等人[13]指出的那样,当背景片段与视频级别分类更相关时,根据这一假设开发的算法将陷入动作-上下文混淆的困境。最近,SF Net[11]通过引入动作点击监督(动作点击监督在SFNet[11]中称为单帧监督。为了表示在每个动作实例中单击了一个时间戳,我们将这种监督称为“动作单击监督”。)来增强弱监督算法,如图1(a)所示。他们随机单击每个动作实例中的时间戳,并标注相应的类别标签。在这项工作中,马等人[11]表明,给定一分钟的视频,制作视频级、点击级和实例级标注分别需要45秒、50秒和300秒。具体来说,它需要在标注视频级别类别标签时观看整个视频。同样,标注动作点击监督需要观看整个视频,并在遇到动作片段时随机点击动作帧。因为点击信息是由标注工具自动生成的,所以动作点击监督的标注时间与视频级监督相似。然而,实例级标注需要来回滚动,以精确确定起始帧和结束帧,其标注成本会显著增加。由于对点击级监督进行标注的成本是可以承受的,同时,实验验证,点击级监督可以指示动作帧,并部分缓解动作上下文混淆的挑战,因此使用点击级标注的弱监督时间动作定位具有很好的研究前景。
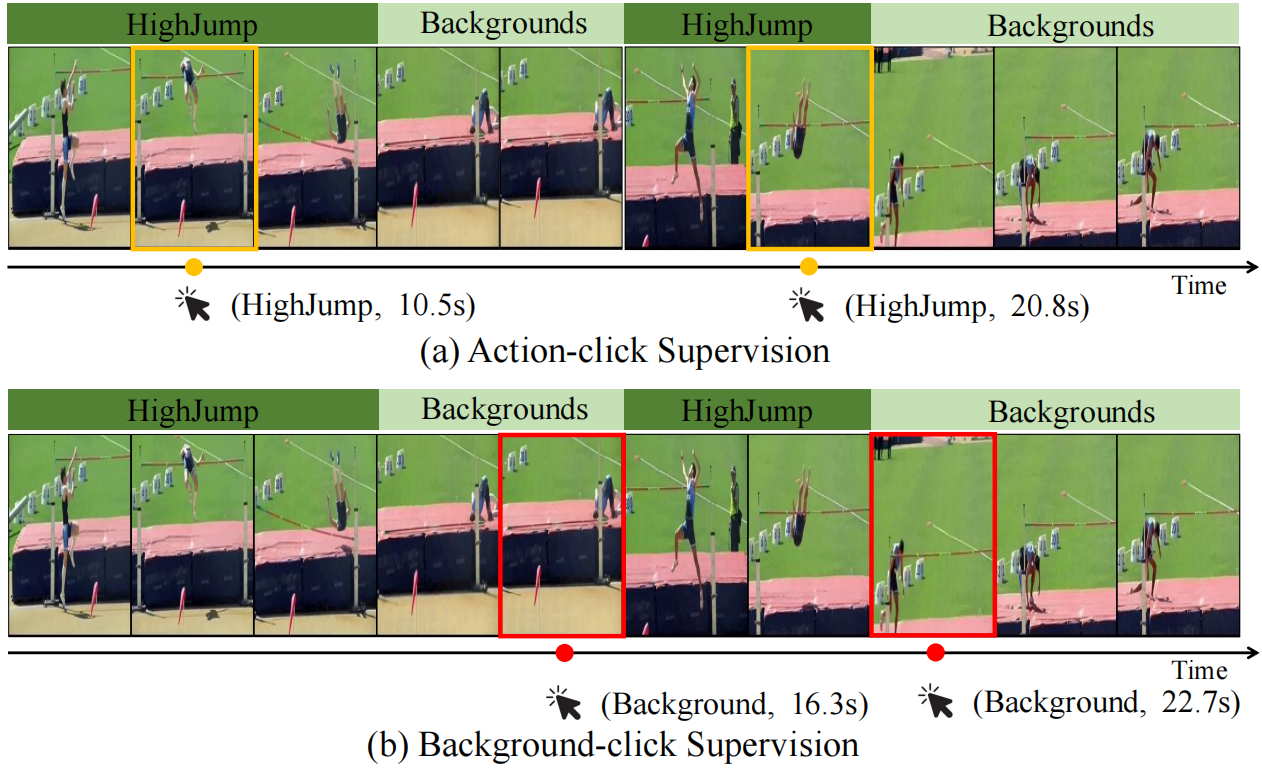
图1。单击级别监督的图示。ground-truth显示在帧序列上方。(a) action click supervision(以橙色显示)在每个action实例中随机单击,记录SF Net使用的时间戳和分类标签[11]。(b) 建议的背景点击监督(显示为红色)在每个背景段内进行随机点击,并记录时间戳。
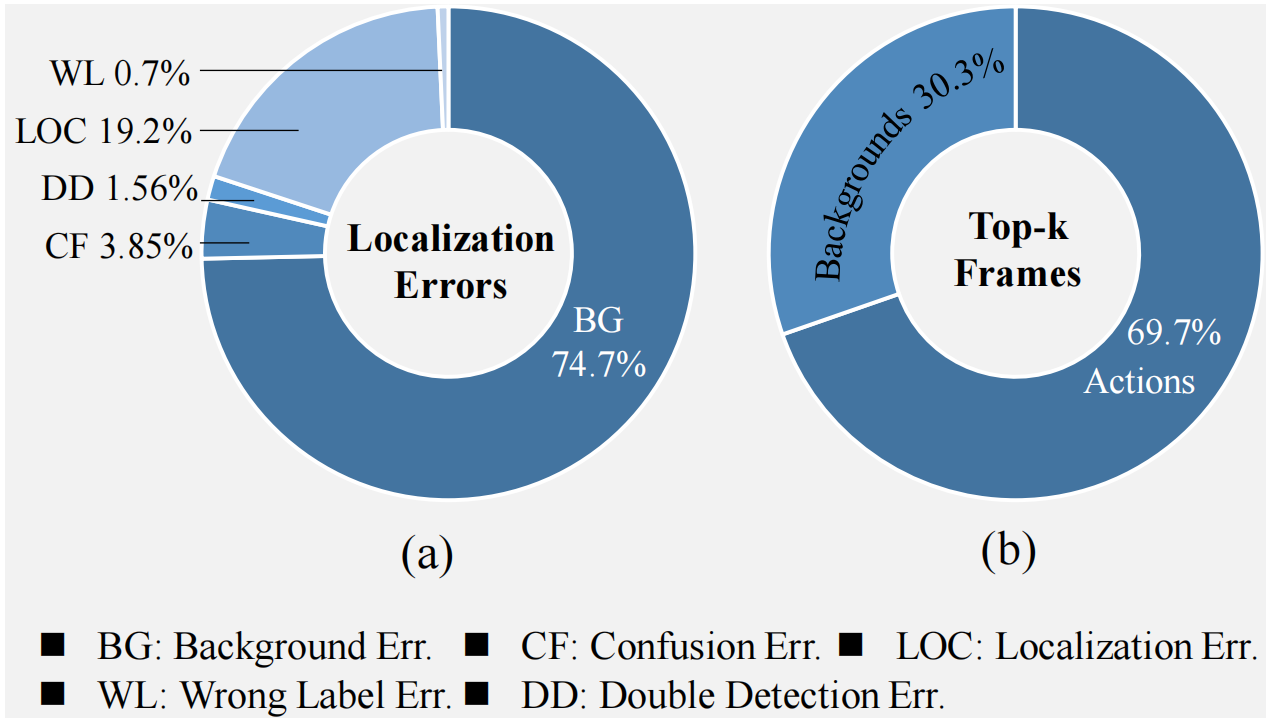
图2。一种针对弱监督动作定位的基线方法的性能分析。(a)从诊断结果中可以发现,大部分的错误来自于背景错误。(b)给定类激活序列,大多数top-k帧都属于动作段。
虽然SF-Net[11]通过探索动作点击监督来提高了定位性能,但对背景片段的点击级监督是否会表现得更好仍然值得怀疑。具体来说,除了视频级的分类标签外,我们还可以点击每个背景段中的一个帧(见图1(b))。为了研究这一点,我们采用之前的弱监督方法[14]、[15]、[16]、[17]实现了一个基线方法,并在THUMOS14上进行了两个实验。具体来说,我们将通过三个时序卷积层传播视频特征,并预测每一帧的分类分数。实验结果见图2。我们使用诊断工具[18]来进行误差分析。在五种类型的误差中,绝大多数的误差来自于背景误差,占74.7%,如图2(a)所示,相反,一部分动作帧可以通过top-k聚合过程来较为准确地确定。具体来说,给定每一帧的分类分数,现有的范式通常选择最高的k个分数,并将其平均值作为视频级的分类分数。因此,一个训练好的模型可以根据选择的top-k帧准确地发现可靠的动作帧。我们测量了最高的k个分数属于动作片段的比例,得到了69.7%,如图2(b)所示诊断结果和top-k帧的分布激励我们将动作点击监督转换为背景点击监督。
为了有效地学习动作定位模型,我们提出了一种新的背景点击监督下的学习框架,称为BackTAL,如图3所示。给定背景点击监督,利用标注信息的直接方法是通过对标注帧执行监督分类来挖掘位置信息,SF-Net[11]主要通过执行category-specific分类和category-agnostic分类来探索这一点。此外,考虑到常用的top-k聚合过程只约束最高的k个分数,而忽略了其他位置,我们设计了一个分数分离模块。该算法力求扩大潜在动作帧和标注背景帧之间的分数差,从而彻底挖掘位置信息,进一步提高定位性能。
除了位置信息外,点击级监督还可以指导构建特征嵌入空间的过程,将动作特征与背景特征分开。然而,以前的工作[11]忽略了这一特征信息。我们提出了一个亲和性模块来利用特征信息,实现时序卷积运算的动态精确计算。给定带标注的背景帧和置信度高的动作帧,亲和力模块通过要求所有动作嵌入紧凑,所有背景嵌入紧凑,同时动作嵌入与背景嵌入保持相当大的距离,努力学习每个帧的适当嵌入。然后,使用高质量嵌入来估计帧与其局部相邻帧之间的相似性,生成相似性掩码。借助于所提出的frame-specific的相似性掩码,卷积核可以在对每一帧进行计算时动态地关注相关的相邻帧,从而实现时序卷积的精确计算。
我们的贡献可以总结如下:
•我们提出对时序动作定位任务进行背景点击监督。与现有的动作点击监督相比,它可以有效地发现动作实例,但标注成本相似。
•在BackTAL中,我们提出了分数分离模块和亲和力模块,分别赋予位置信息和特征信息简单而有效的建模。
•在三个基准上进行了大量实验,BackTAL实现了新的高性能,例如36.3mAP@tIoU0.5在THUMOS14上。
本文的其余部分组织如下。第2节回顾了在完全监督和弱监督下时间动作定位的最新进展,以及点击级监督的发展。然后,第三节详细介绍了所提出的BackTAL,包括整体方法、分数分离模块和亲和性模块。之后,第4节展示了实验结果。具体来说,我们介绍了背景点击标注过程,在三个基准数据集上进行了对比实验,并进行了消融研究,以定量和定性的方式分析每个模块的有效性。最后,第5节得出结论并讨论了进一步的工作。
2 相关工作
本节总结了关于时间动作定位任务[1]、[19]、[20]的最新进展。我们从完全监督的方法开始,回顾了单阶段方法和两阶段方法。然后,我们讨论了仅从视频级别分类标签学习的弱监督方法。最后,我们讨论了一种增强的弱监督学习范式,即点击级监督。
全监督的时间动作定位方法从每一帧的精确标注中学习。现有的工作可以总结为one-stage方法[21]、[22]、[23]和two-stage方法[4]、[5]、[6]、[7]、[24]。对于前一种类型,Lin等人[21]同时预测动作边界和标签,这是GTAN[22]通过利用高斯核开发的。最近,Xu等人[23]利用一个图卷积网络来执行单阶段动作定位。相比之下,两阶段方法首先生成行动建议,然后对置信度高的建议进行细化和分类。具体来说,大多数建议都是由anchor机制[4]、[5]、[7]、[25]、[26]生成的。此外,生成建议的其他方法包括滑动窗口[27]、时间动作分组[28]、结合置信度高的开始帧和结束帧[24]、[29]。之后,MGG[30]将anchor机制和帧动作机制集成到一个统一的框架中,实现了建议生成任务的高查全率和精确性。与完全监督的方法不同,所研究的弱监督设置缺乏精确的示例级标注,使得区分动作与背景具有挑战性。
弱监督时间动作定位主要是挖掘视频级别的分类标签。UntrimmedNet[8]、STPN[9]和AutoLoc[31]的开创性工作构建了一个范例,通过设置类激活序列的阈值来定位动作实例。之后,视频级别的类别标签被彻底挖掘,例如,W-TALC[32]探索了共享同一标签的两个视频之间的共同活动相似性,这启发了Gong等人[33]挖掘共同注意力特征。此外,Liu等人[15]和Min等人[16]都证明,学习多个平行和互补分支有利于生成完整的动作实例,这是由学习混合注意权重以定位完整动作实例的HAM Net[34]开发的。此外,CleanNet[35]提出了一种伪监督范式,该范式首先生成伪行动建议,然后利用这些建议来训练行动建议网络。最近的一些工作进一步发展了伪监督范式,如TSCN[17]和EM-MIL[36]。此外,BaS Net[14]设计了一个背景抑制网络,由Moniruzzaman等人[37]通过进一步建模动作完整性开发。类似地,Nguyen等人[10]指出,对背景建模至关重要。[12]和[38]将其总结为动作上下文混淆挑战。最近,Lee等人[19]研究了框架的不一致性,并将背景框架建模为分布外样本。同时,Liu等人[39],[40]的目标是通过使用正分量和负分量[39]或学习显式子空间[40]来分离动作框架和相邻的上下文框架。
然而,仅仅使用视频级别的标签远远不能解决动作上下文混淆的问题。相比之下,引入额外信息可能是更有效的解决方案。例如,CMCS[15]收集固定的视频片段作为背景。此外,3C Net[41]引入了动作计数提示。Nguyen等人[10]使用微视频。最近,ActionBytes[42]从修剪过的视频中学习,并在未修剪的视频中对动作进行定位。
点击级监督是一种弱监督学习范式。正如Bilen[43]所指出的,弱监督学习指的是一种算法,它在训练阶段需要的标注比推理阶段的期望输出更便宜。例如,从点击监督到像素级语义遮罩[44],从帧点到时空动作框[45],从涂鸦到像素级分割遮罩[46]和显著性贴图[47]。最近,Moltisanti等人[48]利用模拟动作点击监督来学习视频识别模型。
与最相关的工作SF Net[11]相比,我们提出的BackTAL展示了两个不同的贡献。(1) 虽然SF-Net使用了动作点击标注,但我们发现学习算法可以较精确地发现动作帧,而性能瓶颈在于背景错误。因此,我们将action click标注转换为backgroundclick标注。(2) 在点击级标注的情况下,SF-Net主要通过有监督分类在标注的帧上挖掘位置信息,我们在此基础上还通过分数分离模块和亲和力模块联合挖掘位置信息和特征信息。
提出的亲和力模块与嵌入学习相关[49]、[50]、[51]。具体来说,PiCANet[50]直接学习相邻像素之间的亲和力,而BackTAL学习每帧的嵌入,然后测量亲和力。此外,现有方法[49]、[50]、[51]在完全监督的环境下学习嵌入,而BackTAL则从背景点击标注中学习。
除了上面讨论的时间动作定位工作之外,还有一项类似的任务——时间动作分割,该任务最近取得了很好的进展。例如,MS-TCN++[52]利用多阶段架构来处理时间动作段任务。Kuehne等人[53]从包含动作顺序信息的视频中学习动作分类器,并将基于帧的RNN模型与隐马尔可夫模型相结合来分割视频。此外,一些著作[54]、[55]、[56]研究了时空动作检测,它通过每个时间帧内的空间框来检测动作实例。
3 方法
在这一部分中,我们详细介绍了所提出的BackTAL方法,以解决背景点击监督下的弱监督时间动作定位问题。首先,第3.1节正式定义了所研究的问题。然后,在第3.2节中,我们对传统的视频级别分类损失和帧级别分类损失进行了全面概述,以挖掘位置信息。在背景点击监督下,BackTAL同时挖掘位置信息和特征信息。前者见第3.3节,后者见第3.4节。之后,第3.5节介绍了评估过程。
3.1 问题陈述
所提出的BackTAL通过学习视频级的分类标签和背景点击标注来处理未修剪的视频。给定一个视频,我们将背景点击标签表示为b=[b1,b2,...,bT]。在人工标注过程之前,所有帧的背景点击标签均为bt=−1,t=1,...,T,表示不确定每一帧是属于动作还是属于背景。在标注过程中,标注器会浏览所有的视频帧。一旦标注器遇到一系列连续的背景帧,他/她就会随机选择一个帧并进行背景点击标注,即将相应的背景点击标签标记为bt=1.(有关详细的标注过程,请参见第4.2小节背景点击标注。),在训练期间,该算法选择最高k个分数来估计视频级分类分数,这被称为top-k聚合过程。我们将选择的k个帧视为置信度高的动作帧,并将相应的标签标记为bt=0,然后得到伪标签![]() 。BackTAL从训练视频中学习,并旨在精确地发现测试视频中的动作实例,例如,(tsi,tei,ci,pi)。具体来说,第i个动作实例从tsi开始,在tei结束,属于第c类,这个预测的置信度分数是pi。
。BackTAL从训练视频中学习,并旨在精确地发现测试视频中的动作实例,例如,(tsi,tei,ci,pi)。具体来说,第i个动作实例从tsi开始,在tei结束,属于第c类,这个预测的置信度分数是pi。
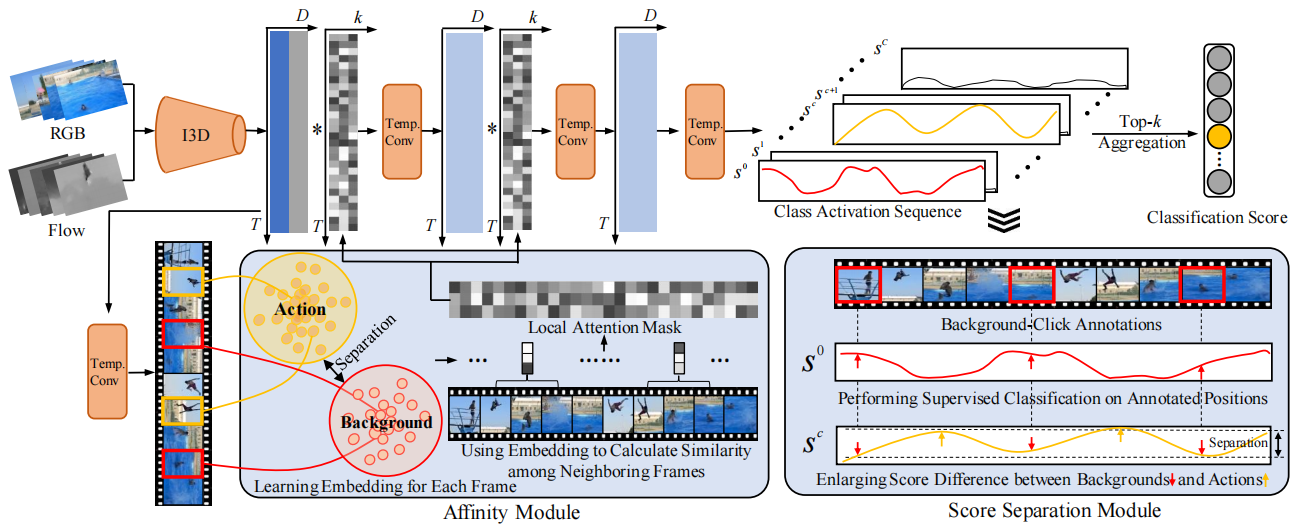
图3.提出的BackTAL框架。BackTAL首先提取视频特征,然后使用3个时序卷积层对每一帧进行分类,得到类激活序列。最后,执行top-k聚合,并预测视频级分类分数。在背景点击监督下,BackTAL采用亲和力模块(见3.4节)挖掘特征信息,估计局部注意力掩码。这有助于计算frame-specific的时序卷积。此外,BackTAL还探索了分数分离模块(见第3.3节),并挖掘了位置信息。这可以扩大动作帧和背景帧之间的响应差距
3.2 BackTAL概述
BackTAL的框架如图3所示。BackTAL采用三个时序卷积层来处理视频特征序列,对每一帧进行分类,并生成类激活序列。对于带有特征X的输入视频,对应的类激活序列为S∈R(C+1)×T。然后,我们利用top-k聚合策略来计算视频级分类得分scv:
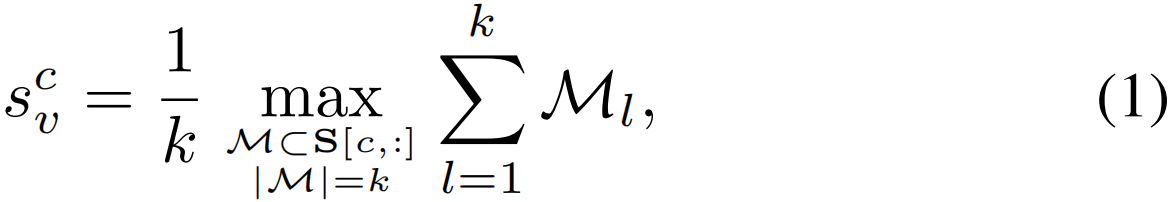
其中scv是第c类的分类分数(所选的最高k分数的时间位置可以表示为一个集合k={k1,k2,...,kk},(ki∈{1,2,...,T}),其中对应的伪帧级标签满足![]() =0,t∈K。)。
=0,t∈K。)。
给定视频级分类评分sv=[s0v,s1v,...,sCv]和分类标签y,可以通过交叉熵损失计算出视频级分类损失Lcls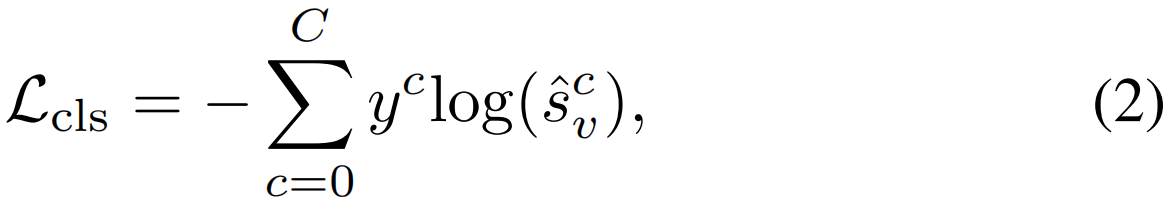
其中,![]() 为softmax归一化后的分类得分。
为softmax归一化后的分类得分。
除了视频级分类外,我们还对标注的背景帧进行有监督分类,以提高类激活序列S的质量。特别地,考虑一个带有标签bt=1的带标注帧,该帧的分类分数是S[:,t]∈R(C+1)×1。我们首先执行softmax归一化,并获得帧级分类分数![]() 。然后,通过交叉熵损失计算帧级分类损失Lframe:
。然后,通过交叉熵损失计算帧级分类损失Lframe:
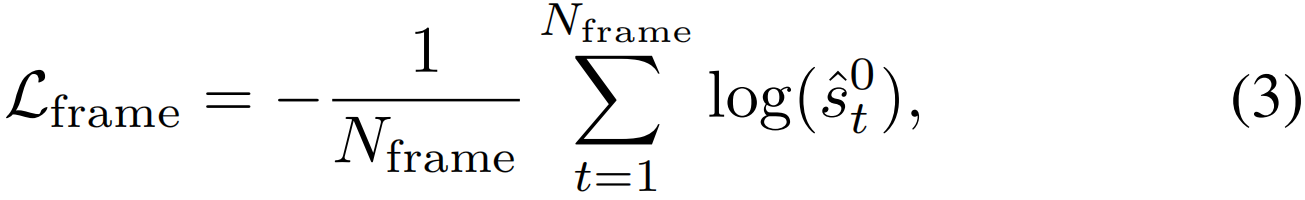
其中,Nframe为本视频中带标注的背景帧数,![]() 为背景类的分类分数。
为背景类的分类分数。
在训练过程中,对背景帧进行标注,类激活序列的最高k个分数可视为置信度高的动作帧。在分数分离模块中(见第3.3节),我们的目标是通过分离损失Lsep来分离置信度高的动作框架和带标注的背景框架之间的响应分数。在亲和力模块中(见第3.4节),我们通过亲和损失Laff学习对每一帧的嵌入,并使用嵌入向量来测量相邻帧之间的相似性。
完整的学习过程由视频级分类损失Lcls,帧级分类损失Lframe、分离损失Lsep和亲和损失Laff共同驱动。总损失可计算为:
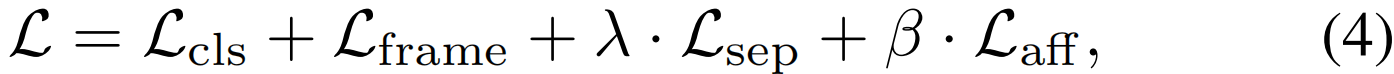
其中λ和β是权衡系数。
3.3 分数分离模块
本节从传统的弱监督动作定位范式开始,揭示了top-k聚合过程不能明确地影响混淆帧。然后,我们提出了分数分离模块,以利用点击级别标注中的位置信息,生成高质量的分类响应。
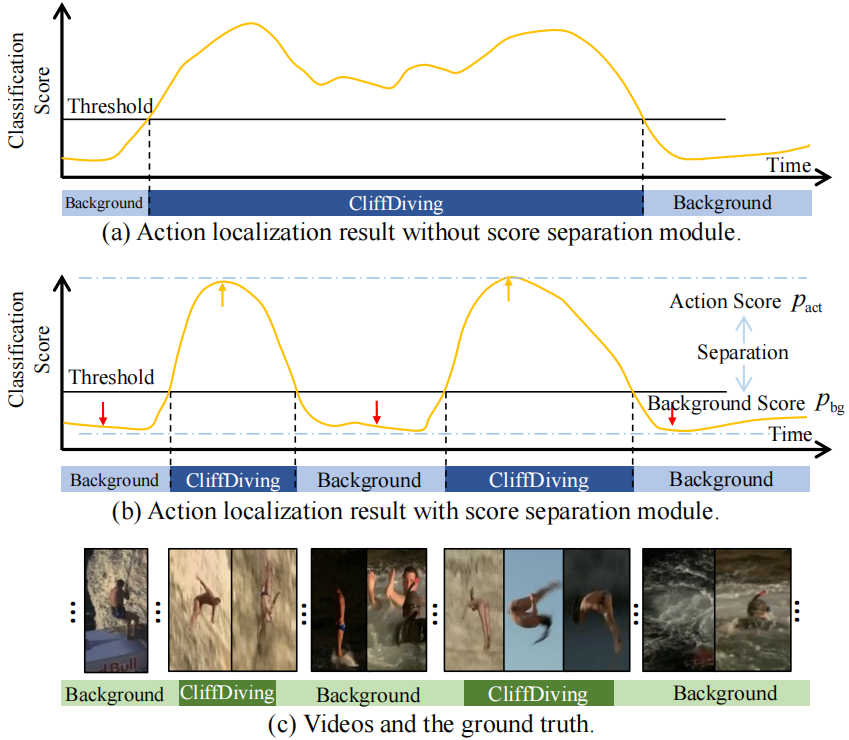
图4。(a)未使用分数分离模块,(b)使用了分数分离模块。我们可以发现,分数分离模块有助于抑制背景帧的响应,增强动作帧的响应,这有利于分离相邻动作实例。
在弱监督的动作定位范式中,top-k聚合过程依赖于k个最高的分数来预测视频级的分类分数。在每次训练迭代中,只有被选择的k个分数受到影响和优化,而其他的分数将被忽略。虽然前k位置在早期训练阶段有所不同,但一个成熟的模型在后期训练阶段会稳步选择相似的前k位置。因此,如图4(a)所示,预测的分类分数置信度高地显示了对动作帧的高响应,但谨慎地显示了对背景帧的低响应。只要这些混淆帧的分数低于top-k分数,它们就不会影响视频级别的分类分数。因此,动作帧和混淆的背景帧的响应不能明显分离,导致对后续基于阈值的时间动作定位过程的预测不精确。
为了分离动作和背景的响应,SF-Net[11]进行动作单击标注,并执行帧级监督分类。还有其他类似的选择,如执行二元分类来学习行动性[11],以及对注意力权重[14]进行监督。然而,根据我们的调查(见4.4节),执行帧级监督分类的多种变体倾向于获得同质信息,即使多种方法叠加也无法获得累加式性能提升。本质上,帧级交叉熵损失可以鼓励背景类的响应高于其他类的响应,这隐含地抑制了所有动作类的响应。然而,考虑到一个包含来自第c类动作的视频,背景帧的交叉熵损失不能明确地强制第c类的响应在背景帧上的响应尽可能低,例如,低于所有其他动作类的响应。
在这项工作中,我们通过使用分数分离模块明确限制背景位置的响应,如图4(b)所示。特别是,给定一个包含第c类动作的视频,我们将最高的k个分数视为潜在的动作,并通过以下方式计算平均分数pact:
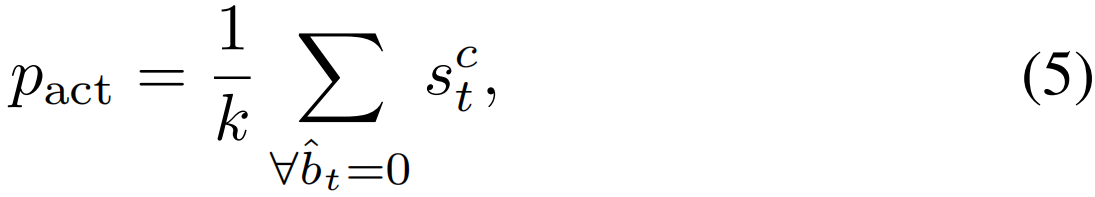
其中,![]() =0表示top-k个动作帧,其总数为k。类似地,给定Nframe标注的背景帧,平均分数pbg被定义为:
=0表示top-k个动作帧,其总数为k。类似地,给定Nframe标注的背景帧,平均分数pbg被定义为: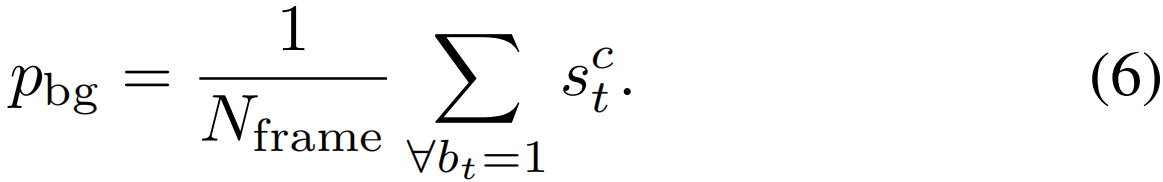
为了扩大平均行动得分pact和平均背景得分pbg之间的相对差异,我们对pact和pbg进行了Softmax归一化,如下:
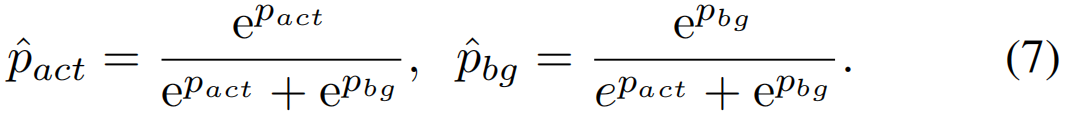
然后,我们引导![]() 为1,而
为1,而![]() 为0,如下所述:
为0,如下所述:
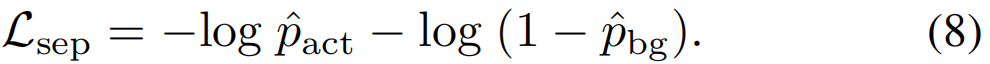
分数分离损失Lsep可以指导动作反应与第c类上的背景反应分离
3.4 亲和力模块
亲和力模块旨在探索背景点击监督中的特征信息。基于带标注的背景帧和伪动作帧,我们学习输入视频的嵌入空间。然后,考虑一帧,我们可以测量其与相邻帧的亲和力,并获得frame-specific的注意权重,即局部注意掩码,该权重被注入到卷积计算过程中。frame-specific的注意权重可以引导卷积过程动态关注相关邻居,从而产生更精确的响应。
在亲和力模块中,我们首先学习一个嵌入空间来区分不可知类的行为。给定输入特征,我们使用时序卷积层来学习每一帧的嵌入,即E=[e1,e2,...,eT],其中eT∈RDemb是一个Demb维向量。每个嵌入向量都是L2−归一化的。具体来说,我们使用余弦相似度来衡量两个嵌入eu和ev之间的亲和性: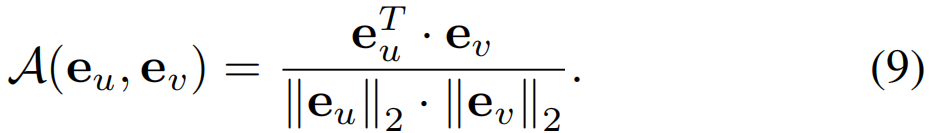
基于带标注的背景帧和潜在动作帧,我们可以从三个项计算亲和力损失Laff,即两个背景帧之间、两个动作帧之间和动作背景对之间。特别是,我们使用在线硬示例挖掘策略[57]来约束训练帧对。对于第一项,两个背景帧的嵌入向量应该彼此相似,并且损失Lbgaff可以表示为:
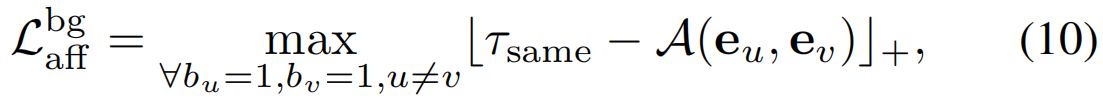
式中,![]() 表示丢弃低于0的值,τsame为同一类别帧之间的相似性阈值。具体来说,我们限制两个最不相似的背景帧之间的相似性应大于τsame,同样地,动作帧的嵌入向量也应该彼此相似:
表示丢弃低于0的值,τsame为同一类别帧之间的相似性阈值。具体来说,我们限制两个最不相似的背景帧之间的相似性应大于τsame,同样地,动作帧的嵌入向量也应该彼此相似:

图5。局部相似掩码的可视化。给定一个包含推铅球动作的视频,我们选择一个动作帧(以橙色显示),并计算所选帧与其本地邻居之间的相似性。生成的局部相似性模板对动作帧的响应较高,对背景帧的响应较低。
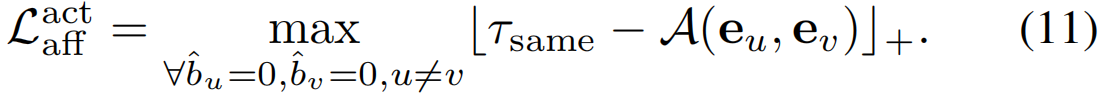
与Lbgaff和Lactaff相比,背景帧的嵌入向量应该不同于动作帧的嵌入向量。这可以表述为: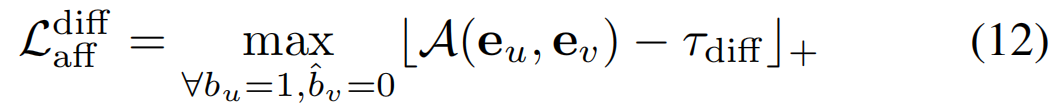
其中,τdiff是约束动作和背景之间相似性的阈值。亲和性损失综合考虑上述三项,可计算为: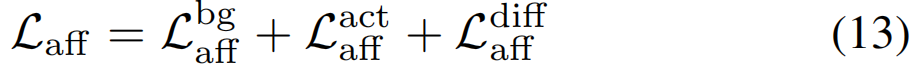
当获得高质量的嵌入向量时,我们可以测量帧与其局部邻居之间的余弦相似性。如图5(因为有些视频是从遥远的角度拍摄的,所以在原始视频帧中拍摄的动作会很小,难以识别。我们遵循之前的作品[12],[58]来展示正在经历的动作。)所示,嵌入向量可以区分动作帧和背景帧,并且在给定参考帧时均匀地高亮显示同质帧。
考虑一个视频特征X∈RDin×T的维度是Din和时间长度是T,时序卷积动作学习卷积内核H∈Rh×Din×Dout处理视频特征X,h是卷积核的大小,Dout是输出特征的维度。为简单起见,我们只考虑输出特征的第m个通道,并使用卷积核Hm∈Rh×Din。然后,对第t个特征的普通时序卷积运算可以表述为:
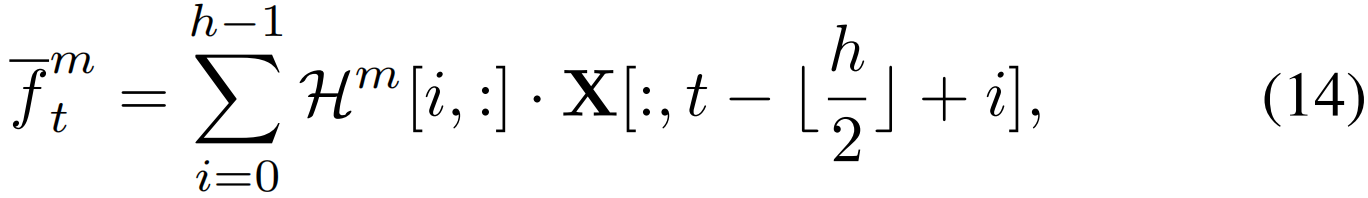
其中,[·]表示从矩阵中索引数据,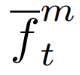 为输出特征向量的第m个通道中的值,(·)表示内积,
为输出特征向量的第m个通道中的值,(·)表示内积,![]() 表示四舍五入。
表示四舍五入。
给定一个视频,我们计算每个时间位置的局部相似度,并得到亲和矩阵a∈Rh×T,其中a[:, t]表示第t个特征向量与其h个邻居之间的亲和关系。与普通卷积相比,在执行时序卷积之前,我们使用亲和权值来调制第t个位置的相邻特征:
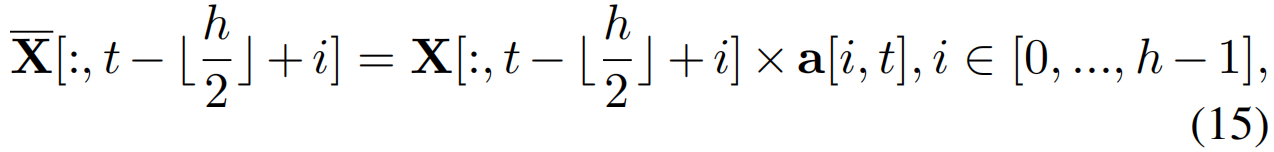
其中,![]() 是被调制的特征。然后,我们在第t个位置进行时序卷积:
是被调制的特征。然后,我们在第t个位置进行时序卷积:
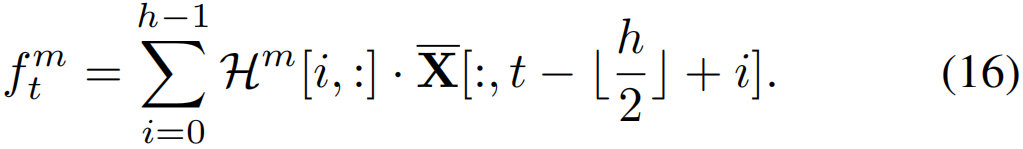
在传统方法中,所有时间帧都是通过共享卷积核来处理的。相反,frame-specific的关联权重引导卷积进行frame-specific的计算。基于背景帧和潜在动作帧,亲和性模块充分挖掘特征信息。亲和力权重和frame-specific的时序卷积有助于区分动作和混淆的背景,这有助于分离两个紧密相邻的动作。尽管亲和性模块包含三个损失项(即Lbgaff,Lactaff和Ldiffaff),但每个项都可以通过基于矩阵乘法的相似性度量进行有效计算。
3.5 推论
在推理中,我们通过学习到的网络提出一个测试视频,得到类激活序列s。然后,top-k聚合程序预测视频级分类分数sv。在C个候选类别中,我们丢弃了视频级分类得分低于阈值τcls的类别。接下来,我们选取置信度高类别的类激活序列,将得分较高的连续帧作为动作实例,获得起始时间tsi和结束时间tei。然后,通过外部-内部对比策略[31]确定该预测动作实例的置信度得分pi。
4 实验
在这一部分中,我们进行实验来评估和分析所提出的BackTAL方法。我们从第4.1节中的实验装置开始。然后,第4.2节介绍了背景点击信息的标注过程。接下来,我们在三个基准数据集上比较了BackTAL和最近开始的art方法,并在第4.3节中验证了BackTAL的优越性能。随后,第4.4节进行了消融研究,分析了背景点击监督的优越性、每个模块的有效性,并研究了参数的影响。此外,我们在第4.5节中描述了定性分析。
4.1 实验装置
基准数据集。我们在三个基准上评估了BackTAL的功效,包括THUMOS14[59],ActivityNet v1.2[60]和HACS[61]。在THUMOS14中,训练集由2765个修剪视频组成,而验证集和测试集分别由200和213个未修剪视频组成。作为文献[8]、[9]、[14]中的常见做法,我们在训练阶段使用验证集,并在测试集上评估性能,其中视频来自20个类。THUMOS14的主要挑战是动作实例持续时间的巨大变化。具体来说,短动作实例只能持续十分之一秒,而长动作实例可以持续数百秒[4]、[5]、[7]。ActivityNetv1.2[60]包括来自100个类的9682个视频,这些视频按2:1:1的比例分为训练、验证和测试子集。ActivityNet v1.2中的挑战。通常涉及许多动作类别、大的类内变化等。除了这两个常用的数据集,我们注意到最近提出的数据集HACS[61]。它包含跨越200个类的5万个视频,其中训练集、验证集和测试集分别由3.8万、6千和6千个视频组成。与现有基准相比,HACS包含大规模视频和动作实例,是一个更现实、更具挑战性的基准。此外,我们遵循SFNet[11],并在BEOID数据集[62]上评估BackTAL的性能。BEOID由来自34个动作类别的58个视频、742个动作实例组成。我们在BEOID数据集上为视频制作背景点击标注。
评估指标。使用不同阈值[59]、[60]下的平均精度(mAP)来评估性能。在THUMOS14上,我们在阈值tIoU={0.3,0.4,0.5,0.6,0.7}下报告mAP,并遵循之前的工作[35]、[36]、[63]重点关注mAP@tIoU0.5.此外,考虑到一些方法可能在低或高tIoU阈值上表现出优势,我们报告了阈值tIoU={0.3,0.4,0.5,0.6,0.7}下的平均mAP,以进行整体比较,正如Liu等人[15]所尝试的那样。ActivityNet和HACS的评估采用了十个均匀分布阈值下的平均mAP,从tIoU=0.5到tIoU=0.95,即[0.5:0.05:0.95]。在BEOID[62]上,我们按照SFNet[11]报告阈值[0.1:0.1:0.7]下的mAP以及这七个映射的平均值。
基线方法。我们遵循BaS-Net[14]最近的一项工作来构建我们的基线方法,主要考虑到它的简单性。该网络利用三个时序卷积层对视频帧进行分类并生成类激活序列。对于每一个视频,这个网络会被使用两次。第一次处理基本视频特征,第二次处理过滤后的视频特征。在度量映射(%)@tIoU0下,我们对BaS Net的正式实现进行了一次简化,并将性能从27.0提高到28.6。5.具体而言,BaS Net[14]通过随机选择视频的一部分来执行数据扩充,但我们将视频特征缩放到固定的时间长度,并通过线性插值使用完整的特征,如下[22],[24]。改进的一个潜在原因是,选择视频的一部分会面临一定的风险,可能会丢失一些动作实例或将一个完整的动作实例切割成一个部分,这可能会混淆学习算法。
实施细节。继之前的作品[9]、[12]、[15] 之后,我们使用在Kinetics-400[64]数据集上预先训练的I3D[64]模型来提取RGB和光流特征。对于缩放特征序列,THUMOS14,ActivityNet v1.2和HACS的时间长度T为分别为750、100和200。top-k聚合过程选择每个数据集上的![]() 个最高分数,其中
个最高分数,其中![]() 的意思是向下取整。
的意思是向下取整。
所提出的BackTAL在PyTorch1.5[65]上实现,并通过Adam算法进行了优化。我们使用batch大小16,学习率1×10−4和权重衰减5×10−4。我们分别对THUMOS14、ActivityNetv1.2和HACS分别训练了100、25和8个epoch。我们将嵌入维数设置为RDemb=32。为了进行公平的比较,我们遵循BaS-Net[14]来设置超参数。具体来说,我们采用了与BaSNet相同的推理范式,并设置了τcls=0.25。我们采用网格搜索策略来根据经验确定超参数的适当值。具体地说,平衡系数设置为λ=1,β=0.8。在亲和损失方面,我们设置为τsame=0.5,τdiff=0.1。在第4.4节中,通过消融实验讨论了这些超参数的影响。

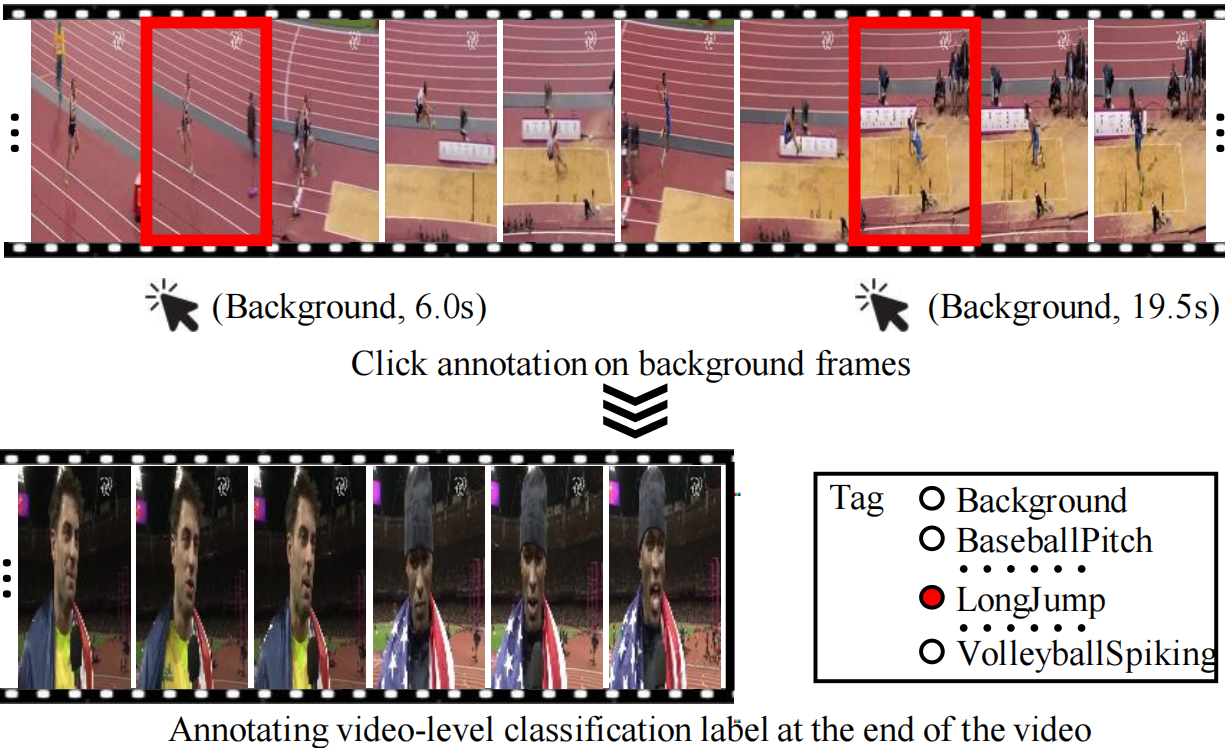
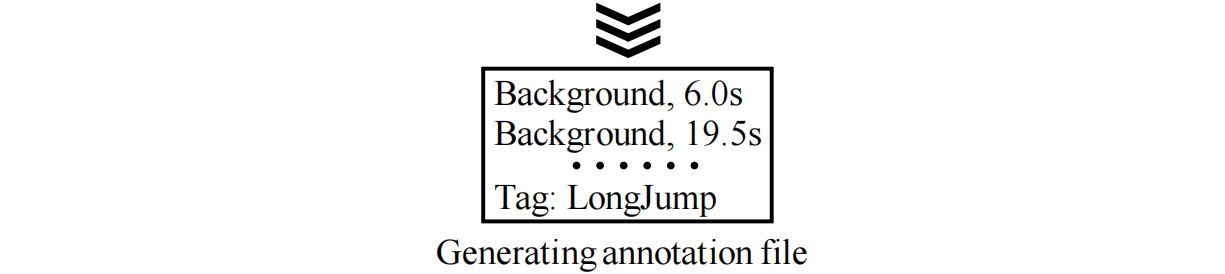
图6。标注背景点击信息的过程,以包含跳远动作的视频为例。首先,我们使用2fps稀疏地从视频中提取帧。然后,当遇到背景片段时,标注器随机单击一个帧并将其标注为背景。之后,视频级别分类标签被记录在视频的末尾。最后,可以为完整的视频生成标注文件。
4.2 背景点击标注
在进行实验之前,我们在THUMOS14上做了背景点击标注[59]。首先,我们训练三名标注员,让他们掌握一些动作和背景,以熟悉每个动作类别。然后,标注者被要求在看到新的背景片段后随机标注背景帧。使用Tang等人[66]提供的标注工具,标注者可以快速浏览动作框架并进行高效标注。图6展示了详细的标注过程。具体来说,由于稀疏提取可以减少帧数并加快标注过程,我们以2fps的帧速率提取帧。在视频中,我们单击背景帧,只在视频末尾记录视频级别分类标签。因此,标注过程是高效的。平均来说,为一分钟的视频添加标注需要48秒。(此外,我们还探讨了为一分钟视频同时标注动作点击和背景点击的成本,并在稀疏帧提取后花费了53秒。)
我们统计了背景点击标注相对于相应背景片段的相对位置。
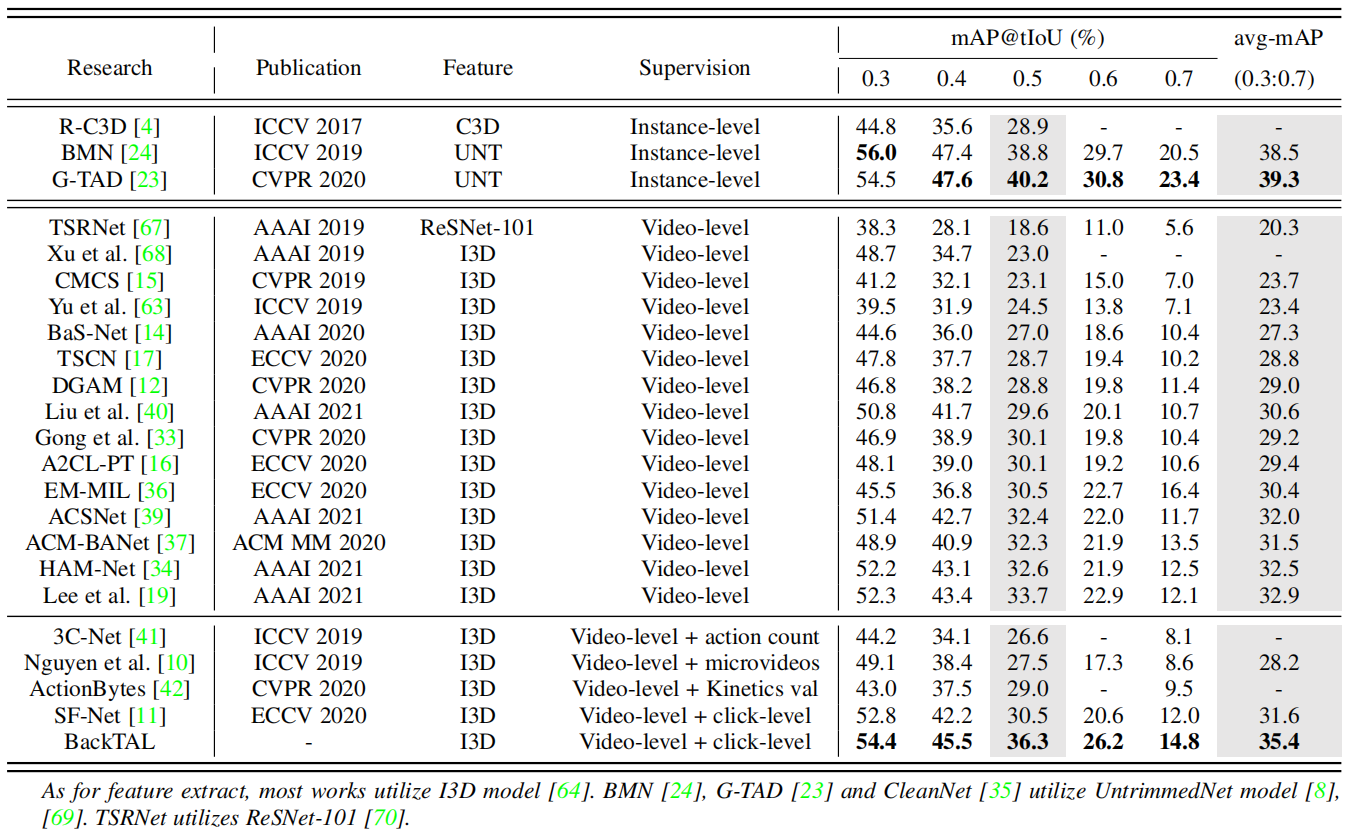
表1在THUMOS14数据集上的比较实验。我们将BackTAL与三种完全监督的方法(实例级监督)、最近的弱监督的方法(视频级监督)和具有额外信息的弱监督的方法(视频级+∗)进行了比较。
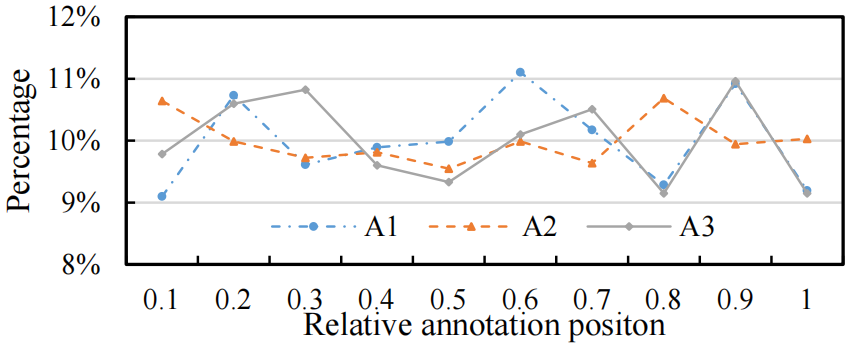
图7。THUMOS14数据集的背景点击标注统计。x轴表示每个标注的相对位置,而y轴表示标注帧的百分比。我们可以发现背景点击标注大致呈现均匀分布。“A1”、“A2”和“A3”表示三种不同的标注者。
考虑到一个背景段从tbs开始,到tbe结束,对于一个带有时间戳tb的背景点击标注,相对位置可通过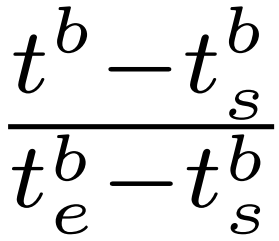 计算得出。如图所示7。三个标注者的标注位置大致呈现均匀分布。均匀分布的潜在原因包括:首先,标注器随机单击背景段内的背景帧。此外,由于背景帧易于识别,标注器几乎不会出错。在THUMOS14上的实验中,BackTAL的性能是采用三种不同标注的三次试验的平均值。在THUMOS14上,SF Net[11]观察到人类标注和模拟标注之间的相似性能。因为ActivityNet v1.2包含比THUMOS14多出几十倍的视频,SF Net[11]采用模拟策略,即根据ground-truth在每个动作实例中随机标注一帧。在本文中,我们遵循SF Net,并在大规模数据集ActivityNet v1.2[60]和HACS[61]上使用模拟标注。
计算得出。如图所示7。三个标注者的标注位置大致呈现均匀分布。均匀分布的潜在原因包括:首先,标注器随机单击背景段内的背景帧。此外,由于背景帧易于识别,标注器几乎不会出错。在THUMOS14上的实验中,BackTAL的性能是采用三种不同标注的三次试验的平均值。在THUMOS14上,SF Net[11]观察到人类标注和模拟标注之间的相似性能。因为ActivityNet v1.2包含比THUMOS14多出几十倍的视频,SF Net[11]采用模拟策略,即根据ground-truth在每个动作实例中随机标注一帧。在本文中,我们遵循SF Net,并在大规模数据集ActivityNet v1.2[60]和HACS[61]上使用模拟标注。
4.3 与最新方法的比较
THUMOS14。表1比较了BackTAL和THUMOS14数据集上最新的方法。由于本文侧重于弱监督的时间动作定位,我们只列出了三种有代表性的监督方法[4]、[23]、[24],以说明在监督范式下的进展。对于弱监督范式,我们将仅使用视频级别分类标签的方法与使用额外信息的方法区分开来。在表1中,与拟议的BackTAL最相似的竞争对手是SF Net[11],其中SF Net采用动作点击监督,BackTAL采用背景点击监督。在相同的标注成本下,在tIoU阈值0.5下,BackTAL比SF Net表现出5.8的映射改进,表明背景点击监督更有效。此外,随着弱监督方法的快速发展,最近的一些工作[19]、[34]、[37]、[39]取得了比使用额外信息的弱监督方法更好的性能。然而,在tIoU阈值为0.5的情况下,建议的BackTAL执行的mAP比当前执行良好的方法[19]高2.6。此外,与监督方法相比,BackTAL可以超过经典方法[4],但与最近的监督方法相比仍存在明显的性能差距。这表明弱监督方法应该持续发展。
ActivityNetv1.2. 表2报告了在ActivityNetv1.2基准测试上的BackTAL和当前最新方法的性能。ActivityNetv1.2与THUMOS14具有不同的特征,例如,很大一部分动作实例在一个动作实例中是非常长的、戏剧性的变化。之前的对应的SF-Net[11]主要对动作点击标注帧执行监督分类,它可以有效地学习相邻帧内的相似模式,但不足以在长距离间隔内传播信息,结果表明,SF-Net的性能弱于一些弱监督方法[19]、[34]、[39]、[40]。相比之下,所提出的BackTAL将有价值的点击级监督转换为背景片段,并通过视频层分类过程,即顶部聚合过程,发现动作实例。如表2所示,在度量平均mAP下,BackTAL的性能优于最近的弱监督方法。在10个不同的阈值下,BackTAL在9个阈值上获得了较高的性能。由于tIoU阈值0.95是一个严格的标准,一个潜在的原因是在整体数据集的性能和某些动作实例的精确边界定位之间存在权衡。BackTAL专注于整体性能,并实现了较高的平均mAP。
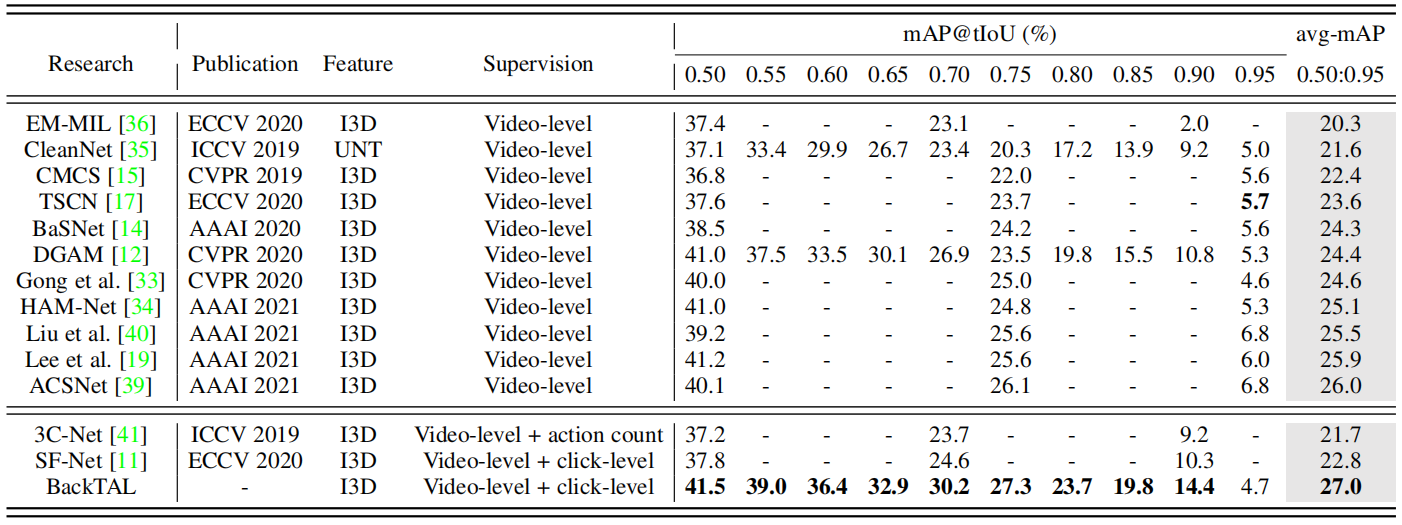
表2在ActivityNetv1.2数据集上的比较实验。我们比较了BackTAL与最近的弱监督方法(视频级监督)和带有额外信息的弱监督方法(视频级+∗)。

表3在HACS数据集上的比较实验,与全监督SSN[28]和弱监督BaS-Net[14]进行了比较。
HACS。除了两个传统的基准测试外,我们还进行了早期尝试,并验证了在大规模HACS数据集上进行弱监督时间动作定位的有效性,如表3所示。SSN[28]是一种经典的全监督时间动作定位方法。它采用金字塔结构对动作结构进行建模,并使用活动分类器和完整性分类器分别预测动作类别和完整性评分。作为一种弱监督方法,BaS-Net[14]在度量平均mAP下的性能低于SSN。相比之下,所提出的BackTAL超过了SSN,超过10个不同的tIoU阈值和平均mAP,且不超过9个。考虑到HACS[61]是一个大规模的真实数据集,本实验揭示了背景点击监督的广阔前景
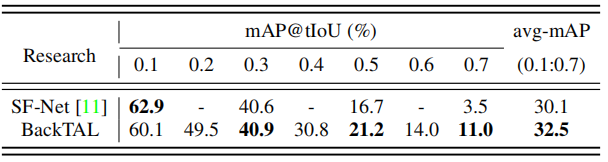
表4在不同tIoU阈值下,通过mAP测量的BEOID数据集上的比较实验。
BEOID。表4报告了SF Net[11]和拟议BackTAL之间的性能比较。SF Net利用动作点击监督,实现30.1mAP,低于公制平均mAP。BackTAL采用背景点击监督,实现了32.5mAP,并展示了SF Net上2.4mAP的改进。在表4中,可以注意到SF Net在低tIoU阈值(例如0.1)下表现良好。一个潜在原因是动作点击监督有助于发现动作实例,但只能生成粗略的时间边界。总的来说,BackTAL在其他tIoU阈值和平均mAP下表现良好,这证明了所提出的背景点击监督的有效性。
进一步讨论。在标注成本和性能增益之间可能存在一个权衡问题。如图8所示,我们将提出的BackTAL与最近的工作进行了比较。可以发现,背景点击监督需要与传统弱监督方法类似的标注成本(48s v.s.45s),但可以稳定地将性能从33.7 mAP(Lee等人[19]报告)提高到36.3 mAP。此外,基于一项开创性的工作[44]和提出的BackTAL,我们分析了点击级监督在语义分割领域和动作定位领域的有效性。如表5所示,与相应的最先进的方法[71]相比,Bearman等人[44]需要17.9%的额外标注成本,并做出10.1%的相对改进。相比之下,BackTAL实现了12.4%的相对改进,而额外的标注成本为6.7%。通过以上分析,我们可以发现所提出的BackTAL方法的有效性,尤其是标注成本和性能增益之间的良好权衡。(继Bearman等人[44]之后,我们将其与前一年出版的最新作品[37]进行比较。)
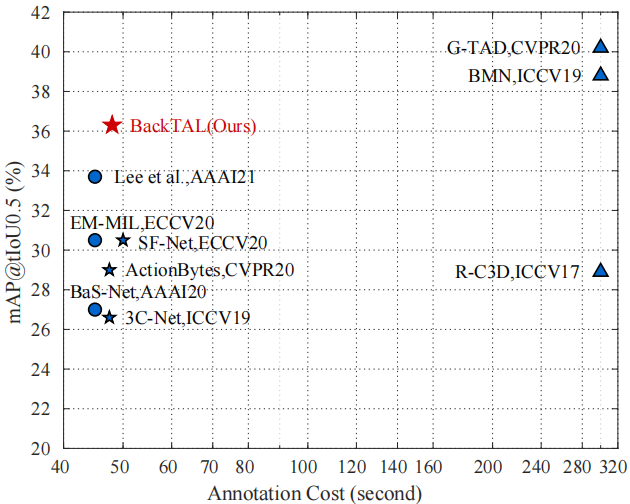
图8。在THUMOS14数据集上,在标注成本和动作定位性能之间进行权衡。我们将BackTAL与最近采用弱监督、附加信息弱监督和全监督的方法进行了比较。弱监督方法[11]、[14]、[19]和完全监督方法[4]、[23]、[24]的标注成本取自[11]。
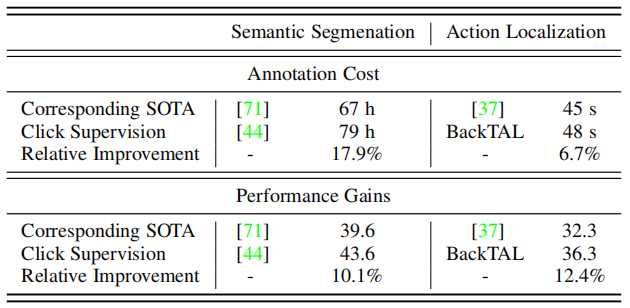
表5:点击监督的有效性。基于[44]和BackTAL的开创性工作,我们展示了在半分割域和时间动作定位域的标注成本和性能的提高。可以发现,BackTAL需要更少的标注成本,但却实现了更多的改进。

表6在THUMOS14数据集上的背景点击标注与动作点击标注的比较。

表7关于THUMOS14数据集上的评分分离模块和亲和力模块的有效性的消融研究。
4.4 消融研究
标注背景的优越性。我们将建议的背景点击标注与SF-Net[11]之前提出的动作点击标注进行了比较,并将结果报告在表6中。我们采用SF-Net[11]发布的动作点击标注来进行公平的比较。从相同的基线方法开始,引入动作点击监督带来了0.5mAP的改进,而建议的背景点击监督带来了6.4mAP的改进。当只有动作点击监督或背景点击监督可用时,除了基线方法使用的视频层分类损失外,我们只在标注的帧上引入帧级分类损失,而不使用任何其他损失函数。这证明了我们的假设,即背景点击标注比动作点击标注更有价值,因为有代表性的动作框架可以通过top-k聚合过程发现,而且大多数定位错误来自于背景错误。此外,从基线+动作单击开始,引入背景单击标注仍然可以将性能从29.1mAP提高到36.8mAP。这说明了背景单击标注与动作单击标注是相当互补的补充。相比之下,从基线+背景点击开始,引入动作点击标注只会将性能从35.0mAP提高到36.8mAP,这与我们的假设,即动作点击标注在一定程度上与顶部k聚合过程的冗余是一致的。值得注意的是,分数分离模块和亲和性模块所带来的性能收益可与最近的一些工作[11],[40]相媲美。
每个模块的有效性。表7报告了每个模块的消融研究。具体来说,虽然BaS Net[14]的官方实现在tIoU阈值0.5下得到27.0 mAP,但我们通过简化数据扩充过程实现了28.6 mAP。背景点击标注带来了明显的性能改进,并实现了35.0 mAP。在此基础上,分数分离模块和亲和力模块分别带来了0.6 mAP和0.8 mAP的改进。最后,完整的BackTAL方法实现了36.3map。可能存在这样一种担忧,即分数分离模块和亲和力模块在背景点击标注时没有带来明显的改进。首先,这项工作的核心贡献是将动作点击监督转换为背景点击监督,从而实现显著的性能提升。另一方面,从一个性能良好的方法开始,分数分离模块和亲和力模块可以进一步改进,总共贡献1.3个mAP增益,这表明了它们的有效性。此外,我们还研究了亲和力损失Laff对亲和力模块的影响。本实验获得35.1 mAP,验证了去除亲和性损失会使亲和性模块失效。据我们所知,这是因为监督不足会导致低质量的局部注意力掩码。

图9。局部注意掩码的可视化。对于每个例子,我们展示了在选定的动作帧(橙色显示)或背景帧(红色显示)与其对应的相邻帧之间计算出的注意力掩码。
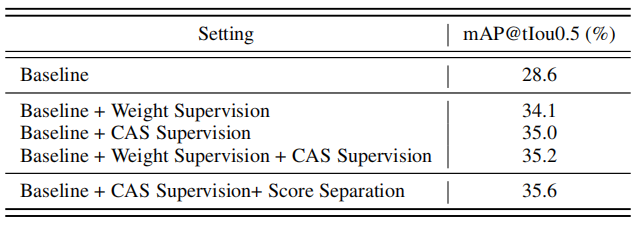
表8关于以不同方式挖掘位置信息的消融研究。直接挖掘位置信息是对注意权重(权重监督)或类激活序列(CAS监督)进行监督分类。此外,我们提出了分数分离模块来进一步挖掘位置信息。实验在THUMOS14数据集上进行。
挖掘位置信息的不同方法。给定背景点击标注,挖掘位置信息的自然选择是对类激活序列进行监督分类。此外,当网络学习到一个class-agnostic的注意权重来过滤背景时,我们可以通过二元分类对注意力权重进行监督。此外,我们还可以联合挖掘关于类激活序列和注意权重的位置信息。实验结果如表8所示,tIoU阈值为0.5。首先,与基线方法相比,挖掘位置信息可以带来足够的性能提升。具体来说,“CAS监督”比“权重监督”表现更好,但同时使用这两种监督并不能明显表现出进一步的改善。这表明简单的帧分类的多个变体是同质的,不能额外提高定位性能。相比之下,提议的分数分离模块明确地模拟了动作和背景的反应。扩大分数差距的目标会提升对动作帧的响应,并抑制对背景的响应,从而进一步将性能从35.0 mAP提高到35.6 mAP。

表9在THUMOS14数据集上,通过IoU阈值0.5下的mAP(%)测量相邻帧数的影响。
消融与相邻帧的数量有关。在亲和力模块中,我们保持相邻帧数h与时序卷积核的大小之间保持相同的值。或者,我们可以首先计算h个相邻帧的加权和,然后执行时序卷积。如表9所示,当h从3变化到9时,我们没有观察到性能的改善。因为相邻帧的数量会影响上下文的范围,一个潜在的原因是,适当的上下文(例如,h=3)可以增强特征表示,而过度的上下文会带来不必要的噪声。

图10。在THUMOS14数据集上,对所提出的BackTAL和SF-Net[11]进行了定性比较,其中描述了每个动作实例的开始时间和结束时间。对于第二个可视化,请查看放大,并注意网球,以区分动作帧和背景。
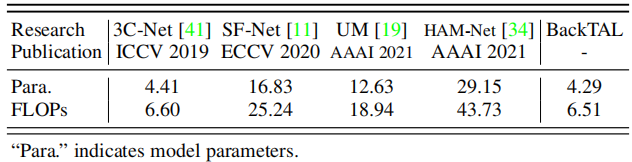
表10我们的BackTAL和最近的动作定位方法在模型参数(M)和计算FLOPs(G)方面的复杂性比较。
计算复杂性。表10比较了模型参数和计算失败方面的计算复杂性。可以看出,我们的方法比最近的方法SF-Net[11]、UM[19]和HAMNet[34]具有更低的计算复杂度。值得注意的是,与最新的方法HAM Net[34]相比,我们的BackTAL只有14.72%的参数和14.89%的失败。
嵌入维度。在亲和力模块中,BackTAL为每一帧学习一个嵌入,其目标是区分动作帧和背景帧。考虑到不同的嵌入维数导致嵌入向量的表示能力不同,我们进行了消融实验来研究嵌入维数Demb的影响。如表11所示,当Demb=32时,BackTAL实现了高性能的36.3mAP。较小的嵌入维数可能会限制表示能力,而较大的嵌入维数则难以学习,这限制了BackTAL的性能。

表11对THUMOS14数据集上的时间动作定位性能的不同嵌入维度的探索。
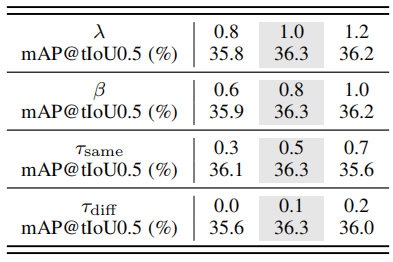
表12消融研究探讨了四个超参数的影响:完全损失函数λ和β中的平衡系数,阈值τsame和τdiff,以计算THUMOS14数据集上的嵌入损失。
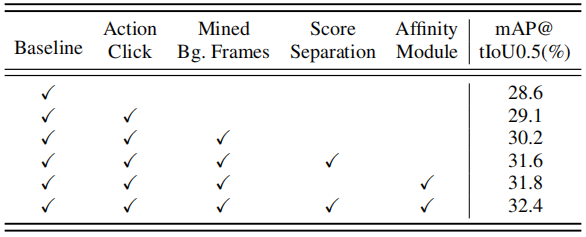
表13基于动作点击标注和挖掘的背景帧,对THUMOS14数据集上的分数分离模块和亲和力模块的有效性进行了消融研究。
超参数的影响。在提出的BackTAL中,平衡系数λ和β,阈值τsame和τdiff由经验确定。我们通过消融实验来研究这些超参数的影响。具体来说,我们在修复其他超参数时改变一个超参数,并验证在THUMOS14数据集上的时间动作定位性能。如表12所示,当超参数在一个合理的范围内发生变化时,我们可以观察到一定的性能变化。例如,降低损失函数中的系数λ会降低0.5mAP的性能。增加τsame将使算法选择类似的动作(或背景)帧更加严格。因此,BackTAL会选择较少的向量来学习嵌入空间,从而损害了性能。降低阈值τdiff也有类似的趋势。相反,减少τsame或增加τdiff会引导BackTAL选择更多的向量来学习嵌入空间。冗余嵌入向量会给学习过程带来噪声,约束学习性能。
基于动作单击标注的性能。此外,我们还使用了SF-Net[11]的动作点击标注,并采用了SF-Net的策略来挖掘背景帧。该实验结果得到32.4 mAP,如表13所示。一方面,由于提出的分数分离模块和亲和力模块,我们的BackTAL(32.4 mAP)在使用相同的动作点击监督时超过了SF-Net(30.5 mAP)。另一方面,基于动作点击的方法(32.4 mAP)和基于背景点击的BackTAL(36.3 mAP)之间的性能差距证明了背景点击监督的有效性。
4.5 定性分析
本节以定性的方式分析所提出的BackTAL方法。首先,图9显示了亲和力模块中使用的局部注意力掩码。可以发现,给定一个动作帧,局部注意遮罩可以突出显示相邻的动作帧并抑制背景帧,反之亦然。在此基础上,局部注意掩码充当frame-specific的注意权重,并指导时序卷积的计算。最后,高质量的局部注意掩码有助于产生区分类激活序列。
此外,图10将提出的BackTAL与基线方法和强大的竞争对手SF-Net[11]进行了比较。基线法和SF-Net都会冒一些风险,不恰当地将令人困惑的背景帧视为行为。例如,潜水后浮出水面的人可能被视为悬崖跳水动作的一部分。手的移动,但不是完整的挥杆动作,可以被视为网球挥杆动作。由于没有足够的能力来抑制混淆的背景帧,该算法可能会将多个相邻的动作实例视为一个长动作实例,或者定位不精确的动作边界。相比之下,所提出的BackTAL可以持续地抑制令人困惑的背景帧,并精确地分离相邻的动作实例。在实验中,我们还注意到BackTAL将一些长动作实例分解为几个独立的实例。当动作实例中存在极端变化时,就会出现这些故障情况。例如,视角更改可能会导致对象大小的极端变化。这些失效案例提醒我们,弱监督的时间动作定位应该进一步发展。
5 结论
我们将动作点击监督发展为背景点击监督,并提出了弱监督时间动作定位的背景。我们将学习过程转换为同时挖掘位置信息和特征信息,并提出了分数分离模块和亲和力模块,以缓解动作上下文混淆的挑战。在实验中,BackTAL在两个传统基准上构建了新的高性能,即THUMOS14和ActivityNet v1.2,并报告了在最近的大型基准HACS上的良好表现。此外,我们还验证了显式分离行为分数和背景分数以及动态关注信息邻居的有效性。未来,我们计划将背景点击监督的思想引入类似的弱监督学习领域,例如,弱监督对象定位[72]和检测[47],点监督语义分割[44]。此外,研究位置信息和特征信息之间的内在相关性,有助于进一步发展背景点击监督。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号