
ACGNet Action Complement Graph Network for Weakly-supervised Temporal Action Localization
0. 前言
摘要
在未修剪的视频中,弱监督的时间动作定位(WTAL)已经成为一项实际但具有挑战性的任务,因为只有视频级别的标签可用。现有方法通常利用现成的段级特征,这些特征存在空间不完整性和时间不一致性,因此限制了它们的性能。在本文中,我们从一个新的角度来解决这个问题,通过一个简单而有效的图卷积网络,即动作补充图网络(ACGNet)来增强段级表示。它有助于当前视频片段感知来自其他片段的时空依赖性,这些依赖性可能传达互补的线索,从而隐含地减轻了上述两个问题造成的负面影响。通过这种方式,段级特征对时空变化更具辨别力和鲁棒性,有助于提高定位精度。更重要的是,提出的中的ACGNet作为一个通用模块,可以灵活地插入不同的WTAL框架,同时保持端到端的训练方式。在THUMOS'14和ActivityNet1.2基准上进行了广泛的实验。其中最先进的结果清楚地证明了所提出方法的优越性。
1.介绍
理解视频中的人类行为是一个重要的研究方向,在计算机视觉领域得到了积极的研究(Wu等人2019;Wang等人2020;Zolfaghari,Singh和Brox 2018;Qin等人2017;Li等人2020;Qi等人2020;Liu等人2020;Feichtenhofer等人2019; 孔等人2020年;杨等2021;倪、秦和黄2021年)。基本步骤是构建有意义的时空表示,它不仅涉及每个帧的静态特征,还涉及连续帧之间的动态依赖关系。在动作理解的主要任务中,时间动作定位(Wu et al.2020;Lin et al.2018,2019)在过去几年中得到了巨大的发展,具有广泛的应用(例如,智能监控、视频检索和人机交互)。
为了获得准确的定位结果,传统的(完全监督)时间动作定位(FTAL)方法(Shou等人2017;Lin等人2018、2019;Zhao等人2017;Yang等人2019)通常使用在具有帧级标注的视频数据集上训练的深度卷积神经网络(CNN)。不幸的是,随着数据集规模的快速增长,视频总长度甚至达到几十年(Abu El Haija等人,2016),获取这种细粒度标注显然是不现实的。为此,弱监督时间动作定位(WTAL)(Wang et al.2017)最近成为了一项更实际的任务,该任务仅对视频级动作类别进行标注。为了解决WTAL问题,一种常见的做法是对长度相等的短片段进行统一采样,并使用视频级标签对分类器进行训练(通常通过多示例学习(Paul、Roy和Roy Chowdhury 2018)),定位结果是基于每个片段在动作类别方面的分类/激活分数生成的。
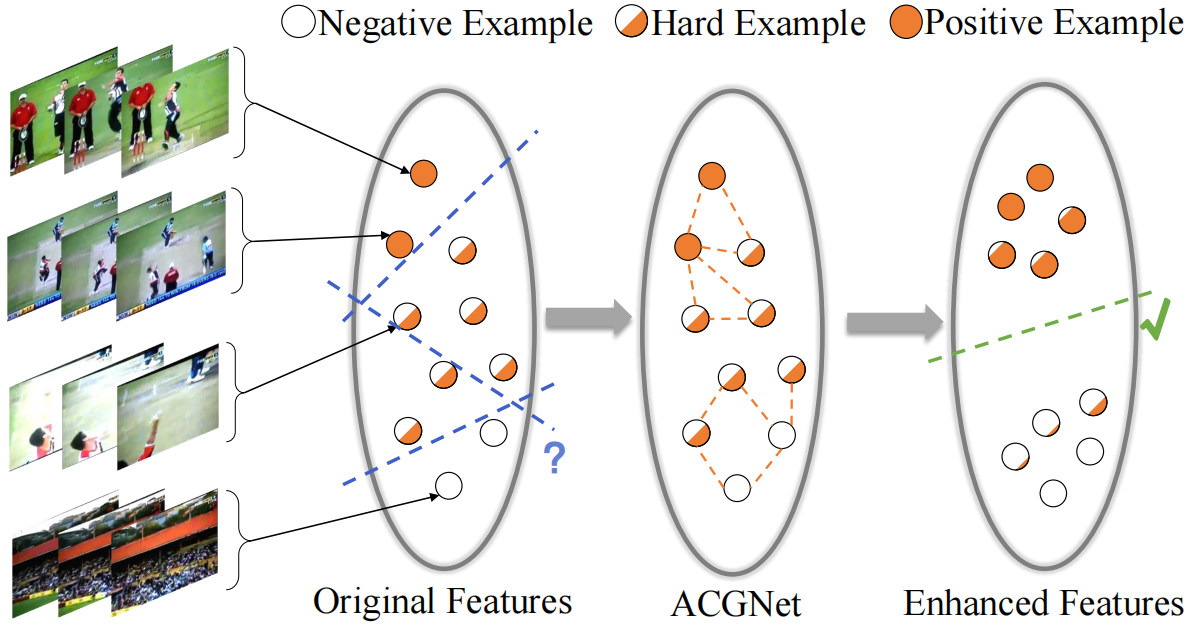
图1:提出的动作补充图网络(ACGNet)背后的直觉。通过利用不同片段之间的互补信息,学习更具区分性的片段级动作表示,从而获得更准确的定位结果。蓝色/绿色虚线表示分类超平面。
然而,在这个范例中,均匀采样策略会产生两个严重限制定位性能的关键问题。一方面,动作片段经常会出现遮挡、模糊、外场等问题,因此缺乏特定的空间细节。另一方面,一个完整的动作通常跨越一个较长的时间窗口,而一个较短的动作片段不足以观察该动作的全部动态。我们分别将这两个问题称作为动作片段的“空间不完整性”和“时间不一致性”,这两个问题都使得WTAL中的预测不可靠。
在这项工作中,我们通过一个简单而有效的图卷积网络隐式地解决了这两个问题。提出的动作互补图网络(ACGNet)有助于动作片段在整个未修剪的长视频中利用其他片段的互补线索。如图1所示,在应用我们的ACGNet之后,可以根据增强的特征更容易地对这些难例进行分类。特别地,我们不仅考虑分段级相似性,而且在构造初始动作补充图(ACG)时也减轻了时间上接近段的负面影响。此外,我们使这个图足够稀疏,以保留信息量最大的连接。通过图卷积,将高质量片段的互补信息传播到低质量片段,从而增强每个片段的动作表示。换言之,其他片段提供的补充信息被视为监督,以了解WTAL场景中更多的区别性特征。最重要的是,由于精心设计的损失函数,我们的ACGNet作为一个通用插件模块工作,可以灵活地嵌入到不同的WTAL框架中,进一步显著增强了SOTA的性能。
总之,我们的主要贡献有三个方面:
•我们提出了一种新的WTAL图卷积网络,即ACGNet,它通过隐式利用互补信息并联合解决空间不完整性和时间不一致性问题,极大地增强了片段级动作表示的可分辨性。
•我们考虑多个重要因素(即片段相似性、时间扩散和图稀疏)来构造初始ACG。此外,我们还提出了一种新的“简单正例挖掘”方法,使图形网络的训练变得可行和实用,使ACGNet能够灵活地注入现有的框架中。
•我们为几种最新的WTAL方法嵌入了提出的ACGNet。在两个具有挑战性的数据集上进行的大量实验表明,它能够在很大程度上进一步推动WTAL的SOTA。
2.相关工作
完全监督的时间动作定位。动作定位最近吸引了很高的研究兴趣(Zhang et al.2019;Escorcia et al.2016;Lin,Zhao,and Shou 2017;Lin et al.2018;Li et al.2019)。一个典型的流程是首先生成时序动作建议,然后根据建议对预定义的动作进行分类。例如,(Shou等人2017年)提出了一种卷积-反卷积滤波器,通过时间上采样和空间下采样来精确检测段边界。(Zhao等人,2017)提出了结构化片段网络,通过结构化时间金字塔对每个动作片段的时间结构进行建模。(Yang等人,2019年)为更有效的时空建模提供了端到端渐进优化框架(STEP)。
弱监督的时间动作定位。关于WTAL,只有整个视频的类别标签可用,没有每个动作示例的任何细粒度标注。为了应对这一挑战,现有的方法通常以相等的时间间隔分割视频,然后通过多示例学习对每个片段进行分类。具体而言,计算每个类别的片段激活分数,即类激活序列(CAS),以对动作片段进行分类。(Wang et al.2017)正式提出了“弱监督动作识别和时间定位”任务,并使用注意力权重排除不包含动作的视频片段。(Lee、Uh和Byun 2020)介绍了BaS Net,通过引入背景类来辅助训练,抑制背景帧的激活以提高定位性能。(Shi等人,2020)提出了一种基于帧级注意力的帧级概率分布模型(即DGAM),以区分动作帧和背景帧。BaM(Lee et al.2021)是BaS网络的一个改进版本,它使用多示例学习来估计视频帧分类的不确定性,并对背景帧进行建模。
目前,大多数现有的研究更多地集中在开发各种基于预提取片段级特征的学习技术,以提高定位性能。相比之下,这项工作强调通过探索和利用片段之间的时空互补性来增强片段级特征,从而有助于提升不同WTAL框架的性能。
基于图的时间动作定位。最近,一些工作研究了图形学习,以融合相关类别、多个提议或多个子动作之间的信息,从而推断某个片段可能的动作。例如,P-GCN(Zeng et al.2019)根据建议之间的距离和IOU构建了一个图,旨在利用上下文信息调整每个提案的类别和边界。G-TAD(Xu et al.2020)试图不仅利用时间上下文,还利用通过图卷积网络(GCN)捕获的语义上下文,然后将时间动作检测转化为子图定位问题。GTRM(Huang、Sugano和Sato 2020)采用GCN在动作分段任务的特定时间段内整合所有动作分段。所有这些工作都是在完全监督的环境下进行的。
在WTAL中,(Rashid、Kjellstrm和Yong 2020)建立了一个相似图,以了解动作是如何出现的,以及构成动作完整范围的子动作。值得注意的是,这与我们通过充分挖掘跨片段的补充信息来补充和增强特征的目的有本质的不同。此外,他们设计了一个固定的WTAL网络,而我们的ACGNet作为一个通用模块来改进各种WTAL框架。此外,我们还提出了不同的图设计和一个新的损失函数,使ACGNet和WTAL框架能够联合训练。
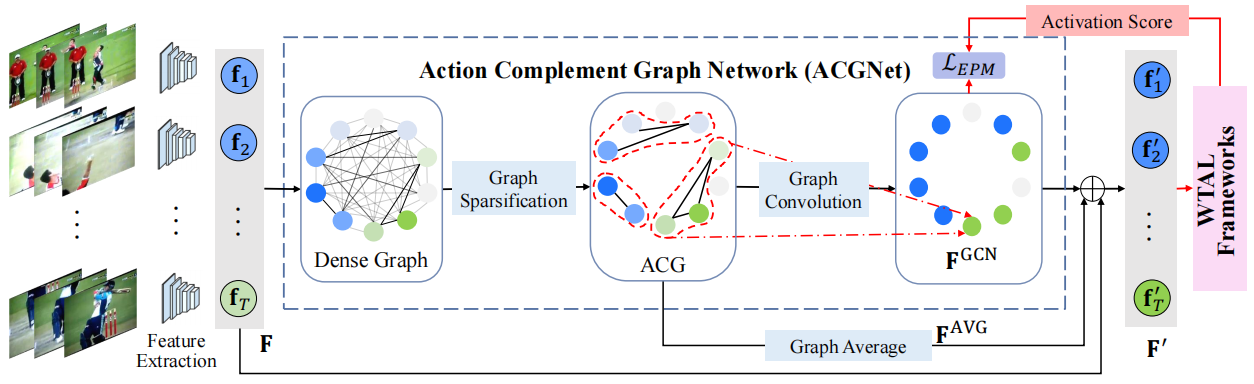
图2:所提出的ACGNet的总体框架,该框架以段级特征作为输入,通过利用不同段之间的互补线索,生成增强的、更具鉴别性的特征。更重要的是,我们的ACGNet可以灵活地插入各种现有的WTAL框架中,而无需附加
3.动作补充图网络
如上所述,输入视频被均匀地划分为多个时间段,基于该时间段执行WTAL。定位精度在很大程度上取决于片段级动作表示的可分辨性,尤其是在我们的弱监督环境中。为此,我们的目标是通过利用不同片段之间的互补信息来增强片段级表示。由于我们的ACGNet本质上是为特征增强而设计的,所以它可以被灵活地插入到现有的WTAL框架中,例如在我们的实验中使用的(李,UH,Byun 2020;李等人,2021;SH等人,2020)。在下文中,我们首先简要介绍整个提出的网络。随后,我们分别阐述了如何以原则性的方式构造动作补充图(ACG),以及如何基于图卷积增强特征。最后,我们提出了一种新的损失,使我们的图网络的训练成为可能。在将ACG-NET嵌入到现有WTAL框架之后,我们遵循(李、UH和Byun 2020;李等人,2021;SH等人2020)中提供的标准流程来生成最终的定位结果。
3.1方法概述
图2显示了提出的ACGNet的总体框架。给定一个输入视频V,我们首先将其平均分成固定数量的T个短时间段{St}Tt=1,用于处理视频长度的巨大变化。然后,我们使用广泛采用的视频特征提取网络,例如I3D网络(Carreira和Zisserman 2017),提取这些片段的特征。提取的段级特征用D维特征向量ft∈RD表示,可以连接形成视频级表示F=[f1,f2,···,fT]∈RT×D。
提出的ACGNet接收原始特征F作为输入,并基于图卷积网络生成增强的特征F'。为每个视频以一种原则性的方式构建动作补充图(ACG),以在其节点(即片段)之间交换补充信息。构造ACG后,使用图卷积操作传播和融合节点级特征。输出的图特征可以被视为原始特征的增强和互补对应。最后,将原始特征和增强特征结合起来作为最终的判别特征F',可以作为任何WTAL方法的输入,在很大程度上提高其定位性能。此外,还提出了一种新的loss,以促进我们的ACGNet和现有WTAL框架的联合训练。
3.2动作补充图
由于缺乏帧级标注,很难对单个短片段进行分类。然而,视频中的多个片段(其中通常存在易于分类的动作示例)可以相互补充。因此,ACG将捕捉互补关系并增强每个片段的表示。
在形式上,ACG被定义为G=(V,E)。V表示一组节点{vt}Tt=1,对应于T个段级特征{ft}Tt=1,E表示eij=(vi,vj)是节点vi和vj之间的边集。此外,我们将A∈RT×T定义为与图G相关的邻接矩阵。一条边的权值,即Aij,表示两个连接节点之间的关系强度,权值越大,表示两个段之间的关联性越大。
接下来,我们将介绍如何同时考虑多个因素来构建ACG。
片段相似图。未经修剪的长视频可能包含多个动作示例,由于场景、照明条件、拍摄角度、遮挡等的不同,差异很大。但是,同一动作类别的多个示例之间始终存在相似的运动模式,其中,一些高质量或易于分类的片段记录了干扰较少的更完整的动作示例,提供了相对稳定的信息,而低质量的片段也可以相互补充。例如,属于同一动作类别的两个时间段可能在不同区域被遮挡。在这种情况下,一方可以帮助另一方感知在其自身片段中可见的区域。因此,我们希望在所有段之间传播各种互补信息。为此,我们首先通过考虑片段级特征之间的相似性来构造片段相似图。
在这里,我们利用两个原始段级特征之间的余弦距离来度量它们的相似性,并通过设置第i个节点和第j个节点之间的边权值(即Asij)来构造相似性图Gs,如下: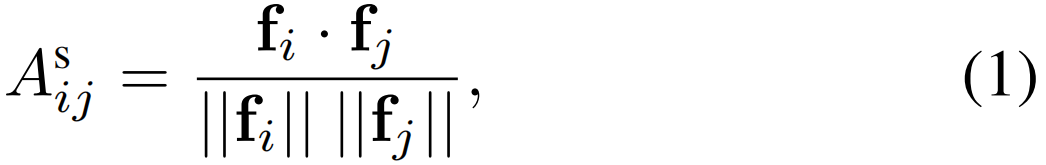
其中(·)是内积,||·||是大小。
时间扩散图。由于在连续段之间存在高度的时间依赖性,因此我们在构造图时也考虑了时间信息。在自然界中,时间上接近的片段通常具有较高的概率属于相同的动作,并且往往有较高的相似性,即相应的边权值应该相对较大。此外,在实际应用中,特征提取网络中的时间卷积(即我们实验中的I3D)可以在较短的时间窗口内融合相邻段之间的时间信息。这导致了时间接近段之间更高的特征相似性(即,当i→j时,Asij趋于较大)。因此,如果我们基于上述事实构造时间图,并将其直接添加到段相似度图中,互补信息的传播可能会在较短的时间窗口内受到限制,不能在距离很远的段之间成功共享。例如,包含高质量判别动作示例的第i段Si不能补充其他在时间上远离Si的劣质示例(属于同一动作)。
因此,我们试图尽可能分散互补信息,以便在未经修剪的长视频中增强更多片段的可分辨性,从而提高定位性能。为此,我们通过在更远的节点之间施加更大的边权重来构造时间扩散图。具体而言,我们构建了时间扩散图Gt,如下所示:
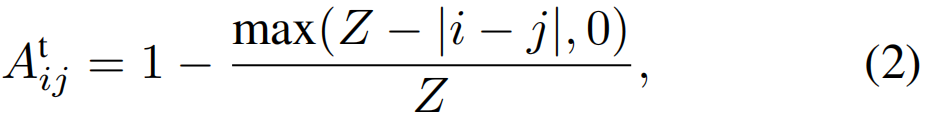
其中,Z是控制扩散度的超参数。
总体稀疏图。通过简单地将两个子图Gs和Gt相结合,我们可以得到最终的动作补充图G,其邻接矩阵定义如下: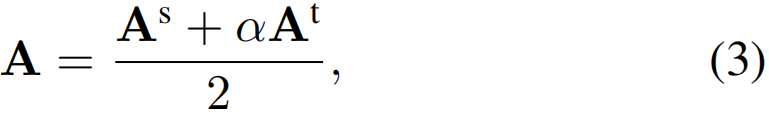
其中,两个矩阵As和At分别包括Asij和Atij作为它们的第(i,j)项,α超参数是为了对两个子图进行更好的权衡。由于这两个子图的边权值大多大于零,因此简单地将它们组合起来形成ACG将生成一个非常密集的图。如果我们直接学习基于这个密集图的增强特征,对于每个节点/片段,我们可能会获得相似的全局视频级特征,因为每个节点都需要感知所有剩余节点的特征。这隐含地妨碍了段级特征的可辨别性,导致定位结果不太准确。因此,有必要使图足够稀疏,只保留那些信息量最大的节点。特别地,我们设置了基于阈值λ和top-K排名列表的稀疏化标准。最终的稀疏ACG被构造为:
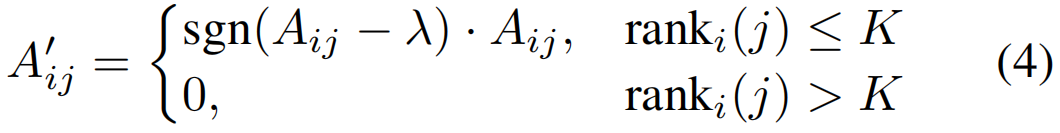
其中sgn(·)是一个指示符,即如果x>0,则sgn(x)=1;否则,sgn(x)=0,ranki(j)是A的稠密图中第i个节点的所有相邻节点中第j个节点关于边权重的排名数。我们对λ和K采用这两个标准来使图稀疏,因为简单地采用阈值不能丢弃在相似场景中属于不同动作类的模糊片段。这种直觉也得到了我们实验中的消融实验的支持。
3.3图形推理
图平均。在构造最终稀疏ACG后,聚合所有节点级特征的一种简单方法是通过考虑以下边权重来计算平均特征: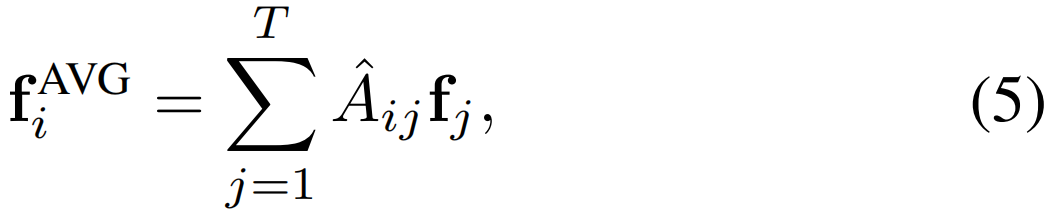
其中,![]() 是矩阵
是矩阵![]() 的第(i,j)个项,它是关于A'的行归一化邻接矩阵。在实际应用中,我们发现平均特征fiAVG可以在一定程度上交换互补信息,从而达到了后续实验中令人满意的性能。
的第(i,j)个项,它是关于A'的行归一化邻接矩阵。在实际应用中,我们发现平均特征fiAVG可以在一定程度上交换互补信息,从而达到了后续实验中令人满意的性能。
图卷积。除了上述平均特征外,我们还将图卷积合并到ACGNet中,以更好地聚合节点级特征。对于具有M层的图卷积网络(GCN),关于第m层(1≤m≤m)的图卷积操作如下:
![]()
F(m)是第m个图卷积层生成的特征,F(0)=F是原始特征,FGCN=F(M)是最后一个图卷积层的最终输出,W(m)∈RD×D是第m层的可训练参数,σ(·)是ReLU(Nair和Hinton2010)激活函数。
最后,将原始特征与图平均特征和GCN的输出特征相结合,得到增强的判别特征:
![]()
由于F'是原始特征的对应增强特征,不同的WTAL方法可以用f'替换其原始输入,进一步执行后续的定位任务。
3.4训练目标
为了发现易于分类的片段,以增强其他类似片段的特征,使更多的片段更易于分类,我们提出了一种基于“简单正例挖掘”(EPM)策略的新损失,以充分训练具有ACGNet嵌入的WTAL网络:
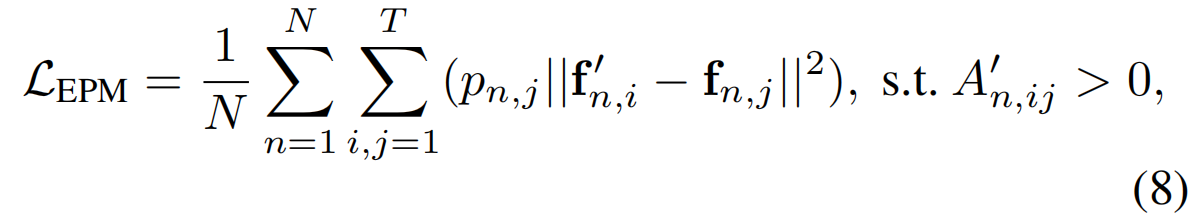
其中,f'n,i是ACGNet关于第n个视频中的第i个片段的输出特征,fn,j和pn,j分别是同一视频中第j段的所有类的原始特征和最大激活分数。
基于公式(8),ACGNet的输出特征被鼓励与类似片段的原始特征保持一致,尤其是那些能够以最高置信度成功分类的“简单阳性”示例。换言之,“简单阳性”片段可以被视为特征空间中的类质心,我们的目标是将其他类似片段推近它们。因此,更多的动作片段变得更容易区分,最终获得更准确的定位结果。
4.实验
4.1实验设置
数据集。THUMOS'14(Idrees et al.2017)包含20节体育课的20多小时视频。由于视频长度的多样性和动作示例的大量性,数据集非常具有挑战性(∼15) 每段视频。训练集只包含不适合动作定位的修剪视频,但验证集和测试集分别提供200和213个未修剪视频。接下来(Lee,Uh,and Byun 2020;Shi et al.2020;Lee et al.2021),我们对验证集进行训练,并对测试集进行评估。活动网1。2(Caba Heilbron等人,2015年)包括100类动作。训练、验证和测试集分别由4819、2383和2480个视频组成。然而,测试集中没有公开的动作标签,因为它只用于比赛。因此,我们遵循(Lee,Uh,and Byun 2020;Shi et al.2020;Lee et al.2021)中的一般做法,使用训练集进行训练,并使用验证集进行测试。
基线。ACGNet作为一个通用模块,可以整合到不同的WTAL框架中。与其他框架的集成相当简单,我们只需要用ACGNet获得的增强功能替换原有功能。在我们的实验中,我们采用了最近提出的三种WTAL方法,包括BaS-Net(Lee,Uh和Byun 2020)、DGAM(Shi等人,2020)和BaM(Lee等人,2021)。
由于其灵活性,我们的ACGNet还可以被纳入其他动作检测(例如FTAL或更通用的时空动作检测)框架。然而,应该注意的是,ACGNet旨在增强分段级表示,这在WTAL环境中尤其重要,因为只有视频级标注可用。在FTAL或其他相关任务中,基于提供的细粒度(帧级)标注,可以更容易地优化段级特征。
评估指标。我们采用标准度量来评估不同方法的性能,即在不同的联合交集(IoU)阈值下的平均精度(MAP)。在实践中,我们采用ActivityNet提供的官方评估代码。
实施细节。该框架是使用PyTorch库实现的。我们的ACGNet和后续动作定位网络以端到端的方式进行联合训练。动作定位网络保留了其原始文件中的参数设置,我们在NVIDIA Tesla V100 GPU上应用随机梯度下降(SGD)同时优化联合网络。为了与其他WTAL方法进行公平比较,我们利用I3D(Carreira和Zisserman 2017)提取初始段级特征。根据经验,构建ACG所采用的超参数的经验设置如下:Z=10、α=1和λ=0.85。当以BaS-Net作为动作定位网络时,我们将K设为50,T=750为固定值。当使用其他两个定位框架时,我们设置了T=400(与原论文一致)和K=T/10=40。我们在所有的实验中都使用了一个2层的图卷积网络
4.2与最新方法的比较
THUMOS'14上的结果。表1显示了不同方法在THUMOS'14上的定位性能。为了公平比较,我们还报告了基于我们实现的三个采用的WTAL框架的结果。从表中,我们可以看到,在整合提议的ACGNet后,三个定位网络的结果在大多数IoU阈值方面都得到了显著且持续的改善。值得注意的是,当IoU阈值设置为0.5时,BaS Net、DGAM和BaM在mAP中分别获得3.0%、1.8%和1.3%的绝对改善。BaM的优势并不显著,可能是因为BaM通过背景建模大大提高了片段特征的可分辨性。这些事实表明,在弱监督环境下,利用时间段之间的互补线索是有效的。总之,我们在很大程度上推动了WTAL技术的发展,甚至与一些完全监督的方法的性能相当。
ActivityNet1.2上的结果。表2显示了ActivityNet1.2上的比较结果。与THUMOS'14的观察结果类似,我们的ACGNet极大地加强了现有WTAL框架的所有IoU阈值,BaS网络的改进尤其令人鼓舞。具体来说,当采用0.5作为IoU阈值时,BaS Net、DGAM和BaM的映射分别提高了3.9%、1.1%和1.0%。这再次证明了所提出的特征增强网络的优越性。
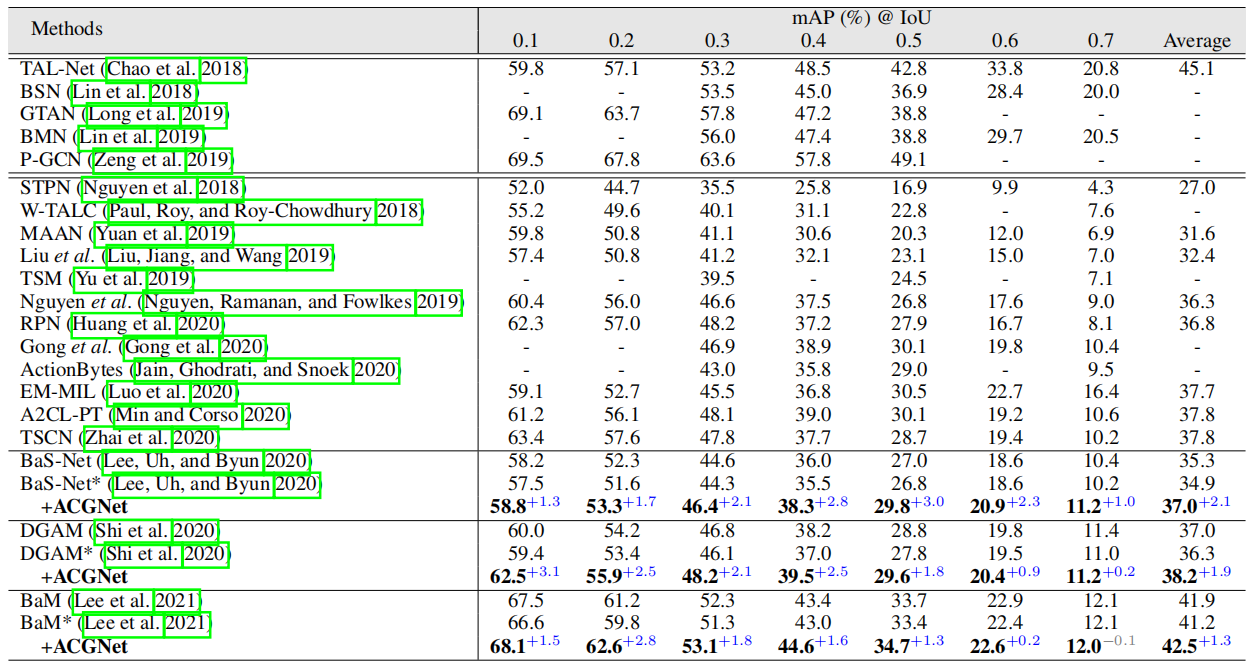
表1:THUMOS‘14的比较结果。*表示基于我们的实现的结果。
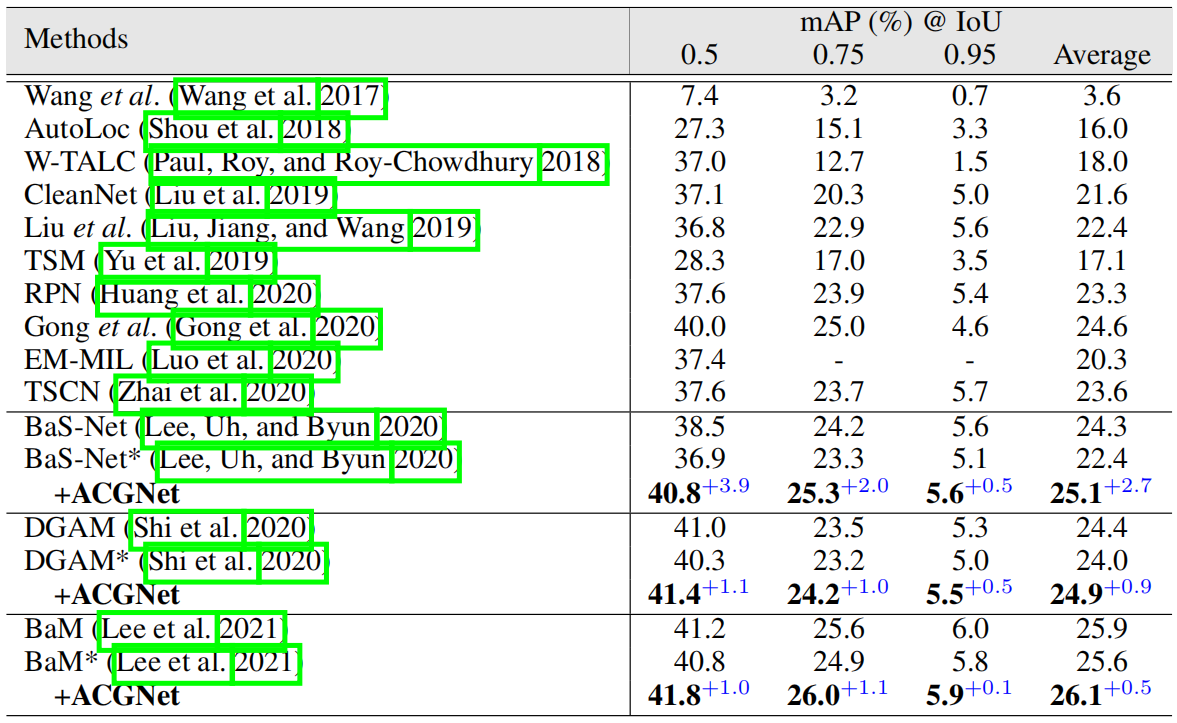
表2:在ActivityNet1.2上的比较结果。*表示基于我们的实现的结果。
4.3消融研究
我们在BaS网络上进行消融研究,因为它是三个基线中最灵活、最有效的。值得注意的是,将ACGNet插入BaS网络时,参数数量从26.3 M增加到34.6 M。由于ACGNet包含多个处理步骤,且未完全优化,因此预计会出现这种复杂性。然而,考虑到这种通用模块的灵活性和一致的性能增益,复杂性的增加是可以接受的。
图形设计的效果。我们首先研究不同图形设计的优点。表3显示了不同稀疏度(K)的结果。G1表示直接使用段相似度图Gs;G2是我们ACG的变体,从Gs中减去时间扩散图Gt;G3是提出的ACG。具体来说,当=50时,G3在三者中获得最高的mAP。然而,当图密度越大,结果就会逐渐减少。这与我们之前的假设很一致,即密集图不能在所有数据段中利用最具鉴别性的特征。最后,我们只使用Gt来测试性能。在这种情况下,Gt中的大多数边都用1加权,不能保证有有意义的特征增强。因此,当K=为50时,我们只得到较差的mAP为22.1%。
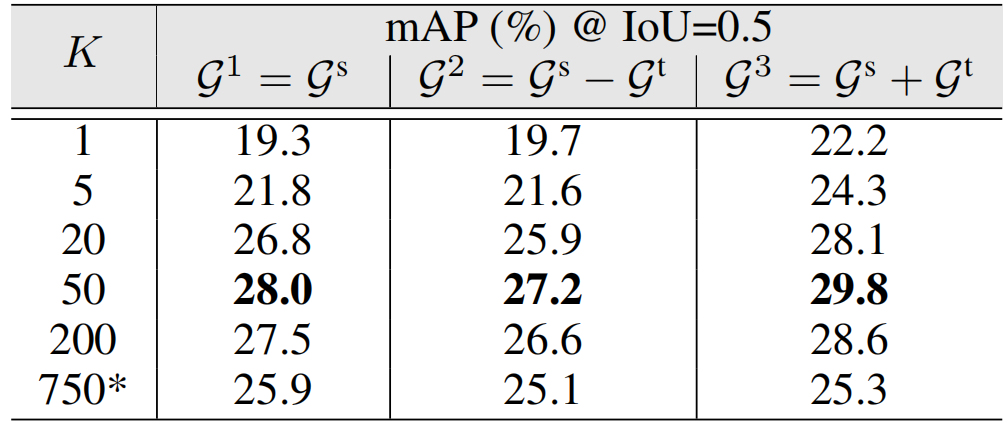
表3:在THUMOS’14上的不同图形设计的结果。*表示没有稀疏化的密集图。
稀疏化的影响。如上所述,表3包含了关于K在采用不同稀疏度级别时的一些结果,我们另外评估了阈值λ如何影响最终性能。如图4所示,通过考虑图稀疏化的这两个因素(即λ和K),总是可以得到最好的结果。这表明,仅仅使用一个阈值并不足以维持最具鉴别性的节点。这可能是因为在一些视频中场景保持不变,也就是说,即使片段包含不同类型的动作实例,不同片段之间的相似性总是很高。在这种情况下,简单地采用一个阈值,就可以保留那些属于不同类别的无关节点。通过进一步施加top-k约束,我们可以去除模糊节点,保留最相关的节点,从而获得更具辨别力的段级特征。
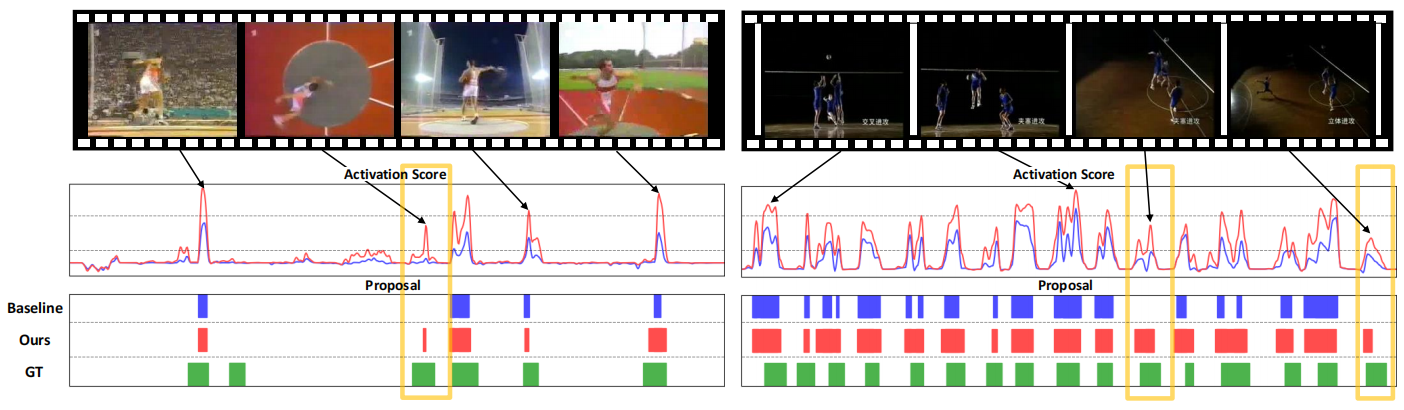
图3:在THUMOS'14上的两个典型视频示例的定性可视化。BaS-Net(基线)、BaSNet+ACGNet(Ous)和ground-truth(GT)的结果分别用蓝色、红色和绿色表示。黄色的方框包括一些Bas-Net无法检测到的困难情况,但可以通过我们的方法成功地定位。
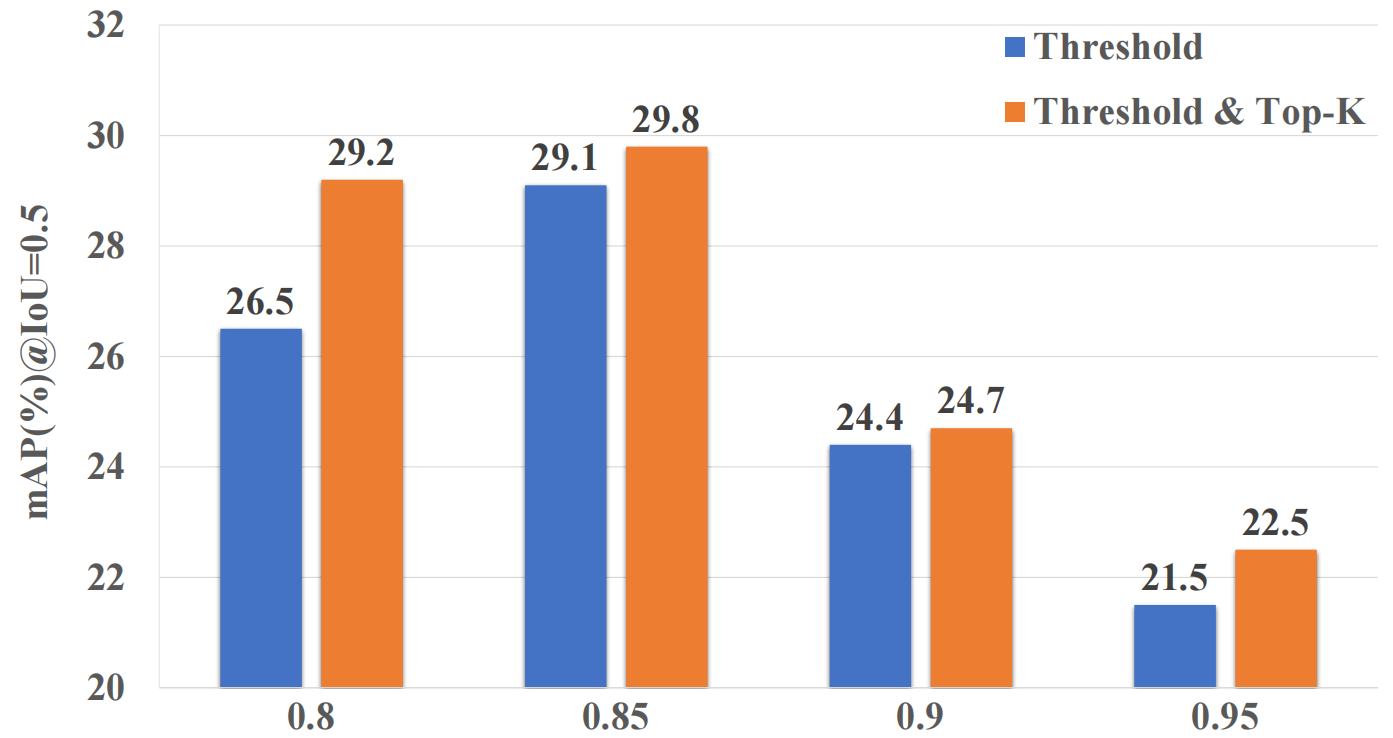
图4:ACGNet(与BaS网络)在THUMOS'14上关于λ使用不同稀疏度的比较结果。
组件验证。表4显示了基于ACGNet中不同成分的结果。具体来说,我们测试了采用不同特征和不同特征组合方式时的性能。我们可以看到,将原始特征与加权平均或图卷积特征相结合可以显著提高整体精度。通过融合所有功能,我们可以获得最佳性能。同样值得注意的是,如果在图形训练期间丢弃EPM损失,则会观察到较差的性能。如前所述,这是因为图卷积层无法充分训练。有趣的是,当仅使用增强的基于图形的功能时,准确度会下降很多,这表明将其作为原始功能的补充是释放图形功能潜力的有效方法。此外,仅使用FAVG性能最差,因为整个视频的平均特征无法表示不同动作示例的不同时间动态。
4.4定性分析
图3显示了一些定性结果。曲线表示检测激活分数,而块表示IoU阈值为0.5的定位结果。可以观察到,我们的大多数分数都高于Bas Net提供的分数,这表明我们的增强功能在分类上更具辨别力。同时,其他非动作片段的得分仍保持相对较低,这表明我们的方法能够成功地区分与动作相关的片段和不相关的背景。我们还注意到,我们检测到的动作建议更完整,而Bas-Net倾向于将一个建议拆分为几个单独的较短建议,从而导致准确性降低。黄色方框中的困难案例进一步证明了我们ACGNet的优越性。
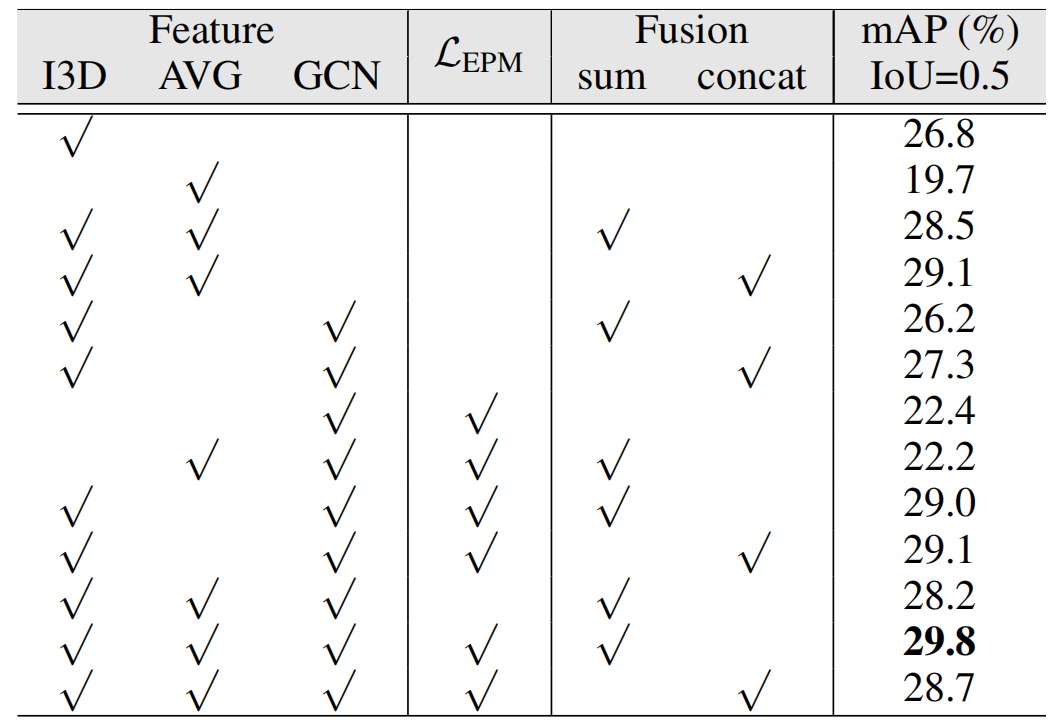
表4:THUMOS‘14上ACGNet(含BaS-Net)不同成分的结果。
5.结论
本文提出了一种用于增强WTAL视频片段级表示的可分辨性的ACGNet。来自同一视频中其他片段的补充线索,尤其是易于分类的片段,提供了一定的监督,以了解更多的判别特征。我们的ACGNet作为一个通用模块,可以灵活地嵌入到各种现有的WTAL框架中,在两个具有挑战性的基准上显著提升了SOTA的性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号