Weakly-supervised Action Localization with Background Modeling
0. 前言
摘要
我们描述了一种潜在的方法,该方法学习在给定训练视频的长序列中检测动作,并且只使用整个视频类标签。我们的方法在弱监督学习中利用了两个创新来建立注意模型。首先,最值得注意的是,我们的框架使用注意模型来提取前景和背景帧,其外观是显式建模的。大多数以前的工作都忽略了背景,但我们表明,建模可以让我们的系统了解更丰富的动作概念及其时间范围。其次,我们将自下而上的、不可知类的注意力模块与自上而下的、特定于类的激活图相结合,使用后者作为前者的自监督形式。这样做可以让我们的模型在没有明确的时间监督的情况下学习更准确的注意力模型。 最后,我们证明了弱监督学习可以用于积极扩大学习规模,以适应未经处理的Instagram视频。添加这些视频显著提高了弱监督模型的定位性能。
1. 介绍
我们探讨了弱监督的动作定位问题,其中的任务是学习在只有videolevel类标签的长序列视频中检测和定位动作。这种行动理解的公式很有吸引力,因为众所周知,即使对人类来说,精确估计行动的开始和结束框架也是一项挑战[3]。我们在一系列工作的基础上,利用注意力处理来推断最可能属于某个动作的框架。我们具体介绍以下创新。
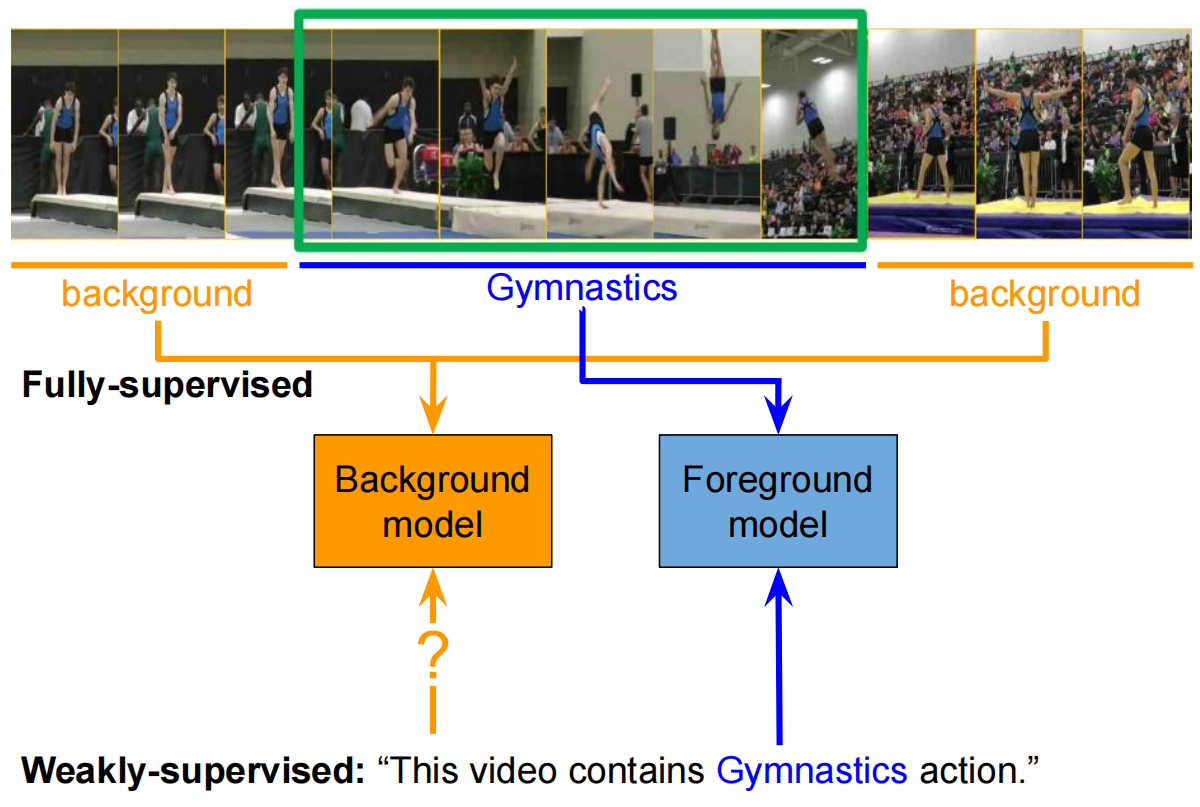
图1:通过提供精确动作边界的完全监督数据,我们可以训练高度区分的检测模型,使用背景区域作为负面示例,隐式地建模背景内容。在只有视频级别标签已知的弱监督设置中,当前的方法只是训练前景模型在视频中的某些位置做出强烈响应,但保留未建模的剩余背景帧。在本文中,我们证明了一个明确考虑背景帧的模型在弱监督定位方面有很大的改进。
背景建模:经典的流程使用注意池将模型聚焦在那些可能包含感兴趣的行为。我们证明,通过对剩余的背景帧进行建模,可以显著提高此类方法的准确性。有趣的是,对象[22]和动作[4]的完全监督系统倾向于为背景patches和背景帧建立显式模型(或分类器),但在大多数弱监督系统中,这种推理是不存在的。文献中值得注意的例外包括建立前景和背景生成模型的概率潜变量模型[16]。我们将背景建模结合到区分性网络架构中,如下所示:许多这样的网络明确地计算一个注意变量λt,该变量它指定了帧t应该影响最终的视频级表示(例如,跨所有帧的加权池)。简单地说,我们构建了一个池化的视频级特征,通过权衡帧来关注背景
自上而下引导注意力:我们的第二项创新是整合自上而下的注意力线索,作为学习自下而上注意力的额外监督形式。注意力变量λt,通常是类别未知的,寻找适用于所有类型行为的通用线索。因此,它可以被认为是一种自下而上的注意显著性[9]的形式。最近的研究表明,人们还可以通过观察(时间)类激活图(T-CAM)[19,38],从处理合并特征的分类器中提取自上而下的注意线索。我们建议使用特定于类的注意图作为一种监督形式来细化自下而上的注意图λt。具体来说,我们的损失鼓励自下而上的注意力图与自上而下的类别特定的注意力图相一致(对于已知存在于给定的训练视频中的类别)。
作为训练补充的微视频:我们观察到社交媒体平台(Instagram、Snapchat)[20]上有大量的微视频涌入。这些视频通常带有用户生成的标签,这些标签可以松散地看作视频级别的标签。这类数据似乎是弱监督视频训练数据的理想来源。然而,这些视频的效用仍有待确定。在本文中,我们表明,在现有的训练数据中添加微视频可以大大提高学习的规模,从而提高动作定位的准确性。
我们的贡献总结如下:
•我们扩展了之前的弱监督动作定位系统,包括背景建模和自上而下的类引导注意。
•我们在THUMOS14[15]和ActivityNet[13]上对我们的模型与其他先进的动作定位系统进行了广泛的对比分析,包括弱监督和完全监督。
•我们展示了使用微视频作为补充、弱监督训练数据的良好效果。
2. 相关工作
近年来,时间动作定位的进展受到大规模数据集的推动,如THUMOS14[15]、Charades[27]、ActivityNet[13]和AVA[12]。建立这样的数据集需要大量的人力来标注较长视频序列中有趣动作的起点和终点。许多完全监督的动作定位方法利用这些注释,并采用两阶段分类框架[2,26,7,14,24,37]。最新的最先进的方法[11,10,32,5,4]借鉴了最近的目标检测框架(例如R-CNN)的直觉。这些方法中的一个共同因素是在视频中使用非动作帧来构建背景模型。
然而,时间边界标注的获取成本很高。这推动了开发模型的努力,这些模型可以通过视频级别标签等较弱的监管形式进行训练。UntrimmedNets[30]使用分类模块执行动作分类,并使用选择模块检测重要的时间段。Hiden Seek[29]通过随机隐藏部分视频,解决了流行的弱监督解决方案(具有全局平均池的网络)只关注最具辨别力的帧的趋势。STPN[19]引入了一个注意力模块,用于学习分段级特征表示加权时间池的权重。该方法通过对由注意值加权的时间类激活映射(T-CAM)进行阈值化来生成检测。AutoLoc[25]引入了一个边界预测器,使用锚定系统预测管段边界。边界预测器是由外部收缩损失驱动的,它鼓励在内部具有高激活的片段,而在该片段的紧邻区域具有较弱的激活。W-TALC[21]引入了一个具有k-max多示例学习的系统,并通过共同活动相似损失明确识别相似类别视频之间的相关性。上述方法均未尝试在训练期间对背景内容进行显式建模。
3. 弱监督定位
假设我们提供了一组视频和视频级标签训练集y∈{0,……,C},其中C表示可能的动作的数量,0表示没有动作(背景)。在每个视频的每一帧t中,让我们为一个基于RGB和在该帧提取的光流特征向量编写xt∈Rd(例如,对相关的视频分类任务进行了预训练)。然后,我们可以将每个训练视频写成一个特征向量和视频级标签的元组:
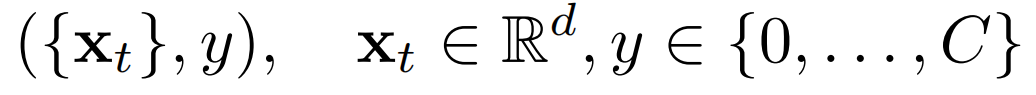
原则上,视频可能包含多种类型的动作,在这种情况下,将y建模为多标签向量更自然。从这组视频级的训练注释中,我们的目标是学习一个帧级分类器,它可以识别在测试视频的每一帧中发生了C+1类动作中的哪些动作(或背景)。
3.1. 弱监督
为了生成前景动作的视频级预测,我们在整个视频中执行帧特征的注意力加权平均池化,以生成单个场景
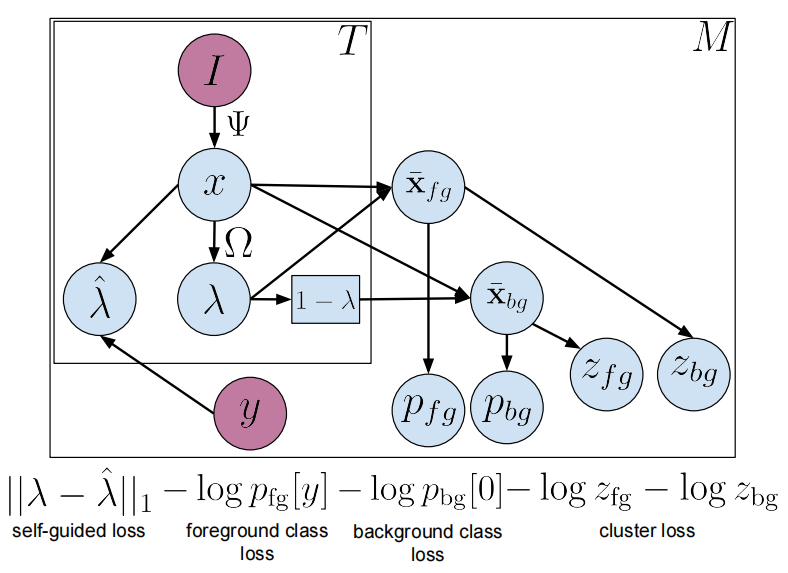
图2:弱监督动作定位模型的网络架构。使用预先训练好的网络,我们提取短视频片段的特征表示。注意力模块Ω 预测帧级注意力λ,该注意力可用于将帧级特征汇集到单个前景视频级特征表示中。注意力向量的补码,1− λ, 也可用于将属于背景的片段汇集到视频级背景表示中。Video级标签是从这些集合的特征中预测出来的。除了这种特定动作的自上而下的模型外观外,我们还包括自下而上的聚类损失,即视频应该分割为不同的前景和背景外观zfg,zbg。为了将这两者联系起来,我们根据ground-truth视频标签y的类激活情况,使用“自我引导”损失来计算注意力目标![]() ,以鼓励预测的注意力λ与该目标匹配。
,以鼓励预测的注意力λ与该目标匹配。
视频级前景特征xfg由下式给出:
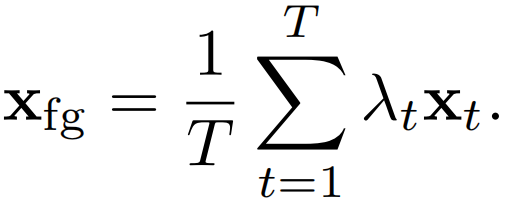
每一帧的权重是一个标量λt∈[0,1],它用于挑选出(前景)帧,在此期间发生了一个动作,同时从背景中降低权重。注意力是二维框架特征λt=Ω(xt)的函数,我们使用两个全连接(FC)层实现,第一层有一个ReLU激活,第二层是一个sigmoid激活函数。
为了产生视频级别的预测,我们将汇集的特征提供给全连接softmax层,由wc∈Rd参数化为第c类
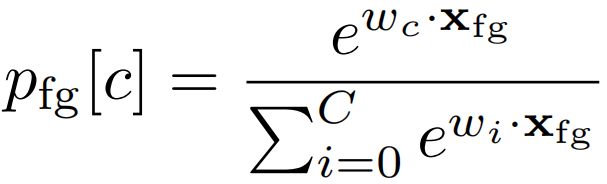
前景分类损失是通过对视频标签y的规则交叉熵损失来定义的。
![]()
背景感知损失 注意因子的补充,1−λ,代表模型认为没有任何行动发生的帧。我们建议,从这些背景帧xbg中合并的特征也应该用与应用于合并的前景框架相同的softmax模型进行分类。
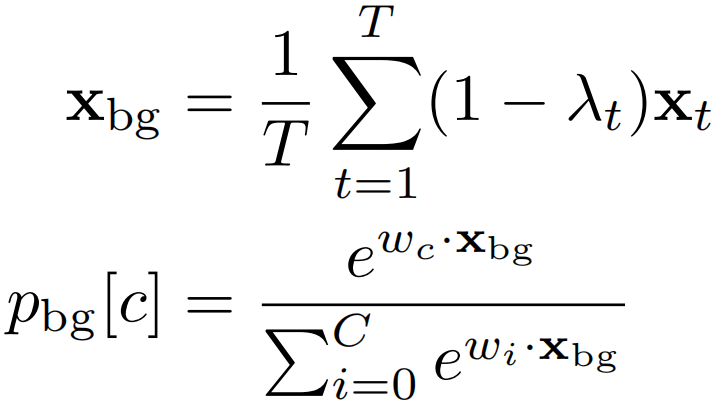
向量pbg∈RC+1表示背景合并特征的每个动作类的可能性。背景感知损失Lbg鼓励这个向量在背景索引处接近于1,y=0,否则为0。这个在背景特征上的交叉熵损失然后被简化为
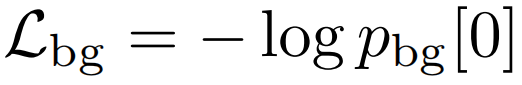
与只对前景帧进行分类的模型相比,Lbg确保参数w也能学会区分动作和背景。
自我引导的注意力损失 注意力变量可以被认为是一个自底向上的,或者说是类不可知的注意力模型,用来估计一帧的前景概率。这可能会对一般性提示做出反应,例如身体的大动作,而这些动作并非特定于特定动作。最近的研究表明,通过检查(暂时的)类激活图(TCAM),可以从基于集合特征的分类器中提取自上而下的注意线索[19,38]。我们建议使用特定于类的TCAM注意图作为自我监督的一种形式,以细化不可知类的自下而上注意图。具体来说,我们使用类上自上而下的注意力地图,这是已知的给定训练视频:λtλtY
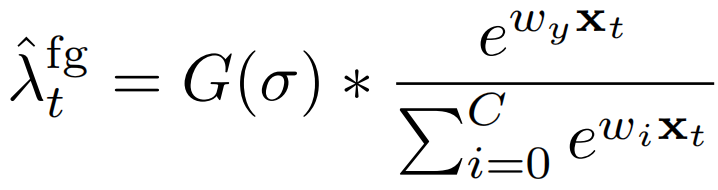
其中G(σ)指的是一个高斯滤波器,用于时序平滑特定类的、自上而下的注意力信号。高斯平滑施加了直观的先验,即如果一个帧有很高的概率成为一个动作,它的相邻帧也应该有很高的概率包含一个动作。请注意,上述softmax与(2)和(5)的不同之处在于,它们被定义在帧级(而不是视频级),并且它们不受自下而上的注意力λt=Ω(xt)的调制。
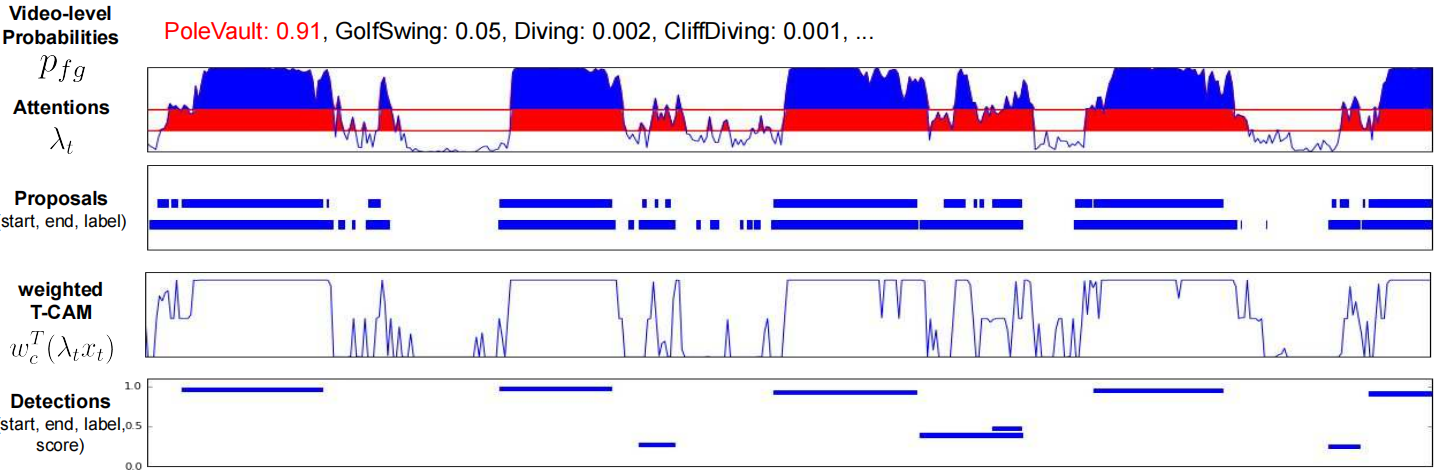
图3:检测过程包括三个步骤:视频级类概率阈值化、分段建议生成和检测评分。首先,通过视频级概率阈值来选择相关类。注意向量采用不同的阈值来选择显著的连通段。每个阈值对应于一组不同的段建议。每个建议都是通过在其时间间隔内平均加权TCAM值来得分的。执行每类非最大抑制,以去除高度重叠的检测。最后一个图中的y轴表示最终的检测分数。
由于我们的自顶向下分类器还包括背景模型,所以我们可以考虑一个由背景类激活的补充给出的注意力目标。
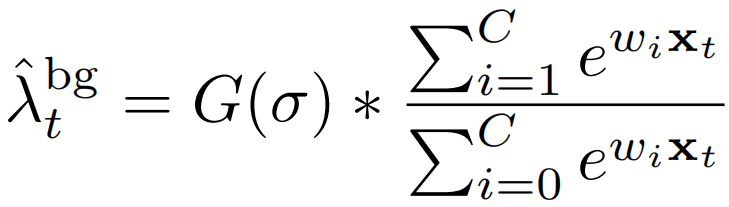
鉴于这一关注目标,我们将自我引导损失定义为
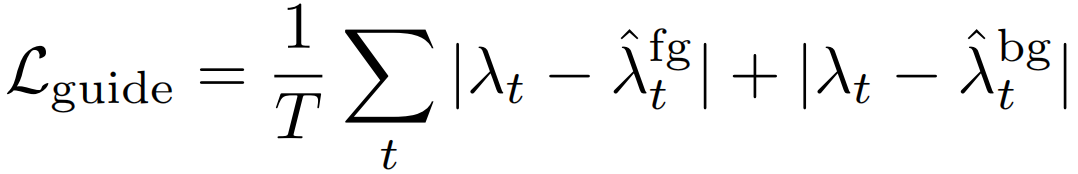
这会使位置类的自下而上的注意力图与自上而下的类特定注意力图相一致(对于已知存在于给定训练视频中的类)。
前景背景聚类损失 最后,我们考虑了一个纯粹根据视频特征和注意力λ来定义的自下而上的损失,它不参考视频级别的标签。我们估计了另一组参数ufg,ubg∈Rd,它们应用于自下而上的注意力集中特性(不需要自上而下的类标签)
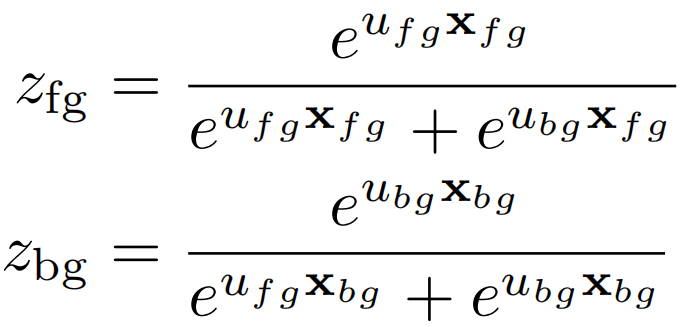
每个视频都应该包含前景和背景帧,因此聚类丢失会鼓励两个分类器对其相应的合并特征做出强烈响应
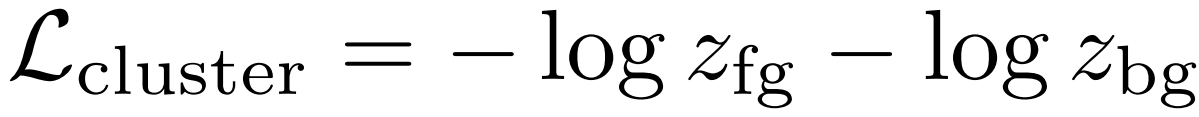
这可以被视为一种聚类损失,鼓励前景和背景合并的特征彼此不同。
总损失 我们将这些损失结合起来,得出每个视频训练的总损失
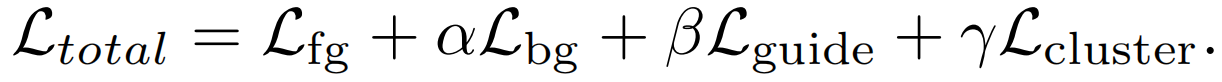
α,β和γ是控制损失之间相应权重的超参数。我们发现这些超参数(α,β,γ)需要足够小,以便网络主要由前景损失Lfg驱动。
3.2. 动作定位
为了生成行动建议和检测,我们首先基于视频级分类概率pfg来识别相关的行动类。为每个相关的类生成分段建议。然后用相应的加权t-cam对这些建议进行评分,以获得最终的检测结果。我们在时间戳t处保持段级特征,注意值λt大于某个预先确定的阈值。我们对连接相邻分段进行一维连接组件,以形成分段建议。然后,一个分段建议[tstart, tend, c]得分为
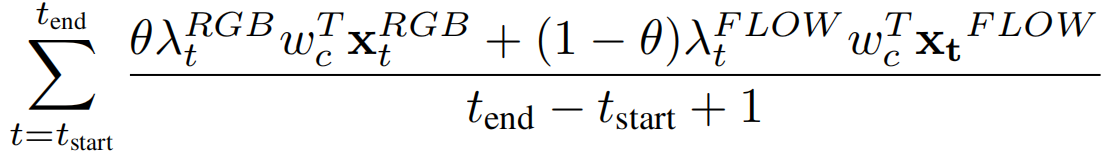
其中,θ是一个标量,表示两种模式之间的相对重要性。在这项工作中,我们设置了θ=0.5。
图3显示了推理过程的一个示例。与STPN不同,我们不会利用注意力-权重T-CAMs生成建议,而是使用注意向量λ。多个阈值用于提供更大的建议池。我们发现,从不同模式的平均注意力权重生成建议会导致更可靠的建议。分类非最大值抑制(NMS)用于消除高重叠的检测。
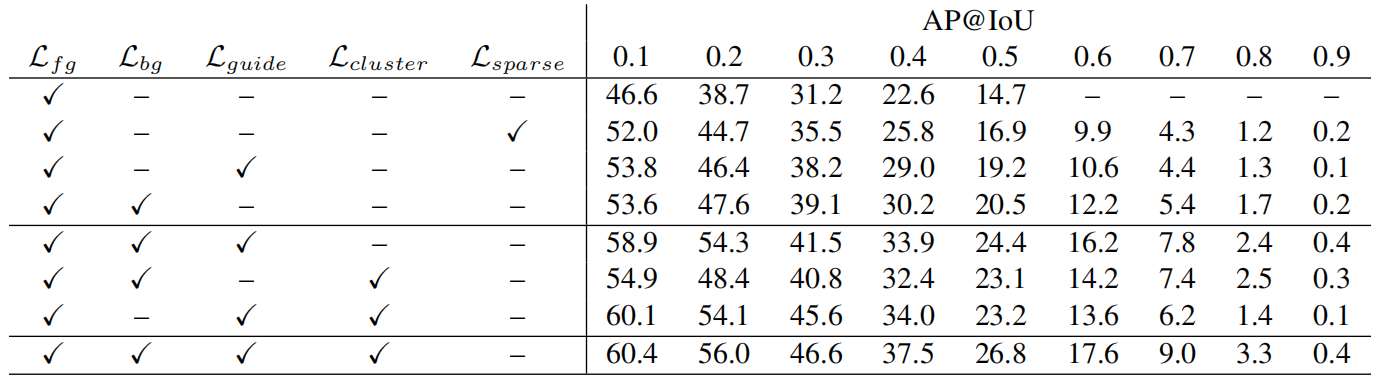
表1:消融研究表明,每一个额外的损失都会导致显著的定位性能的提高。这些损失也会相互补充,因为将它们结合起来可以获得更好的结果。第一行和第二行都来自于STPN[19]。
4.结果
故障模式 图5分析了我们方法的当前故障模式。图5a显示了发生在彼此附近的多个动作实例,它们之间几乎没有背景。当动作之间几乎没有背景时,模型无法正确分割动作。图5b显示了组合动作CleanAndJerk的示例。执行这些动作的人通常站在这些动作之间,因此模型将其分为两部分。在图5c中,我们看到了另一个困难,即边界注释的主观性。在训练视频中,“篮球扣篮”的动作通常包括有人跑向篮筐、跳跃和扣篮。然而,人类注释只是把最后一个动作看作是地面真理。在这种情况下,弱监督方法很难找到正确的人类同意的边界,从而限制了在更高IoU制度下的性能。为了更好地了解这些失败案例,我们建议读者参考我们的补充材料。
讨论 在没有稀疏性损失的情况下,STPN的大多数注意力权重仍然接近1,这使得它们对检测生成毫无用处。稀疏性损失迫使注意力模块输出更多不同的注意力权重值。然而,这种损失与视频级别前景损失相结合,鼓励模型选择预测视频级别标签所需的最小帧数。在训练过程中的某一点之后,随着稀疏度损失继续消除相关帧,定位性能开始显著恶化。这需要提前停止,以防止性能下降。相比之下,我们的模型使用自上而下的T-CAMs作为对注意力权重的自我监督形式。因此,我们的模型可以简单地训练到收敛。
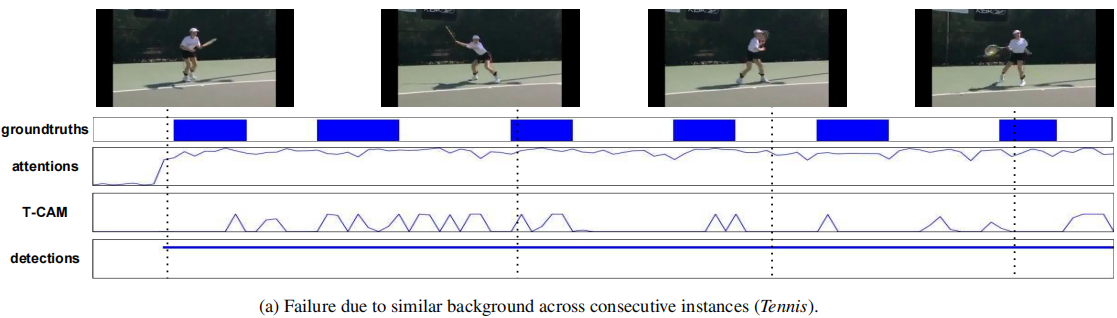

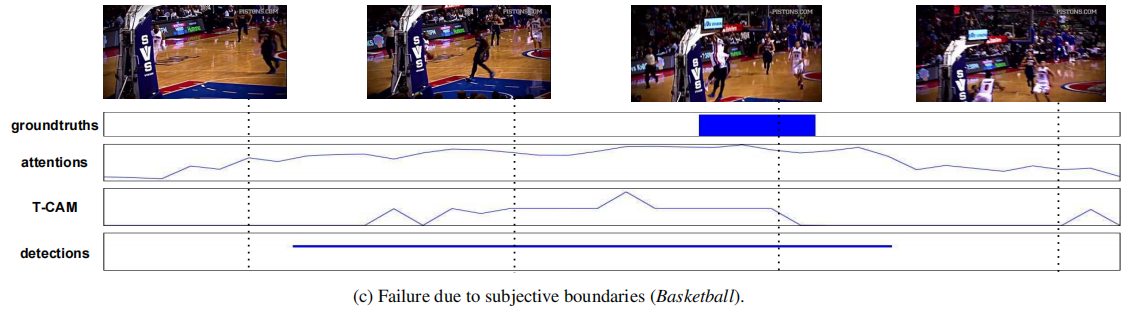
图5:仅通过视频级监督很难解决行动位置的故障案例的定性示例
5.结论
我们提出了一种从弱监督训练数据中学习动作定位的方法,其性能优于现有的方法,甚至优于一些完全监督模型。我们将这种方法的成功归因于为视频中的背景内容建立了一个明确的模型。通过将自上而下的动作模型与自底向上的聚类模型相结合,我们可以学习一个潜在的注意信号,该信号可以用于使用简单的阈值来提出动作间隔,而不需要更复杂的稀疏性或动作范围的时间先验。也许最令人兴奋的是,由此产生的模型可以利用在线收集的其他弱监督数据。尽管Instagram视频和THUMOS14之间的领域发生了变化,但我们仍然能够在许多类别中提高性能,证明了弱监督方法克服昂贵视频注释相关成本的能力。
6.补充知识
自上而下和自下而上的注意力:
参考1:自下而上的机制(基于 Faster R-CNN)提出了图像区域,每个区域都具有关联的特征向量,而自上而下的机制决定了特征权重,个人理解自上而下注意力就是利用目标检测技术(Faster R-CNN)在物体层面从面到点attention, 而自上而下注意力就是从点到面的角度进行attention
参考2:
top-down这种自上而下的注意力是由系统本身主动驱动的,这种驱动力可能来自系统自发,也有可能是来自其他任务刺激下产生的高阶信号;而bottom-down这种自下而上的注意力是由外界驱动,驱动力来自外界事物的刺激下产生的被动触发。
具体到注意力池化,作者通过矩阵的低秩近似将二阶池化作分解:
score_{attention}(X) = (Xw_{ak})^T (Xw_b)
其中,第一项与类别相关,可以看作是top-down attention;第二项与类别无关,可以看作是bottom-up attention。这样一来,二阶池化就被分解为两种注意力的乘积(交集)
参考3:
1.the bottom-up mechanism(Faster R-CNN):提取图像区域,每个图像区域由池化的卷积特征向量表示
2.the top-down mechanism:决定图像上特征向量的注意力权值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号