
Weakly-Supervised Temporal Action Localization Through Local-Global Background Modeling
0. 前言
- 相关资料:
- arxiv
- github
- 论文解读
- 论文基本信息:
- 领域:行为时空检测
- 发表时间:CVPRW 2021(2021.6)
摘要
弱监督时间动作定位(WSTAL)任务旨在识别和定位未经修剪的视频中动作示例的时间开始和结束,只有视频级别的标签监督。由于缺乏背景类别的负样本,网络很难分离前景和背景,导致检测性能较差。在本报告中,我们提出了我们的2021年HACS挑战-弱监督学习跟踪[24]解决方案,该解决方案基于BaSNet[10]来解决上述问题。具体来说,我们首先采用经过预训练的CSN[17],Slowfast[5],TDN[19],还有ViViT[1]作为特征提取器来获取特征序列。然后,我们提出的局部全局背景建模网络(LGBM-Net)只使用基于多示例学习(MIL)的视频级别标签进行训练,以定位示例。最后,我们集成多个模型,以得到最终的检测结果并在测试集上达到22.45% mAP。
1. 介绍
视频理解是计算机视觉中的一个重要领域,包括许多子研究方向,如动作识别[20,5,7]、时间动作检测[23,11,15,22]、时空动作检测[16,9]等。在本报告中,我们介绍了我们仅在视频级监督下执行时序动作检测任务的方法,称为弱监督时序动作定位(WS-TAL)。
由于弱监管的设置更符合实际需要,WS-TAL受到了越来越多的关注。最近,出现了几种方法[12,8,14,13]使用视频级标签对未修剪视频中的示例进行定位。然而,尽管这些方法取得了显著的性能,但与完全监督的方法相比仍然存在性能差异[11,15,23]。我们认为这是因为有很多前景和背景混淆。仅基于视频级别的标签来区分动作和背景是一个挑战。为了解决这个问题,我们改进了主流方法BaSNet[10],并提出了局部-全局背景建模网络(LGBM-Net),该网络集成了两个分支权重共享局部-全局子网和一个局部-全局注意模块,以抑制背景并提高动作的辨别能力。
2. 特征提取器
按照最近的WS-TAL方法[14,13],给定一个未修剪的视频V,我们首先根据预定义的采样率将其分成多个片段,然后应用预训练网络提取片段级特征。接下来,我们简要介绍我们在竞赛中使用的特征提取网络。
2.1. 通道分离卷积网络
灵感来自图像分类中2D可分离卷积显示的精度增益和良好的计算节省。Du等人[17]提出了一套视频分类体系结构——3D通道分离网络(CSN)——其中所有卷积运算被分离为点方向1×1×1或深度方向3×3×3卷积。CSN表明,只要保持较高的信道交互值,通过利用信道分离来减少触发器和参数,就可以获得良好的精度/计算成本平衡。由于其在动作识别方面的出色表现,我们使用Kinetics400[3]预训练的CSN作为我们的特征提取器之一。
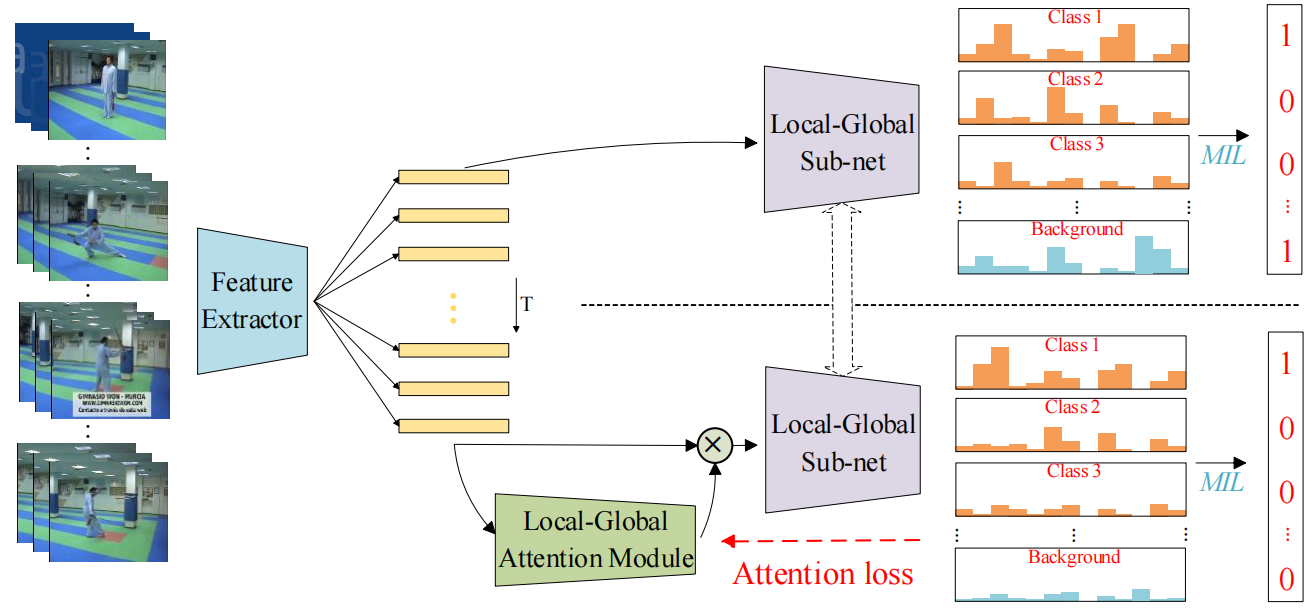
图1。局部-全局背景建模网络(LGBM-Net)的总体架构。使用预先训练的模型,我们提取输入视频的clip特征,然后将其输入两个分支。这两个分支共享局部全局子网权值,产生类激活序列(CAS)来预测视频级标签。请注意,上分支的ground-truth背景类别总是1,而下分支的ground-truth背景类别总是0。有关其他一些细节,您可以参考BaSNet[10]。
2.2. Slowfast
Slowfast[5]模型涉及两条以不同帧速率运行的路径。一条路径是用来捕获图像或几个稀疏帧所提供的语义信息,它的帧速率低,刷新速度慢。相比之下,另一条路径负责捕捉快速变化的运动,它以快速刷新速度和高时间分辨率运行。请注意,尽管它的时间频率很高,但这条路径非常轻。这是因为该路径被设计为具有较少的通道和较弱的处理空间信息的能力,而此类信息可以由第一条路径以较少冗余的方式提供。在比赛中,我们使用在Kinetics400数据集上预训练的Slowfast101和在Kinetics700[2]数据集上预训练的Slowfast152作为主干。
2.3. 时差网络
时间差分网络(TDN[19])专注于捕捉多尺度时间信息,用于动作识别。TDN的核心是通过显式地利用时间差分算子来设计有效的时间模块,并系统地评估其对短期和长期运动建模的影响。同时,采用两级差分建模方法建立TDN,充分捕捉整个视频的时间信息。具体来说,对于局部运动建模,使用连续帧上的时间差来为2D CNN提供更精细的运动模式,同时合并跨段的时间差来捕获运动特征激励的远程结构。TDN提供了一个简单且有原则的时间建模框架,被选为我们的主干。在比赛中,我们在Kinetics700数据集上预先训练了TDN。
2.4. ViViT
ViViT[1]受到transformer[18]在视觉领域[4]的大规模应用和良好效果的启发,提出使用transformer作为基本块,分别对时间和空间之间的关系进行建模。ViViT是一个纯粹的基于Transformer的动作识别模型。我们应用了ViViT-B/16x2版本和因式分解编码器,该编码器由imagenet预训练的Vit[4]初始化,然后在Kinetics700数据集上对其进行预训练。具体来说,我们使用AdamW作为优化器,并将基本学习率设置为0.0001。权重衰减设置为0.1。训练进行了2.5个阶段的热身,初始学习率为1e-6。
3. 局部-全局背景建模网络
在本节中,我们将介绍我们的局部-全局背景建模网络(LGBMNet)的生成过程,然后给出实验结果。LGBM-Net的体系结构如图1所示。
3.1局部-全局注意力模块
局部-全局注意模块的目标是通过背景类的相反训练目标来抑制背景帧/片段。局部-全局注意模块包括局部操作(Conv)和全局操作(LSTM[6])。请注意,这两个操作是并行训练的,并通过两个卷积层合并,然后是sigmoid函数。该模块的输出是前景权重,范围从0到1。同时,为了训练特定类别的注意,我们使用CAS中最高类别的激活来监督局部-全局注意模块中的注意输出。
3.2. 局部-全局子网
局部-全局子网用于生成CAS,可用于预测分段级别的班级分数。与local-global attention模块一样,Local-global subnet也包含Local operation(Conv)和global operation(LSTM)。请注意,我们还尝试了其他全局操作(例如,非局部[21]和全局池化)来实现最终的集成。之后,我们汇总段级类分数,得出视频级类分数。在这里,我们采用top-k平均技术进行训练。
3.3. 检测结果
在得到CAS后,我们可以使用分水岭算法来获得检测结果。注意,由于分离了前景和背景,我们只使用图1中较低分支的CAS来生成检测结果。
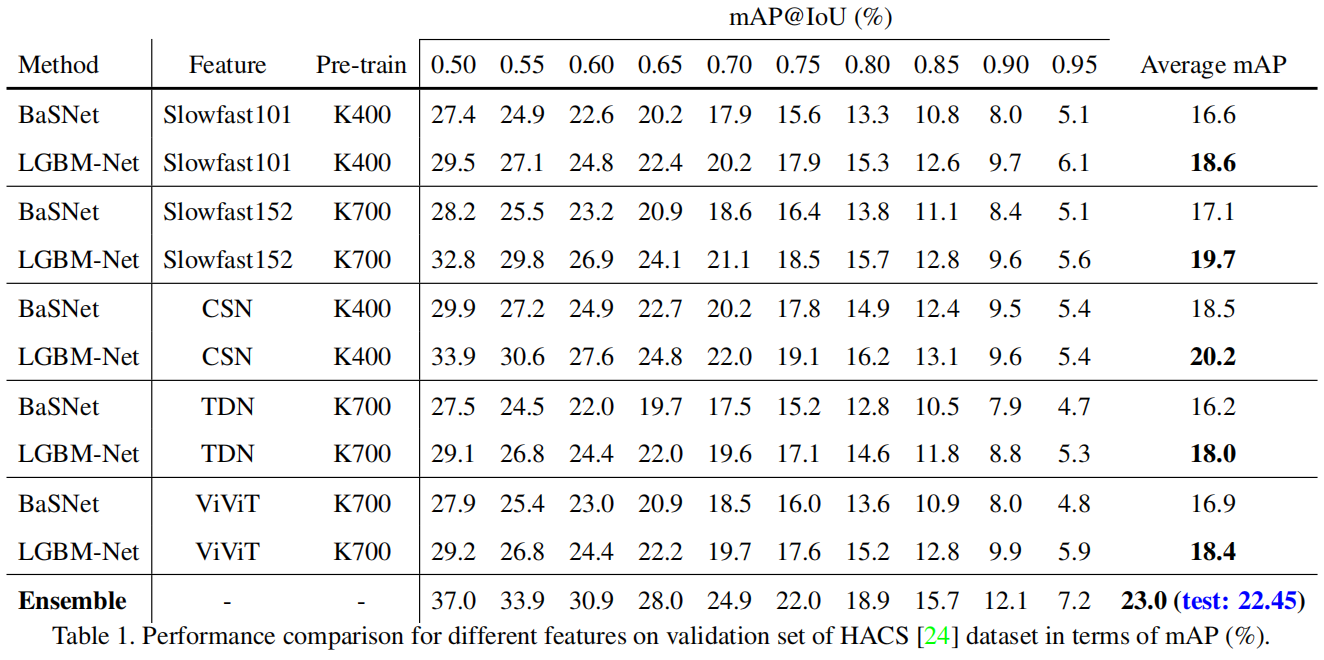
从表1中,我们可以得出以下结论:(1) 从Slowfast101和Slowfast152的结果可以看出,大规模的预训练和更深层次的模型在提高表现方面发挥了巨大作用。(2) 基于Transformer的方法(ViViT)通常比CNN方法(例如CSN和Slowfast)的检测性能稍差。(3) 从集成结果可以看出,模型之间存在互补性。
4. 结论
在本报告中,我们提出了LGBM网络,它基于BaSNet,能够很好地分离前景和背景。我们对多个特征(例如CSN、Slowfast、TDN和ViViT)进行了实验,以证明LGBM网络的有效性。特别是,通过集成策略,可以进一步提高检测性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号