
Weakly-supervised Temporal Action Localization by Uncertainty Modeling
摘要
弱监督时间动作定位旨在学习仅使用视频级别标签检测动作类的时间间隔。为此,将动作类的帧与背景帧(即不属于任何动作类的帧)分离是至关重要的。在本文中,我们对背景帧提出了一种新的观点,在这种背景帧中,由于背景帧的不一致性,背景帧被建模为分布外样本。然后,可以通过估计每个帧来自外分布的概率(称为不确定性)来检测背景帧,但如果没有帧级标签,直接学习不确定性是不可行的。为了在弱监督环境下实现不确定性学习,我们利用了多示例学习公式。此外,我们还引入了背景熵损失,通过鼓励背景帧的分布内(动作)概率在所有动作类中均匀分布,从而更好地区分背景帧。实验结果表明,我们的不确定性建模在消除背景帧干扰方面是有效的,并且在without bells and whistles的情况下带来了很大的性能增益。我们证明,我们的模型在THUMOS'14和ActivityNet(1.2和1.3)基准上的表现明显优于最先进的方法。
1导言
时间动作定位(TAL)是在未修建视频中寻找和分类动作间隔的一个非常具有挑战性的问题,在视频理解和分析中起着重要动作。为了解决这个问题,许多工作都是在完全监督的方式下完成的,并取得了令人印象深刻的进展。然而,它们在获取精确注释(即标记每个动作示例的开始和结束时间戳)方面的成本非常高。
为了缓解高成本问题并扩大可扩展性,研究人员将注意力集中在具有弱监督的同一任务上,即弱监督时间动作定位(WTAL)。在各级弱监督中,由于成本低廉,视频级别的动作标签被广泛使用(Wang等人,2017)。在此设置中,对于动作类,如果视频包含相应的动作帧,则将其标记为正,否则将其标记为负。请注意,一个视频可能有多个动作类作为其标签。

图1:建模背景的挑战:动态性和不一致性。(a) 红色框中显示足球运动员庆祝的背景帧非常具有动态醒。(b) 背景帧不一致。绿色框中的画面显示有字幕的空白场景,蓝色框中的画面显示一名高尔夫球手准备投篮。这两种类型的外观和语义并不一致。
现有方法通常将WTAL视为逐帧分类,并采用注意力机制(Nguyen et al.2018)或多示例学习(Paul、Roy和RoyChowdhury 2018)从视频级别标签中学习。尽管如此,与完全监督的相似方法相比,他们的表现仍然非常差。根据文献(Xu et al.2019),性能下降主要来自背景帧的错误提示,因为视频级别标签没有任何背景线索。为了弥补这一差距,出现了几项研究试图以弱监督的方式进行显式背景建模。Liu等人(Liu、Jiang和Wang 2019)合并静态帧来合成伪背景视频,但他们忽略了动态背景帧(图1a)。与此同时,一些作品(Nguyen、Ramanan和Forkes 2019;Lee、Uh和Byun 2020)试图将背景帧分类为单独的类别。然而,强制所有背景帧属于一个特定类是不可取的,因为它们不共享任何公共语义(图1b)。
在本文中,我们接受了对背景帧不一致性的观察,并建议将其表述为分布外样本(Liang、Li和Srikant 2018;Dhamija、Gunther和Boult–2018)。通过估计每个样本来自分布外的概率,也就是不确定性(Bendale和Boult 2016;Lakshminarayanan、Pritzel和Blundell 2017)可以识别它们。为了建模不确定性,我们建议利用嵌入特征向量的大小。通常,与背景帧的特征相比,动作帧具有更大的特征量,如图2a所示。这是因为动作帧需要为ground-truth动作类生成较高的logits。虽然特征量与背景和动作帧之间的区分有相关性,但由于动作和背景的分布非常接近,直接使用特征量进行区分是不够的。因此,为了进一步鼓励特征大小的差异,我们建议通过扩大动作特征的大小和减少背景特征的大小到接近零的来分离分布(图2b)。
为了仅通过视频级监督来学习不确定性,我们利用了多示例学习的公式(Maron和Lozano Perez’1998;Zhou 2004),其中模型使用bag(即未剪辑的视频)而不是示例(即帧)进行训练。具体而言,从每个未裁剪的视频,我们选择top-k和bottom-k特征量,并分别考虑它们作为伪动作和背景帧。此后,我们设计了一个不确定性建模损失来分离它们的大小,通过该模型,我们的模型能够在没有帧级标签的情况下间接建模不确定性,并在动作帧和背景帧之间提供更好的分离。此外,我们还引入了背景熵损失,以迫使伪背景帧在动作类上具有一致的概率分布。这可以防止他们倾向于某个动作类,并通过最大化它们的动作类分布熵来帮助实现这一点。为了验证我们的方法的有效性,我们在两个标准基准THUMOS'14和ActivityNet上进行了实验。通过联合优化建议的损失和一般的动作分类损失,我们的模型成功地区分了动作帧和背景帧。此外,我们的方法在两个基准上都取得了最新的性能。
我们的贡献有三个方面:1)我们提出将背景帧描述为分布外样本,克服了由于背景不一致而难以建模的困难。2) 我们设计了一个新的弱监督动作定位框架,通过多示例学习,仅使用视频级别的标签对不确定性进行建模和学习。3) 我们使用一个损失进一步鼓励在动作和背景之间进行分离,该损失使背景帧的动作概率分布熵最大化。
2.相关工作
完全监督的动作定位。时间动作定位的目标是从长时间未经剪辑的视频中找到动作示例的时间间隔,并对其进行分类。
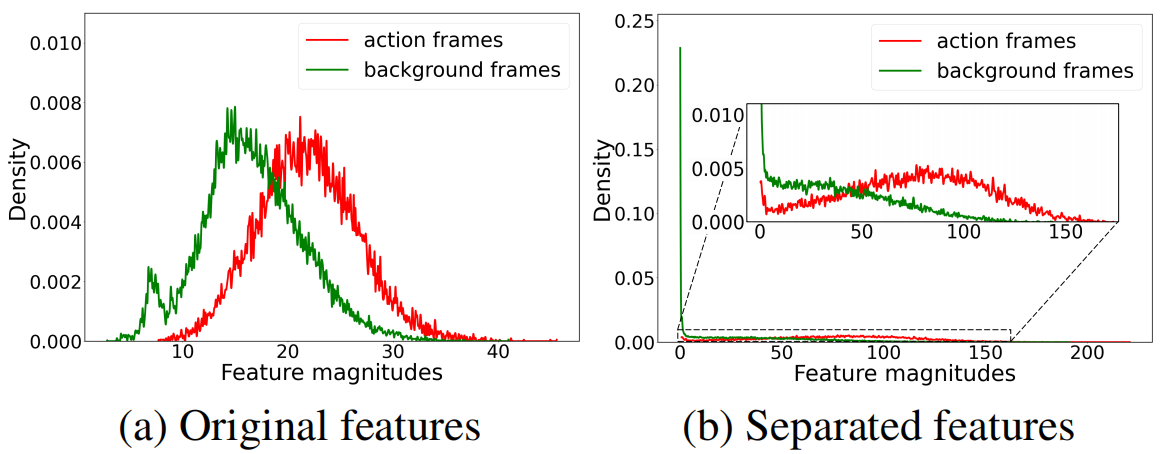
图2:特征量的归一化直方图。(a) 原始特征的大小与动作/背景相关,但两个分布的中心很近。(b) 该方法分离出的特征量具有更好的动作和背景区分能力。
对于该任务,许多方法依赖于每个训练视频的精确时间注释。其中大多数采用两阶段方法,即首先生成建议,然后对其进行分类。为了产生建议,早期的方法采用滑动窗口技术(寿、王和昌2016;袁等人2016;寿等人2017;杨等人2018;熊等人2017;赵等人2018),而最近的模型预测行动的开始和结束帧(林等人2018、2019、2020)。同时,也出现了一些利用图形结构信息的尝试(Zeng et al.2019;Xu et al.2020)。此外,还有每个动作示例的高斯建模(Long等人,2019年)和一种无需建议生成步骤的有效方法(Alwassel、Caba Heilbron和Ghanem 2018年)。
弱监督动作定位。近年来,许多人试图解决弱监督时间动作定位问题,主要是视频级别的标签。(Wang et al.2017)首先通过soft和hard两种方式选择相关片段来解决这个问题。(Nguyen等人,2018年)提出稀疏正则化,而(Singh和Lee,2017年)和(Yuan等人,2019年)扩展了小的区分部分。(Paul、Roy和Roy Chowdhury 2018),(Narayan et al.2019)和(Min和Corso 2020)采用深度度量学习,迫使同一动作的特征比不同类别的特征更接近自己。(Shi等人,2020年)和(Luo等人,2020年)分别使用可变自动编码器和期望最大化策略学习注意力权重。(翟等人,2020年)追求不同模式之间的共性。同时,(Shou et al.2018)和(Liu et al.2019)试图回归动作示例的间隔,而不是执行硬阈值。最近,(Ma等人,2020年)提议开发中间级别的监督(即单帧监督)。
除上述方法外,一些工作(刘江和王2019;阮、拉马南和福尔克斯2019;李、嗯和尹2020)试图明确模拟背景。然而,如上所述,它们有先天的局限性,背景帧可能是动态的,不一致的。相反,我们认为背景属于分布外,并建议学习不确定性,以及行动类分数。在sec.4验证了我们方法的有效性。
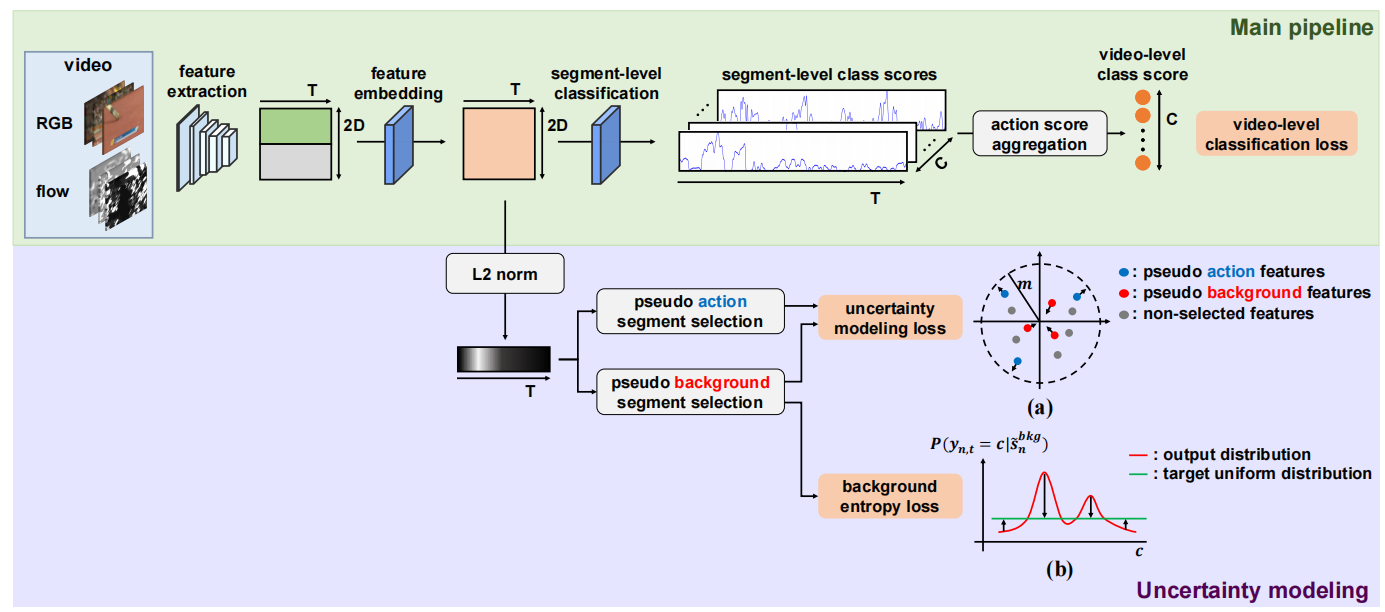
图3:所提出的方法的概述。主流程采用弱监督动作定位的标准过程。我们通过建模不确定性,即分布外的概率来区分背景帧和动作帧的概率。在不确定性建模部分,根据特征大小选择伪动作/背景段,反过来推导出两个提出的背景识别损失:(a)不确定性建模损失,分别增大和减少了伪动作段和背景段的特征大小;和(b)背景熵损失迫使伪背景段具有均匀的动作概率分布。
3.方法
在本节中,我们首先为弱监督的时间动作定位建立基线网络(第3.1节)。此后,我们将识别背景帧的问题归结为分布外检测,并通过建模不确定性来解决它(第3.2节)。最后,阐述了训练我们模型的目标函数(第3.3节)以及如何进行推理(第3.4节)。我们的方法概述如图3所示。
3.1主流程
特征抽取。由于内存限制,我们将每个视频分割为多帧段,即vn={sn,l}Lnl=1,其中Ln表示vn中的段数。为了处理视频长度的巨大变化,从每个原始视频中采样固定数量的T段![]() 。从采样的RGB和光流段中,分别用预训练的特征提取器提取时空特征xRGBn,t∈RD和xflown,t∈RD。接下来,我们将RGB和流特征连接到完整的特征向量xn,t∈R2D中,然后将其堆叠构建长度为T的特征图,即Xn=[xn,1,...,xn,T]∈R2D×T。
。从采样的RGB和光流段中,分别用预训练的特征提取器提取时空特征xRGBn,t∈RD和xflown,t∈RD。接下来,我们将RGB和流特征连接到完整的特征向量xn,t∈R2D中,然后将其堆叠构建长度为T的特征图,即Xn=[xn,1,...,xn,T]∈R2D×T。
特征嵌入。为了将提取的特征嵌入到特定任务的空间中,我们采用了一个一维卷积层,然后是一个ReLU函数。形式上,![]() ,其中,gembed表示具有激活函数的卷积算子,φembed是该层的可训练参数。具体地说,嵌入特征的维数与输入特征的维数相同,即Fn=[fn,1,...,fn,T]∈R2D×T。
,其中,gembed表示具有激活函数的卷积算子,φembed是该层的可训练参数。具体地说,嵌入特征的维数与输入特征的维数相同,即Fn=[fn,1,...,fn,T]∈R2D×T。
段级分类。从嵌入的特征中,我们预测了段级类分数,这将被用于动作定位。给定特征Fn,段级类分数由动作分类器得到,即An=gcls(Fn;φcls),其中gcls表示具有参数φcls的线性分类器。具体来说,An∈RC×T,其中C是动作类的数量。
行动得分汇总。在之前的工作(Paul、Roy和Roy Chowdhury 2018)之后,我们汇总了每个动作类的所有片段的前Kact个分数,并对其进行平均,以构建视频级原始类分数:
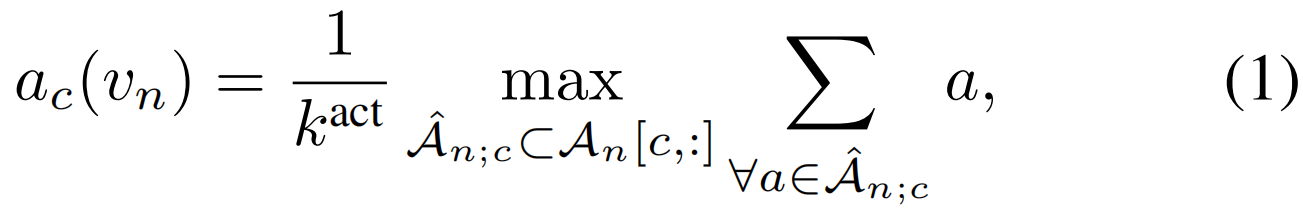
其中![]() 是包含第c类kact个动作分数的子集(即
是包含第c类kact个动作分数的子集(即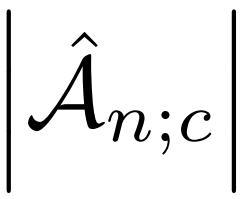 =Kact),kact是控制聚合段数量的超参数。然后,我们将softmax函数应用于聚合分数,得到每个动作类的视频级动作概率:
=Kact),kact是控制聚合段数量的超参数。然后,我们将softmax函数应用于聚合分数,得到每个动作类的视频级动作概率:
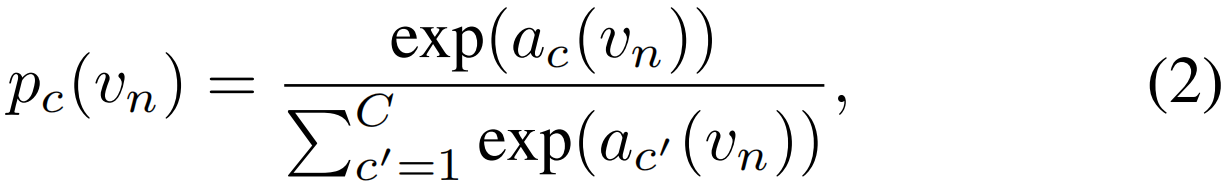
其中,pc(vn)表示vn的第c个动作的softmax分数,它是由视频级的弱标签指导的。
3.2不确定性建模
从主流程中,我们可以获得每个片段的动作概率,但没有仔细考虑动作定位的基本组成部分,即背景识别。考虑到背景帧的无约束性和不一致性,我们将背景视为分布外(Hendrycks和Gimpel 2017)并且为WTAL建模不确定性(成为背景的概率)。
考虑段![]() 属于第c个动作的概率,可以用一系列规则分解为两部分,即分布内动作概率和不确定性。设d∈{0,1}表示背景识别的变量,即如果该段属于任何动作类,则d=1,否则d=0(属于背景)。然后,
属于第c个动作的概率,可以用一系列规则分解为两部分,即分布内动作概率和不确定性。设d∈{0,1}表示背景识别的变量,即如果该段属于任何动作类,则d=1,否则d=0(属于背景)。然后,![]() 的c类的后验概率为:
的c类的后验概率为:
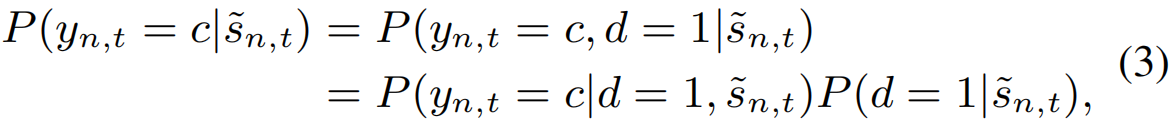
其中yn,t为段的标签,即如果![]() 属于第c个动作类,则yn,t=c,若yn,t=0则为背景段。为了提高可读性,我们描述了单标签的情况。不失一般性,这可以推广到多标签。
属于第c个动作类,则yn,t=c,若yn,t=0则为背景段。为了提高可读性,我们描述了单标签的情况。不失一般性,这可以推广到多标签。
在等式3中,与一般分类任务一样,使用softmax函数估计分布内行动分类的概率P(yn,t=c|d=1,![]() )。此外,有必要对一个片段属于任何动作类的概率进行建模,即P(d=1|
)。此外,有必要对一个片段属于任何动作类的概率进行建模,即P(d=1|![]() ),以解决背景区分问题。观察到动作帧通常比背景帧具有更大的特征量(图2),我们通过使用特征向量的大小来表示不确定性。具体来说,背景特征的小值接近于0,而动作特征的大值很大。那么第n个视频中的第t段(
),以解决背景区分问题。观察到动作帧通常比背景帧具有更大的特征量(图2),我们通过使用特征向量的大小来表示不确定性。具体来说,背景特征的小值接近于0,而动作特征的大值很大。那么第n个视频中的第t段(![]() )是一个动作段的概率定义为:
)是一个动作段的概率定义为:
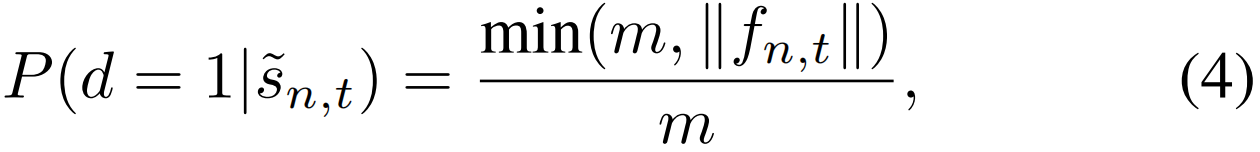
其中fn,t是![]() 对应的特征向量,||·||是一个范数函数(我们在这里使用L-2范数),m是预定义的最大特征量。从公式可以看出,保证概率在0到1之间,即0≤P(d=1|
对应的特征向量,||·||是一个范数函数(我们在这里使用L-2范数),m是预定义的最大特征量。从公式可以看出,保证概率在0到1之间,即0≤P(d=1|![]() )≤1。
)≤1。
为了只用视频级别的标签来学习不确定性,我们借用了多示例学习的概念(Maron和LozanoP‘erez1998),其中一个模型是用一个包(视频)而不是示例(片段)来训练的。在这个设置中,考虑到每个未修剪的视频同时包含动作帧和背景帧,我们选择了代表视频的伪动作/背景片段。具体地说,特征大小的前kact个动作段被视为伪动作段{![]() |i∈Sact},其中Sact表示伪动作集合。同时,将后kbkg段看作是伪背景段{
|i∈Sact},其中Sact表示伪动作集合。同时,将后kbkg段看作是伪背景段{![]() |j∈Sbkg},其中Sbkg表示伪背景集合。kact和kbkg分别表示为动作和背景采样的片段数。然后,伪动作/背景片段作为输入未剪辑视频的特征表示,并通过多示例学习用于训练。
|j∈Sbkg},其中Sbkg表示伪背景集合。kact和kbkg分别表示为动作和背景采样的片段数。然后,伪动作/背景片段作为输入未剪辑视频的特征表示,并通过多示例学习用于训练。
3.3训练目标
我们的模型联合优化了三个损失:1)视频级分类损失Lcls用于每个输入视频的动作分类,2)不确定性建模损失Lum用于分离动作和背景特征向量的大小,3)背景熵损失Lb,迫使背景片段对动作类具有统一的概率分布。总损失函数如下所示:
![]()
其中,α和β是平衡超参数。
视频级别分类损失。对于多标签动作分类,我们使用归一化视频级标签的二进制交叉熵损失(Wang等人,2017),如下所示:
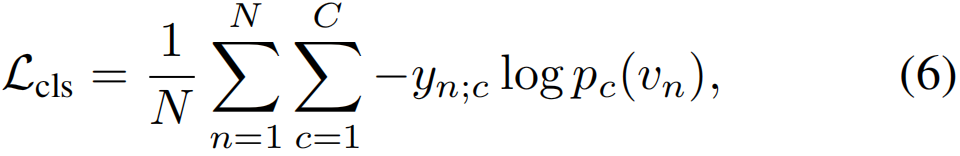
其中,pc(vn)表示第n个视频的第c类的视频级softmax分数(等式2),yn;c是第n个视频的第c类的归一化视频级标签。
不确定性建模损失。为了了解不确定性,我们训练模型为伪动作片段生成较大的特征量,但为伪背景片段生成较小的特征量,如图3(a)所示。形式上,不确定性建模损失的形式如下:
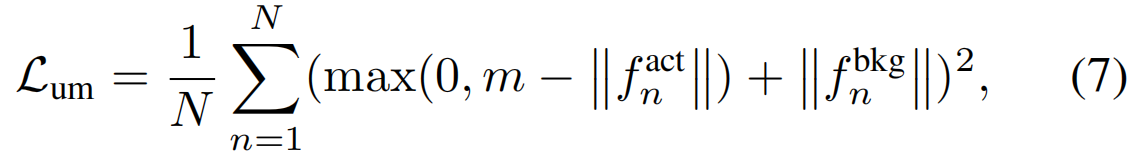
其中,![]() 和
和![]() 分别是第n个视频的伪动作和背景片段的平均特征。||·||为范数,m为预定义的最大特征大小,与等式4中相同 。
分别是第n个视频的伪动作和背景片段的平均特征。||·||为范数,m为预定义的最大特征大小,与等式4中相同 。
背景熵损失。尽管不确定性建模损失鼓励背景片段为所有动作生成较低的Logits,但由于softmax函数的相对性,某些动作类别的softmax分数可能较高。为了防止背景片段对任何动作类具有较高的softmax分数,我们定义了一个损失函数,该函数使背景片段的动作概率熵最大化,即,如图3(b)所述,背景片段被鼓励对动作类具有均匀的概率分布。损失计算如下:
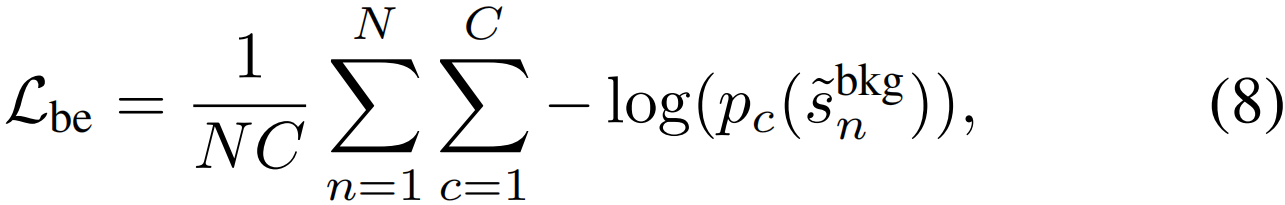
其中,![]() 是第c类伪背景段的平均动作概率,pc(
是第c类伪背景段的平均动作概率,pc(![]() )是
)是![]() 的c类的softmax分数。
的c类的softmax分数。
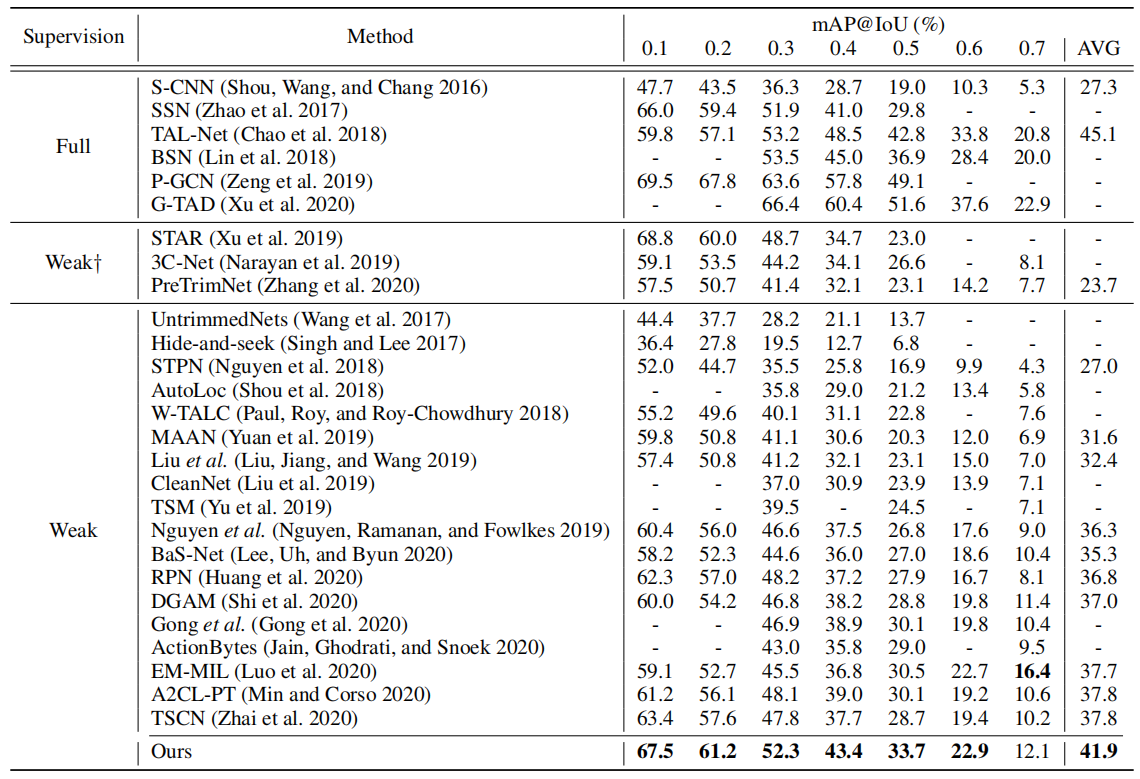
表1:在THUMOS'14上的比较。AVG是在阈值0.1:0.1:0.7下的平均mAP,同时†表示额外信息的使用,如动作频率或人体姿势。
3.4推论
在测试时,对于一个输入的视频,我们首先获取视频层的softmax分数并在分数上应用阈值θvid,以确定哪些动作类需要定位。对于其余的动作类,我们通过将分段级softmax分数与该片段是动作段的概率相乘来计算分段后验概率,见等式3.然后,选择后验概率大于θseg的片段作为候选段。最后,将连续的候选片段分组为一个建议,其得分计算采用(Liu、Jiang和Wang2019)中提出的方法。为了丰富建议池,我们对θseg使用多个阈值,并对重叠的建议执行非最大抑制(NMS)。
4个实验
4.1实验设置
数据集。THUMOS'14(Jiang等人,2014)是一个广泛使用的时间动作定位数据集,包含20个动作类的200个验证视频和213个测试视频。这是一个非常具有挑战性的基准,因为视频的长度多种多样,动作频繁发生(平均每个视频15个示例)。在前面的工作之后,我们使用验证视频进行训练,使用测试视频进行测试。另一方面,ActivityNet(Caba Heilbron et al.2015)是一个具有两个版本的大型基准测试。ActivityNet 1.3由200个行动类别组成,包括10024个训练视频、4926个验证视频和5044个测试视频。ActivityNet 1.2是1.3版的一个子集,由4819个训练视频、2383个验证视频和2480个100个动作类的测试视频组成。由于ActivityNet测试视频的ground-truth在竞赛中被保留,我们使用验证视频进行评估。
评估指标。我们在几个不同的联合交集(IoU)阈值下使用平均精度(MAP)来评估我们的方法,这是时间动作定位的标准评估指标。活动网的官方评估代码用于测量。
实施细节。作为特征提取器,我们采用了基于Kinetics(Carreira和Zisserman 2017)预训练的I3D网络(Carreira和Zisserman 2017),该网络采用16帧的输入段。应该注意的是,我们并没有为了公平比较而微调特征提取器。TVL1算法(Wedel等人,2009)用于从视频中提取光流。我们将THUMOS'14和ActivityNet的段数T分别固定为750和50。
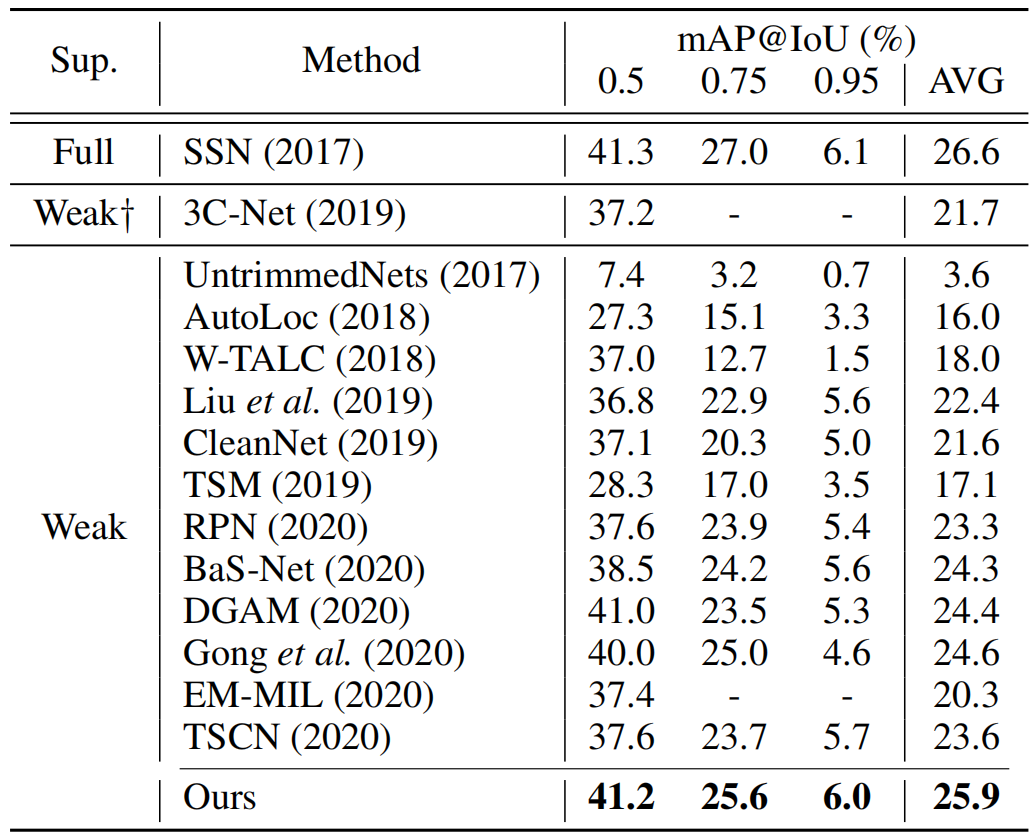
表2:ActivityNet 1.2的结果。AVG是阈值为0.5:0.05:0.95时的平均mAP,而†表示使用动作计数。
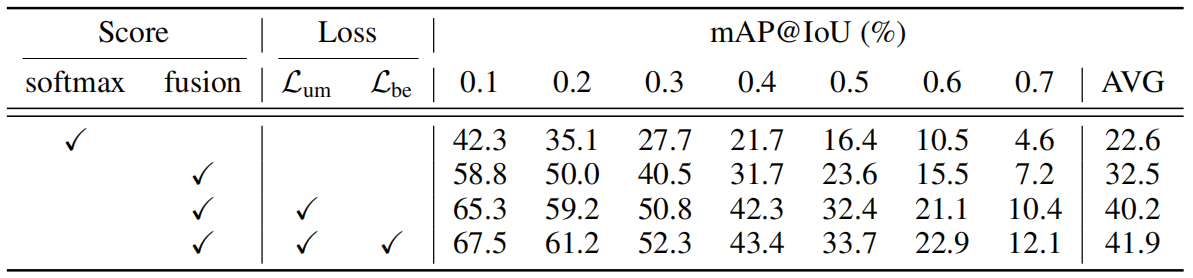
表3:THUMOS'14的消融研究。平均值代表IoU阈值0.1:0.1:0.7时的平均图。“分数”表示计算最终分数的方式。为了得出最终分数,softmax方法使用分段级softmax分数,而融合方法将分段级softmax分数和不确定性进行融合,如等式3所示。
采样方法与STPN相同(Nguyen等人,2018年)。伪动作/背景帧的数量由比值参数决定,即kact=T/ract和kbkg=T/rbkg。所有超参数都通过网格搜索设置;m=100,ract=9,rbkg=4、α=5×10−4、β=1和θvid=0.2。使用步长为0.025的从0到0.25的多个阈值作为θseg,然后我们执行IoU阈值为0.6的非最大抑制(NMS)。
4.2与最先进方法的比较
在几个IoU阈值下,我们将我们的方法与现有的完全监督和弱监督方法进行了比较。我们根据监督级别用横线分隔条目。为了便于阅读,所有结果都以百分比为单位进行报告。
表1展示了THUMOS'14的结果。如图所示,我们的方法在弱监督的时间动作定位上取得了新的最先进的性能。值得注意的是,我们的方法明显优于现有的背景建模方法,刘等人(刘、江和王2019年)、阮等人(阮、拉马南和福克斯2019年)和BaS-Net(李、呃和Byun 2020年),在平均mAP上分别大幅度提高了9.5%、5.6%和6.6%。这证实了我们的不确定性建模的有效性,此外,由于监督水平低得多,我们的方法优于几种完全监督的方法,遵循最新的方法,差距最小。
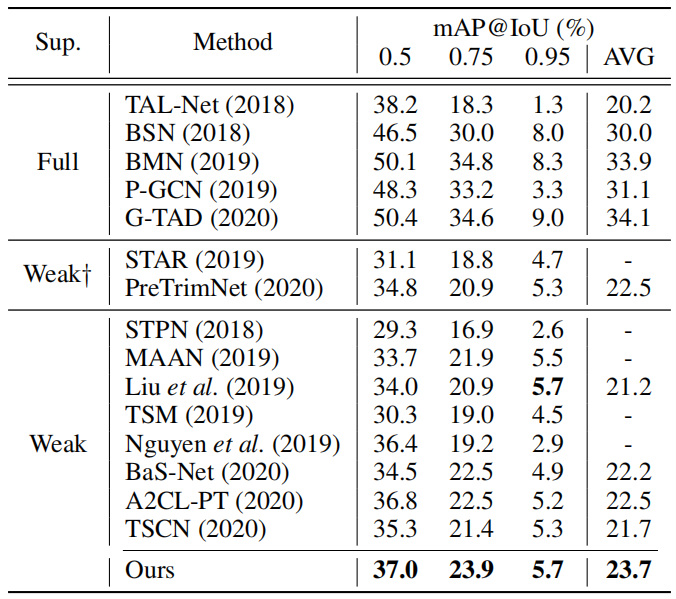
表4:ActivityNet 1.3上的比较†表示使用外部数据,平均值是阈值0.5:0.05:0.95下的平均mAP。

表5:对THUMOS‘14上的最大特征大小m的分析。我们报告了IoU阈值0.1:0.1:0.7下的平均mAPs,变量m从10到250取值。
ActivityNet 1.2上的性能如表2所示。与THUMOS'14的结果一致,我们的方法明显优于所有弱监督方法,紧随SSN(Zhao et al.2017)之后,差距小于1%。我们还在表4中总结了ActivityNet 1.3的结果。我们发现,我们的方法优于现有的弱监督方法,包括那些使用外部信息的方法。此外,我们的方法在平均mAP方面比监督方法TAL-Net(Chao等人,2018)表现更好,证明了弱监督动作定位的潜力。
4.3消融研究
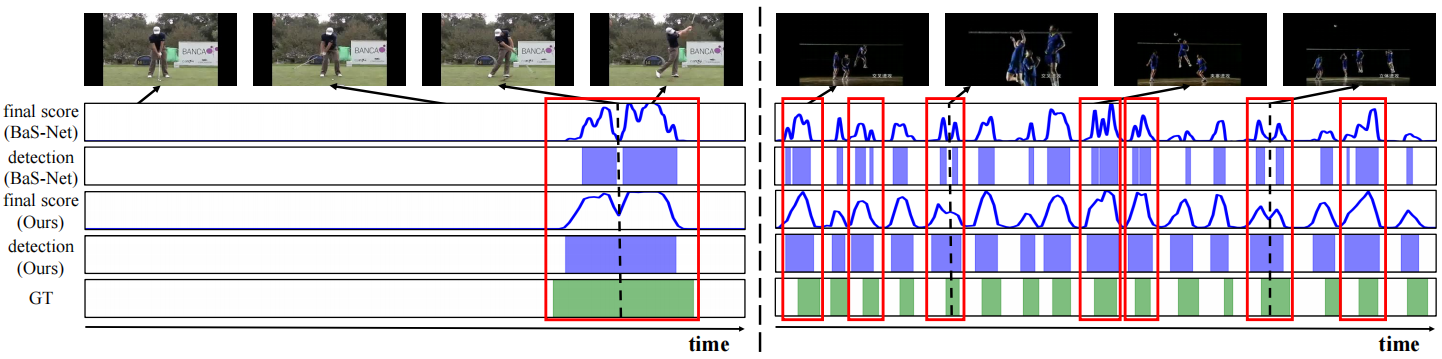
图4:与THUMOS的BaS-Net(Lee、Uh和Byun2020)进行14的定性比较。我们提供了两种不同的例子:(1)是高尔夫的稀疏动作,(2)是排球的频繁动作。每个例子都有五个带有采样帧的图。第一个和第二个图分别显示了BaS-Net对应的动作类的最终得分和检测结果,而第三个和第四个图分别代表了我们的方法。最后一个情节是ground-truth的动作间隔。每个图中的横轴表示视频的时间步长,而纵轴表示从0到1的评分值。在红框中,虽然BaS-Net不能覆盖完整的动作示例,并将它们分割成多个检测结果,但我们的方法精确地定位了它们。黑色虚线表示被BaS-Net错误分类但被我们的方法检测到的动作帧。
损失部分和分数计算的影响。在表3中,我们调查了每个部分对THUMOS'14的贡献。首先,将基线设置为仅具有视频级别分类损失(L)的主流程。我们尝试了两种基线得分计算方法:(1)softmax和(2)softmax与不确定性的融合(如等式3)。对于第二种情况,由于原始特征量是不受约束的,因此不适合使用公式4。取而代之的是,我们对特征量进行最小-最大归一化,以估计某个片段处于分布状态的概率。令人惊讶的是,融合方法使得平均mAP提升了9.9%,因为背景片段的相对较低量级抵消了它们的softmax分数,减少了假阳性。这证实了特征大小和动作/背景片段之间的相关性,以及背景建模的重要性。随后,添加建议的损失,即不确定性建模损失(L)和背景熵损失(L)。我们注意到,背景熵损失不能单独存在,因为它是用基于不确定性选择的伪背景段计算的。因此,不确定性建模将平均mAP的性能提升到40.2%,这已经是新的SOTA。此外,背景熵损失进一步提高了性能,扩大了与现有方法的差距。
对最大特征幅度m的分析。在等式4中的最大特征大小m决定了动作帧和背景帧的特征大小的差异化程度。我们研究了表5中最大特征大小m的影响,其中m从10改变到250。我们注意到,当m足够大时,性能差异不显著。同时,若是m过小,由于动作与背景的分离不足,性能会下降。
4.4定性结果
为了确认我们的背景建模的优越性,我们定性地将我们的方法与使用背景类的BaS Net(Lee,Uh,and Byun 2020)进行了比较。图4显示了THUMOS'14的两个例子:稀疏和频繁动作案例。在这两种情况下,我们看到我们的模型更精确地检测动作示例。更具体地说,在红色框中,可以注意到BaSNet将一个动作示例拆分为多个未完成检测结果。我们推测,这个问题是因为BaS Net强烈要求不一致的背景帧属于一个类,这使得模型错误地将动作示例中令人困惑的部分归类为背景类(见黑色虚线)。相反,我们的模型通过不确定性建模而不是使用单独的类,在动作和背景之间提供了更好的分离。因此,我们的模型成功地定位了完整的动作示例,而没有拆分它们。
5结论
在这项工作中,我们发现了现有背景建模方法的固有局限性,并观察到背景帧可能是动态的和不一致的。然后,基于它们的不一致性,我们提出将背景帧表示为分布外样本,并用特征量对不确定性进行建模。为了训练模型在没有帧级标注的情况下识别背景帧,我们设计了一种新的体系结构,通过多示例学习来学习不确定性。此外,还引入了背景熵损失,以防止背景片段倾向于任何特定的动作类别。消融实验证实,我们的不确定性建模和背景熵损失都有利于定位性能。通过在两个最流行的基准测试——THUMOS'14和ActivityNet上的实验,我们的方法在弱监督时间动作定位方面取得了很大的进步。我们相信,在完全监督的环境或其他相关任务中采用分布外的背景公式将是一个有希望的未来方向。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号