
Asynchronous Interaction Aggregation for Action Detection
0. 前言(网上相关资料不少,这里直接进行借鉴(概括,翻译))
1. 要解决的问题
- 用于解决时空行为检测(spatial-temporal action detection)问题,该类问题是行为识别的升级版,感觉是在检测+跟踪的基础上进行行为识别。
- 现在在行为识别,或者说在时空行为检测领域又多了一类研究,主要是研究人与人、人与物之间的相关关系(interaction)。这类研究其实还比较少,所以也存在比较多问题:
- 之前的研究主要着重研究某一类相互作用(如人与物之间的相互关系)
- long-term temporal interaction很难寻找。通过3D卷积很难做到这一点,也有方法要保存长期的特征信息,但这非常消耗资源。
- 之前的方法中,为了检测行为时只用了 cropped features,其他信息都去掉了。
2.主要贡献
本文将Interaction分为三类Person-Person Interaction:人与人之间的相互关系,如听。Person-Object Interaction:人与物之间的相互关系,如拿着物品。Temporal Interaction:有较大时间相关性的事件,如开、关门。
提出了一个新的框架Asynchronous Interaction Aggregation network(AIA),即异步交互聚合网络,它探索了三种交互(人-人、人-物和时间交互),几乎涵盖了视频中所有类型的人-语义交互。该网络主要有两种设计:交互聚合(IA)结构和异步记忆更新(AMU)算法。
IA结构集成了多种人-语义交互以实现鲁棒的动作检测,它探索并整合了所有三种类型的交互在一个深层结构中。更具体地说,它由多个元素的交互块组成,每个元素交互块通过一种交互类型增强目标特征。这三种类型的交互块沿着IA结构的深度嵌套,一个块可以使用先前交互块的结果。因此,IA结构能够使用不同类型的信息精确地对交互进行建模。
AMU算法估计训练过程中的难处理特征,用来缓解时间交互建模中计算量大和内存消耗大的问题。采用类记忆结构来存储空间特征,并提出了一系列的写-读算法来更新内存中的内容:每次迭代时从目标片段中提取的特征被写入记忆池,然后在后续迭代中进行检索,从而对时间交互进行建模。这种有效的策略使我们能够端到端地训练整个网络,并且计算复杂度不会随着时间记忆特征长度的增加而线性增加。与先前预先提取特征的解决方案相比,AMU简单得多,并且获得更好的性能。
3. 具体实现
总体工作流程。
a. Feature Extractor
有一个独立于AIA的Detector,用于检测人和物体,即图中红色的 Detector。通过该Detector,将原始数据中的人和物体都标定出来。
通过 Video Model 提取视频数据的特征,看源码应该是通过 slowfast 提取的。
Detector 提取的人/物的 bbox 在 Video Model 得到的特征图上做ROI操作,得到每个人/物的特征。
b. Interaction Aggregation
该模块主要就是通过 IA structure 融合各类intaraction的信息。
IA structure 输入共三类:当前图像中人的特征、当前图像中物的特征、Feature Pool(即历史图像中)中人的特征。
IA structure 的输出就是更新后的人特征。
此时的特征融合了周围其他人的特征、历史特征、物体特征。
通过融合后的特征进行简单的分类,判断人的行为。
c. Asynchronous Memory Update
该模块的主要作用就是按照一定的方法保存历史数据,从而实现 long-term 的行为识别。
主要解决的问题是:随着时间增加,特征尽量不丢失,且总体积不增加。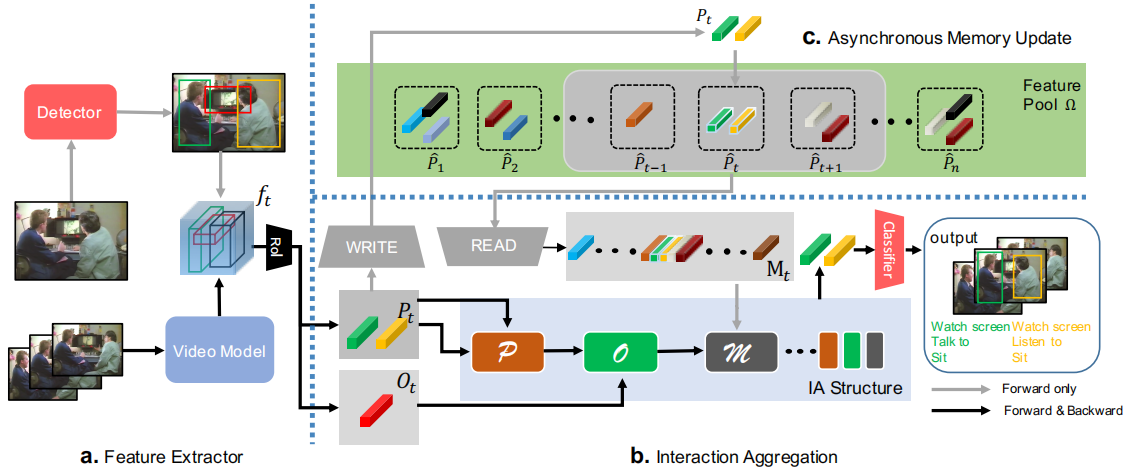
图2:AIA流程。a. 我们从提取的视频特征中裁剪人物和对象的特征。 b.将c中的特征池Ω中人的特征、对象特征和内存特征输入IA,以集成多个交互。IA的输出被传递给最终的分类器以进行预测。 c.我们的AMU算法从特征池中读取内存特征,并将新的人的特征写入其中
3.1 实例级和时间记忆特征
为了在视频中建立交互模型,我们需要正确地找到被查询的人与什么交互。以前的工作如[36]计算特征图中所有像素之间的交互作用。由于计算量大,这些暴力方法使用视频数据集的大小有限,难以学习像素之间的交互。因此,我们开始考虑如何获得集中的交互特征。我们观察到人总是与具体的物体和其他人互动,因此我们提取对象和人作为实例级特征。另外,视频帧之间总是高度相关的,因此我们保留了人的特征作为长期时间记忆特征。
实例级特征将从视频特征中截取。由于计算整个长视频是不可能的,所以我们将其分割为连续的短视频片段![]() ,利用视频骨干模型
,利用视频骨干模型![]() 提取第t个视频片段vt的d维特征,其中
提取第t个视频片段vt的d维特征,其中![]() 为参数。在vt的中间帧上应用检测器得到人员框和物体框。在检测到的边界框的基础上,利用RoIAlign算法从特征ft中裁剪出人和物体的特征,vt中人和物体的实例级特征分别表示为Pt和Ot。
为参数。在vt的中间帧上应用检测器得到人员框和物体框。在检测到的边界框的基础上,利用RoIAlign算法从特征ft中裁剪出人和物体的特征,vt中人和物体的实例级特征分别表示为Pt和Ot。
一个视频片段仅仅是一个短会话,容易错过时间全局语义。为了建立时间交互模型,我们对时间记忆特征进行跟踪。时间记忆特征包括连续片段中的persons特征:Mt=[Pt−L,....Pt,Pt+L],其中(2L+1)是从视频片段中抽取帧的大小。实践中,从每个相邻视频片段中抽取一定数量的persons。
上述三个特征都具有语义意义,包含了识别动作的集中信息。有了这三个特性,我们现在能够显式地对语义交互进行建模。
3.2 交互模型和聚合
我们如何利用这些提取的特征?对于人和物体,有多个检测到的人和物体,主要的挑战是如何正确地关注与目标人互动的人和物体。在这一节中,我们首先介绍我们的交互块,它可以在一个统一的结构中自适应地对每种类型的交互进行建模,然后我们描述了能够聚合多个交互的交互聚合(IA)结构。
概述
给定不同的人Pt、物体Ot和时间记忆特征Mt,提出的IA结构输出动作特征 At=E(Pt,Ot,Mt,φE),其中φE表示IA结构中的参数,然后At输入到最终分类器以进行结果预测。
IA结构由多个交互块组成,它们中的每一个都是为单一类型的交互而定制的。交互块与其他块进行深度嵌套,有效地集成不同的交互,以获得更高层次的特征和更精确的关注。
交互块
交互块结构改编自[35]最初提出的Transformer块,具体设计基本遵循[36,39]。简单地说,两个输入中的一个用作查询,另一个映射到键和值。通过图3a中softmax层的输出dot-product attention,块能够选择对查询特征高度激活的值特征,并将它们合并以增强查询特征。交互块有三种类型:P块、O块和M块。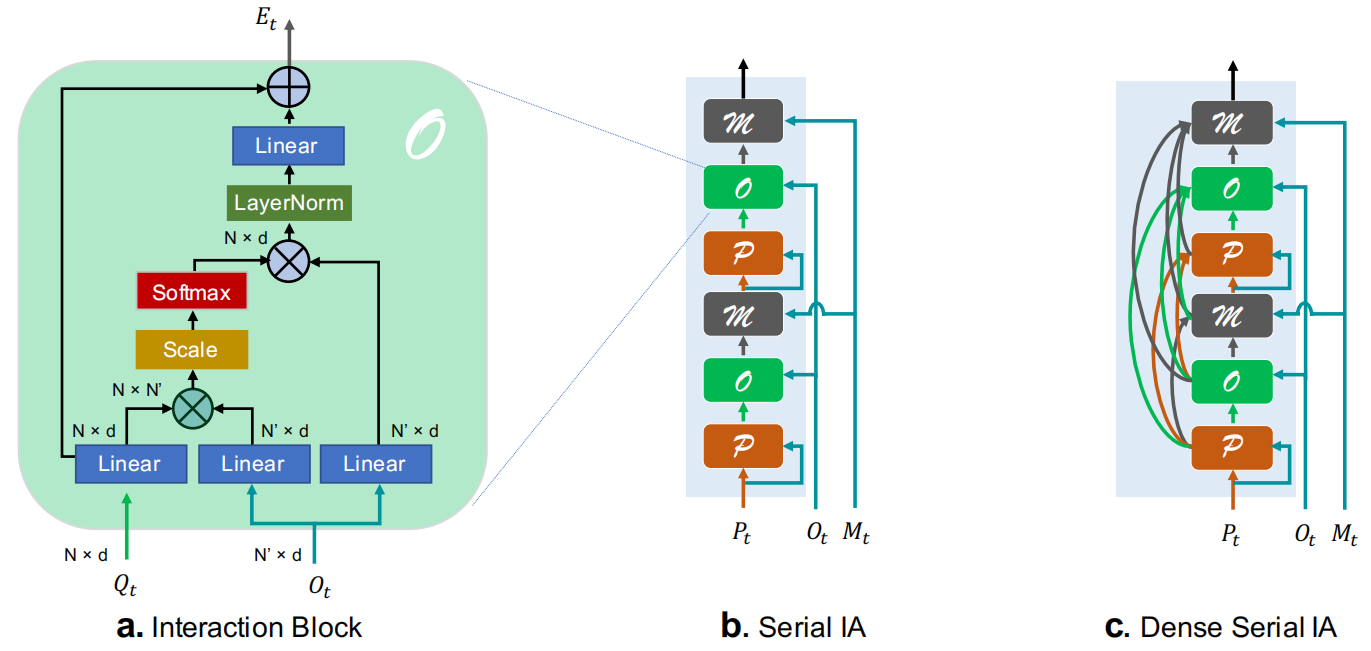
图3:交互块和IA结构。a.O块:查询输入是目标人的特征,键/值输入是物体的特征。P块和M块相似。b. 序列IA。c. 密集序列IA
P块:P块在同一片段中模拟人与人之间的交互。它有助于识别听和说等动作。由于查询输入已经是person特征或增强的person特征,因此我们采用与查询输入相同的键/值输入。
O块:在O块中,我们的目标是模拟人与物体的相互作用,例如推动和携带物体。我们的键/值输入是检测到的物体特征Ot。在检测物体太多的情况下,我们根据检测分数进行采样,图3a是O块的图示。
M块:有些动作在时间维度上有很强的逻辑联系,比如打开和关闭。我们将这类交互建模为时间交互。为了操作这种类型,我们将记忆特征Mt作为M块的键/值输入。
交互聚合结构
我们提出三个IA结构来整合这些不同的交互块,包括原始并行IA、串行IA和密集串行IA。为了清楚说明,我们使用P、O和M分别表示P块、O块和M块。
并行IA:一种简单的方法是分别对不同的交互进行建模在最终合并它们。如图4a所示,每个分支遵循与[12]相似的结构,只处理一种类型的交互,而不知道其他交互,我们认为并行结构很难精确地找到相互作用。我们通过为不同的人显示softmax层的输出来说明图4c中第二个P块的注意,如我们所见,目标人显然是在看和听穿红色衣服的人,然而P块关注了两个男人。
图4:我们通过在P块中显示softmax层的输出来可视化注意力。原始输出包含对零填充人的注意。我们移除那些无意义的注意力,并将其余的注意力归一化为1
串行IA:不同交互之间的信息有助于识别交互。我们提出串行IA来聚合不同类型的交互作,如图3b所示,不同类型的交互块按顺序堆叠。查询的功能在一个交互块中得到增强,然后传递给不同类型的交互块。图4f和4g展示了串行IA的优势:第一个P块不能区分左边男人和中间男人的重要性,从O块和M块中获得知识后,第二个P块能够更加注意到与目标人物交谈的左边男人。与并行IA中的注意图(图4c)相比,我们的串行IA在发现相互作用方面更好。
密集串行IA:在上述结构中,交互块之间的连接完全是手工设计的,交互块的输入只是另一个交互块的输出。我们希望该模型能够进一步了解哪些交互特征可以单独使用,考虑到这一点,我们提出了密集串行IA。在密集串行IA中,每个交互块接受先前块的所有输出,并使用可学习权重聚合它们。形式上,第i个块的查询可以表示为

其中,![]() 表示元素相乘,C是先前块的索引集,Wj是用C中的Softmax函数规范化后学习得到的d维向量,Et,j是来自第j块的增强输出特征。密集串行IA如图3c所示。
表示元素相乘,C是先前块的索引集,Wj是用C中的Softmax函数规范化后学习得到的d维向量,Et,j是来自第j块的增强输出特征。密集串行IA如图3c所示。
3.3 异步记忆更新算法
长期记忆特征可以提供有用的时间语义来帮助识别动作。想象一下这样一个场景:一个人打开瓶盖,喝水,最后合上瓶盖,用微妙的动作很难察觉瓶盖的打开和关闭。但是了解喝水整个过程的语义,事情就变得容易多了。
资源挑战
为了获取更多的时间信息,我们希望Mt能够从足够多的片段中收集特征,然而,使用更多的片段将大大增加计算和内存消耗。如图5所示,当联合训练时,随着Mt时间长度的增加,内存使用和计算消耗迅速增加。要训练一个目标person,必须一次取前后(2L+1)个视频片段,这会消耗更多的时间,更糟的是,由于GPU内存有限,无法充分利用足够的长期信息。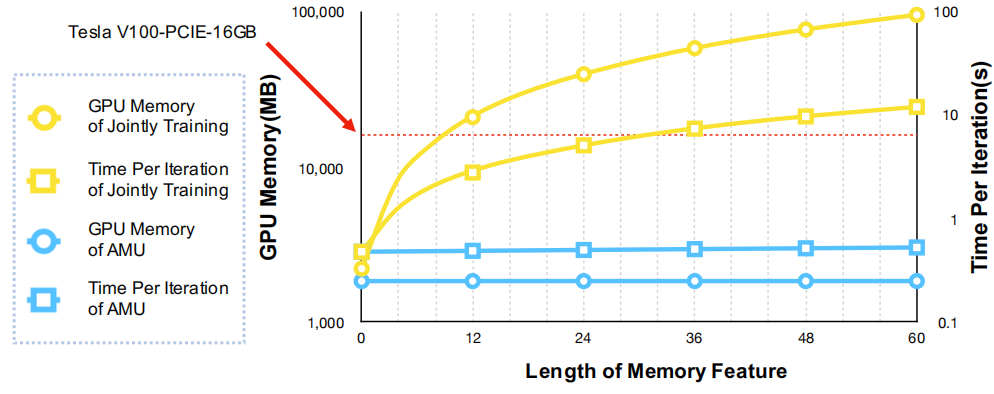
洞察
在前面的工作[39]中,预先训练了另一个重复的骨干来提取记忆特征,以避免这个问题。然而,该方法利用了冻结记忆特征,其表示能力不能随着模型训练的进行而增强。我们期望在训练过程中,记忆特征能够动态更新,并享受参数更新带来的改进。因此,我们提出了一种异步记忆更新方法,可以生成有效的动态长期记忆特征,使训练过程更加轻量级。算法1给出了该算法的训练过程。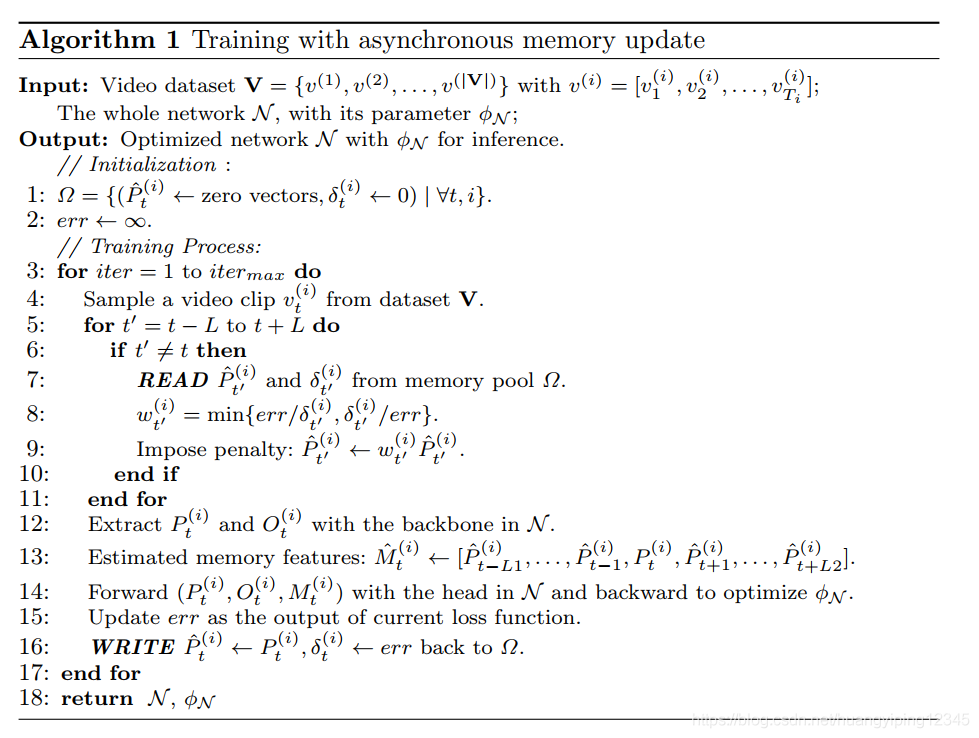
受文献[38]的启发,我们的算法由内存组件、记忆池Ω和读写两个基本操作组成。记忆池Ω记录记忆特征。在这个池中的每个特征![]() 是一个估计值,并用损失值
是一个估计值,并用损失值 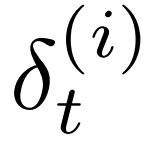 标记,损失值
标记,损失值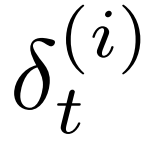 记录整个网络的收敛状态。在每次训练迭代中调用两个基本操作:
记录整个网络的收敛状态。在每次训练迭代中调用两个基本操作:
-READ:在每次迭代的开始,给定来自第i个视频的视频片段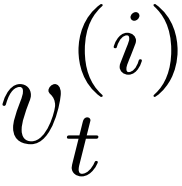 ,从记忆池Ω读取目标片段周围的记忆特征,即
,从记忆池Ω读取目标片段周围的记忆特征,即![]() 和
和![]() 。
。
-WRITE:在每次迭代结束时,目标片段的人特征![]() 作为估计的记忆特征
作为估计的记忆特征![]() 被写进记忆池Ω,并用当前损失值标记。
被写进记忆池Ω,并用当前损失值标记。
-Reweighting:我们的READ功能是在不同的训练步骤中written的,因此本文从模型中提取了一些与现有特征参数相差较大的早期特征,以惩罚因子![]() 评估丢弃的错误估计的特征。我们设计了一个简单有效的方法来计算惩罚因子和损失目标,损失目标
评估丢弃的错误估计的特征。我们设计了一个简单有效的方法来计算惩罚因子和损失目标,损失目标![]() 与当前损失值之间的差值表示为
与当前损失值之间的差值表示为
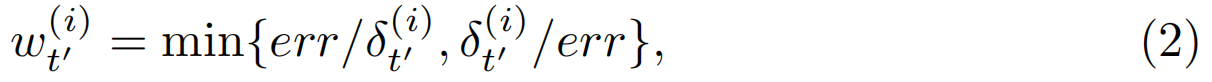
当差别很小时非常接近1,当网络收敛时,时间池中的估计特征将越来越接近精确特征,![]() 接近1。
接近1。
如图5所示,随着记忆特征长度的增加,我们的算法消耗的GPU内存和计算量都没有明显的增加,因此我们可以在当前的通用设备上使用足够长的记忆特征。通过动态更新,异步记忆特征可以比冻结记忆特征得到更好的利用
4. 效果如何
在AVA数据集上达到SOTA。给的结果表是跟SlowFast比的

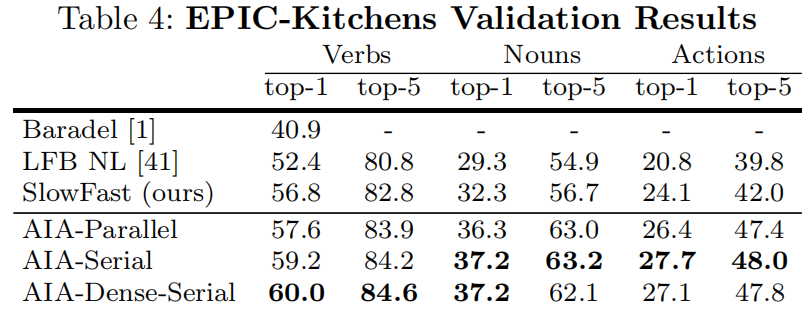
在UCF101-24和EPIC-Kitchens上做了验证

5. 结论
本文介绍了异步交互聚合网络及其在动作检测中的性能,我们的方法在AVA数据集上得到最先进指标。然而,动作检测和交互识别的性能还很不理想,性能不佳的原因可能是视频数据集有限,从图像中传递行为的交互信息可以作为AIA网络的进一步改进。
6.相关知识
slowfast:Facebook的AI研究团队新发表的一篇论文,提出了一种新颖的方法来分析视频片段的内容,可以在两个应用最广的视频理解基准测试中获得了当前最好的结果:Kinetics-400和AVA。该方法的核心是对同一个视频片段应用两个平行的卷积神经网络(CNN)—— 一个慢(Slow)通道,一个快(Fast)通道。详见CSDN。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号