A Structured Model for Action Detection
0. 前言
- 相关资料:
- arxiv
- github
- 论文解读
- 论文基本信息
- 领域:动作检测
- 作者单位:Google
- 发表时间:CVPR 2019
1. 要解决的问题
动作检测是一个具有挑战性的问题——需要训练的模型很大,而且获取标记数据的成本很高。
2.主要贡献
提出了一种新的动作检测方法,该方法可以明确地捕捉长期行为以及人与人和人与对象的交互,具体见3.2节,将多对象跟踪集成到动作检测框架中。
3. 具体实现
作者认为,对于动作检测来说,捕捉长期的时间信息和参与者与对象之间的空间关系是至关重要的,所以考虑将此领域知识纳入模型的结构中,以简化优化。特别是使用一个跟踪模块扩展了一个标准的I3D网络,以聚合长期运动模式,并使用一个图卷积网络来推理角色和对象之间的交互。
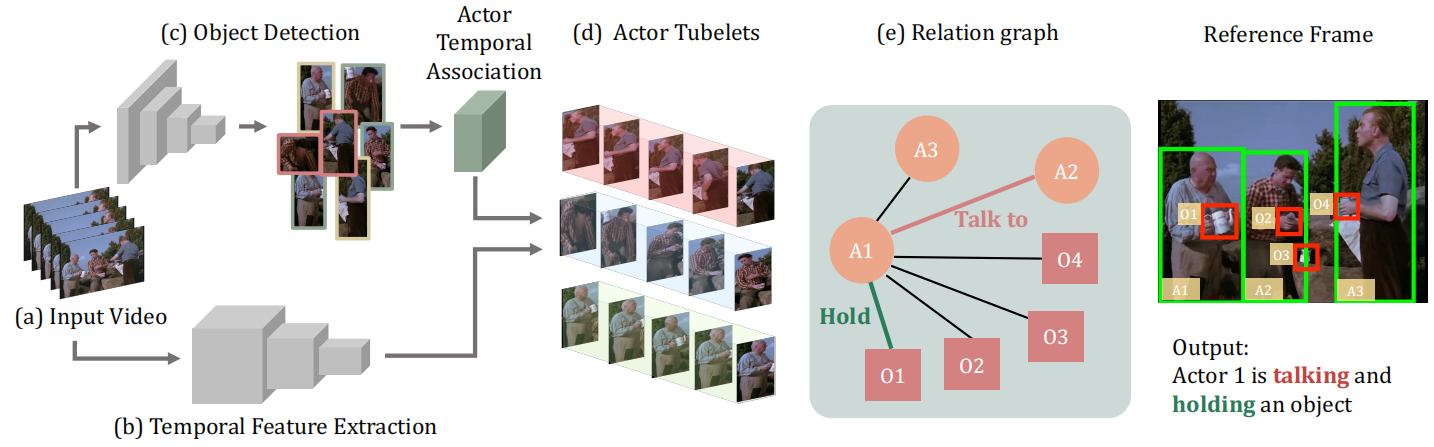
将一系列视频帧作为输入(a),并将其通过I3D网络(b)。同时,对每个帧应用最先进的对象检测模型(c),以生成人和对象边界框。然后,使用关联模块将人类边界框组合成tubelet(一系列随时间变化的边界框)(d)。然后使用tubelets和对象框(作为节点)为视频剪辑(e)中的每个参与者构建以参与者为中心的图。
在以参与者为中心的图中,定义了两种节点,参与者节点和对象节点,以及两种边,表示人-对象操作和人-人交互。对象节点是通过执行来自I3D表示的兴趣区域(ROI)池化生成的。希望对其时间行为建模的参与者节点是通过将I3D特征与对应的小结节上的图卷积聚合而获得的。图形边缘的特征用作动作分类的最终表示。除了2D对象检测器外,整个模型以端到端的方式进行训练,只需要参与者边界框和ground-truth动作。在本节的其余部分中,将首先介绍视频表示和对象检测的模型。然后,解释了如何使用基于外观的多目标跟踪模块集成时间信息。演示如何构建以参与者为中心的图,以及如何使用它生成动作预测。
3.1 时空特征提取
第一步是从视频中提取两组特征:非结构化视频嵌入,以及对象和参与者区域建议的集合。
非结构化视频嵌入。为了利用视频输入的时空结构,我们使用了具有非局部层的膨胀3D ConvNet(I3D)。在3D ConvNet中,视频被建模为坐标x,y,t的密集采样,相应的学习滤波器在空间和时间域中运行,从而捕获短期运动模式。我们还使用非局部层来聚合整个图像的特征,使我们的网络能够超越局部卷积滤波器的范围进行推理。在我们的场景中,输入是一个3秒的36帧视频剪辑。我们最终的视频嵌入保留了它的时间维度,使我们能够在模型的后期显式地使用时间信息。
基于外观的参与者/对象建议。我们利用类似RCNN的目标检测模型的成功来识别感兴趣的区域。在我们的模型中,我们感兴趣的是确定参与者的空间位置以及他们操纵的潜在对象。由于我们的目标是理解人类执行的动作,独立于对象的类别,因此我们使用[7]中提出的类别不可知检测器来定位对象。对于MS-COCO中标记的80个类别之外的对象,该模型实现了更高的召回率。具体而言,我们在MS-COCO上通过将所有类别标签折叠为单个对象标签来训练Mask-RCNN,从而产生类别不可知的对象检测器。我们使用标准的人员检测器来定位参与者。
3.2 基于时间上下文的动作检测
为了使我们的动作检测系统能够捕获长期的时间依赖关系,我们将多对象跟踪集成到我们的动作检测框架中。我们不生成明确的行动建议,而是在整个视频中跨帧跟踪每个参与者。然后,利用存储在节点中的角色外观信息和边缘中的跟踪信息,使用图卷积对每个角色的运动进行聚合。
3.2.1 多角色关联模块
我们注意到,一些动作由多个单元动作组成,例如,“站起来”动作由坐着、向上移动和站立组成。我们假设,自信地跨多个帧跟踪参与者,并以原则性的方式集成这些局部表示,对于学习由多个动作组成的动作的区别表示至关重要。以前的方法从几个帧中识别动作并通过actioness分数将其链接,这些方法无法保持一致的轨迹,因为与外观特征不同,为动作识别而训练的模型的特征因参与者的动作而在不同帧之间存在显著差异。
基于这一观察,我们引入了一个多参与者关联模块,旨在关联视频剪辑中每个参与者的边界框建议。我们不是基于动作得分链接动作边界框,而是基于参与者外观特征的相似性关联参与者边界框。
我们遵循检测跟踪范式,并构建关联模块来执行链接。具体来说,我们首先训练外观特征编码,然后在下一帧中显式搜索相邻区域以获得外观匹配。为了学习区分不同角色的外观特征编码,我们训练了一个三元损失的Siamese network。在获得外观特征编码后,我们在连续帧中的边界框建议中进行搜索,并匹配外观相似度最高的边界框。
3.2.2 基于图的Actor-tubelet学习
最近的动作检测工作试图直接从I3D提取的特征中预测动作。我们认为,在多个帧上集成I3D特征对于识别长期活动至关重要。一种简单的方法是简单地沿时间维度平均这些特征。不过我们建议使用图卷积网络对每个参与者的行为进行建模。我们建议使用RoIAlign从I3D主干提取的特征对人形图的节点进行编码。边缘是从我们的多角色关联模块构造的tubelets中获得的。在执行图卷积时,每个参与者框的运动信息由图聚合。形式上,让我们假设视频中有参与者。每个参与者由一个D维的特征向量表示。T是时间维度。我们用G表示维数为N×T的参与者图的亲和矩阵,用X表示维数为T×D的特征。图卷积运算可以写成Y=GXW,其中W是维数为D×D的权重矩阵。图Y的输出具有维数N×D,并沿时间轴聚合actor特征。图卷积运算也可以堆叠在多个层中,以学习更多的差异化特征。
3.3 参与者和对象之间的交互
要识别与交互相关的动作,关键是要利用感兴趣的角色、其他角色和场景中的对象之间的关系。然而,对所有这些可能的关系进行建模可能会变得棘手。我们建议使用ROI建议中的类无关特性来构建关系图,并仅在给定动作注释的情况下隐式执行关系推理。
为了整合来自其他参与者和对象的信息,我们构建了两个关系图,一个用于建模人-对象操作,另一个用于建模人-人交互。人类对象图将每个感兴趣的参与者与其他对象连接起来,人类对象图将每个感兴趣的参与者与其他参与者连接起来。参与者节点的特征来自多角色关联模块后的参与者tubelets,我们用H=[h1,h2,…,hN]来表示它们,其中N代表clip的中间帧中的参与者数目。对象的特征由I3D表示的ROI池化生成,表示为O=[o1,o2,…oM],其中M是整个视频中的对象数。
为了模拟选定参与者和其他主体之间的关系,我们可以建立硬注意模型和软注意模型的概念。表示动作特征的一种方法是首先在所有对象和所有其他参与者(目标参与者除外)中定位正确的主体。然后,可以使用来自参与者和已识别主体的特征,我们称之为硬关系图。或者,在软关系图中,我们不是显式地定位主体,而是通过隐式学习主体与目标参与者的关联程度来整合这些信息。我们将进一步演示如何实现软关系图和硬关系图来学习交互的区别性特征表示。
硬关系图。我们为每个目标参与者显式地定位正确的对象和参与者,以表示对象操纵动作和人类交互动作。对象操纵动作通过链接参与者节点和对象节点来表示,而人类交互动作通过一个参与者和其他参与者节点之间的边来表示。给定参与者节点特征H=[h1,h2,…,hN]和对象节点特征O=[o1,o2,…,oM],第i个目标参与者和第j个对象的对象操作关系特征可以通过连接两个节点的特征来表示
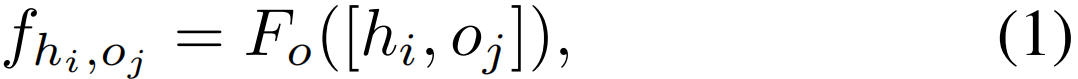
其中,Fo是用于对象操作的特征提取函数。同样,以Fh作为人体交互的特征提取函数,我们表示了第i个和第k个参与者的人体交互关系特征
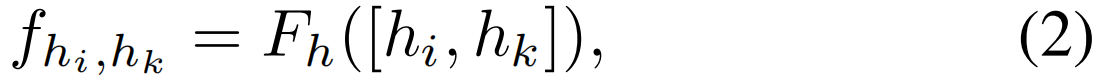
在目标对象没有ground-truth标注的情况下,我们采用多实例学习的方法进行目标检测,并选择ground-truth动作得分最大的区域。具体来说,对于以第i个参与者为中心的对象操作动作,
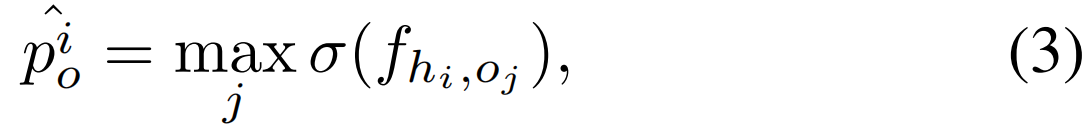
其中σ是sigmoid函数,![]() 是第i个参与者的人-对象操作动作预测。同样地,对人类互动行为的预测也是如此
是第i个参与者的人-对象操作动作预测。同样地,对人类互动行为的预测也是如此
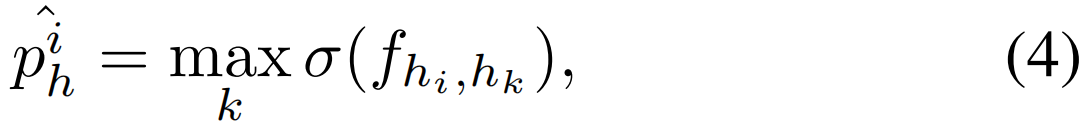
其中![]() 是第i个参与者的人与人的交互行动预测。
是第i个参与者的人与人的交互行动预测。
软关系图。上面描述的方法在概念上是有吸引力的,但在训练期间会导致不稳定。因此,我们提出了一种替代方法,通过聚集场景中所有对象的信息,避免对ground-truth对象做出硬决策。我们将感兴趣的参与者与另一个参与者或对象之间的关系强度定义为特征变换后两个节点特征之间欧氏距离的倒数。
角色特征和对象特征的转换分别使用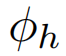 和
和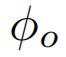 定义。给定参与者节点特征H=[h1,h2,…,hN]和对象节点特征O=[o1,o2,…,oM],我们首先将它们转换为
定义。给定参与者节点特征H=[h1,h2,…,hN]和对象节点特征O=[o1,o2,…,oM],我们首先将它们转换为![]() ,
,
![]()
![]() 。
。
第i个参与者和第j个对象之间的边表示如下
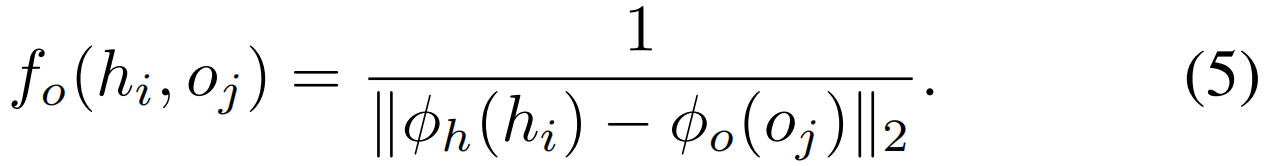
第i个行动者和第k个行动者之间的边表示类似。我们进一步规范化上面的边权值,使它们之和为1。我们对每个参与者采用softmax函数
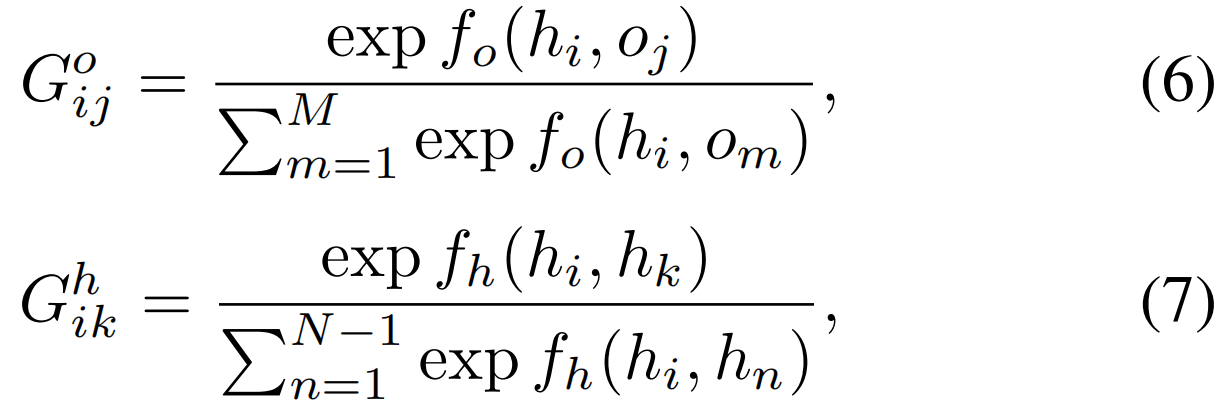
其中k是1…N除了i。在计算图形表示后,第i个参与者的对象操作和人工交互动作用表示如下
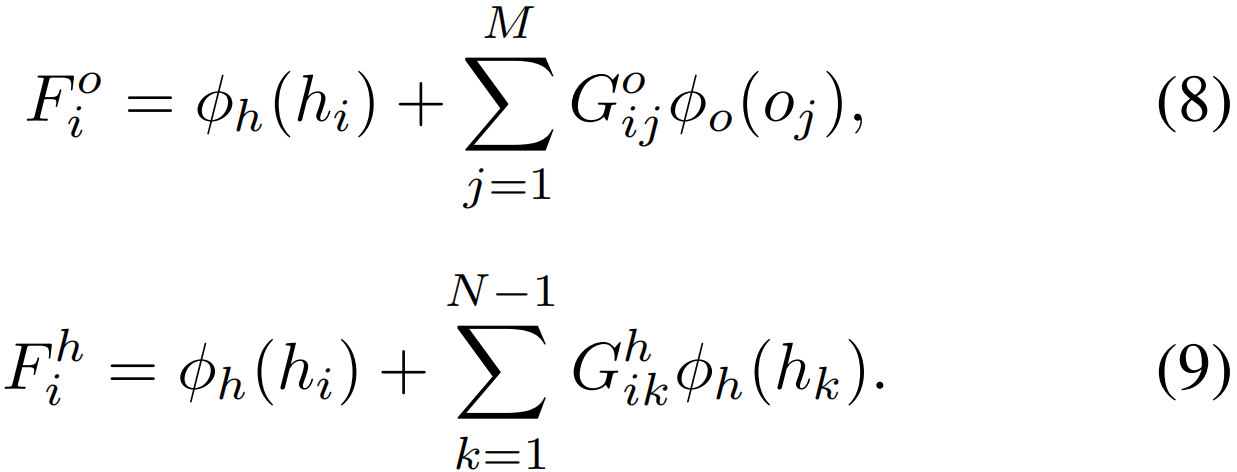
最后的动作预测是通过分别应用于公式8和公式9中的人机交互类和人机交互类的特征表示的逻辑分类器得到的。
4. 效果如何
在具有挑战性的AVA数据集上进行评估,提出的方法比I3D基线提高了5.5%的mAP,比最先进的方法提高了4.8%的mAP。
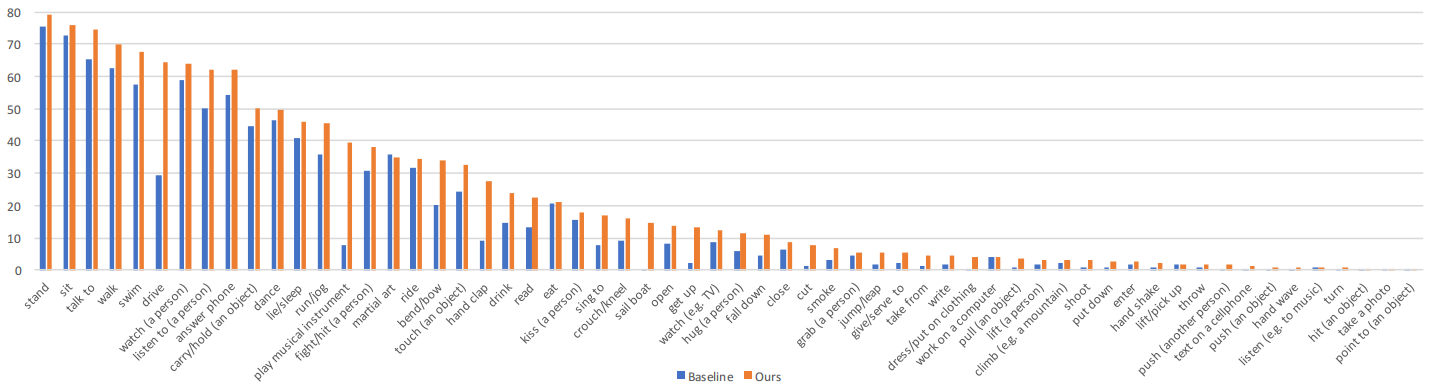
该模型的每类别结果和AVA验证集上的基线对比。

模型与AVA验证集上最先进方法的比较。

人体姿势、人体对象操作和人机交互类别的消融分析。
5. 结论
提出了一个结构化的动作检测模型,它明确地模拟了长期的时间行为以及对象操作和人类交互。显示了在模型体系结构中集成时间信息和关系信息对于行动检测任务的重要性。
6.相关知识
1.I3D:Inflated 3D ConvNet,膨胀卷积网络,根据之前各个模型的优缺点,设计的一个基于3D卷积的双流(RGB图信息+光流)模型(Two-stream Inflated 3D ConvNets)(见CSDN,知乎)

2.Siamese network:这个是一个曾经用于签字认证识别的网络,也就是我们平时说笔迹识别。Siamese network就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的,左右两个神经网络的权重一模一样,在代码实现的时候,甚至可以是同一个网络,不用实现另外一个,因为权值都一样。对于siamese network,两边可以是lstm或者cnn,都可以。主要用途是衡量两个输入的相似程度。(见CSDN,知乎)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号