Weakly Supervised Relative Spatial Reasoning for Visual Question Answering
本篇论文收录于ICCV2021,主要介绍了通过弱监督学习来检测视频异常,地址如下:
网上已有相关博客,这里进行了一些借鉴,原博客链接如下,本人还是一个小白,若有错漏之处,敬请包涵与指正。
https://blog.csdn.net/weixin_42653320/article/details/120234036
摘要
视觉和语言推理(V&L)需要感知如对象和行为的视觉概念、理解语义和推理这种模态的相互作用。视觉推理的一个关键方面是空间理解,它涉及到理解对象的相对位置,即隐式地学习场景的几何形状。本工作中,我们评估了V&L模型对这种几何理解的可靠性,通过制定对象的成对相对位置的预测作为一个分类器和一个回归任务。我们的研究结果表明,最先进的基于transformer的V&L模型缺乏足够的能力来完成这项任务,在此基础上,我们设计了两个目标作为三维空间推理(SR)的代理--对象质心估计和相对位置估计,并在现成的深度估计器的弱监督下训练V&L。这导致了“GQA”视觉问答挑战(在完全监督、少镜头和O.O.D设置中)的准确性显著提高,以及相对空间推理的改进。
一、介绍
“视觉推理”是一个总称术语,用于表示感知外观(物体及其大小、形状、颜色和纹理)之外的视觉能力。在V&L领域,图像-文本匹配、视觉基础[、视觉问题回答(VQA)和常识性推理等任务都属于这一类。其中一种能力就是空间推理——理解场景的几何形状和图像中物体的空间位置。视觉问题回答(如图1所示的GQA挑战)是一项任务,它可以通过涉及图像中物体的空间位置,或需要对物体之间空间关系的组合理解的问题来评估这种能力。

图1。GQA[21]需要对对象、其属性和空间位置(带下划线)的组合理解。
基于transformer的模型已经导致了多个V&L任务的显著改进。然而,这些模型的底层训练协议依赖于学习视觉和文本输入之间的对应关系,通过预训练任务,如图像-文本匹配和跨模态掩码对象预测或特征回归,然后确定特定数据集如GQA。因此,即使下游任务评估了空间理解,这些模型也没有经过训练来推理场景的三维几何形状。因此,V&L模型仍然忽略了图像形成的机制。
真实世界的场景是三维的,如图2所示,它显示了一个场景中的块。当相机捕捉到这个场景的图像时,对象上的点被投影到同一图像平面上,即所有点被映射到一个深度值,z维(深度)丢失。这个映射依赖于透镜方程和相机参数,导致光学错觉,如图3,因为物体的放大率与深度成反比,取决于焦距,由于3D场景被投影到2D图像上,遥远的人看起来更小,左边图中在女人的手掌上面,右边图中在女人的鞋子下面。物体大小、深度、相机校准和场景几何形状之间的这种关系使得图像的空间推理具有挑战性。

图3。常见的光学错觉是因为靠近相机的物体被放大了。这说明需要理解三维场景的几何形状,以对二维图像执进行空间推理。
如果已知对象的三维坐标(Xi、Yi、Zi),那么推断它们的相对位置将是很简单的,比如图1中的问题。然而,V&L数据集中的图像是众包的,来自不同的单目相机,如焦距和孔径大小,这使得很难从图像坐标中解析三维坐标(特别是深度)。这导致了场景几何形状的歧义,并使回答需要空间推理的问题成为一个严重的不适定问题。
在本文中,我们考虑了以空间推理(SR)为重点的视觉问题回答任务。我们研究了VQA模型是否能够解决GQA挑战中图像中物体之间的空间关系问题。我们的研究结果表明,尽管模型正确地回答了其中一些问题(∼60%),但它们不能真实地解决空间关系问题,如相对位置(左、右、前、后面、上、下)或物体之间的距离。这就引出了一个问题:VQA模型是否真的理解了场景的几何形状,或者它们是否基于从数据中学习到的虚假相关性来回答空间问题?
为此,我们设计了两个考虑三维几何形状的任务,目标质心估计和相对位置估计。这些任务由现成的单目深度估计技术和对象的边界框注释估计的推断深度图进行弱监督。对于目标质心的估计,该模型被训练来预测在单位归一化的三维向量空间中检测到的输入对象的质心。另一方面,对于相对位置的估计,需要该模型来预测在同一向量空间中检测到的输入对象之间的距离向量。
我们的工作可以总结如下:
1.我们的方法将现有的基于transformer的语言模型的训练协议与基于场景三维几何形状的新型弱监督SR任务相结合,即目标质心估计(OCE)和相对位置估计(RPE)。
2.这种方法显著提高了GQA性能和SR任务之间的相关性。
3.我们表明,我们的方法在开放式问题上提高了2.21%,总体提高了2.21%,总体提高了1.77%。
4.我们的方法还提高了对分布外样本(GQA-OOD)的泛化能力,并且在few-shot设置中明显优于baseline,仅用10%的标记GQA样本就实现了最先进的性能。
二、相关工作
视觉问题回答是一个位于视觉和语言交叉点的任务,其中系统需要回答关于图像的问题,如图1所示。VQA是一个活跃的研究领域,有多个数据集,包括各种各样的问题,例如关于对象存在及其属性的问题、对象计数、需要常识知识的问题、外部事实或知识和空间推理(如下所述)。
VQA中的空间推理专门针对CLEVR中的合成世界块图像和问题以及GQA中的真实场景和人类编写的问题进行了讨论。这两个数据集的问题都需要对物体的空间关系及其属性的组合理解。然而,CLEVR的合成性质和问题和图像的有限复杂性使其更容易完成;CLEVR模型已经达到非常高(99.80%)测试精度。另一方面,由于现实世界场景中的对象和上下文的多样性和视觉上的歧义,GQA提出了重大挑战。GQA也带来了语言上的困难,因为问题是通过人类标注者众包的。对于GQA任务,已经提出了神经符号方法,如NSM和TRRNet,它们试图通过将问题转换为符号程序来将问-答建模为指令-跟随。
三维场景重建是计算机视觉的基础,有着悠久的历史。从立体图像、多帧或视频、编码孔径、可变照明、离焦等多个观测结果中得到的深度估计已经取得了显著进展。然而单目(单图像)深度估计仍然是一个具有挑战性的问题,基于学习的方法突破了极限。在这项工作中,我们使用了AdaBins,它使用了一个基于transformer的体系结构,自适应地将深度范围划分为可变大小的bins,并估计深度作为这些深度bins的线性组合。AdaBins是一种最先进的室外和室内场景的单目深度估计模型,我们使用它作为弱监督来指导VQA模型进行空间推理任务。
V&L中的弱监督。弱监督是动作/目标定位和语义分割等视觉任务中的一个活跃的研究领域。虽然来自V&L数据集的弱监督已被用于帮助图像分类,但对V&L,特别是VQA的弱监督仍未得到充分探索。虽然现有的方法侧重于从大规模数据中学习跨模态特征,但除对象、问题和答案之外的注释,在VQA中尚未得到广泛使用。克尔瓦德克等人使用对象-词对齐形式的弱监督作为预训练的任务。使用图像中的对象计数作为弱监督来指导VQA处理基于计算的问题,Gokhale等人使用关于逻辑连接词的规则来增加是非问题的训练数据集,Zhao等人使用单词嵌入来设计一个额外的弱监督目标。来自描述的弱监督最近也被用于视觉基础任务。
三、相对空间推理
在V&L理解任务中,如基于图像的VQA、字幕和视觉对话框,系统需要对图像中出现的对象进行推理。当前的V&L系统,一些提取FasterRCNN对象特征来表示图像。这些系统通过投影二维对象边界框坐标并将它们添加到提取的对象特征中来合并位置信息。虽然V&L模型是通过图像标题匹配、掩码对象预测和掩码语言建模等任务进行预训练,以捕获对象-单词上下文知识,但这些任务都没有明确地训练系统来学习对象之间的空间关系。
在VQA领域中,通过提出相应的问题,如图1所示,可以间接评估空间理解。然而,这并不能客观地捕捉到模型是否能够推断出物体的位置、空间关系和距离。之前的工作已经表明,VQA模型通过来自训练集的问答对之间的虚假语言先验来学习回答问题,当测试集在这些语言先验中发生变化时,并不能泛化。同样,我们的工作也试图通过引入两种新的基于几何形状的训练目标--对象质心估计(OCE)和相对位置估计(RPE),将空间推理(SR)从数据集的语言先验中分离出来。
3.1 预训练
像素坐标归一化。我们将两个维度的像素坐标归一化到范围[0,1]。例如,对于大小为H×W的图像,一个像素(x、y)的坐标被归一化为(x/H、y/W)。
深度提取。虽然VQA数据集中有对象边界框,但它们缺乏深度注释。为了从图像中提取深度图,我们使用了一种开源的单目深度估计方法AdaBins,这是在室外和室内场景数据集上最先进的方法。AdaBins利用一个transformer将图像的深度范围划分为bins,bins的中心值由每幅图像自适应估计。最终的深度值是bins中心的线性组合。由于室内和室外图像的深度值的尺度差异很大,我们使用所有室内和室外图像的最大深度值将深度归一化到[0,1]范围。因此,我们得到了图像中每个像素(i、j),i∈{1、H}、j∈{1、W}的深度值d(i、j)。
使用质心表示对象。给定图像中每个对象的边界框[(x1、y1)、(x2、y2)],我们可以计算对象质心的(xc、yc、zc)坐标。xc和yc计算为边界框的左上角(x1、y1)和右下角(x2、y2)的平均值,zc计算为边界框中所有点的平均深度:
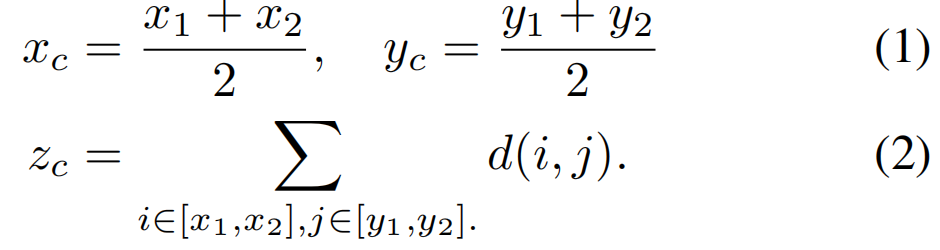
因此,对象特征中的每个对象Vk都可以用其质心的三维坐标来表示。这些坐标对我们下面的空间推理任务起着弱监督的作用。
3.2 对象质心估计(OCE)
我们的第一个空间推理任务是训练模型来预测图像中每个物体的质心。
在二维OCE中,我们将该任务建模为输入对象的二维质心坐标(xc、yc)的预测。设V表示输入图像的特征,设Q为文本输入。然后二维估计任务要求系统预测存在于对象特征的所有对象k∈{1…N}的质心坐标(xck,yck)。在三维OCE中,我们还预测了物体的深度坐标,因此,该任务要求系统预测三维质心坐标(xck,yck,zck)。
3.3 相对位置估计(RPE)
该模型被训练来预测投影的单位归一化向量空间中每对不同对象之间的距离向量。这些距离向量是实值向量∈ ![]() 。因此,对于两个不同物体的一对质心(x1,y1、z1)和(x2,y2、z2),给定V和Q,训练模型来预测向量[x1−x2,y1−y2,z1−z2]。RPE不是对称的,对于任何两个不同的点A,B,dist(A,B)=−dist(B,A)。
。因此,对于两个不同物体的一对质心(x1,y1、z1)和(x2,y2、z2),给定V和Q,训练模型来预测向量[x1−x2,y1−y2,z1−z2]。RPE不是对称的,对于任何两个不同的点A,B,dist(A,B)=−dist(B,A)。
回归vsBin分类。在上述两个任务中,预测都是实值向量。因此,我们评估了这些任务的两个变体:(1)一个回归任务,其中模型预测![]() 中的实值向量,以及(2)bin分类,为此,我们将所有三个维度的实值范围划分为C个log-scale bins。第c个bin的bin宽由下式(使用超参数λ=1.5)给出:
中的实值向量,以及(2)bin分类,为此,我们将所有三个维度的实值范围划分为C个log-scale bins。第c个bin的bin宽由下式(使用超参数λ=1.5)给出:
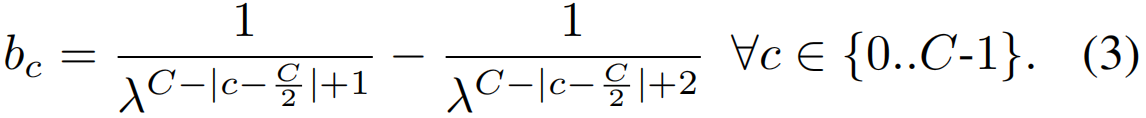
对数尺度的bins对更近的距离有更高的分辨率(更多的bins),对更远的距离有更低的分辨率(更少的bins),为接近的对象提供细粒度类。在给定一对对象的情况下,对模型进行训练,以预测在3个维度上的bin类别作为输出。我们评估了不同bin数量的值:C∈{3、7、15、30},以研究V&L模型在更高分辨率的空间距离下的区分能力的程度。例如,最简单的bin分类形式是一个具有bin间隔的三类分类任务[−1,0)、[0]、(0,1]。
四、方法
我们采用最先进的视觉和语言模型LXMERT,作为我们实验的backbone。LXMERT和其他流行的基于transformer的V&L模型方法,在多个VQA和图像字幕数据集的组合上进行了预训练,如概念字幕、SBU字幕、VisualGenome和MSCOCO。这些模型使用由FasterRCNN对象检测器提取的前36个对象的对象特征作为输入图像的视觉表示。transformer编码器将这些对象特征和文本特征作为输入,并输出跨模态token。通过优化掩码语言建模、图像-文本匹配、掩码对象预测和图像-问题回答等方法,对模型进行了预训练。
4.1 弱监督SR
由LXMERT编码器的交叉模态注意力层产生视觉特征v∈R36×H、跨模态特征x∈R1×H、文本特征t∈RL×H,H是隐藏维数,L是令牌数量,这些输出用于微调两个任务的模型:使用x作为输入的VQA,以及使用v作为输入的空间推理任务。设D是我们在空间推理中使用的坐标维数(2或3)。对于SR回归任务,我们使用一个两层前馈网络freg将v投影到一个维数为36×D的实值向量,并使用对应于真实对象坐标yreg的均方误差(MSE)计算损失:
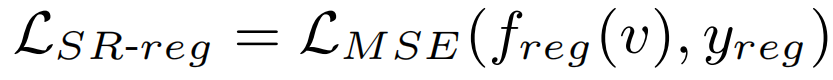
对于bin分类任务,我们训练一个两层前馈网络fbin来预测每个维度上每个对象的36×C×D个bin类,其中C是类的数量,使用交叉熵损失进行训练:
![]()
其中ybin是ground-truth对象位置bin。总损失的计算:
![]()
yreg和ybin是在预处理过程中从深度估计网络和对象边界框计算出的物体质心中获得的。由于场景中物体的真实三维坐标是未知的,这些yreg和ybin作为代理,因此可以对我们的空间推理任务起到弱监督作用。
4.2 空间金字塔Patches
由于LXMERT只以不同的对象和二维边界框特征作为输入,因此它本质上缺乏三维空间推理任务所需的深度信息。我们对二维和三维空间推理任务的评估证实了这一点,其中该模型在二维任务上具有较强的性能,但在3D任务上缺乏性能,如表1所示。为了结合原始图像中的空间特征来捕获相对物体的位置和深度信息,我们提出使用空间金字塔patch特征将给定的图像表示到不同尺度的特征序列中。图像I被分成一组patches:pn=![]() ,每个
,每个![]() 是一个ij×ij patches网格,并为每个patch提取ResNet特征。较大的patches编码全局对象关系,而较小的patches包含本地关系。
是一个ij×ij patches网格,并为每个patch提取ResNet特征。较大的patches编码全局对象关系,而较小的patches包含本地关系。
4.3 融合Transformer
为了结合空间金字塔patch特征和LXMERT提取的特征,我们提出了一种具有e层transformer的编码器融合transformer,包括自注意、残差连接和每个子层后的层归一化。我们将pn patch特征与来自LXMERT的v视觉、x交叉模态和t文本隐藏向量输出表示连接起来,以创建融合向量h,该融合向量h被输入融合transformer。设M为连接所有隐藏向量后的序列长度,对于序列中的任何隐藏向量m:
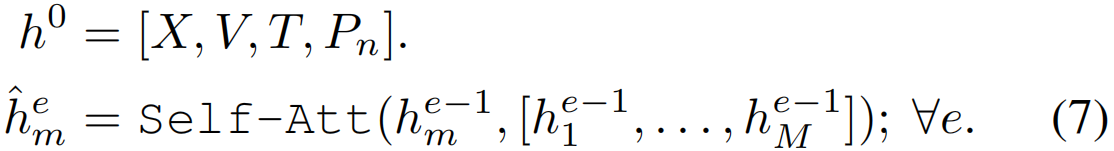
然后将融合transformer![]() 的输出分离为其组件,其中
的输出分离为其组件,其中![]() 、
、![]() 用作VQA和SR任务的输入,与第4.1节相同。
用作VQA和SR任务的输入,与第4.1节相同。
4.4 相对位置向量作为输入
我们使用的最后一组特征是对象之间的成对相对距离向量,如第3.3节所述。在这种情况下,除了视觉、文本、跨模态和patchs特征外,还使用成对距离作为输入,并训练模型来重建成对距离。这使得我们的模型成为回归任务的自动编码器。对于每个输入视觉对象特征vk,我们使用前馈层从36×3到36×H的成对距离向量投影创建一个相对位置特征rk,其中H是隐藏向量表示的大小。我们评估了这些特征的两种融合模式。在Early Fusion中,rk被添加到LXMERT编码器的输出中的vk中。在Late Fusion中,rk被添加到Fusion transformer输出的![]() 中。图4显示了同时利用patch特征和相对位置作为输入的最终模型的体系结构。
中。图4显示了同时利用patch特征和相对位置作为输入的最终模型的体系结构。
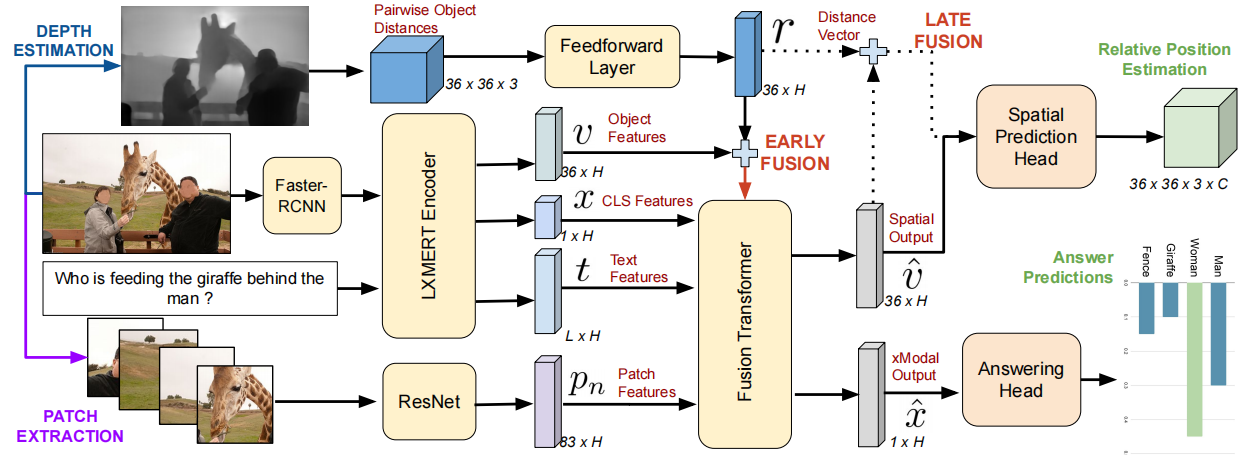
图4。我们的方法的总体架构显示了用于对象特征提取、跨模态编码和回答头的传统模块,以及我们新的来自深度图、patch提取、融合机制和空间预测头的弱监督。
五、实验
数据集:GQA和GQA-OOD,两者都包含空间推理的视觉问题,需要组合性和在自然非标志性图像中存在的对象之间的关系。有共同的训练集,测试集的区别为:GQA使用了一个i.i.d.分割,GQA-OOD包含一个分布移位。数据集中有2000个独特的答案,问题可以根据答案的类型进行分类:二值类和开放类。
评估指标:用于评估在全监督、few-shot以及O.O.D.中的表现对于GQA任务的设置,我们使用在[21]中定义的指标,包括精确匹配的准确性、对最常见的头部答案分布的准确性、不常见的尾部答案分布、与转述问题的一致性、有效性和空间关系的合理性。我们使用均方误差(MSE)来评估SR任务的SR回归和SR箱子分类的分类精度。
模型结构:LXMERT包含9个语言transformer编码器层、5个视觉层和5个跨模态层。该特性提取器可以被任何其他基于transformer的V&L模型所取代。我们的融合transformer有5个跨模态层,其隐藏尺寸为H=512。对于视觉特征提取,我们使用在ImageNet[41]上预训练的ResNet-50[18]来提取图像补丁特征,50%重叠,并使用在VisualGenome[30]预训练的FasterRCNN来提取前36个对象特征。我们使用3×3、5×5、7×7补丁和整个图像作为空间图像补丁特征。该图像在多个尺度上被均匀地划分为一组重叠的斑块。
训练协议和超参数:我们的Fusion transformer有5个跨模态层,隐藏维度为H=512。所有模型都使用Adam优化器,在一个NVIDIAA100 40 GBGPU上训练20个epoch,学习率为1e−5,batch大小为64。公式6中的系数(α、β)值选择为(0.9、0.1)进行回归,选择(0.7、0.3)进行分类。
baseline:我们使用LXMERT联合训练的SR和GQA任务作为我们的实验的强基线。此外,我们还比较了现有的非集成(单模型)方法在GQA挑战上的性能,这些方法直接从问答对中学习,而不使用外部程序监督或额外的视觉特征。尽管NSM在GQA挑战上报告了强大的性能,但它使用了更强的对象检测器和前50个对象特性(与所有其他baseline使用的前36个相比),这使得与NSM的比较变得不公平。
5.1 空间推理的结果
我们首先在不同的空间推理任务上评估模型,使用不同的弱监督训练方法。表1和表2总结了这些实验的结果。LXMERT+SR基线(在没有深度图监督的情况下进行训练)在所有空间推理任务中都表现得很差,因为深度信息并没有被当前的V&L方法的输入明确地捕获,这些方法利用只包含二维空间信息的边界框信息。平均而言,跨SR任务的改进与跨GQA任务的改进相关。在某些情况下,我们观察到该方法可以预测在GQA任务上的空间关系问题的正确答案,即使它不能正确地预测在SR任务中的箱类或对象位置。这种现象在18%的正确的GQA预测中观察到这种现象。例如,该模型预测“左”为GQA答案,以及对应于“右”的矛盾SR输出。

表1。针对空间推理任务(LXMERT+SR)训练的LXMERT模型、二维和三维相对位置估计(RPE)、回归和c路bin分类任务的结果。与同一模型具有附加特征(图像patch)的弱监督和从深度图中提取的相对位置向量的弱监督进行了对比。GQA-Val评分为弱监督任务的最佳表现,分别为2D-15w和3D-15w。回归得分以均方误差为单位,分类得分均为百分比准确率。15w:15路bin分类。
不同SR任务的比较:质心估计要求模型预测物体在单元归一化向量空间中的质心位置,而相对位置估计要求模型确定质心之间的成对距离向量。这两个任务都为空间理解提供了弱监督,但我们在表2中观察到,3DRPE的箱分类最好地转移到GQA的精度。
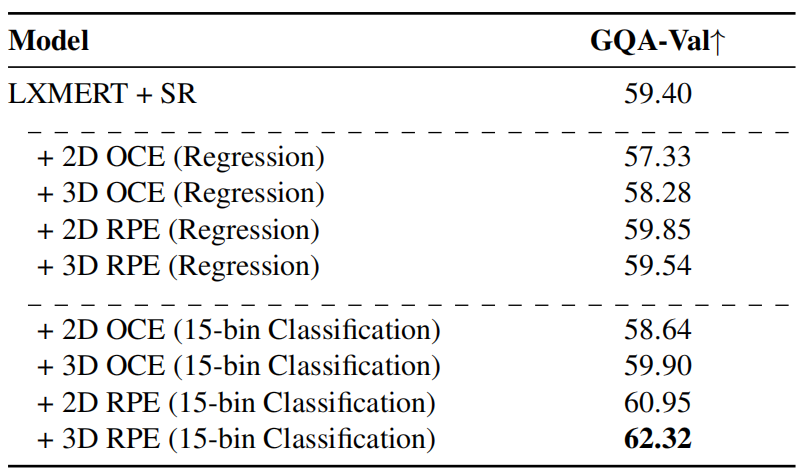
表2。在GQA验证分割上的不同弱监督空间推理任务的比较。
回归v/s Bin分类:类似地,任务的回归版本对V&L模型准确确定物体之间的极性和距离的大小提出了巨大的挑战。室内外场景的距离范围有很大的变化,对模型在回归任务中精确预测距离提出了挑战。该任务的分类版本似乎不那么具有挑战性,三路二维相对位置估计获得了显著的高分(∼90%)。bins的数量(30/3/15)也会影响性能;大量的bins意味着模型应该具有对距离的细粒度理解,这比较困难。我们发现bins的最佳数量(对于RPE和GQA)是15个。
不同方法的比较:早期图像补丁融合方法同时利用相对位置距离向量和融合transformer的锥体补丁特征,在所有空间任务和GQA任务中都取得了最好的性能。从表1中可以看出,这两个附加输入都提高了三维RPE的性能,这些性能改进可以归因于距离特征与预测目标之间的直接关系。另一方面,补丁特征隐式地拥有这种空间关系信息,并利用这两个特征一起获得最好的性能。然而,即使输入和输出之间存在直接相关性,该模型在更难的15/30路分类化或回归任务上也远没有达到完美的性能,这指出了进一步改进的空间。
早期v/s晚融合:通过表1的实验结果,我们可以得出早期融合优晚期融合的结论。我们假设融合Transformer层在从预测的相对位置距离向量中提取空间关系信息方面比晚融合更有效。
Patch大小的影响:我们研究了不同图像patch网格大小的影响,如3×3、5×5、7×7和9×9以及这些patch特征集的几种组合。我们观察到在3×3、5×5和7×7中表现最好的特征组合是整个图像和一组带有网格的patch。添加更小的patch,如9×9网格,并不会提高性能。从ResNet101中提取特性也会导致微小的收益(+0.05%)。
5.2 GQA上的结果
表3和表4总结了我们对GQA和GQA-OOD视觉问答任务的研究结果。我们最好的方法,使用早期融合和图像补丁的LXMERT,在15路双分类化相对位置估计任务的弱监督下,在GQA和GQA-OOD上比基线LXMERT分别提高了1.77%和1.3%,实现了一种新的最新水平。它在VQA-v2上的性能略优于LXMERT(72.9%),开放式问题的改善最为显著(2.21%)。我们可以观察到,弱监督和联合端到端SR的训练和使用transformer结构的问题回答,可以训练系统在空间推理任务中保持一致,并在空间VQA任务中更好地推广。
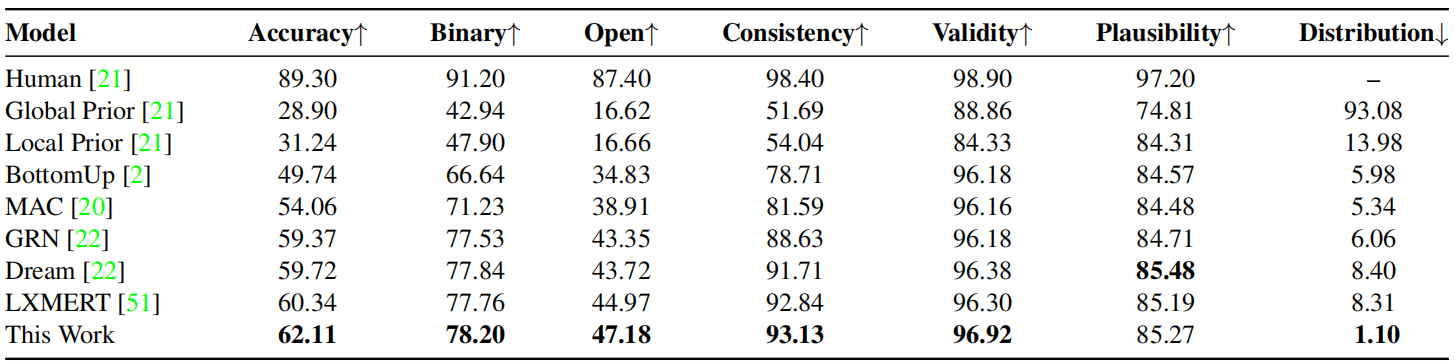
表3。在GQA测试标准集上,将我们的模型与现有baseline以及所有评估指标进行比较评估。
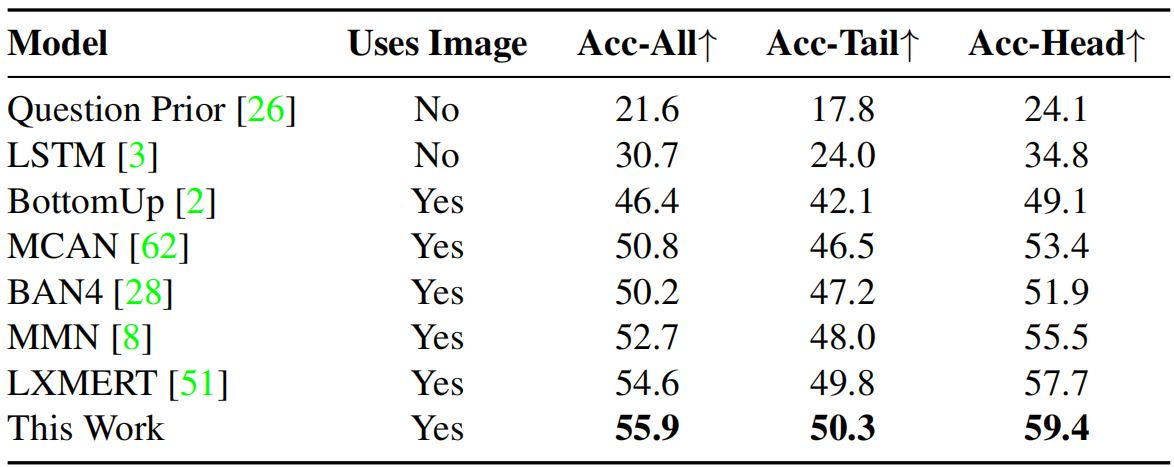
表4。在GQA-OOD test-dev分割上的几种VQA方法的比较。Acc-Tail:OOD设置,AccHead:对最可能的答案(给定的上下文)的准确性,分数单位为%。
OOD泛化:我们还研究了GQA对分布变化的泛化,即在训练过程中看到的语言先验在测试时发生了变化。我们在GQA-OOD基准上评估了我们的最佳方法,并观察到我们将最常见的答案头部分布提高了1.7%,也将不常见的非分布(OOD)尾部答案提高了0.5%。这使我们相信,在弱监督的SR任务上的训练可能允许模型减少对虚假语言相关性的依赖,从而实现更好的泛化能力。
Few-shot学习:我们研究了弱监督RPE任务对开放式问题的影响,结果如图5所示。我们可以观察到,即使在低至1%和5%的样本下,使用相对位置估计的联合训练也比使用相同数据训练的LXMERT分别提高了2.5%和5.5%,并且在所有其他分数上始终优于LXMERT。更重要的是,只有10%的训练数据集,我们的方法达到了接近使用整个(100%)数据集训练的基线LXMERT的性能。大多数空间问题都由相对的空间词来回答,如“左”、“右”、“上”、“下”或对象名称。对象名称是在V&L预训练任务中学习的,而对空间单词的学习可以在很少的空间VQA样本和包含空间信息的适当监督信号下完成。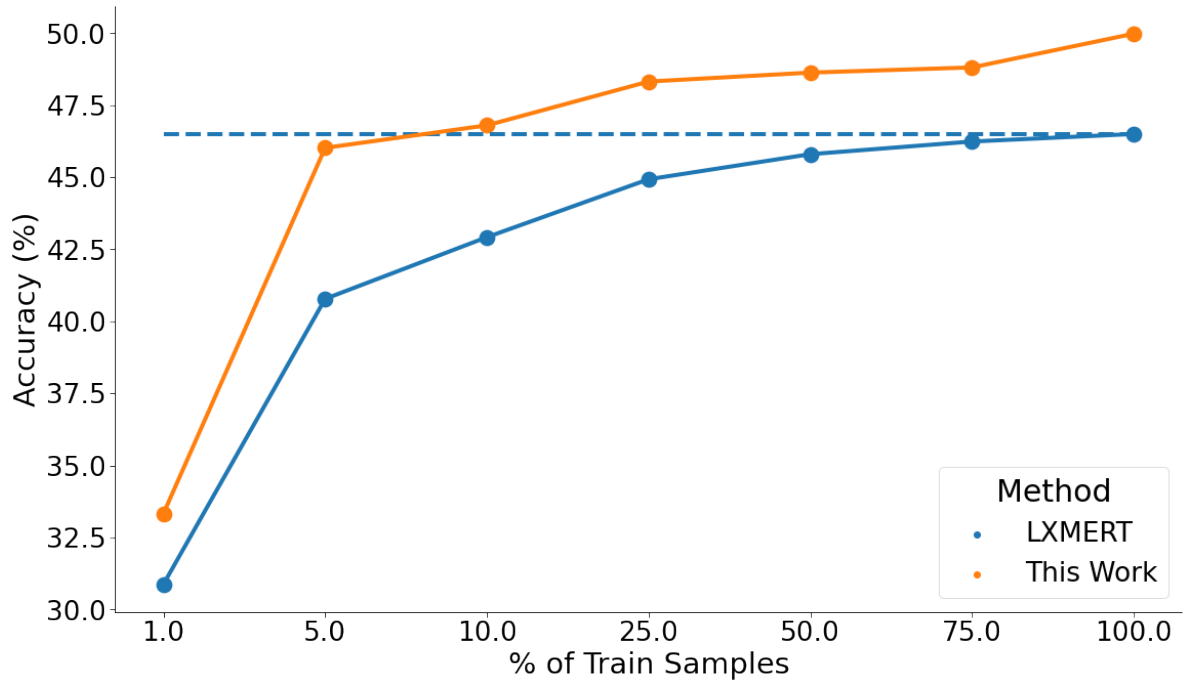
图5。与LXMERT相比,当我们在few-shot设置中进行训练,并在来自GQA-testdev分割的开放式问题上进行评估时,我们的最佳方法的性能。
5.3 错误分析
我们进行了三组错误分析来了解弱监督SR任务的不同方面,相对SR任务与VQA任务之间的一致性,以及在VQA任务中所犯的错误。
空间推理任务:sr回归似乎是最具挑战性的版本,因为系统需要重建从输入图像到三维单位归一化向量空间的相对对象距离。分类变体具有更高的召回率和更好的极性,即“右”的对象在“右”方向上正确分类,无论大小如何。将正确的距离箱类,与回归任务进行比较。大多数错误(∼60%)是由于无法区分接近的对象。
SR和VQA之间的一致性:仅在没有补丁特征或相对位置距离向量的弱监督任务上训练的基线LXMERT预测了错误空间相对位置的18%的正确预测。对于使用与图像补丁进行早期融合的最佳方法,这个误差减少到3%,增加了两个任务之间的忠诚度或一致性。我们手工分析了50个不一致的问题,观察到23个问题包含歧义,即,问题可以引用多个对象,并导致不同的答案。
手动分析:我们分析了从GQA测试-开发分割中得到的100例错误,并将其大致分类如下,括号中的误差百分比:(1)预测是地面事实的同义词或超名词;例如,“curtains-drapes”、“cellphone-phone”、“man-person”等等。8%(2)预测是黄金答案的单数/复数版本,比如“curtain-curtains”、“shelf-shelves”。(2%)(3)含糊两可的问题可以指多个对象导致不同的答案;例如,在两个黑色和棕色头发站在镜子前的照片中,有人问一个问题:“镜子前的人有黑头发吗?”(5%)(4)答案注释中的错误。(5%)(5)错误的预测。这方面的例子包括,当真实答案是“左”时,预测“右”,或者预测与答案类似的对象类,如“手机-遥控”、“交通标志-停止标志”。在许多情况下,该模型能够检测到一个物体,但不能解决其相对于另一个物体的相对位置;这可能是由于虚假的语言偏见或模型缺乏空间推理。(80%)
这项小规模的研究得出的结论是,20%的错误预测可以通过改进对主观、模糊或替代答案的评估来缓解。罗等人[34]分享了这一观察结果,并提出了更稳健地评估VQA模型的方法。
六、讨论
学习图像和文本之间对应关系的预训练模型的范式已经导致了跨广泛的V&L任务的改进。空间推理不仅是理解场景的语义,而且是理解场景的物理和几何性质的独特挑战。一股工作流从使用程序监督的顺序指令遵循的角度来处理这项任务。相比之下,我们的工作是第一个通过来自深度估计器的弱监督,在同一训练管道中联合建模几何理解和V&L。我们表明,这增加了空间推理和视觉问题回答之间的可靠性,并提高了在完全监督和少镜头设置下的GQA数据集的性能。虽然在这项工作中,我们使用了深度图作为弱监督,但许多其他来自基于物理的视觉的概念可以进一步帮助V&L推理。未来的工作还可以考虑在损益设置中的空间推理,而无需访问边界框或可靠的物体探测器(例如在恶劣天气和/或弱光设置下)。诸如此类的挑战可能会揭示基于几何和物理的视觉信号在稳健的视觉推理中发挥的作用。
7.补充知识
不适定问题(ill-posed problem):是数学领域的术语。在计算机视觉领域,Jaeyoung在CVPR的论文中这样描述CV中的不适定问题:这种不适定问题就是:一个输入图像会对应多个合理输出图像,而这个问题可以看作是从多个输出中选出最合适的那一个。
few-shot learning:小样本学习,是元学习(Meta Learning)的一个实例。Meta Learning,又称为learning to learn,该算法旨在让模型学会“学习”,能够处理类型相似的任务,而不是只会单一的分类任务。
LXMERT:从Transformers学习跨模态编码器表示(Learning Cross-Modality Encoder Representations from Transformers),用于学习视觉概念和语言语义之间的对齐和关系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号