

**前面爬取过毒液影评,这段时间很多人找我要源码,我之前的代码已经遗失,所以重新做了下,分享给大家,希望帮到大家😀**
爬取豆瓣电影恶人转
**1.分析网页**
可以看出,strat=0&limit=20,说明第一页,一页20条
第二页,以此类推,所以我们可以得到此信息页。
**2.保存所有网页**
直接给出保存代码,同学们自己查看:
``` import requests from bs4 import BeautifulSoup def gethtml(url): headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763'} xx= requests.get(url, headers=headers, timeout=3) xx.encoding='utf-8' html=xx.text return html #soup=BeautifulSoup(html, 'html.parser') #for i in soup.find_all('div', class_="comment-item"): # 名字 # data.append(i) #alldata.append(data) def savehtml(file_name,html): with open(file_name.replace('/', '_') + ".html", "wb") as f: # 写文件用bytes而不是str,所以要转码 f.write(html.encode('utf-8')) x=0 while x <200: y=str(x) url='https://movie.douban.com/subject/30211551/comments?start='+y+'&limit=20&sort=new_score&status=P' html=gethtml(url) xxx=savehtml('data'+y,html) x=x+20 ```
显示结果如上,我们防止其被封杀,所以保存网页下来
**3.数据处理**
```
from bs4 import BeautifulSoup
num=0
allname = []
alltime = []
alldatapeople = []
alltalk = []
while num<200:
y=str(num)
with open('data'+y+'.html',"r",encoding='utf-8') as f:
soup=BeautifulSoup(f.read(), 'html.parser')
#print(soup)
data=[]
alldata=[]
for i in soup.find_all('div', class_="comment-item"):
data.append(i.text.replace("\n",''))
alldata.append(i)
#print(data)
name=[]
time=[]
datapeople=[]
talk=[]
for i in data:
alldatapeople.append(i.split(" ")[0].split('有用')[0])
allname.append(i.split(" ")[0].split('有用')[1].split('看过')[0])
alltime.append(i.split(" ")[1].replace(' ',''))
alltalk.append(i.split(" ")[2])
num = num + 20
#print(alldata)
print(alldatapeople)
print(allname)
print(alltime)
print(alltalk)
```
上述获取了200条评论,以及时间,评论者名字,显示如下:
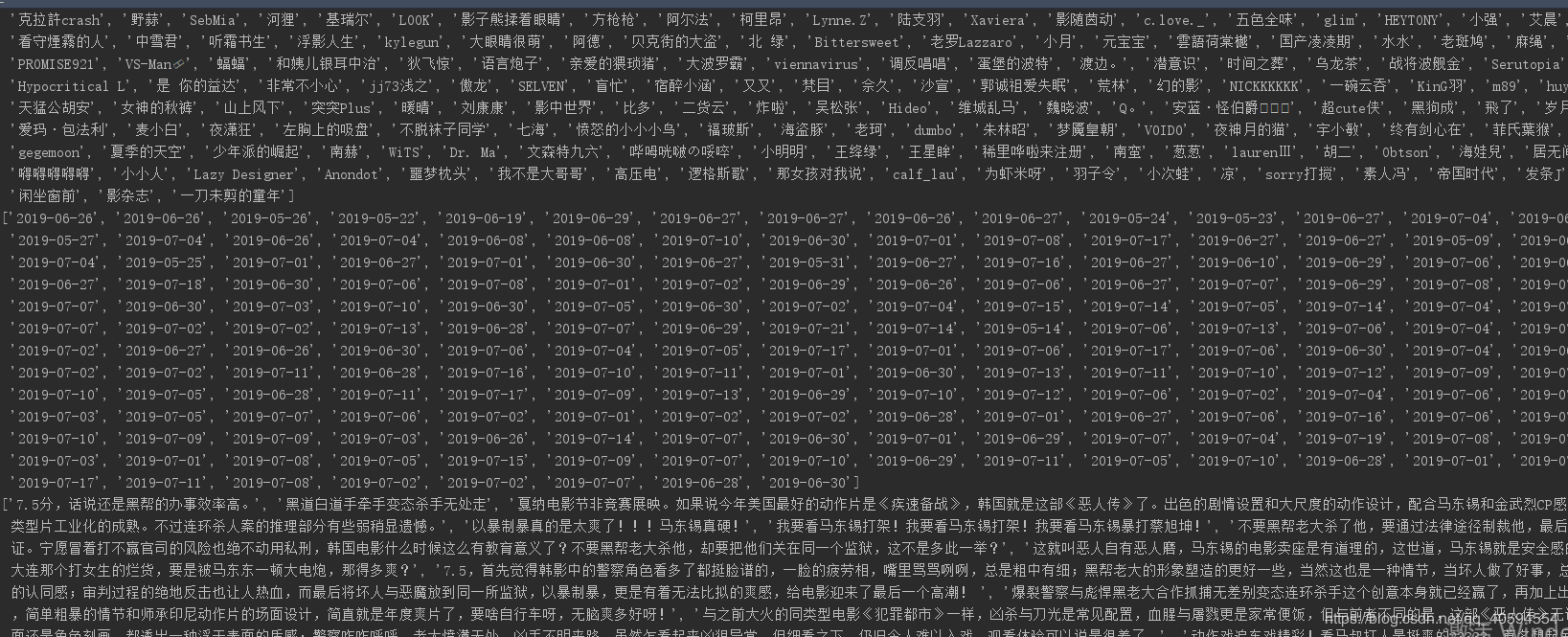
数据可视化,以及数据挖掘,从上述数据中自行处理,此处不多讲解
**4.获取更多数据**
我们已经获取数据了,以及通过数据可视化,和数据挖掘,那么我们依旧可以获取更多数据,例如,评论者得地区:代码如下:
``` import requests,csv from bs4 import BeautifulSoup def gethtml(): num = 0 alldata=[] while num<200: y=str(num) with open('data'+y+'.html',"r",encoding='utf-8') as f: soup=BeautifulSoup(f.read(), 'html.parser') data=[] newdata=[] for i in soup.find_all('div', class_="comment-item"): data.append(i) for i in data: x=str(i).replace("\n","") newdata.append(x) #print(newdata) for i in newdata: # print(i.split('href="')[1].split('"')[0]) alldata.append(i.split('href="')[1].split('"')[0]) num = num + 20 return alldata #https://www.douban.com/people/128265644/ def getdata(url_list): alldata=[] for i in url_list: headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763'} xx = requests.get(i, headers=headers, timeout=30) xx.encoding = 'utf-8' html = xx.text soup = BeautifulSoup(html, 'html.parser') for i in soup.find_all('div', class_="user-info"): # 名字 try: print(i.text.split("常居: ")[1].split("\n")[0]) alldata.append(i.text.split("常居: ")[1].split("\n")[0]) except: alldata.append("暂无") with open("居住地.csv", 'w+', newline="",encoding='utf-8') as f: writer = csv.writer(f) for row in alldata: writer.writerow(row) y=gethtml() x=getdata(y) ```
结果如下:

我将其保存为csv格式,应为涉及到得网页较多,所以容易被封,建议大家保存数据在自己电脑上,或者代理ip,等等,基本上所有代码都在上面了,关于数据分析,大家自行百度,如何画图,之类的既然有数据,那应该很简单了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号