

深度学习执行速度不稳定的解决方法
在程序中使用深度学习模型进行检测时,有时会出现执行速度忽然变慢的问题,其原因可能是当没有连续执行深度学习方法时,显卡自动降频导致的,解决方法如下:
1、在程序中开启一个新线程用空图持续执行深度学习方法,这样可避免显卡自动降频。
2、锁定显卡频率(使用nvidia-smi工具)
(1)使用 nvidia-smi -q -d SUPPORTED_CLOCKS 命令查询显卡支持的最大频率,排在最上面的即为显卡支持的最大频率。

(2)执行 nvidia-smi -lgc gpuclock 命令将显卡锁定到最大频率,出现All done表示锁定成功。

锁定最大频率后,测试非连续执行深度学习方法,执行速度不再明显下降,但仍然会有一些波动。
如需解除锁定,可执行 nvidia-smi --reset-gpu-clocks 命令。
3、配置显卡的电源管理模式
(1)打开NVIDIA控制面板,左侧选择“管理3D设置”,然后在右侧将“电源管理模式”修改为“最高性能优先”,点击应用按钮保存配置,修改后需要重启电脑生效。
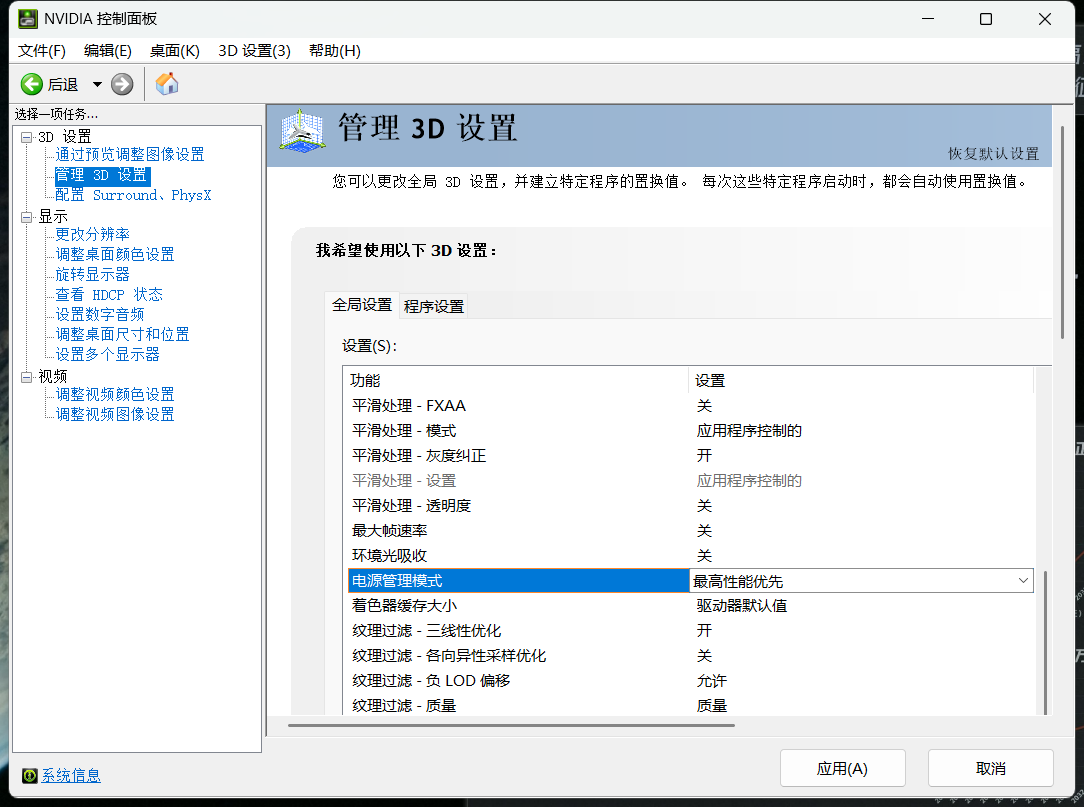
(2)重启电脑后,通过 nvidia-smi 命令可以看到显卡的性能等级已经从P8变为P0(数字越小等级越高)。
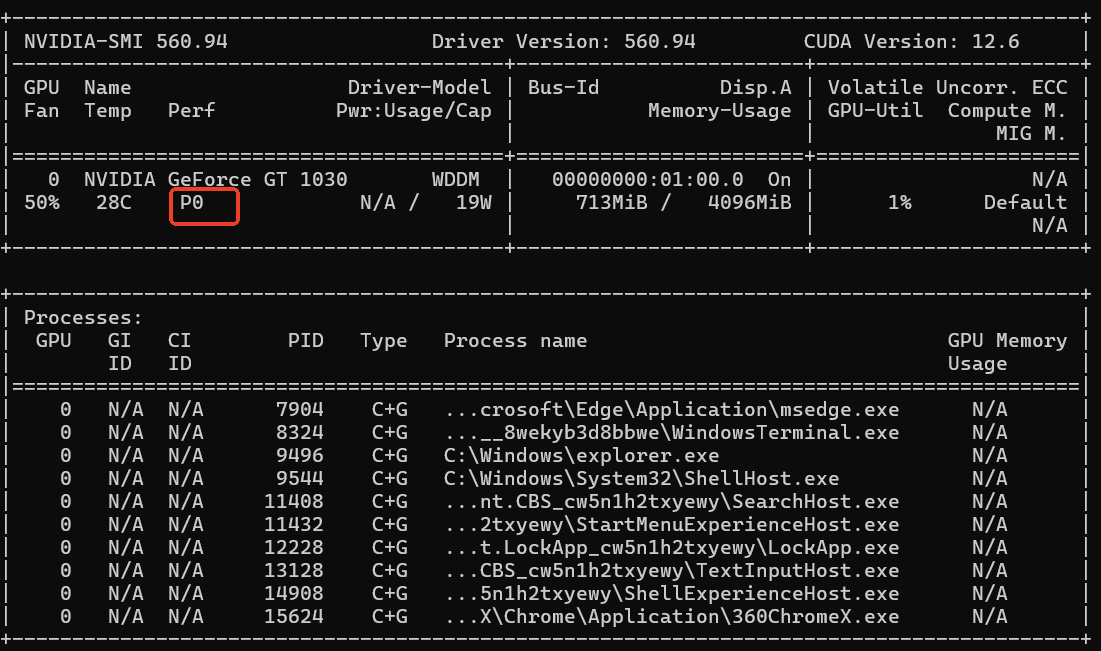
配置显卡的电源管理模式后,测试非连续执行深度学习方法,发现执行速度不再下降,执行时间波动很小。
3、首次执行深度学习方法很慢的解决方法
在程序中首次执行深度学习方法,发现执行时间很长,解决方法就是在首次执行前对深度学习模块进行预热,预热方法也很简单,就是用程序先生成一张空图让模型先执行一下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号