
个人项目:论文查重
| 作业所属课程 | https://edu.cnblogs.com/campus/gdgy/Networkengineering1834 |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/gdgy/Networkengineering1834/homework/11147 |
| 作业目标 | 实现论文查重算法,学会使用PSP表格估计,使用Github管理项目,学会单元测试 |
一、 Github仓库
二、 PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 400 | 450 |
| · Analysis | · 需求分析 (包括学习新技术) | 80 | 90 |
| · Design Spec | · 生成设计文档 | 60 | 50 |
| · Design Review | · 设计复审 | 60 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 25 |
| · Design | · 具体设计 | 35 | 40 |
| · Coding | · 具体编码 | 200 | 240 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 45 |
| Reporting | 报告 | 60 | 60 |
| · Test Report | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| Total | · 合计 | 1125 | 1250 |
三、 论文查重算法原理
1、simHash简介
simHash算法是GoogleMoses Charikear于2007年发布的一篇论文《Detecting Near-duplicates for web crawling》中提出的, 专门用来解决亿万级别的网页去重任务。
simHash是局部敏感哈希(locality sensitve hash)的一种,其主要思想是降维,将高维的特征向量映射成低维的特征向量,再通过比较两个特征向量的 汉明距离(Hamming Distance) 来确定文章之间的相似性。
局部敏感:
假设A,B具有一定的相似性,在hash之后,仍能保持这种相似性,就称之为局部敏感hash
汉明距离:
Hamming Distance,又称汉明距离,在信息论中,等长的两个字符串之间的汉明距离就是两个字符串对应位置的不同字符的个数。即将一个字符串变换成另外一个字符串所需要替换的字符个数,可使用异或操作。
例如: 1011与1001之间的汉明距离是1。
2、simHash具体流程
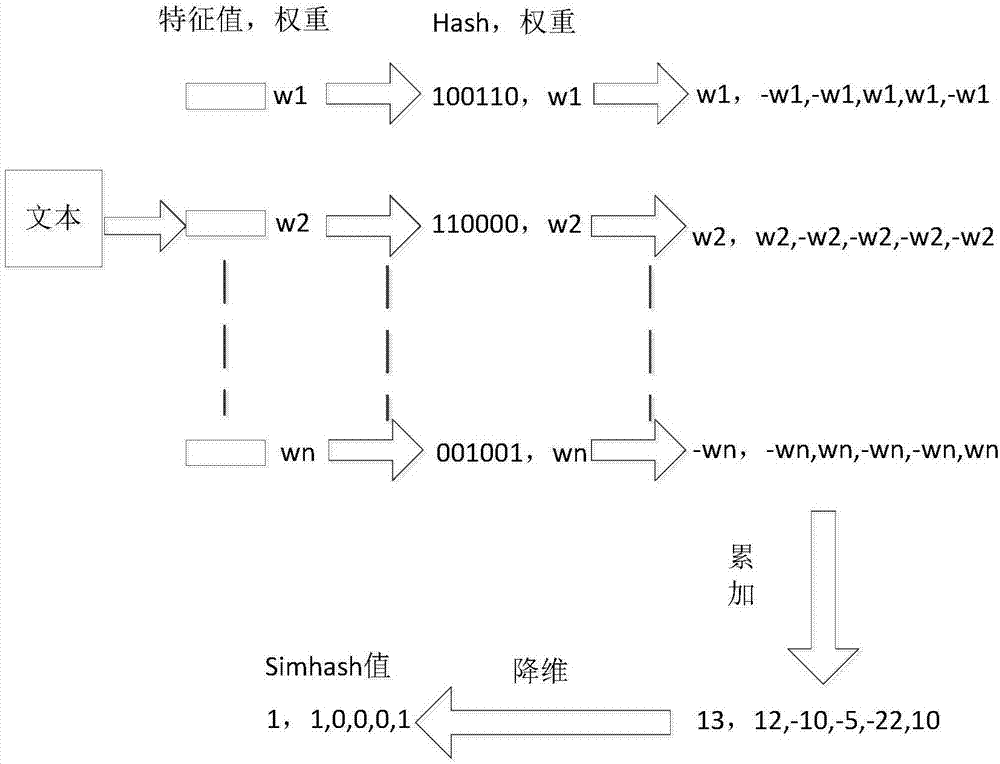
simHash算法总共分为5个流程: 分词、has、加权、合并、降维。
分词
对待处理文档进行中文分词,得到有效的特征及其权重。可以使用TF-IDF方法获取一篇文章权重最高的前topK个词(feature)和权重(weight)。即可使用jieba.analyse.extract_tags()来实现
hash
对获取的词(feature),进行普通的哈希操作,计算hash值,这样就得到一个长度为n位的二进制,得到(hash:weight)的集合。
加权
在获取的hash值的基础上,根据对应的weight值进行加权,即W=hash*weight。即hash为1则和weight正相乘,为0则和weight负相乘。例如一个词经过hash后得到(010111:5)经过步骤(3)之后可以得到列表[-5,5,-5,5,5,5]。
合并
将上述得到的各个向量的加权结果进行求和,变成只有一个序列串。如[-5,5,-5,5,5,5]、[-3,-3,-3,3,-3,3]、[1,-1,-1,1,1,1]进行列向累加得到[-7,1,-9,9,3,9],这样,我们对一个文档得到,一个长度为64的列表。
降维
对于得到的n-bit签名的累加结果的每个值进行判断,大于0则置为1, 否则置为0,从而得到该语句的simhash值。例如,[-7,1,-9,9,3,9]得到 010111,这样,我们就得到一个文档的 simhash值。
最后根据不同语句的simhash值的汉明距离来判断相似度。
simhash 原理图:
四、代码块部分单元测试展示
代码审计:
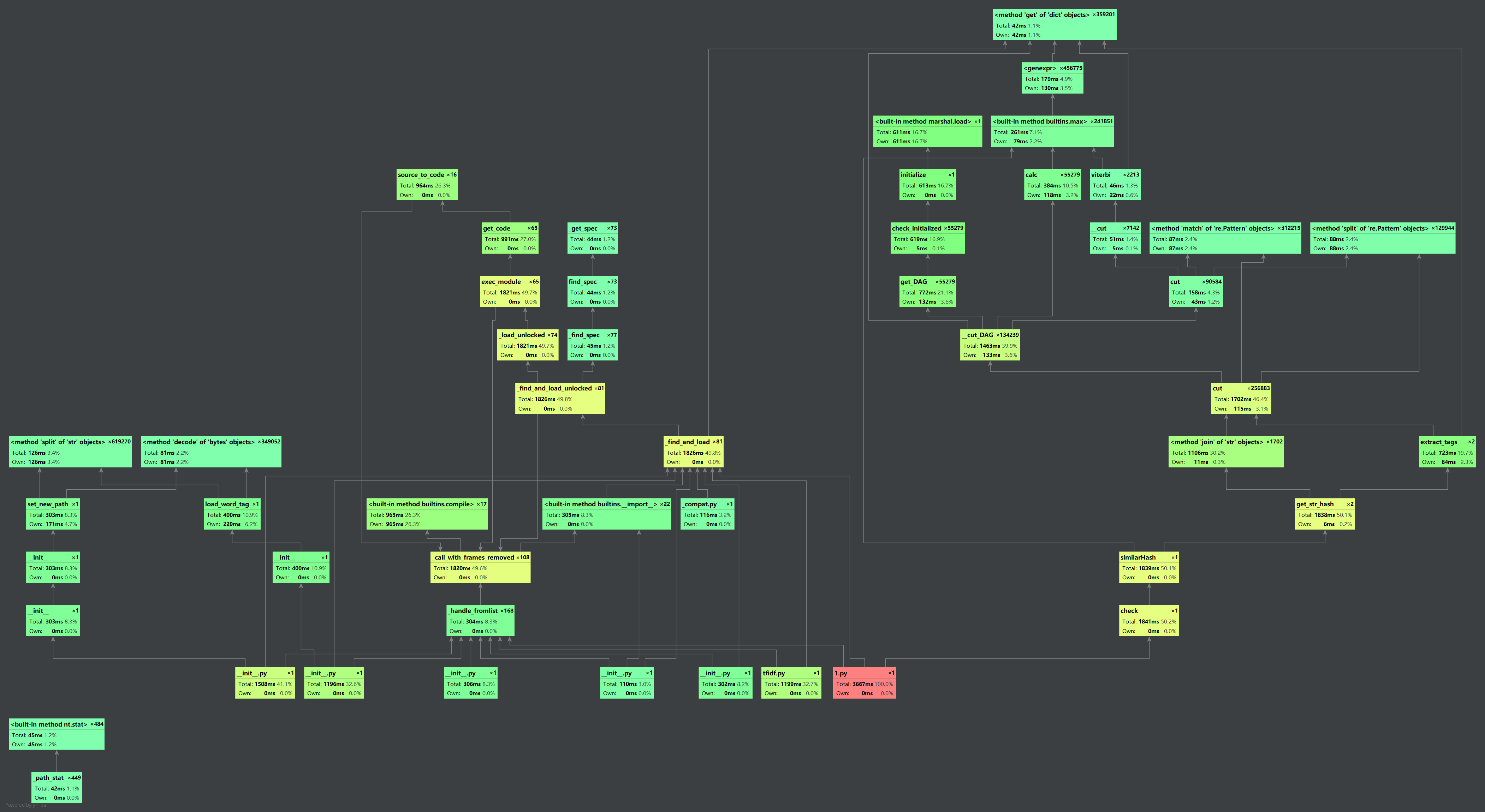
具体展示时间:
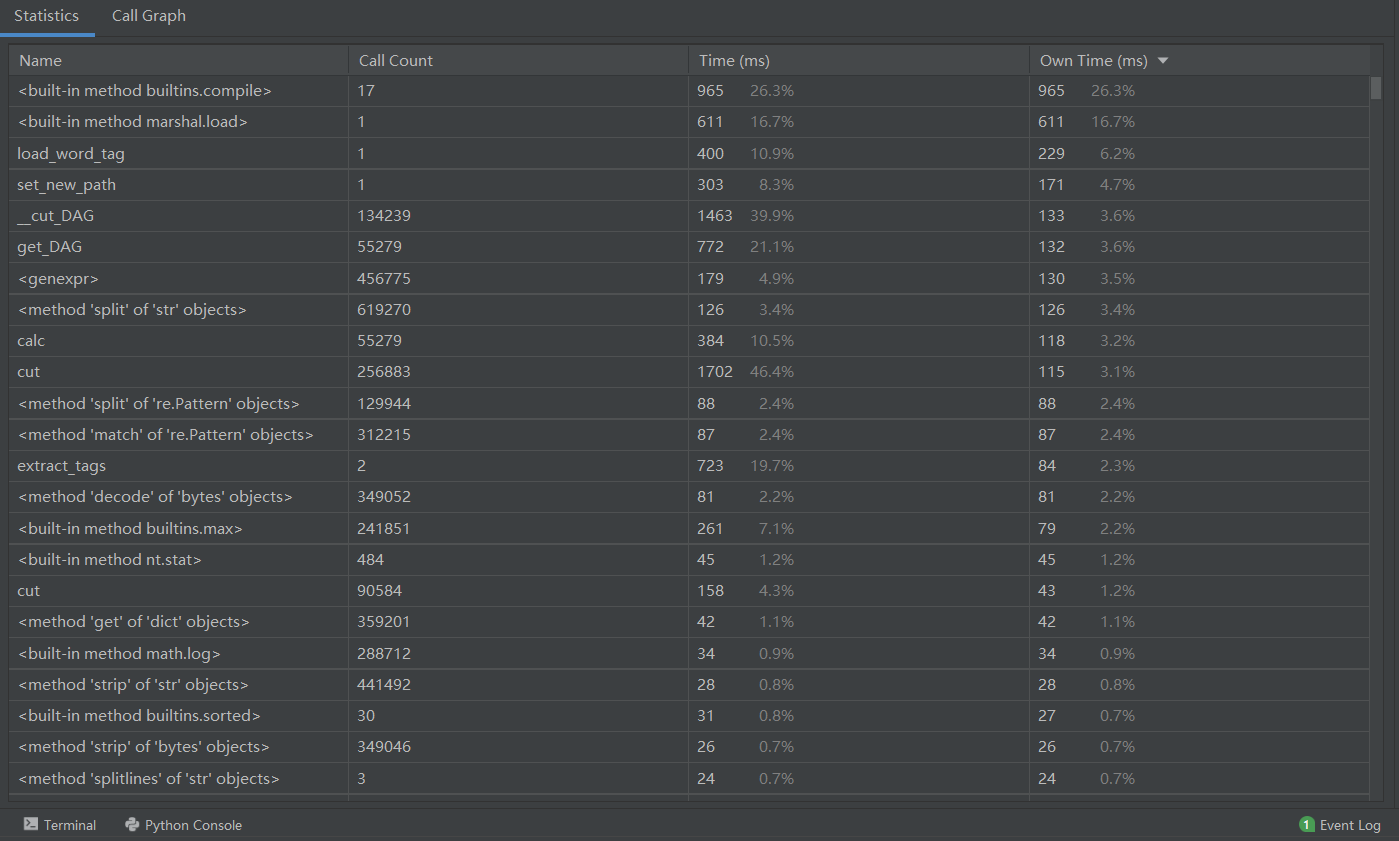
占用内存:

五、单元测试展示代码
- 对照原文
文章:.\orig.txt和文章:.\orig.txt,相似率为:1.00
- 测试抄袭文本
文章:.\orig.txt和文章:.\orig_0.8_add.txt,相似率为:0.85
文章:.\orig.txt和文章:.\orig_0.8_del.txt,相似率为:0.79
文章:.\orig.txt和文章:.\orig_0.8_dis_1.txt,相似率为:0.77
文章:.\orig.txt和文章:.\orig_0.8_dis_10.txt,相似率为:0.77
文章:.\orig.txt和文章:.\orig_0.8_dis_15.txt,相似率为:0.79
六、错误异常展示

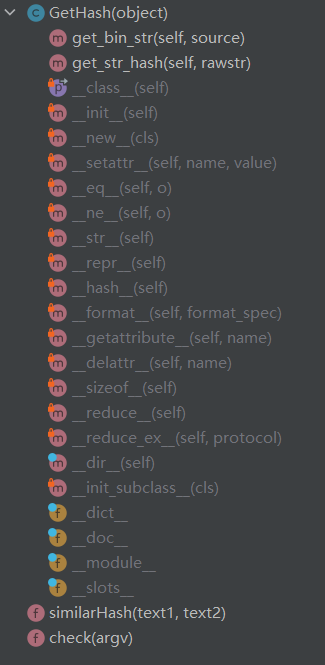
七、计算模块接口

 浙公网安备 33010602011771号
浙公网安备 33010602011771号