

前情提要:字符编码
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)。ASCILL有255个字符,包括英语和西欧字符,不包括中文。汉字处理靠GBK, window的中文内码。Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,(注:此处说的的是最少2个字节,可能更多)
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
注意三个关键:
1.在python2默认编码是ASCII, python3里默认是unicode。 UTF-8是unicode的扩展集, 。核心思想:
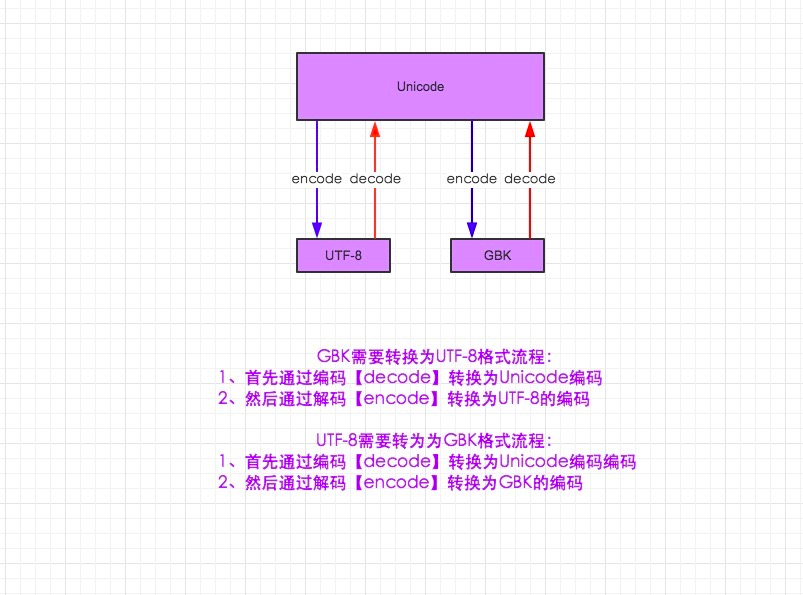
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
Py3.x的转码操作
首先,需要声明文件编码为GBK, 但是数据编码还是默认utf-8
# -*- coding:gbk -*- # 改的是文件编码,非数据编码 import sys print(sys.getdefaultencoding()) # 打印系统默认编码
utf-8
s = '你好' # 这还是个unicode print(s.encode("gbk")) # 转成gbk,转成bytes类型
b'\xc4\xe3\xba\xc3'
print(s.encode('utf-8')) # 转成UTF-8,也转成bytes类型
b'\xe4\xbd\xa0\xe5\xa5\xbd'
print(s.encode('utf-8').decode('utf-8').encode('gb2312'))
b'\xc4\xe3\xba\xc3'
重要解读: Python 编码终极版 by 吴苑

 浙公网安备 33010602011771号
浙公网安备 33010602011771号