Redis 多线程网络模型源码解读
Redis已经成为系统高性能缓存方案的事实标准,而Redis使用纯C语言编写,每个模块功能都划分的很清晰。Redis服务器是一个事件驱动程序,最近也刚好在看事件驱动这一块。
Redis 有多快?
根据官方的 benchmark,通常来说,在一台普通硬件配置的 Linux 机器上跑单个 Redis 实例,处理简单命令(时间复杂度 O(N) 或者 O(log(N))),QPS 可以达到 8w+,而如果使用 pipeline 批处理功能,则 QPS 至高能达到 100w。
在set,lpush子集下发送10w个请求
$ redis-benchmark -t set,lpush -n 100000 -q
SET: 74239.05 requests per second
LPUSH: 79239.30 requests per second
使用流水线:默认情况下,每个客户端只有在收到前一个命令的回复时才发送下一个命令,Redis 支持流水线,因此可以一次发送多个命令,减少网络RTT,能显著提高QPS。
在MacBook air 11上使用16个命令的流水线:
$ redis-benchmark -n 1000000 -t set,get -P 16 -q
SET: 403063.28 requests per second
GET: 508388.41 requests per second
仅从性能层面进行评判,Redis 完全可以被称之为高性能缓存方案。
Redis 为什么快?
Redis 的高性能得益于以下几个基础:

- C 语言实现,虽然 C 对 Redis 的性能有助力,但语言并不是最核心因素。
- 纯内存 I/O,相较于其他基于磁盘的 DB,Redis 的纯内存操作有着天然的性能优势。
- I/O 多路复用,基于 epoll/select/kqueue 等 I/O 多路复用技术,实现高吞吐的网络 I/O。
- 单线程模型,单线程无法利用多核,但是从另一个层面来说则避免了多线程频繁上下文切换,以及同步机制如锁带来的开销。
Redis 为何选择单线程?
Redis 的核心网络模型选择用单线程来实现,这在一开始就引起了很多人的不解,Redis 官方的对于此的回答是:
It's not very frequent that CPU becomes your bottleneck with Redis, as usually Redis is either memory or network bound. For instance, using pipelining Redis running on an average Linux system can deliver even 1 million requests per second, so if your application mainly uses O(N) or O(log(N)) commands, it is hardly going to use too much CPU.
However, to maximize CPU usage you can start multiple instances of Redis in the same box and treat them as different servers. At some point a single box may not be enough anyway so if you want to use multiple CPUs you can start thinking of some way to shard earlier.
核心意思就是,对于一个 DB 来说,CPU 通常不会是瓶颈,因为大多数请求不会是 CPU 密集型的,而是 I/O 密集型。具体到 Redis 的话,如果不考虑 RDB/AOF 等持久化方案,Redis 是完全的纯内存操作,执行速度是非常快的,因此这部分操作通常不会是性能瓶颈,Redis 真正的性能瓶颈在于网络 I/O,也就是客户端和服务端之间的网络传输延迟,因此 Redis 选择了单线程的 I/O 多路复用来实现它的核心网络模型。
上面是比较笼统的官方答案,实际上更加具体的选择单线程的原因可以归纳如下:
- 避免过多的上下文切换开销:线程切换会带来开销
- 避免同步机制的开销:需要将数据结构都改成线程安全的
- 简单可维护:并发编程将是逻辑和执行顺序不可预测,使编码和调试复杂
Redis 真的是单线程?
在讨论这个问题之前,我们要先明确『单线程』这个概念的边界:它的覆盖范围是核心网络模型,抑或是整个 Redis?如果是前者,那么答案是肯定的,在 Redis 的 v6.0 版本正式引入多线程之前,其网络模型一直是单线程模式的;如果是后者,那么答案则是否定的,Redis 早在 v4.0 就已经引入了多线程。
因此,当我们讨论 Redis 的多线程之时,有必要对 Redis 的版本划出两个重要的节点:
Redis v4.0(引入多线程处理异步任务)
Redis v6.0(正式在网络模型中实现 I/O 多线程)
Redis 在 6.0 版本之前的单线程事件循环模型,实际上就是一个非常经典的 Reactor 模型:
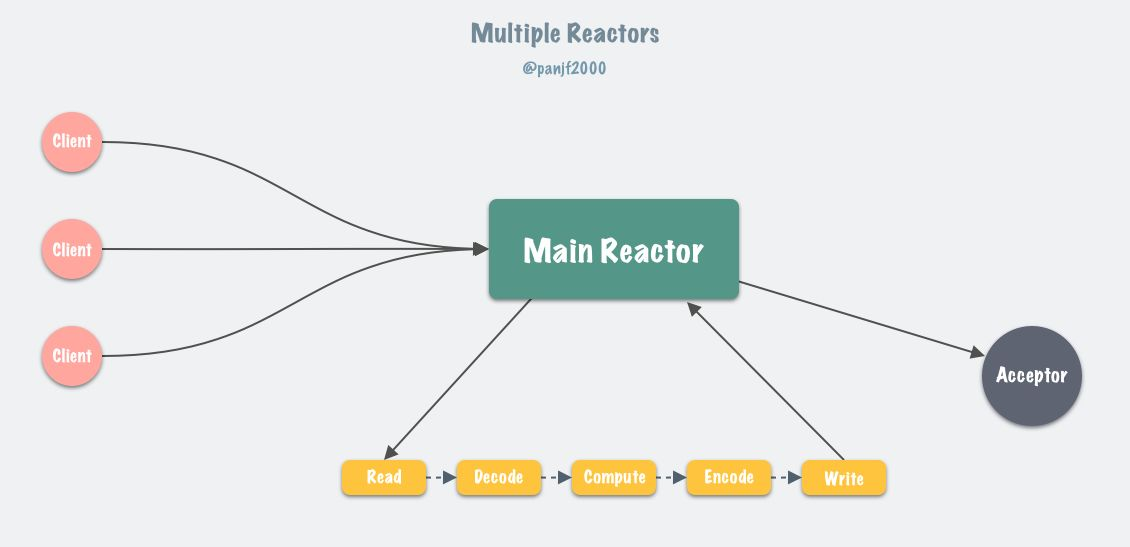
目前 Linux 平台上主流的高性能网络库/框架中,大都采用 Reactor 模式,比如 netty、libevent、libuv、POE(Perl)、Twisted(Python)等。
Reactor 模式本质上指的是使用 I/O 多路复用(I/O multiplexing) + 非阻塞 I/O(non-blocking I/O) 的模式。
Redis 多线程网络模型
执行流程

- Redis 服务器启动,开启主线程事件循环(Event Loop),注册 acceptTcpHandler 连接应答处理器到用户配置的监听端口对应的文件描述符,等待新连接到来;
- 客户端和服务端建立网络连接;
- acceptTcpHandler 被调用,主线程使用 AE 的 API 将 readQueryFromClient 命令读取处理器绑定到新连接对应的文件描述符上,并初始化一个 client 绑定这个客户端连接;
- 客户端发送请求命令,触发读就绪事件,服务端主线程不会通过 socket 去读取客户端的请求命令,而是先将 client 放入一个 LIFO 队列 clients_pending_read;
- 在事件循环(Event Loop)中,主线程执行 beforeSleep -->handleClientsWithPendingReadsUsingThreads,利用 Round-Robin 轮询负载均衡策略,把 clients_pending_read队列中的连接均匀地分配给 I/O 线程各自的本地 FIFO 任务队列 io_threads_list[id] 和主线程自己,I/O 线程通过 socket 读取客户端的请求命令,存入 client->querybuf 并解析第一个命令,但不执行命令,主线程忙轮询,等待所有 I/O 线程完成读取任务;
- 主线程和所有 I/O 线程都完成了读取任务,主线程结束忙轮询,遍历 clients_pending_read 队列,执行所有客户端连接的请求命令,先调用 processCommandAndResetClient 执行第一条已经解析好的命令,然后调用 processInputBuffer 解析并执行客户端连接的所有命令,在其中使用 processInlineBuffer 或者 processMultibulkBuffer 根据 Redis 协议解析命令,最后调用 processCommand 执行命令;
- 根据请求命令的类型(SET, GET, DEL, EXEC 等),分配相应的命令执行器去执行,最后调用 addReply 函数族的一系列函数将响应数据写入到对应 client 的写出缓冲区:client->buf 或者 client->reply ,client->buf 是首选的写出缓冲区,固定大小 16KB,一般来说可以缓冲足够多的响应数据,但是如果客户端在时间窗口内需要响应的数据非常大,那么则会自动切换到 client->reply 链表上去,使用链表理论上能够保存无限大的数据(受限于机器的物理内存),最后把 client 添加进一个 LIFO 队列 clients_pending_write;
- 在事件循环(Event Loop)中,主线程执行 beforeSleep --> handleClientsWithPendingWritesUsingThreads,利用 Round-Robin 轮询负载均衡策略,把 clients_pending_write 队列中的连接均匀地分配给 I/O 线程各自的本地 FIFO 任务队列 io_threads_list[id] 和主线程自己,I/O 线程通过调用 writeToClient 把 client 的写出缓冲区里的数据回写到客户端,主线程忙轮询,等待所有 I/O 线程完成写出任务;
- 主线程和所有 I/O 线程都完成了写出任务, 主线程结束忙轮询,遍历 clients_pending_write 队列,如果 client 的写出缓冲区还有数据遗留,则注册 sendReplyToClient 到该连接的写就绪事件,等待客户端可写时在事件循环中再继续回写残余的响应数据。
源码剖析
根据最新的Redis v6.2.
(矢量图,可点击方法查看)

思考
1. Redis 的多线程模型是全程无锁(Lock-free)的
Redis 的多线程模式下,似乎并没有对数据进行锁保护,事实上 Redis 的多线程模型是全程无锁(Lock-free)的,这是通过原子操作+交错访问来实现的,主线程和 I/O 线程之间共享的变量有三个:io_threads_pending 计数器、io_threads_op I/O 标识符和 io_threads_list 线程本地任务队列。
io_threads_pending 是原子变量,不需要加锁保护,io_threads_op 和 io_threads_list 这两个变量则是通过控制主线程和 I/O 线程交错访问来规避共享数据竞争问题:I/O 线程启动之后会通过忙轮询和锁休眠等待主线程的信号,在这之前它不会去访问自己的本地任务队列 io_threads_list[id],而主线程会在分配完所有任务到各个 I/O 线程的本地队列之后才去唤醒 I/O 线程开始工作,并且主线程之后在 I/O 线程运行期间只会访问自己的本地任务队列 io_threads_list[0] 而不会再去访问 I/O 线程的本地队列,这也就保证了主线程永远会在 I/O 线程之前访问 io_threads_list 并且之后不再访问,保证了交错访问。io_threads_op 同理,主线程会在唤醒 I/O 线程之前先设置好 io_threads_op 的值,并且在 I/O 线程运行期间不会再去访问这个变量。

可见,不会,Redis 的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程顺序执行。因此,不会存在线程并发安全问题。
源码里面有个io_threads_mutex,但这个并不是用来做线程同步的,而是开启和停止ThreadedIO的
2. 模型有什么缺陷
首先,Redis 的多线程网络模型实际上并不是一个标准的 Multi-Reactors/Master-Workers 模型,和其他主流的开源网络服务器的模式有所区别,最大的不同就是在标准的 Multi-Reactors/Master-Workers 模式下,Sub Reactors/Workers 会完成 网络读 -> 数据解析 -> 命令执行 -> 网络写 整套流程,Main Reactor/Master 只负责分派任务,而在 Redis 的多线程方案中,I/O 线程任务仅仅是通过 socket 读取客户端请求命令并解析,却没有真正去执行命令,所有客户端命令最后还需要回到主线程去执行,因此对多核的利用率并不算高,而且每次主线程都必须在分配完任务之后忙轮询等待所有 I/O 线程完成任务之后才能继续执行其他逻辑。
Redis 之所以如此设计它的多线程网络模型,我认为主要的原因是为了保持兼容性,因为以前 Redis 是单线程的,所有的客户端命令都是在单线程的事件循环里执行的,也因此 Redis 里所有的数据结构都是非线程安全的,现在引入多线程,如果按照标准的 Multi-Reactors/Master-Workers 模式来实现,则所有内置的数据结构都必须重构成线程安全的,这个工作量无疑是巨大且麻烦的。
其次,目前 Redis 的多线程模型中,主线程和 I/O 线程的通信过于简单粗暴:忙轮询和原子变量,因为通过自旋忙轮询进行等待,导致 Redis 在启动的时候以及运行期间偶尔会有短暂的 CPU 空转引起的高占用率,而且这个通信机制的最终实现看起来非常不直观和不简洁,希望后面 Redis 能对目前的方案加以改进。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号