ESRGAN的原理及Pytorch实现
paper: https://arxiv.org/pdf/1809.00219.pdf
Enhanced SRGAN,顾名思义,就是SRGAN的增加版
改进的地方包括网络结构、对抗损失和感知损失
网络结构
作者参考SRResNet结构作为整体的网络结构,SRResNet的基本结构如下:
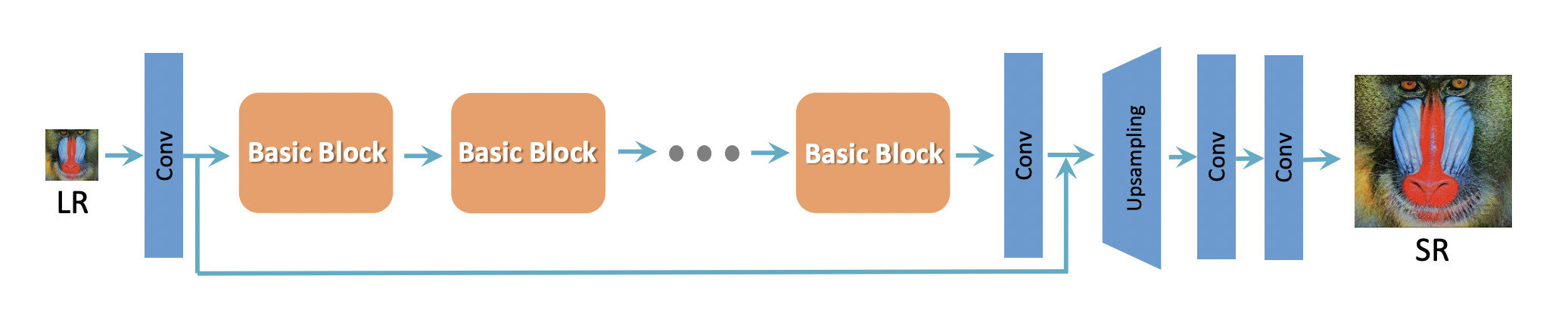
判别器和SRGAN一样,多层卷积,最后得到一个patch
生成器有些区别,将residual blocks换成了RRDB

5个conv模块拼成一个Dense block,3个Dense block拼成一个RRDB(密集的残差中的残差模块),论文中连续使用了23个RRDB (/恐怖)
Dense Block加到主路径上还有一个参数β
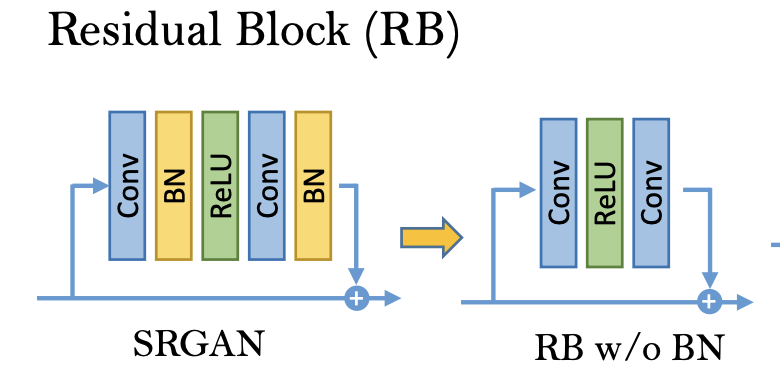
可以发现,与SRGAN相比,去掉了BN层
loss 改进
adversaial loss
借鉴Relativeistic GAN,然判别器预测图像的真实性而不是“是否是fake图片”
SRGAN中的判别器D用于估计输入到判别器中的图像是真实且自然图像的概率,而Relativistic判别器则尝试估计真实图像相对来说比fake图像更逼真的概率。


perceptual loss
感知loss,也就是vgg loss
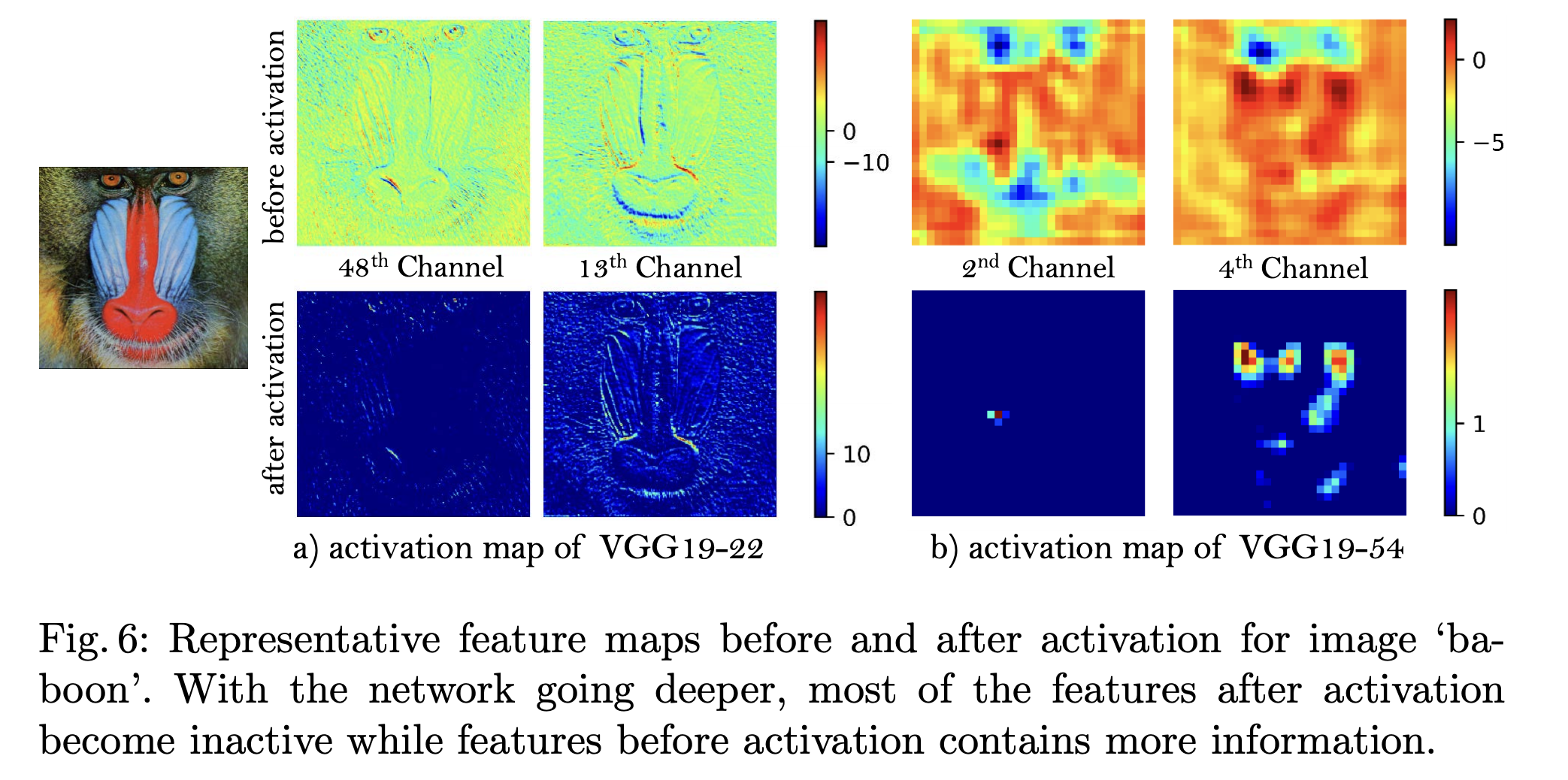
激活前后的feature map,作者发现,随着网络的加深,激活之后的大部分features会变得inactive
因此,使用激活前的feature map来计算loss
SRGAN
self.vgg = vgg19(pretrained=True).features[:36].eval().to(config.DEVICE)
ESRGAN
self.vgg = vgg19(pretrained=True).features[:35].eval().to(config.DEVICE)
代码上看就是少了一层,论文中还解释了一大堆,自己可以去看一下。。。
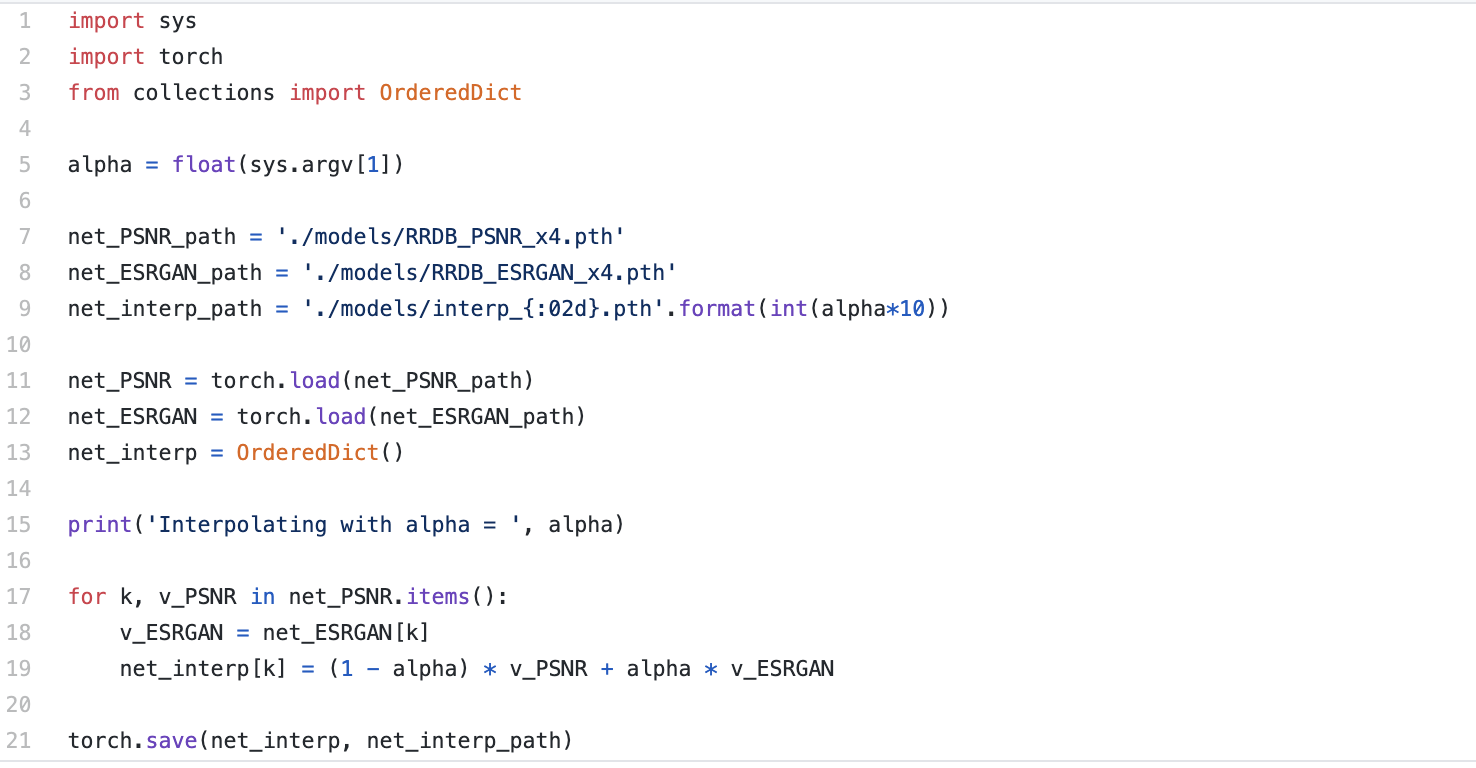
Network Interpolation
作者说纯的 GAN-based method产生锐利的边缘和丰富的纹理,但是有一些unpleasant artifact;而纯的PSNR-oriented method会输出卡通风格的模糊图片
通过使用网络插值,unpleasant artifact会减少,而纹理会保留。对比起来,Image interpolation不能有效的去除artifact

实现起来也很简单,将两个网络的权重线性相加(这网络结构不就要一模一样吗?
一些思考
(1) 为什么要去掉BN?
论文有写
ESRGAN不使用批量标准化。学习如何规范化层之间的数据分布是许多深度神经网络中的一般做法。BN层通过在训练中使用一批数据的均值和方差规范化特征并且在测试时通过使用在整个训练集上预估后的均值和方差规范化测试数据。当训练集和测试集的统计结果相差甚远时,BN层常常趋向于引入一些不太爽的伪影并且限制了模型的泛化能力,删除批量标准化可提高稳定性并降低计算成本(减少学习参数)

(2) VGG 如何选取
正如我在SRGAN中说得那样,vgg需要是在同一数据集上训练得到的吗?如果不是,该怎么选

该论文作者说,他们使用了一个用于材料识别的VGG微调网络,它关注纹理而不是对象。
虽然MINC loss带来的感知指数的增益是微乎其微的,但我们仍然认为,探索专注于纹理的感知损失对SR任务至关重要
其他
一个训练技巧
除了上述的改进,作者也使用了一些技巧来训练深层网络:1.对残差信息进行scaling,即将残差信息乘以一个0到1之间的数,用于防止不稳定;2.更小的初始化,作者发现当初始化参数的方差变小(x 0.1)时,有利于帮助网络跳出局部极小值,残差结构更容易进行训练。
参考链接:
1. https://zhuanlan.zhihu.com/p/73395512
2. https://zhuanlan.zhihu.com/p/54473407

 浙公网安备 33010602011771号
浙公网安备 33010602011771号