图像分割U-Net原理及Pytorch实现
follow this video: https://www.youtube.com/watch?v=IHq1t7NxS8k
paper: https://arxiv.org/pdf/1505.04597.pdf
介绍
一个2015年较老经典的模型,最初是为生物医学图像而开发的,后面在许多图像分割(Image Segmentation)任务都有良好的表现
结构
全都在这张图里了
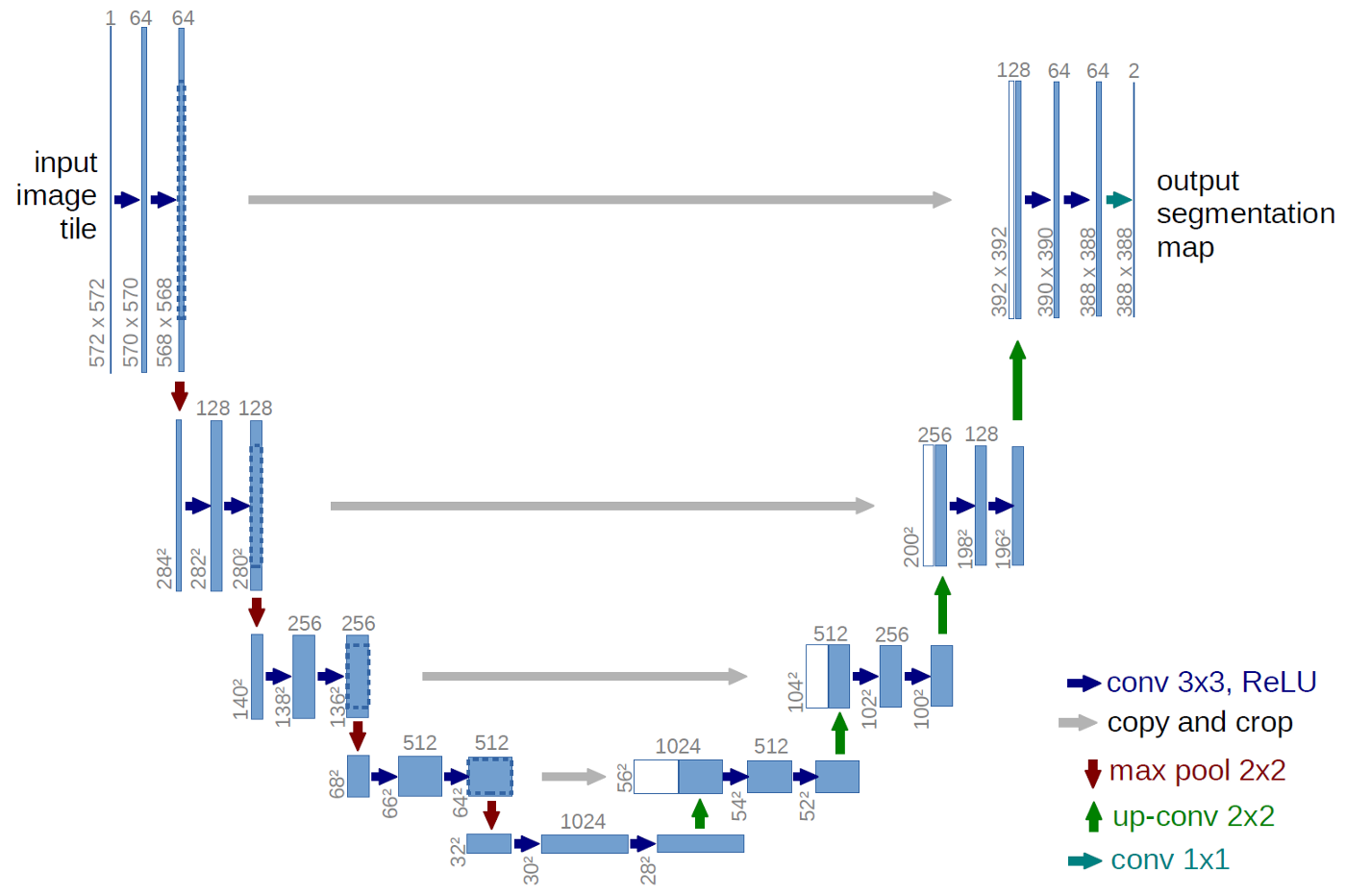
好对称啊,Encode-Decode
(1) Encode
Encode由卷积操作和下采样操作组成,论文中的所用的卷积结构统一为 3x3 的卷积核, padding=0, stride=1,没有padding所以每次卷积之后feature map的 H 和 W 都会减2.
但在像Residual中,使用padding来 res(x) 和 x 尺寸相同,方便相加
- 3 1 0,W和H - 2
- 3 1 1,W和H 不变
(2) Decode
feature经过Decode恢复原始分辨率,该过程除了卷积还有upsampling和skip-connection
Upsamping上采样常用的有2种:反卷积 和 插值,论文用的反卷积(有博客写论文中用的插值,但是我看是用的反卷积啊,是不是论文有修改呢)
一个细节
论文中为了更好地处理图像的边界像素,给输入加上镜像的圈
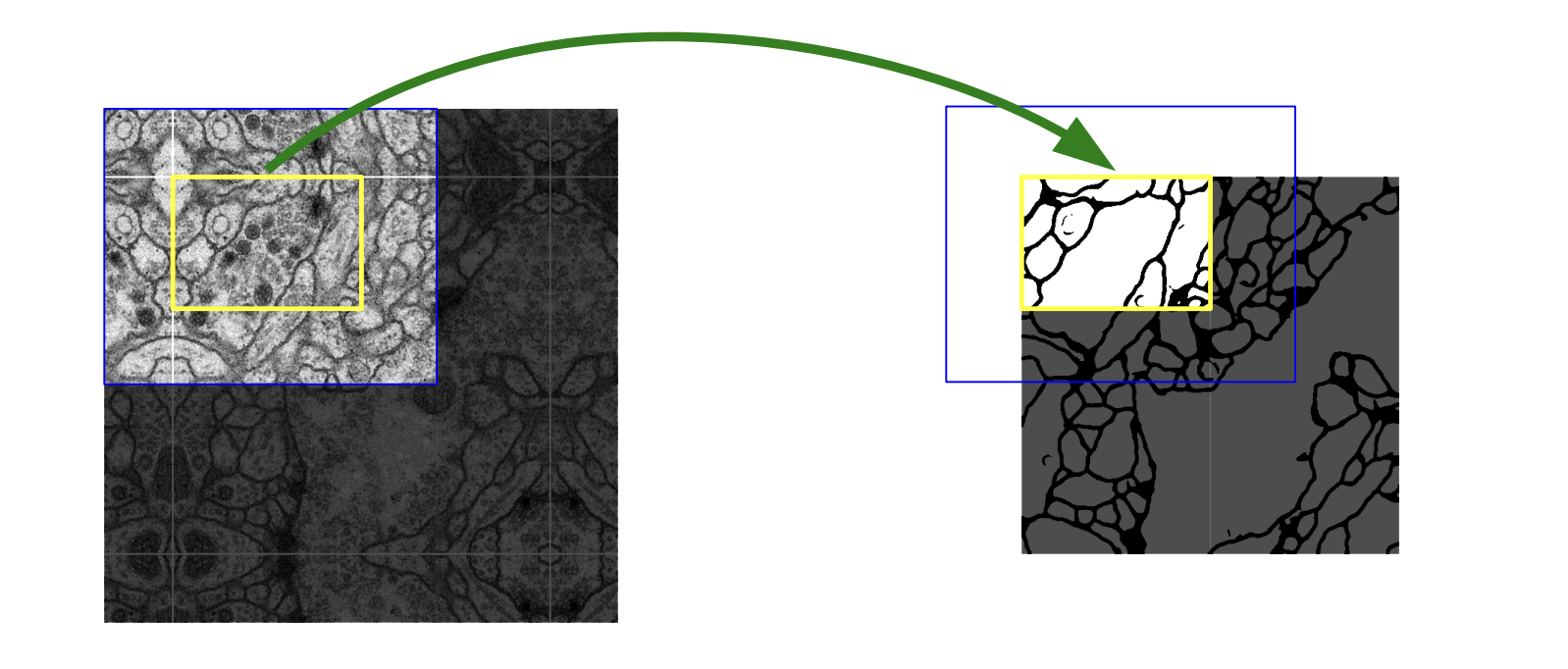
那么这个边的宽度多少好呢?
一个比较好的策略是通过感受野来确定
因为有效卷积是会降低Feature Map分辨率的,但是我们希望 512x512的图像的边界点能够保留到最后一层Feature Map。所以我们需要通过加边的操作增加图像的分辨率,增加的尺寸即是感受野的大小,也就是说每条边界增加感受野的一半作为镜像边。
根据图1中所示的压缩路径的网络架构,我们可以计算其感受野:
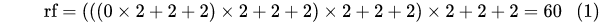
这就是为什么U-Net的输入数据是572x572
疑问:每一次不是都可以设置padding吗,padding不就是为了处理边界情况的吗(菜鸡落泪
其他
U型结构也启发了后面很多算法,比如CycleGAN的generator就是用的U-Net.
参考链接:
1. https://juejin.cn/post/6844903924999127047
2. https://zhuanlan.zhihu.com/p/43927696

 浙公网安备 33010602011771号
浙公网安备 33010602011771号